一劳永逸解决Hive执行insert命令调用MR任务报错问题
一劳永逸_解决Hive执行insert指令集调用MapReduce任务的报错问题
·
1. 问题描述
hive建表之后进行insert数据插入操作时,出现以下报错,主错误已上圈
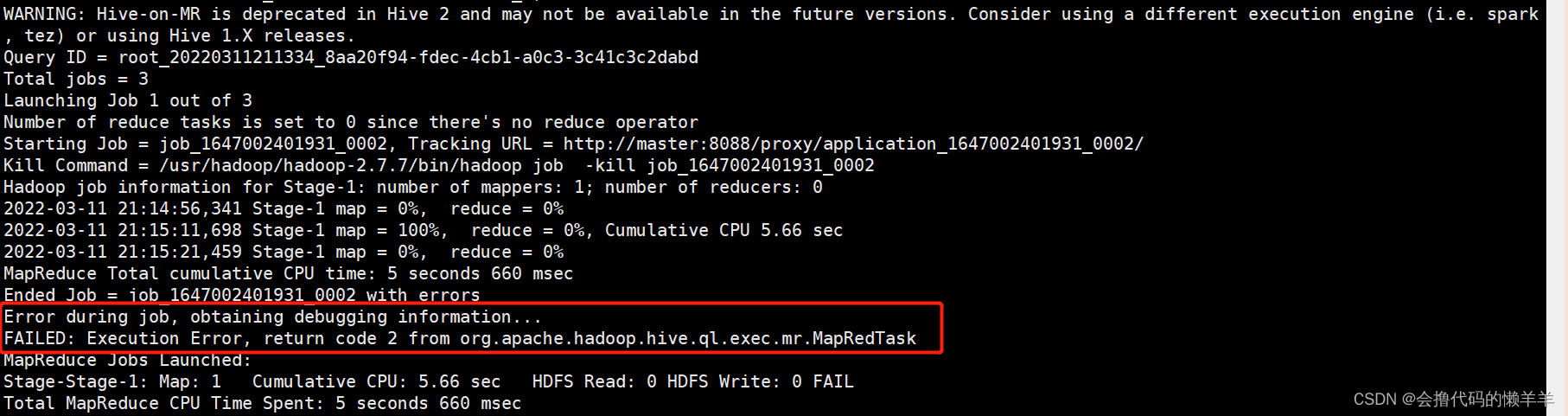
问题摘录
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20220311211334_8aa20f94-fdec-4cb1-a0c3-3c41c3c2dabd
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1647002401931_0002, Tracking URL = http://master:8088/proxy/application_1647002401931_0002/
Kill Command = /usr/hadoop/hadoop-2.7.7/bin/hadoop job -kill job_1647002401931_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2022-03-11 21:14:56,341 Stage-1 map = 0%, reduce = 0%
2022-03-11 21:15:11,698 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.66 sec
2022-03-11 21:15:21,459 Stage-1 map = 0%, reduce = 0%
MapReduce Total cumulative CPU time: 5 seconds 660 msec
Ended Job = job_1647002401931_0002 with errors
Error during job, obtaining debugging information...
