谷粒商城高级篇
谷粒商城项目详细总结,结合ES,Redis,分布式事务,消息队列,还整合了支付宝支付,微博认证登录,解决分布式开发时的多种问题。
谷粒商城高级篇
内容目录:
文章目录
- 谷粒商城高级篇
- 一、 ElasticSearch
- 二、商城业务
- 三、性能压力测试&性能优化
- 四、缓存与分布式锁
- 五、异步&线程池
- 六、认证服务
- 七、购物车
- 八、消息队列 Message Queue
- 九、订单服务
- 十、分布式事务
- 十一、支付&内网穿透
- 十二、秒杀服务
一、 ElasticSearch
1.1 ElasticSerch简介:
全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它 Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的 接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。 REST API:天然的跨平台。
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
官方中文:https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html
社区中文: https://es.xiaoleilu.com/index.html http://doc.codingdict.com/elasticsearch/0
1.2 相关概念
1.2.1 Index(索引)
动词,相当于 MySQL 中的 insert; 名词,相当于 MySQL 中的 Database
1.2.2 Type(类型)
在 Index(索引)中,可以定义一个或多个类型。 类似于 MySQL 中的 Table;每一种类型的数据放在一起;
1.2.3 Document(文档)
保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格 式的,Document t 就像是 MySQL 中的某个 Table 里面的内容。
1.2.4 倒排索引机制
倒排索引源于实际应用中需要根据属性的值来查找记录,lucene是基于倒排索引实现的。
简单来说就是根据属性值获取索引值。
1.3 安装
使用docker安装,同时需要安装ElasticSearch和Kibana两个镜像。
更多详情请参考官方文档。
ElasticSearch符合RestFul风格
1.4 基本操作
参考相关文档
就像是使用RestFul的风格用url操纵数据库。
1.5 结合JAVA使用
1.5.1 引入相关依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
1.5.2 编写配置类
//排除引入common工程的数据源依赖
//@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("101.200.45.111", 9200, "http")));//需要填写es所在服务器的域名以及端口号
return client;
}
}
1.5.3 创建索引(添加数据)
//存储数据到es(添加更新二合一)
@Test
public void addIndex() throws Exception{
//(创建索引的请求指定索引名称(users))
IndexRequest indexRequest = new IndexRequest("users");
//指定id
indexRequest.id("1");
//这种方法也可以 直接写json字符串
// indexRequest.source("username","zhansan","age",18,"gender","男");
User user =new User();
