
基于TCGA数据库的差异基因分析实现
1.数据下载1.1 网页下载1.2 TCGABiolinks下载setwd("D:\Bioinformatics data analysis")if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install("TCGAbiolinks")library(
1.数据下载
1.1 网页下载
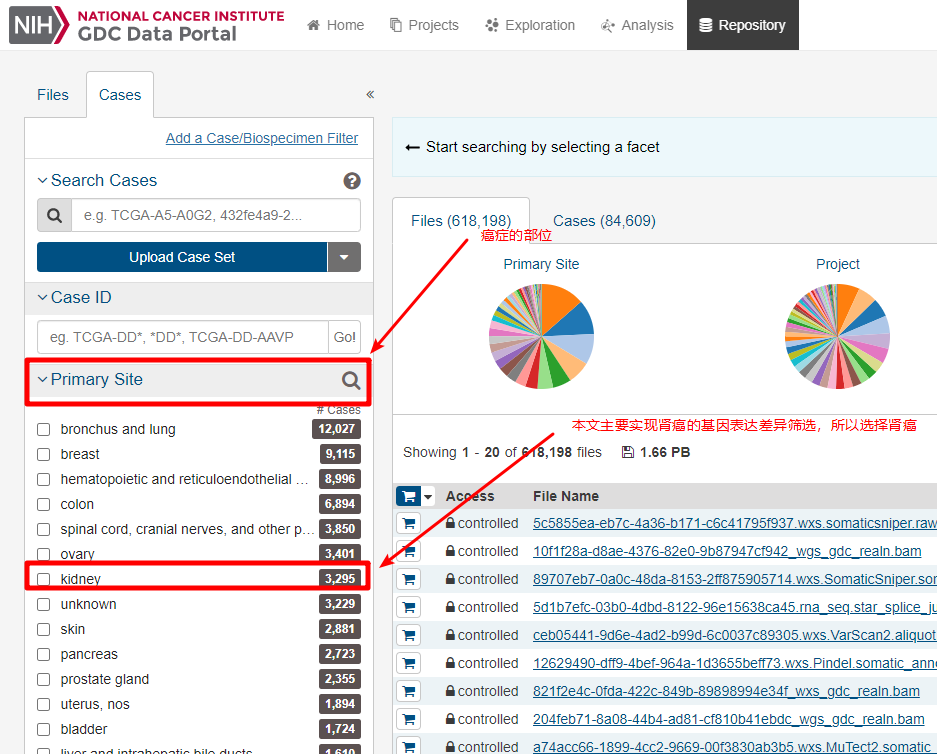
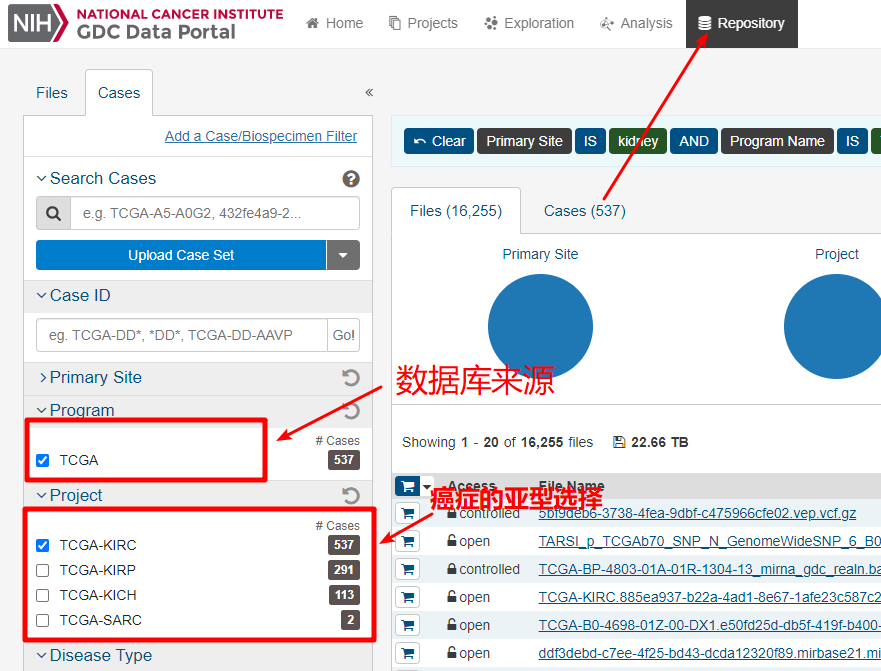
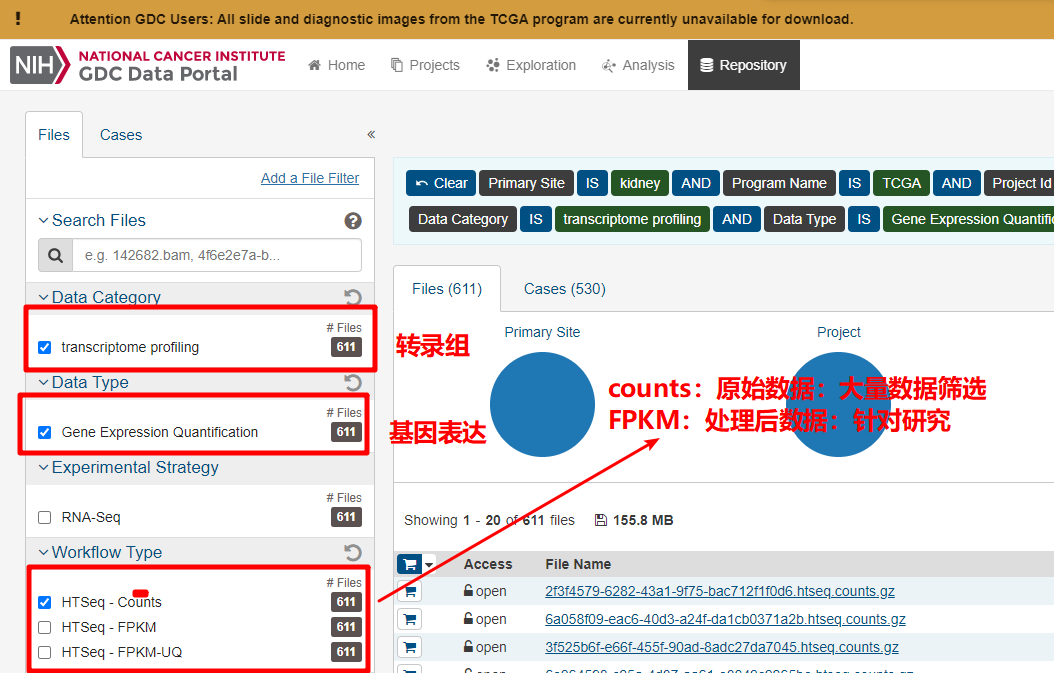
1.2 TCGABiolinks下载
setwd("D:\Bioinformatics data analysis")
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("TCGAbiolinks")
library(TCGAbiolinks)
query <- GDCquery(project = "TCGA-KIRC",
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "HTSeq - Counts")
BiocManager :管理旗下的所有R包,具有少依赖,即时更行的特点
TCGAbiolinks :TCGA的一个官方数据包,详细教程参考TCGA数据下载—TCGAbiolinks包参数详解
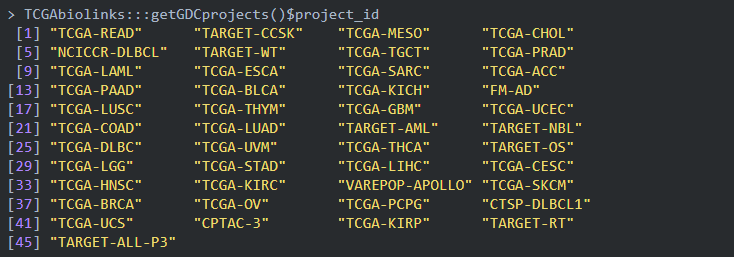
project:可以使用TCGAbiolinks:::getGDCprojects()$project_id)得到各个癌种的项目id,总共有45个ID值。对应中文参考TCGA数据库中含有的癌症名称、简写、中文名称对照表
