
Hadoop入门(三):本地运行模式和完全分布模式,集群分发脚本、远程同步、集群分发
本地模式和完全分布模式
文档:hadoop文档
三种模式与区别

本地模式
基本步骤:

创建文件夹,进入文件夹,创建word.txt文件。编写内容:
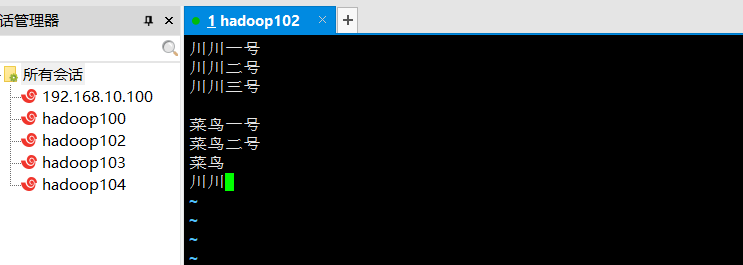
演示如下:

执行jar文件,只想wordcount案例,指定输入(wcinput/)输出(wcout)路径:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce examples-3.2.4.jar wordcount wcinput/ wcout
注意:输出路径名称是不存在的,如果存在就会冲突报错。比如wcout
执行成功:
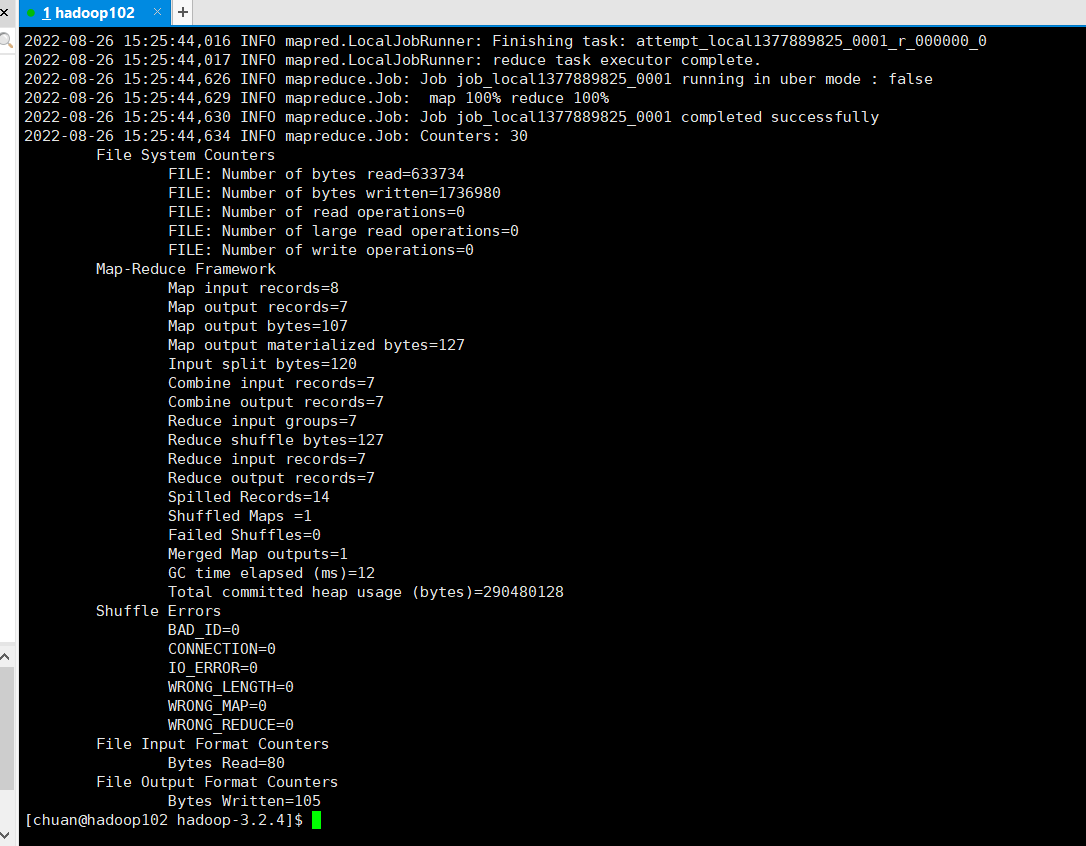
查看各个字符出现次数:
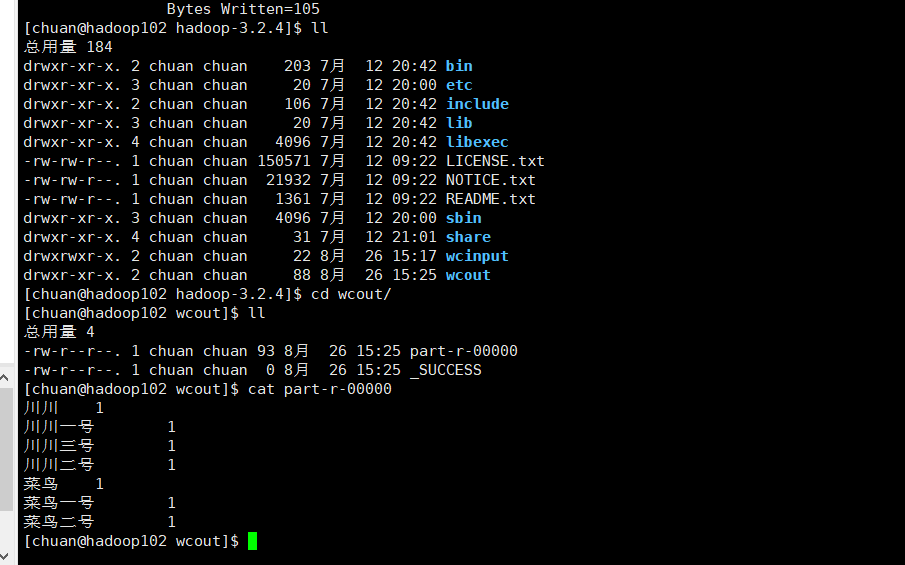
再重新编辑一下txt文件测试:
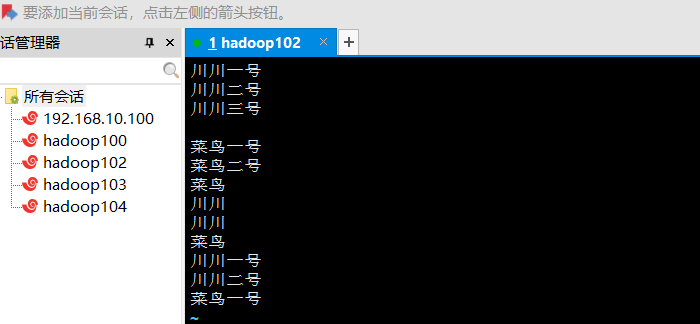
回到文件夹,执行:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar wordcount wcinput/ wcout2
执行完查看wcout2文件夹内容,可见计数很成功:
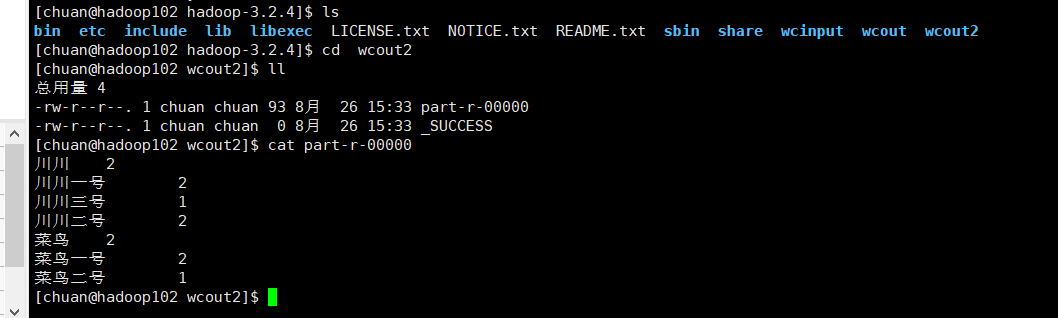
完全分布式运行模式(重点)
我们只是在hadoop102上配置好了相关环境,接着需要把jdk,hadoop克隆过去到另外两台,因此需要编写集群分发脚本