user.setUsername("战三");
user.setGender("f");
user.setAge(123);
//将对象解析为JSON字符串
String s = JSON.toJSONString(user);
indexRequest.source(s,XContentType.JSON);
//保存后拿到响应结果
IndexResponse index = restHighLevelClient.index(indexRequest,COMMON_OPTIONS);
System.out.println(index);
}
@Data
class User{
private String username;
private String gender;
private Integer age;
}
1.5.4 查询
@Test
public void searchData() throws Exception {
//1.创建索引请求
SearchRequest searchRequest = new SearchRequest();
//2.指定索引
searchRequest.indices("xxx");
//3.指定DSL 检索条件
//SearchSourceBuilder sourceBuilder(里面封装的查询条件)
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3.1构建检索条件
// searchSourceBuilder.query();
// searchSourceBuilder.from();
// searchSourceBuilder.size();
// searchSourceBuilder.aggregation();
searchSourceBuilder.query(QueryBuilders.matchQuery("field", "xxx"));
//创建聚合条件
//1.查看值分布聚合
TermsAggregationBuilder agg1 = AggregationBuilders.terms("Aggname").field("AggField").size(10);
//将聚合条件加入到查询条件中
searchSourceBuilder.aggregation(agg1);
searchRequest.source(searchSourceBuilder);
//4.执行检索 拿到数据
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, ElasticSearchConfig.COMMON_OPTIONS);
//5.分析结果(Json串)
//获取所有查到的数据
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String string = hit.getSourceAsString();
XXClass xxClass = JSON.parseObject(string,XXClass.class);
System.out.println("xxClass"+xxClass);
}
// }
//获取检索到的分析信息
Aggregations aggregations = searchResponse.getAggregations();
Terms aggName = aggregations.get("AggName");
for (Terms.Bucket bucket : aggName.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄"+keyAsString+bucket.getDocCount());
}
}
1.6 结合商城业务
1.6.1 创建微服务gulimall-search
相关的配置文件:
application.properties
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.application.name=gulimall-search
server.port=12000
1.6.2 编写配置类
@Configuration
public class GulimallElasticSearchConfig {
//配置es请求OPTIONS
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
//配置es连接
@Bean
RestHighLevelClient client() {
RestClientBuilder builder = RestClient.builder(new HttpHost("192.168.190.131", 9200, "http"));
return new RestHighLevelClient(builder);
}
}
1.6.3 Controller层
@RequestMapping("/search")
@RestController
@Slf4j
public class ElasticSaveController {
@Autowired
ProductSaveService productSaveService;
// 上架商品
@PostMapping("/product")
public R productStatusUp(@RequestBody List<SkuEsModel> skuEsModels) {
boolean flag = false;
try {
flag = productSaveService.productStatusUp(skuEsModels);
} catch (IOException e) {
log.error("ElasticSaveController商品上架错误: {}", e);
return R.error(BizCodeEnume.PRODUCT_UP_EXCEPTION.getCode(), BizCodeEnume.PRODUCT_UP_EXCEPTION.getMsg());
}
if (flag) {
return R.ok();
} else {
return R.error(BizCodeEnume.PRODUCT_UP_EXCEPTION.getCode(), BizCodeEnume.PRODUCT_UP_EXCEPTION.getMsg());
}
}
}
1.6.4 Service层
注: 使用RestHighLevelClient进行操作
@Slf4j
@Service
public class ProductSaveServiceImpl implements ProductSaveService {
@Autowired
RestHighLevelClient restHighLevelClient;
@Override
public boolean productStatusUp(List<SkuEsModel> skuEsModels) throws IOException {
// 保存到es中
//1、给es中建立索引。product,建立好映射关系。
//2、给es中保存这些数据
//BulkRequest bulkRequest, RequestOptions options
BulkRequest bulkRequest = new BulkRequest();
for (SkuEsModel model : skuEsModels) {
// 构造保存请求
IndexRequest indexRequest = new IndexRequest(EsConstant.PRODUCT_INDEX);
//指定数据id
indexRequest.id(model.getSkuId().toString());