data.category:可以使用TCGAbiolinks:::getProjectSummary(project)查看project中有哪些数据类型,表达谱’data.category="Transcriptome Profiling’
| 序号 | 类型[英] | 类型[中] |
|---|---|---|
| 1 | Transcriptome Profiling | 转录组分析 |
| 2 | Copy Number Variation | 拷贝数变异 |
| 3 | Simple Nucleotide Variation | 简单的核苷酸变异 |
| 4 | DNA Methylation | DNA甲基化 |
| 5 | Clinical | 临床数据 |
| 6 | Sequencing Reads | 测序(机翻:可能有错) |
| 7 | Biospecimen | 生物标本 |
data.type:筛选要下载的文件的数据类型
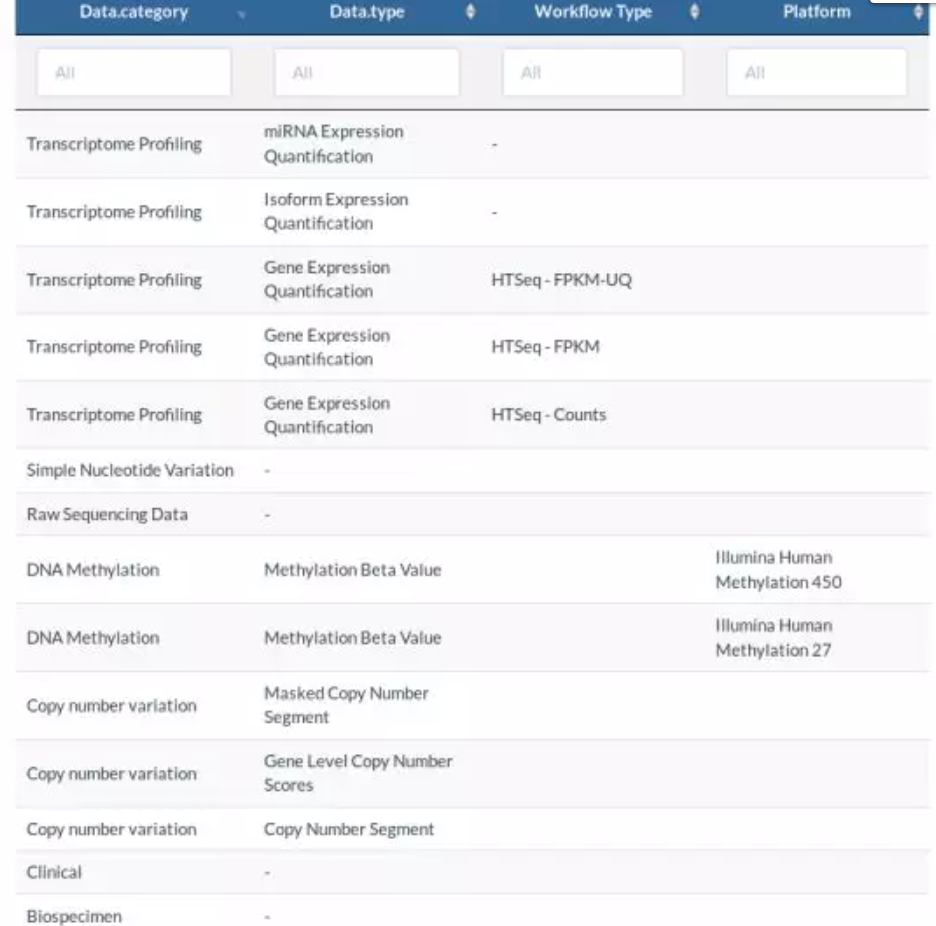
workflow.type:不同的数据类型,有其对应的参数可供选择。workflow.type 有三种类型分别为:
- HTSeq - FPKM-UQ:FPKM上四分位数标准化值
- HTSeq - FPKM:FPKM值/表达量值
- HTSeq - Counts:原始count数
本次需要count数,即workflow.type=“HTSeq - Counts”。
2. 数据预处理
2.1数据组合

所以我们要做的就是把下载得到的所有文件夹里面的压缩包移动到同一个文件夹,然后把他们解压,让所有的counts文件放在一起,便于我们后面的导入。
##################数据文件解压、组合#######################
#移动文件夹中的所有压缩包到同一个文件夹,再解压
#2021.6.8 R4.0.1