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 5.66 sec HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 5 seconds 660 msec
2. 问题纠错
在生产环境中,使用hive时出现该报错信息的原因非常多,翻阅网上各类帖子也是五花八门,我在此做个摘录,仅供参考
- 经查发现发现/tmp/hadoop/.log提示java.lang.OutOfMemoryError: Java heap space,集群namenode节点或者hive等进程的jvm内存不足(已踩雷),jvm不够新job启动导致。
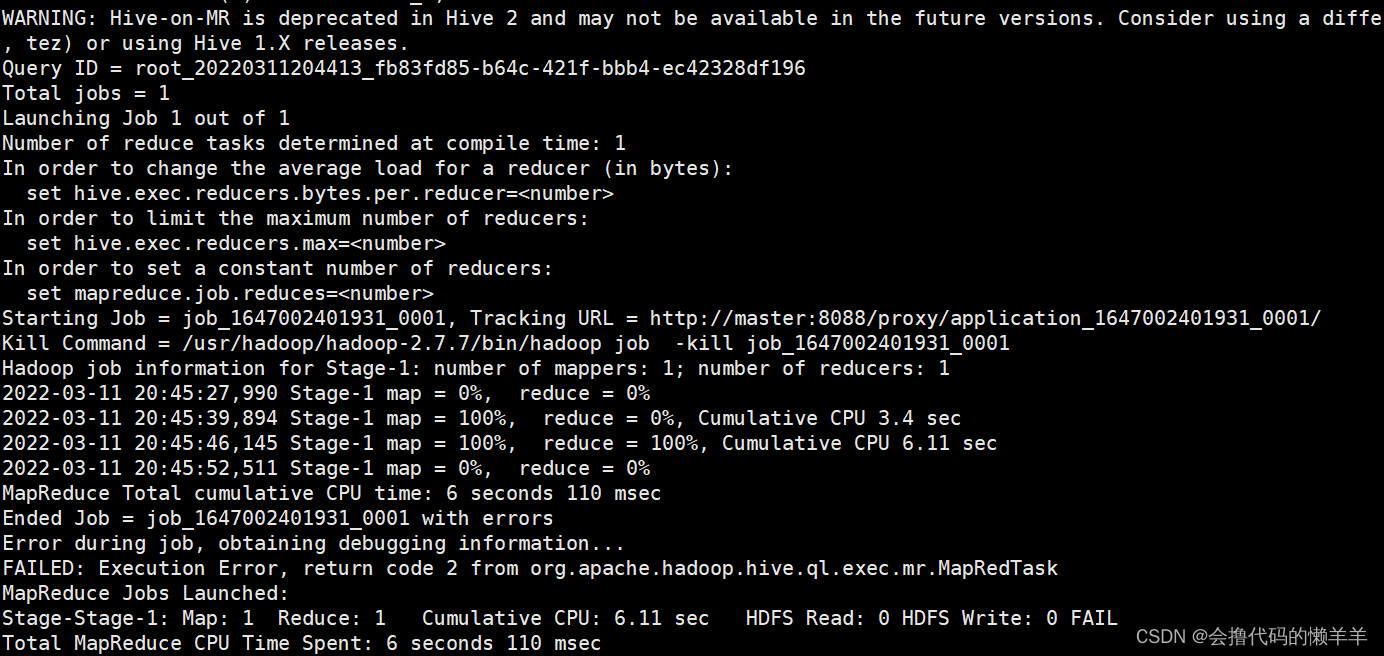
主错类摘录
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
调整后再测试 hive 发现即使内存空间给的足够大但执行
insert插入命令经过长时间加载后仍然无法得到预期结果,还时报如上所示的Error
3. 问题解决
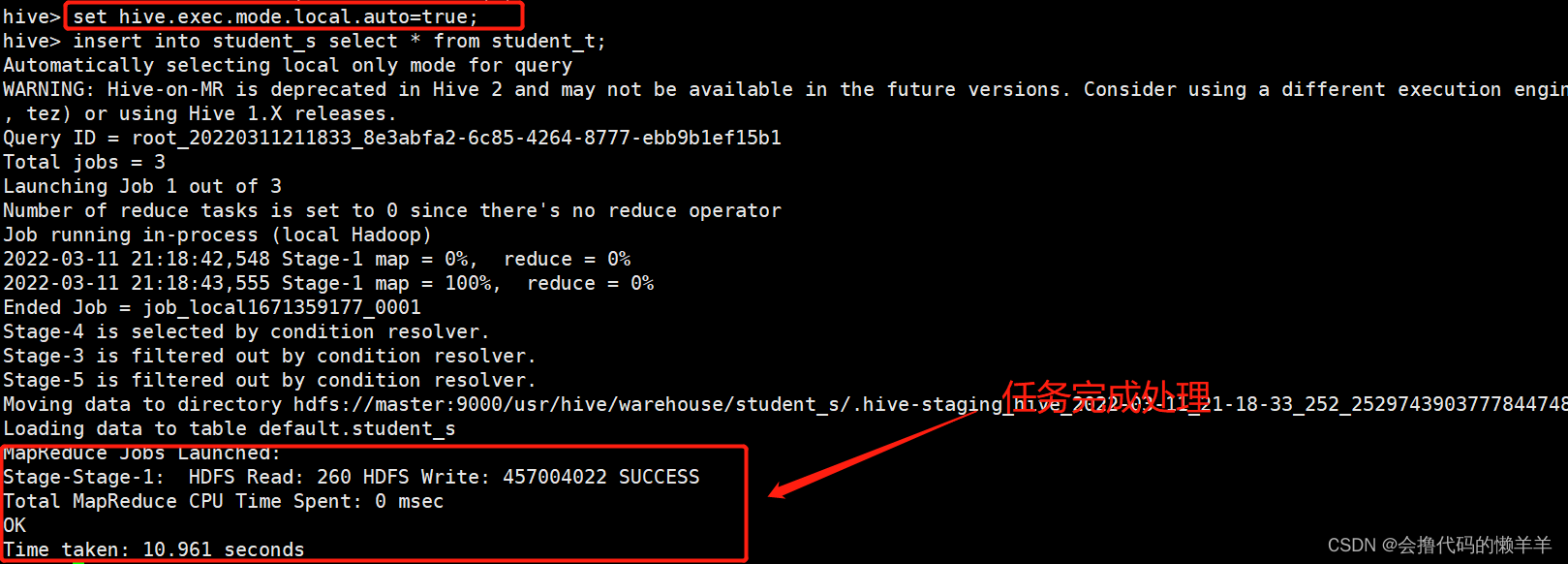
3.1 临时设置
将 hive 设置成本地模式来执行任务试试,命令如下
set hive.exec.mode.local.auto=true;
3.2 一劳永逸
修改在 hive 环境搭建过程中的主配置文件
hive-site.xml
# 本地测试时所用主机的hive配置文件目录如下,实际工作根据生产环境目录不同做修改
vim /usr/hive/apache-hive-2.3.4-bin/conf/hive-site.xml

重启hive,再次执行insert命令处理表,明显察觉处理效率嘎嘎快
了解更多知识请戳下:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)