//将要保存的数据对象转换为JSON格式
String s = JSON.toJSONString(model);
//插入数据 并指明数据类型为JSON
indexRequest.source(s, XContentType.JSON);
//将保存请求(indexRequest)添加到批量保存请求中
bulkRequest.add(indexRequest);
}
//创建批量执行对象
//使用restHighLevelClient客户端进行保存 拿到响应结果
//两个参数 第一个是批量保存的请求 第二个是请求OPTIONS
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
//分析保存结果
boolean b = bulk.hasFailures();
List<String> collect = Arrays.stream(bulk.getItems()).map(item -> {
return item.getId();
}).collect(Collectors.toList());
log.info("商品上架成功: {}", collect);
//返回布尔类型的数据,如果是true就是有错误了,返回false就是没有错误
return b;
}
}
二、商城业务
2.1 使用Nginx反向代理
2.1.1 Nginx和gateway的区别
nginx:
C语言编写,采用服务器实现负载均衡,高性能的HTTP和反向代理web服务器。
Gateway:
是springcloud自己研制的微服务网关,是基于Spring5构建,能够实现响应式非阻塞式的Api,支持长连接。
支持异步。
功能更强大,内部实现了限流、负载均衡等,扩展性也更强。Spring Cloud Gateway明确的区分了 Router 和 Filter,并且一个很大的特点是内置了非常多的开箱即用功能,并且都可以通过 SpringBoot 配置或者手工编码链式调用来使用。
依赖于spring-webflux,仅适合于Spring Cloud套件。
代码复杂,注释少。
区别:
Nginx适合于服务器端负载均衡,Zuul和gateway 是本地负载均衡,适合微服务中实现网关。Spring Cloud Gateway 天然适合Spring Cloud 生态。
模拟测试图:
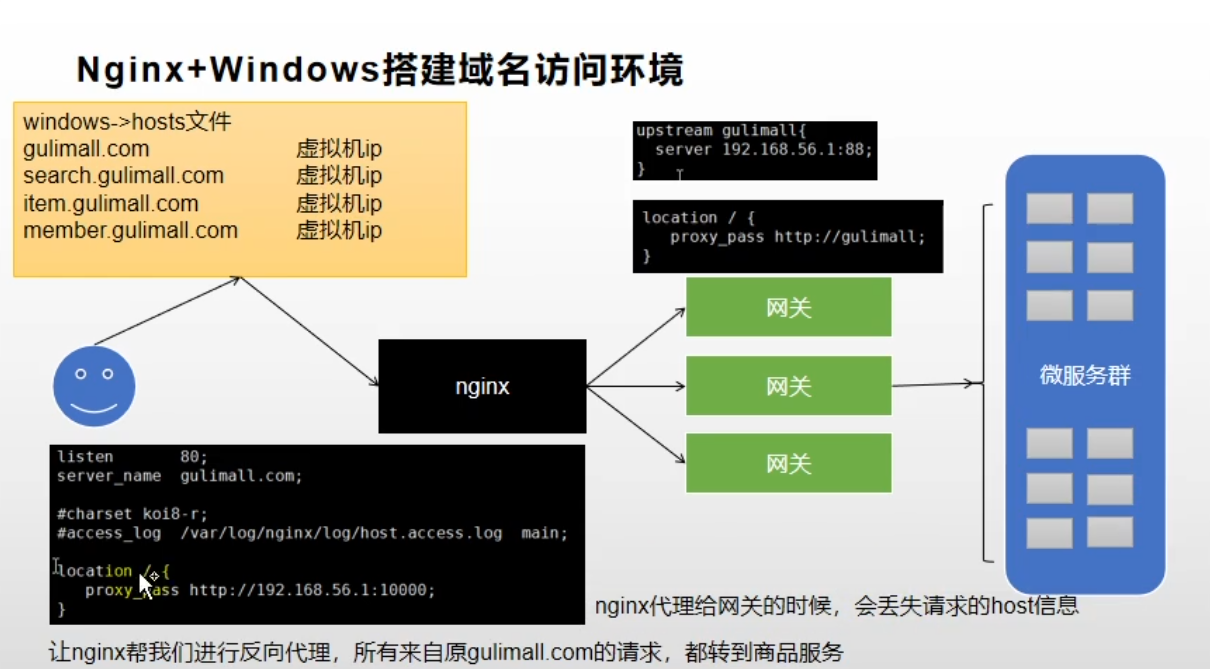
在主机的host文件配置gulimall.com与虚拟机ip绑定。
2.1.2 流程描述
通过浏览器访问gulimall.com会访问到虚拟机中,由虚拟机的nginx进行处理,nginx在将请求转发给我们的网关(gulimall-gateway),然后我们在网关中配置路由规则,最终将我们的请求转到gulimall-product服务。
2.1.3 Nginx的坑
由Nginx进行负载均衡会出现丢失请求头的问题,因此我们需要在nginx的相关配置文件中进行配置,加入我们的请求头信息。
三、性能压力测试&性能优化
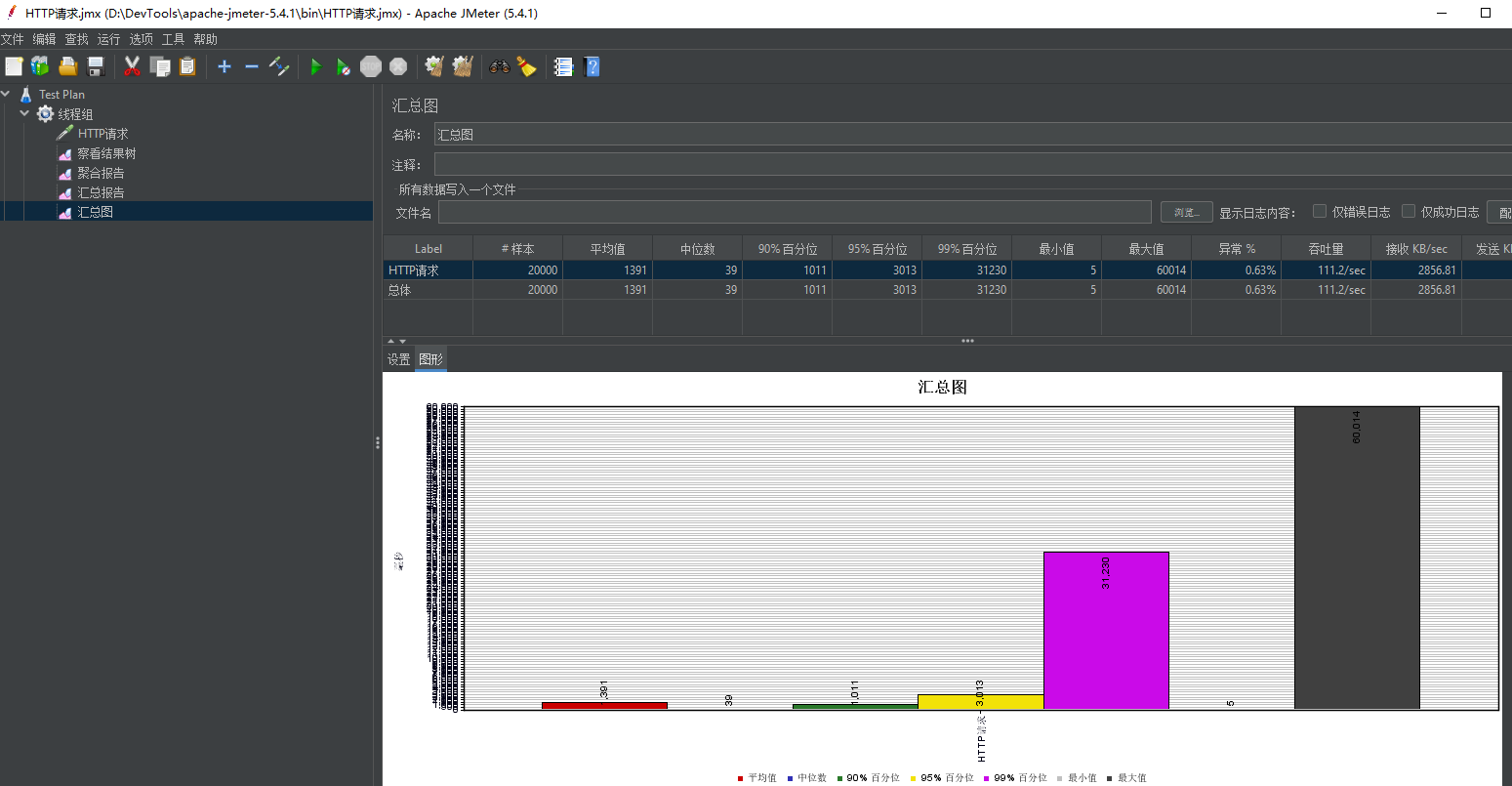
3.1 Jmeter的使用
1、官网现在
2、点击jmeter.bat使用
使用截图:
3.2 JVM优化
可使用使用优化工具 JVISUALVM 测试优化情况。
cmd窗口输入命令: jvisualvm 使用
优化的点:
- JVM内存
- 视图渲染
- 数据库
3.3 Nginx动静分离
将静态的页面,css,js等放到nginx中,并在nginx中设置路径,实现动静分离。
每次访问主页时静态的页面由Nginx提供,而数据由本地服务提供。
四、缓存与分布式锁
4.1 缓存使用
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而 db 承担数据落盘工作
哪些数据适合放入缓存?