setwd("D:/Bioinformatics")
dir.create("mergeAllFileTofolder")
filePath = dir(path = "./dataBase_TCGA-KIRC",full.names = T)
filePath = filePath[1:length(filePath)-1]
for(wd in filePath){
files = dir(path = wd,pattern = "gz$")
fromFilePath = paste0(wd,"/",files)
toFilePath = paste0("./mergeAllFileTofolder/",files)
file.copy(fromFilePath,toFilePath)
}
setwd("./mergeAllFileTofolder")
countsFiles = dir(path = "./",pattern = "gz$")
library(R.utils)
sapply(countsFiles,gunzip)
得到的文件夹如下图所示,下面就便于导入数据了。
2.2counts矩阵生成
我们需要把上一步得到的所有文件导入到同一个表中,其中为EnsembleID,行名为TCGA编码。
-
疑问:
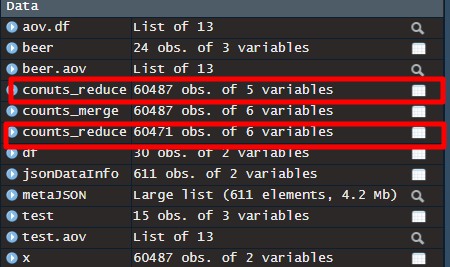
-
疑问:
#################counts转换矩阵#####################
#导入所有counts文件,然后根据JOSN数据修改列名为TCGA编码,以及去掉EnsembleID的版本号,便于后面进行ID转换
#2021.6.8 R4.0.1
#文件读取
setwd("D:/Bioinformatics")
countFilePath = dir(path = "./test_Samplecounts",pattern = "*.counts")