编写集群分发脚本(安全拷贝)

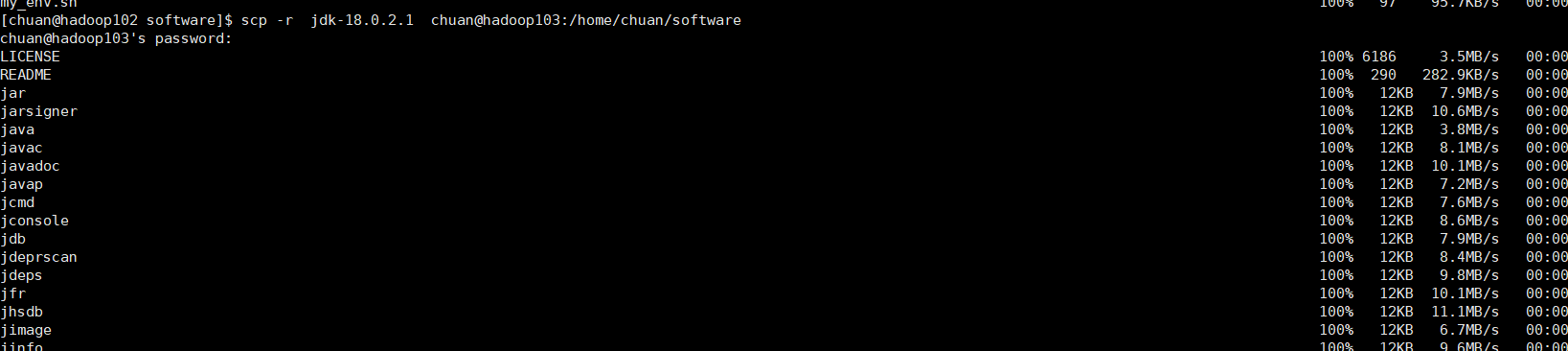
在 hadoop102 上,将hadoop102中software/jdk-18.0.2.1目录拷贝到hadoop103上
scp -r jdk-18.0.2.1 chuan@hadoop103:/home/chuan/software
执行如下:
去hadoop103查看一下:

上面的方法是把文件推送到另外的服务器,再来试试从别的服务器拉取到自己服务器。比如从hadoop102拉取hadoop文件到hadoop103上(./表示当前路径):
scp -r chuan@hadoop102:/home/chuan/software ./
执行成功:

hadoop103查看下目录:

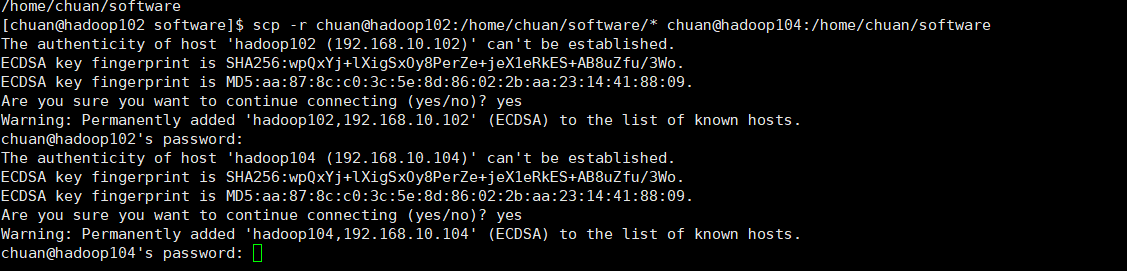
此时已经实现hadoop102到hadoop103转移了。同理处理hadoop104,这里直接一次性把文件夹全部传送过去,不一个个传送了(记得hadoop104也要创建software文件夹,前面的演示我没有创建):
scp -r chuan@hadoop102:/home/chuan/software/* chuan@hadoop104:/home/chuan/software
如下:

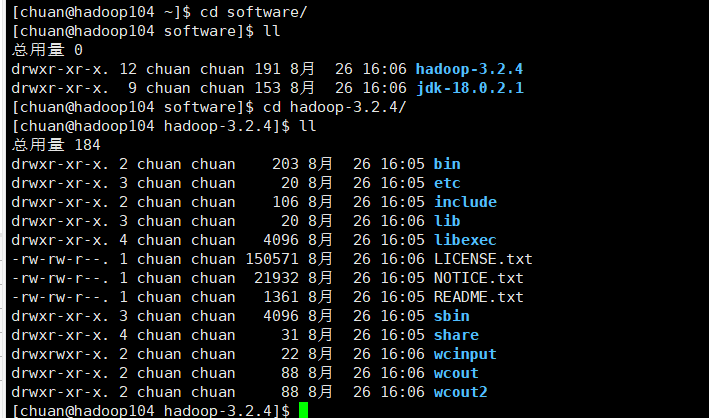
到hadoop104查看下:
最后记得soursce一下jdk和hadoop

远程同步
如果只是个别文件变化,不需要全部拷贝,使用rsync远程同步即可。
rsync,主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp,是把所有文件都复制过去。
语法:
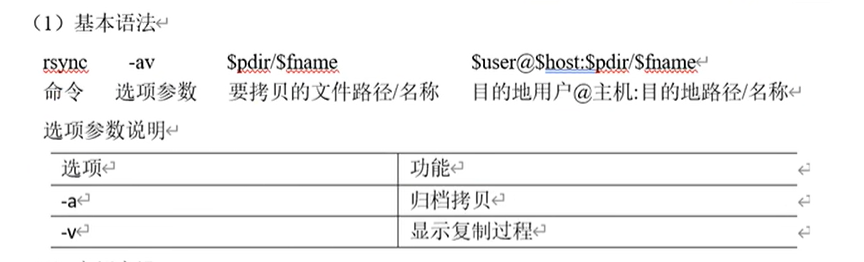
比如把hadoop102上的wcout2删除:

现在希望把hadoop102上的hadoop同步到hadoop103上:
rsync -av hadoop-3.2.4/ chuan@hadoop103:/home/chuan/software/hadoop-3.2.4/
如下:

验证hadoop103上已经没有了:
集群同步分发
基于同步功能,希望只要做一个更改,就可以其它几个hadoop服务器全部实现同步。
脚本实现:
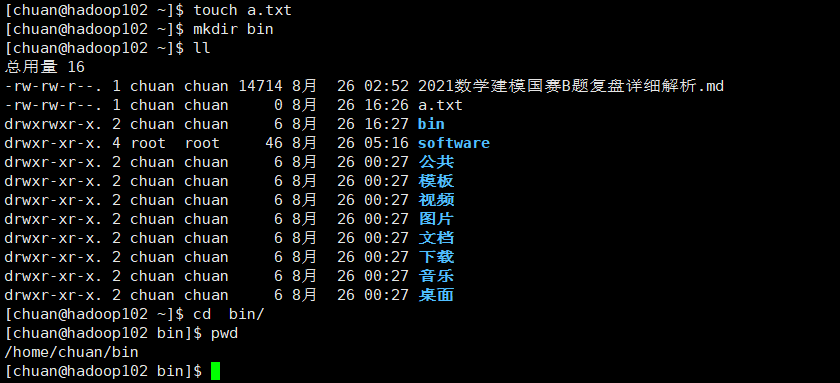
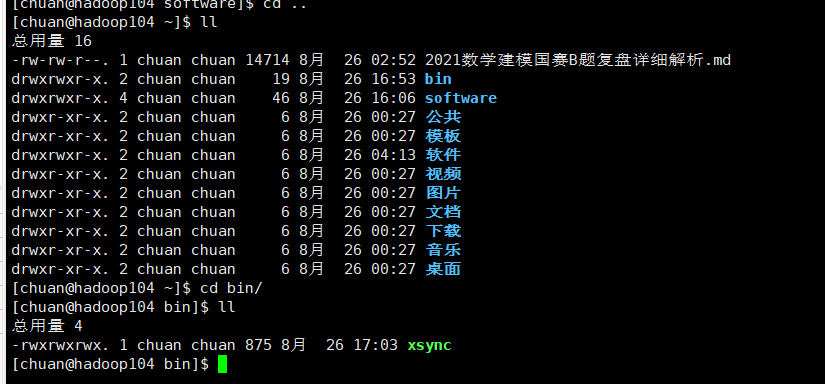
创建xsync

xsync中添加内容,内容添加后记得添加权限:
#!/bin/bash
#1. 判断参数个数
# 判断参数是否小于1
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
# 对102,103,104都进行分发
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
# 如果不存在
else
echo $file does not exists!
fi
done
done
测试:
xsync /home/chuan/bin
连续输入几次密码即可:
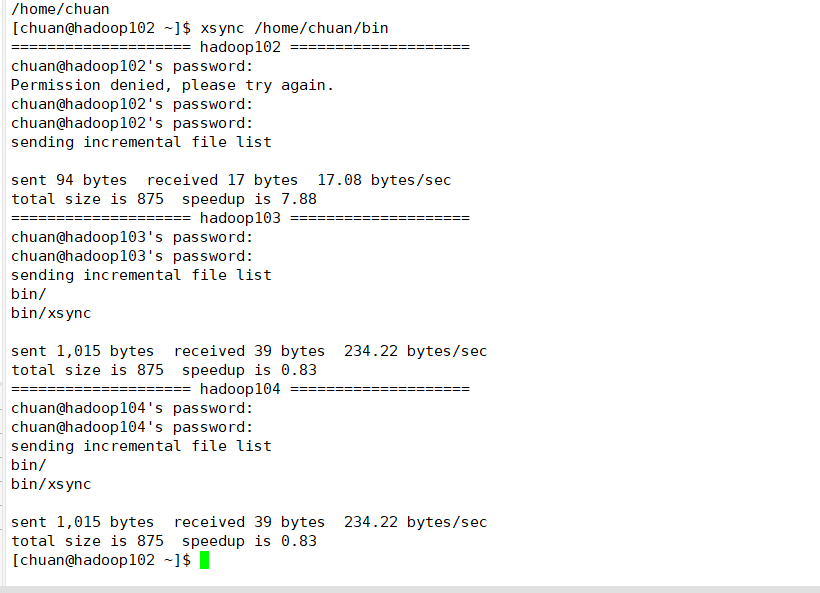
验证传输成功:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)