- 即时性、数据一致性要求不高的
- 访问量大且更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率 来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。
流程图:
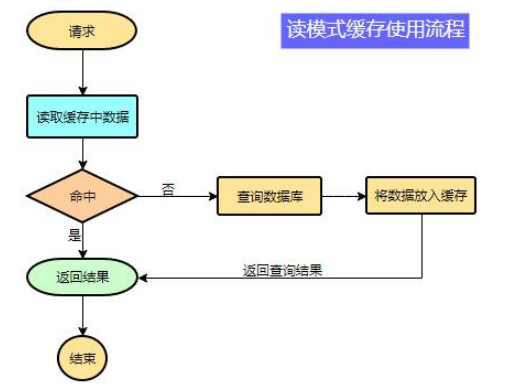
不需要强一致性,需要最终一致性
注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。
4.2 整合 redis
4.2.1 环境配置
1)引入依赖
<!--引入redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2)在配置文件中配置redis的ip地址和端口号(可配可不配,因为默认端口号就是6379)
4.2.2 Redis的使用
Redis的配置类为我们配置好了两种bean
RedisTemplate和StringRedisTemplate
@Configuration
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
通过注入IOC容器的方式进行使用。
4.2.3 测试使用
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void testStringRedisTemplate() {
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
ops.set("hello", "world_" + UUID.randomUUID().toString());
String hello = ops.get("hello");
System.out.println("之前存放的数据: " + hello);
}
实际业务使用:
//TODO 产生对外内存溢出: OutOfDirectMemoryError
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
//先判断Redis中是否有数据
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
// 缓存中没有,向数据库中获取数据
Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDb();
// 获取到数据后,要想redis缓存中存放获取到的数据
// 因为redis中key和value都是字符串,所有要想向redis中存放数据就要先将数据对象转化成为Json的格式,之后在保存到Redis中
String value = JSON.toJSONString(catalogJsonFromDb);
redisTemplate.opsForValue().set("catalogJSON", value);
return catalogJsonFromDb;
}
//redis中有对应的数据时的逻辑
// 需要从redis中获取数据,并将json数据转换为对象,然后再返回
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
4.2.4产生的BUG

springboot2.0使用lettuce会堆外内存溢出的bug,所以要暂时使用另外一个操作redis的客户端jedis,但是我们无论使用Jedis还是Lettuce都使用redisTemplate,这是因为springboot对这两个操作redis的客户端进行了封装。
4.2.5 高并发下缓存失效问题
(1) 缓存穿透
缓存穿透最直白的意思就是,我们的业务系统在接收到请求时在缓存中并没有查到数据,从而穿透到了后端数据库里面查数据的过程。
或是指外来大量访问去查询缓存中不存在的值,最终导致需要不断的去查数据库,使数据库压力变大,最终导致程序异常。
- 缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次 请求都要到存储层去查询,失去了缓存的意义。
- 在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决:
缓存空结果、并且设置短的过期时间。
(2) 缓存雪崩
简要来讲是指缓存中的key大面积失效,同时有大量的请求过来获取数据,去查看缓存,但是缓存中的数据已经失效,就回去访问数据库,最终导致数据库压力变大。
- 缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失 效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决:
原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的 重复率就会降低,就很难引发集体失效的事件
(3) 缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据,当一个key非常热点(类似于爆款),在不停的扛着大并发,大并发集中对这一个点进行访问;当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
- 对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问, 是一种非常“热点”的数据。
- 这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所 有对这个 key 的数据查询都落到 db,我们称为缓存击穿
解决:
加互斥锁
① 使用本地锁(sychronized)单体应用
当大量请求全都访问这个数据时,发现缓存中没有,就会访问数据库进行查询,将访问数据库操作的方法使用sychronized加锁,那么这些请求就会排队访问。第一个请求执行完同步操作后会释放锁, 在释放锁之前会将查询到的数据存入缓存中,其他请求进入同步操作会先判断缓存中是否有相应的数据,就避免了多次查库的问题。
//TODO 产生对外内存溢出: OutOfDirectMemoryError
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
//先判断Redis中是否有数据
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
// 缓存中没有,向数据库中获取数据
//调用下面的方法
Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDb();
return catalogJsonFromDb;
}
//redis中有对应的数据时的逻辑
// 需要从redis中获取数据,并将json数据转换为对象,然后再返回
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
//从数据库查询并封装数据
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDb() {
synchronized (this) {
//将数据库的查询变为一次
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 查出所有一级分类
List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);
// 封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
.................封装数据操作..................