counts_merge = NULL
for (i in countFilePath) {
x=read.delim(paste0("./test_Samplecounts/",i),col.names = c("ID",substring(i,1,9)))
if(is.null(counts_merge)){
counts_merge = x
}
else{
counts_merge =merge(counts_merge,x,by = "ID")
}
}
#转换行名
rownames(counts_merge)=counts_merge$ID
counts_reduce = counts_merge[-(1:5),]
conuts_reduce = counts_merge[,-1]
rownames(counts_reduce) = counts_merge$ID[-(1:5)]
#head(counts_reduce,10)[,1:3]
#注释分组信息提取
#加载meta文件
metaJSON = fromJSON(file = './metadata.cart.2021-06-08.json')
jsonDataInfo = data.frame(fileName = c(),TCGA_Barcode = c())
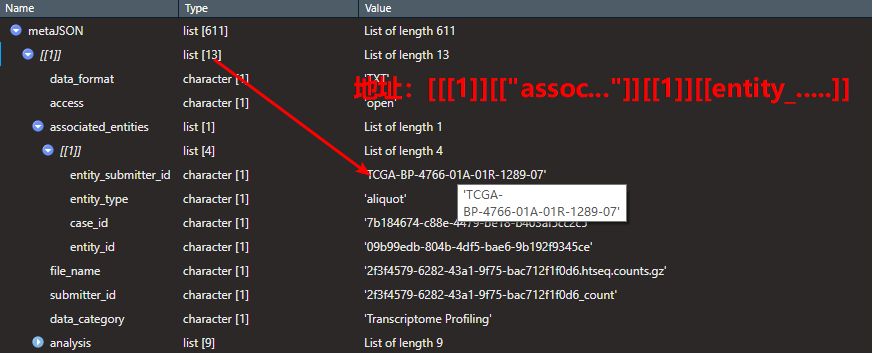
for (i in 1:length(metaJSON)) {
TCGA_barcode = metaJSON[[i]][["associated_entities"]][[1]][["entity_submitter_id"]]
fileName = metaJSON[[i]][["file_name"]]
jsonDataInfo = rbind(jsonDataInfo,data.frame(fileName = fileName,TCGA_barcode = TCGA_barcode))
}
rownames(jsonDataInfo) = jsonDataInfo[,1]
write.csv(jsonDataInfo,file = "./fileNameToTCGA_Borcode.csv")
#获取counts矩阵
fileNameToTCGA_Barcode = josnDataInfo[-1]
countsFilesName =list.files(path = "./test_Samplecounts",pattern = "*.counts")
allSampleCounts = data.frame()
for (file in countsFilesName) {
sampleCounts = read.table(paste0("./test_Samplecounts/",file),header = F)
rownames(sampleCounts) = sampleCounts[,1]
sampleCounts = sampleCounts["V2"]
#根据上面文件的对应关系命名列名
colnames(sampleCounts) = fileNameToTCGA_Barcode[paste0(file,".gz"),1]
if(dim(allSampleCounts)[1] == 0){
allSampleCounts = sampleCounts
}else{
allSampleCounts = cbind(allSampleCounts,sampleCounts)
}
}
write.csv(allSampleCounts,file = "./ENSG_TCGABarcode.csv")
ENSG_ID = substr(row.names(allSampleCounts),1,15)
rownames(allSampleCounts) = ENSG_ID
write.csv(allSampleCounts,file = "./ENSG_TCGABarcode_RowNameSubstr1_15.csv")
在转换行名中,由于counts文件有5行的注释信息,记得删除5行数据
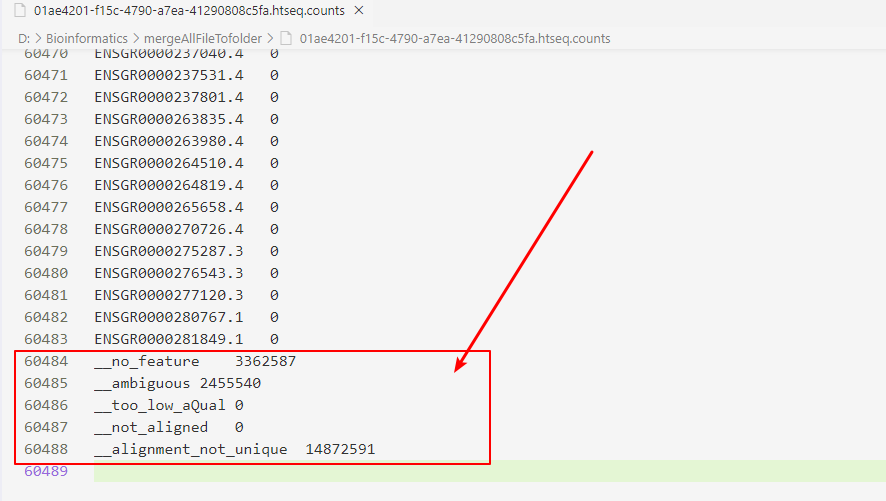
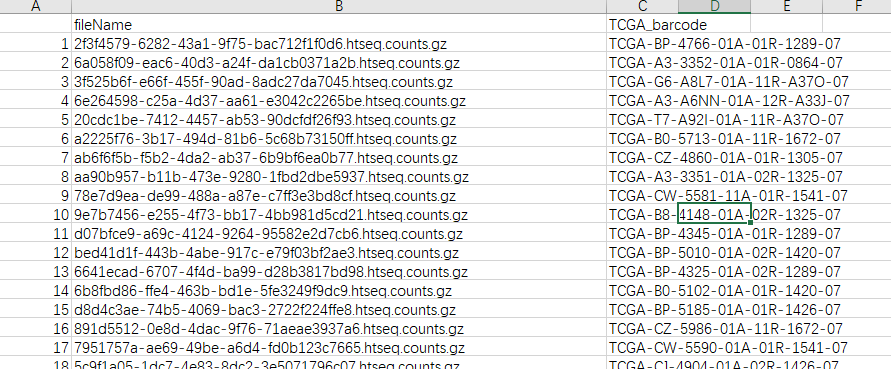
由于我们的文件名均是以01ae4201-f15c-4790-a7ea-41290808c5fa.htseq的方式存在,而我们需要的是TCGA编码信息,所以我们需要下载对应的JSON数据进行转换
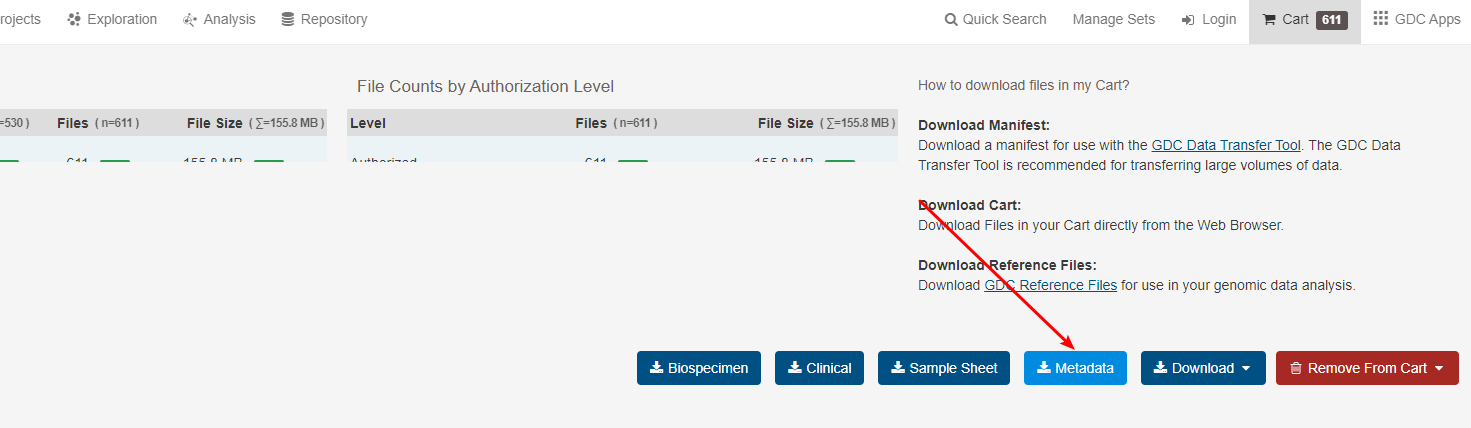
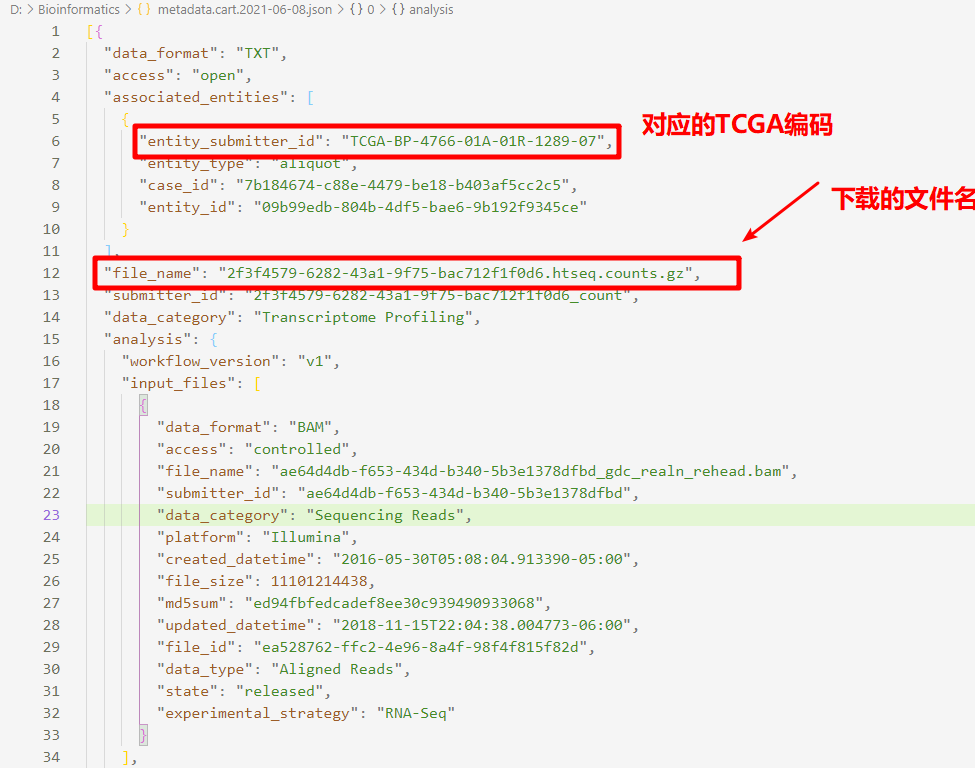
建立filename与TCGA编码的对应关系,然后根据对应关系替换掉对应的列名
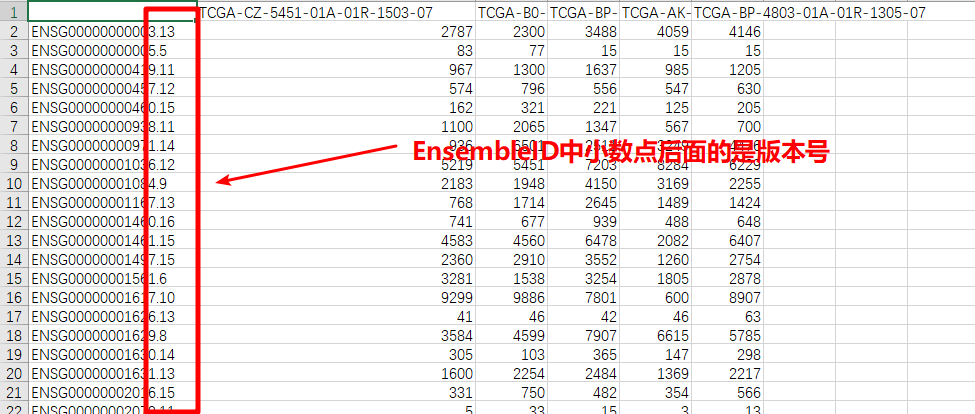
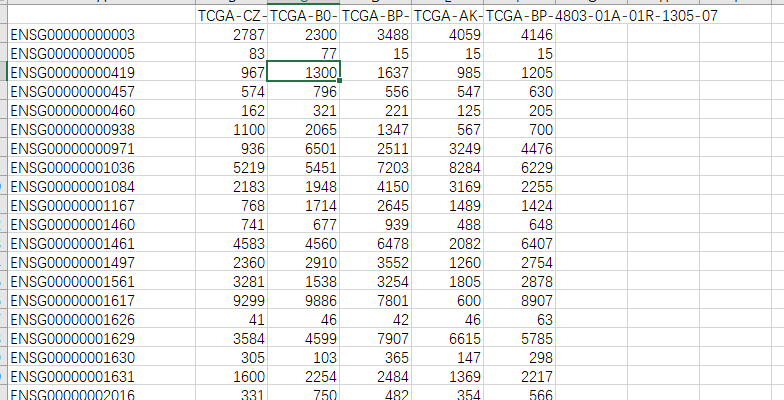
由于EnsembleID中含有版本号,在下一步的ID转换中我们的数据与EnsembleID-GeneName对照表中EnsembleID的版本号不对应,所以我们需要去掉这里的版本信息,同样的,在后面的对应关系中我们也需要去掉版本号。
2.3ID转换
在进行ID转换前,我们首先需要得到一张EnsembleID-GeneName对照表,我们有三种方式进行获取。
2.3.1EnsembleID-GeneName转换表获取
R包:GeoTcgaData
GeoTcgaData包中有一个id转换的函数:id_conversion_vector() , 它可以对人类的各种基因id进行转换。2019年9月第一次发布,目前这个包在CRAN的下载量为1633次,2020年2月20日我在github和CRAN上对它进行了更新,支持转换的id种类更多!同时它对基因id的转换率也很不错。