}));
// 获取到数据后,要想redis缓存中存放获取到的数据
// 因为redis中key和value都是字符串,所有要想向redis中存放数据就要先将数据对象转化成为Json的格式,之后在保存到Redis中
String value = JSON.toJSONString(parent_cid);
redisTemplate.opsForValue().set("catalogJSON", value);
return parent_cid;
}
}
但是使用本地锁的方式在分布式的情景下就会出现问题:每一个服务都是锁住了当前进程,无法锁住其他进程。
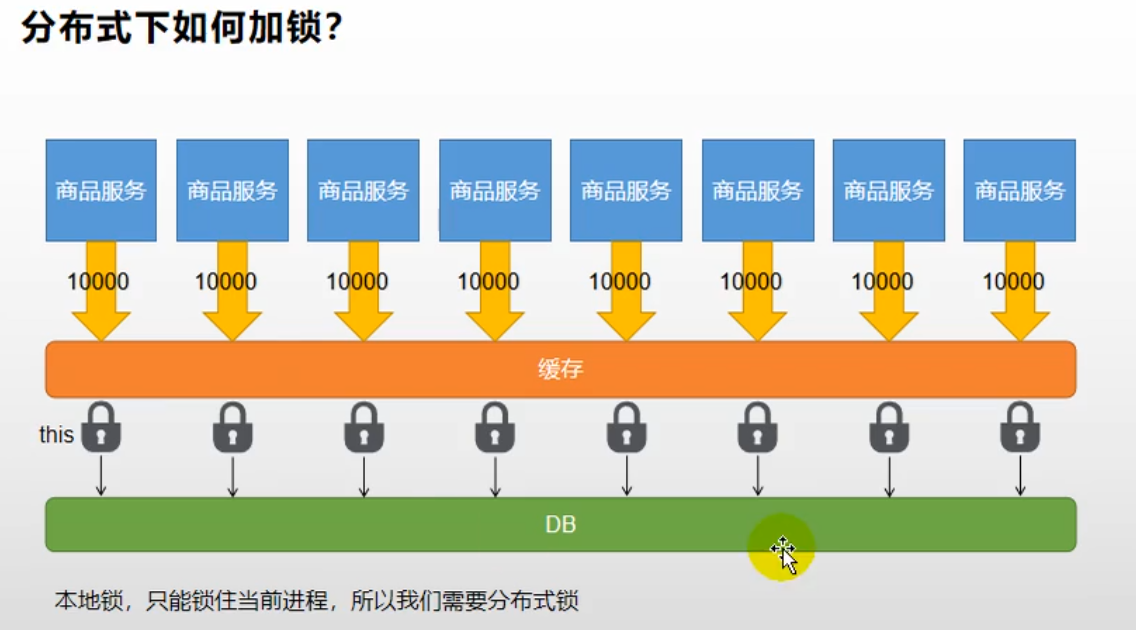
4.3 分布式锁
4.3.1 初级
原理是使用redis中的setnx命令,根据官方文档 :
Redis Setnx( SET if Not eXists )命令在指定的 key 不存在时,为 key 设置指定的值,这种情况下等同 SET 命令。当 key存在时,什么也不做。
返回值
整数:
1如果key被设置了0如果key没有被设置
而在Java中对应方法是:
public Boolean setIfAbsent(K key, V value) {
byte[] rawKey = this.rawKey(key);
byte[] rawValue = this.rawValue(value);
return (Boolean)this.execute((connection) -> {
return connection.setNX(rawKey, rawValue);
}, true);
}
// 此方法可以设置key的过期时间以及时间类型
public Boolean setIfAbsent(K key, V value, long timeout, TimeUnit unit) {
byte[] rawKey = this.rawKey(key);
byte[] rawValue = this.rawValue(value);
Expiration expiration = Expiration.from(timeout, unit);
return (Boolean)this.execute((connection) -> {
return connection.set(rawKey, rawValue, expiration, SetOption.ifAbsent());
}, true);
}
最终形态:
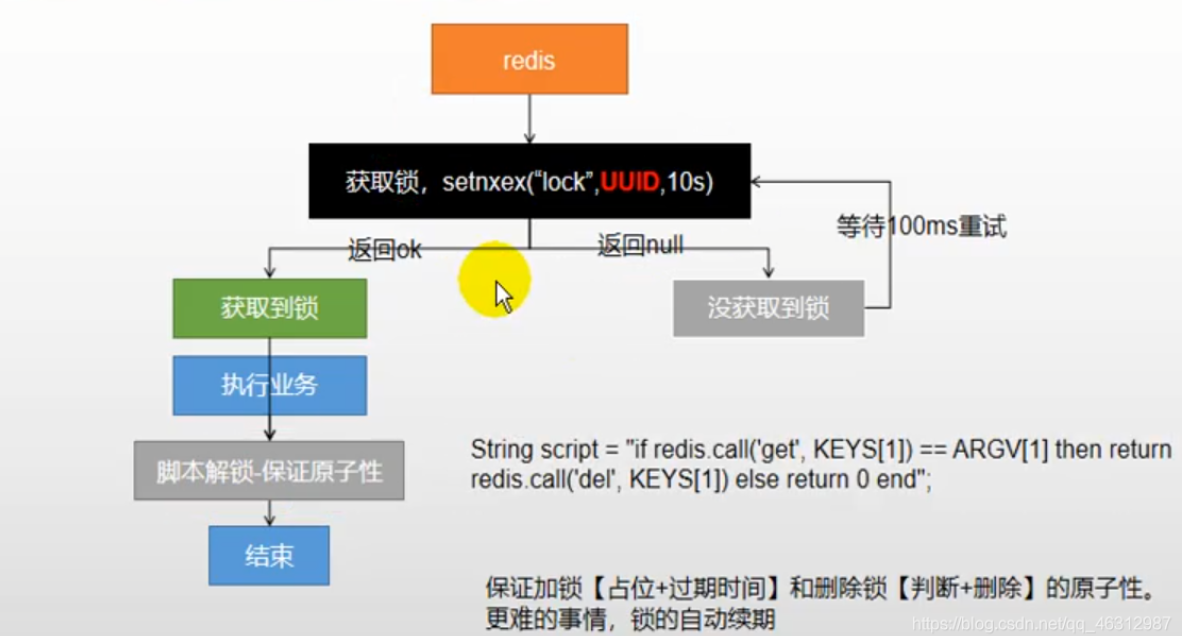
4.3.2 高级
(1) Redisson简介&集合
1)Redisson相对于Jedis来讲,是一个功能更加强大的Redis客户端。
2)使用Redisson进行加锁的操作与JUC包下的API相近,使用也可以参考JUC相关文档。
① 引入依赖
<!--使用 redssion 作为分布式锁-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>
② 配置Redssion
更多详情参考官方文档
编写配置类
@Configuration
public class MyRedissonConfig {
/**
* 所有对Redisson的使用都是通过RedissonClient对象
* @return
*/
//配置指定方式销毁
@Bean(destroyMethod = "shutdown")
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.190.131:6379");
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}
}
③ Redisson-lock锁测试
在配置了RedissonClient 就可以操作RedissonClient的实例进行各种加锁操作。
1)测试(看门狗原理)
@ResponseBody
@GetMapping("/hello")
public String hello(){
//1.获取一把锁,只要锁的名字一样,就是同一把锁
RLock lock = redissonClient.getLock("my-lock");
//2.加锁
//此方法不指定过期时间
lock.lock();//阻塞式等待,前一个线程不执行完,所锁就不会释放
//1)锁的自动续期 测试发现如果某一个业务超长,运行期间会自动给锁续上30s,不用担心业务时间长锁因为过期被删掉的问题
//2)加锁的业务只要运行完成,就不会给锁续期,即使不手动解锁,锁也会在30s后自动删除,所以在测试中将第一个请求获取锁之后没有解锁就将服务关闭,第二个线程依然可以获取锁
//**********************************************************************************
//lock.lock(10,TimeUnit.SECONDS);指定锁的超时时间
//问题:Lock.lock(1,fimeUnit.SECONDS);在锁时间到了以后,不会自动续期。
//1、如果我们传递了锁的超时时间,就发送给redis执行脚本,进行占锁,默认超时就是我们指定的时间
//2、如果我们未指定锁的超时时间,就使用30 * 100【LockWatchdogTimeout看门狗的默认时间】;
//只要占锁成功,就会启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10s都会自
//internalLockLeaseTime【看门狗时间】/ 3,10s
//最佳实战
// lock.Lock(30, TimeUnit.SECONDS);省掉了整个续期操作,指定过期时间尽量比业务时间长
//**********************************************************************************
try {
System.out.println("加锁成功 执行业务"+Thread.currentThread().getId());
Thread.sleep(5000);