它支持的种类中就有EnsembleID,所以我们可以使用此方法来转换ID

3. 使用edgeR进行基因差异分析
R
#edgR差异分析
#time 2021.9.16 R4.0.1
#使用edgR包对数据进行差异分析
#输入:表达矩阵、分组信息
#输出:差异表达结果
edgRAnalyze <- function(path){
setwd(path)
if(any(grepl("BiocManager",installed.packages())) == FALSE){
install.packages("BiocManager")
}
library(BiocManager)
if(any(grepl("edgeR",installed.packages())) == FALSE){
BiocManager::install("edgeR")
BiocManager::install("limma")
}
library(edgeR)
library(limma)
#将第一列换成行名
DATA = read.csv("../中间文件输出/重复名列名为TCGA编号源文件.csv")
DATA = DATA[-1]
row.names(DATA) <- DATA[, 1]
DATA <- DATA[, -1]
#分组信息
group_list <- ifelse(as.numeric(substr(colnames(DATA),14,15))<10,"tumor","normal")
group_list <- factor(group_list,levels = c("normal","tumor"))
table(group_list)
dge <- DGEList(counts=DATA,group=group_list)
#差异分析
dge$samples$lib.size <- colSums(dge$counts)
dge <- calcNormFactors(dge)
design <- model.matrix(~0+group_list)
rownames(design)<-colnames(dge)
colnames(design)<-levels(group_list)
dge <- estimateGLMCommonDisp(dge,design)
dge <- estimateGLMTrendedDisp(dge, design)
dge <- estimateGLMTagwiseDisp(dge, design)
fit <- glmFit(dge, design)
fit2 <- glmLRT(fit, contrast=c(-1,1))
DEG2=topTags(fit2, n=nrow(DATA))
DEG2=as.data.frame(DEG2)
logFC_cutoff2 <- with(DEG2,mean(abs(logFC)) + 2*sd(abs(logFC)))
DEG2$change = as.factor(ifelse(DEG2$PValue < 0.05 & abs(DEG2$logFC) > logFC_cutoff2,ifelse(DEG2$logFC > logFC_cutoff2 ,'UP','DOWN'),'NOT'))
print("本次差异基因分析结果为")
print(table(DEG2$change))
edgeR_DEG <- DEG2
dir.create("../最终分析文件输出")
write.csv(edgeR_DEG,"../最终分析文件输出/差异分析结果.csv")
TRUE
}

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)