}catch (Exception e){
}finally {
//3.解锁
System.out.println("释放锁"+Thread.currentThread().getId());
lock.unlock();
}
return "hello";
}
④ 读锁和写锁
为了保证一定能读取到数据,修改期间,写锁是一个排它锁(互斥锁、独享锁),而读锁是一个共享锁。
写锁没有释放就必须等待
| 读写操作 | 效果说明 |
|---|---|
| 读 + 读 | 相当于无锁,并发读,只会在Redis中记录好,所有当前的读锁,他们都或同时加锁成功。 |
| 写 + 读 | 等待写锁释放 |
| 写 + 写 | 阻塞方式 |
| 读 + 写 | 读操作先上锁,写操作也要等待 |
总结:只要有写的存在,都需要等待。
测试代码:
@GetMapping("/write")
@ResponseBody
public String write() {
RReadWriteLock lock = redissonClient.getReadWriteLock("rw-lock");
String s = "";
RLock rLock = lock.writeLock();
try {
rLock.lock();
System.out.println("写锁加锁成功。。。" + Thread.currentThread().getName());
s = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue", s);
Thread.sleep(30000);
} catch (Exception e) {
}finally {
rLock.unlock();
System.out.println("写锁释放..." + Thread.currentThread().getName());
}
return s;
}
@GetMapping("/read")
@ResponseBody
public String read() {
RReadWriteLock lock = redissonClient.getReadWriteLock("rw-lock");
String s = "";
RLock rLock = lock.readLock();
try {
rLock.lock();
System.out.println("读锁加锁成功..." + Thread.currentThread().getName());
s = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue", s);
Thread.sleep(30000);
} catch (Exception e) {
}finally {
rLock.unlock();
System.out.println("读锁释放..." + Thread.currentThread().getName());
}
return s;
}
4.4 缓存数据一致性
保证一致性模式
4.4.1 双写模式
先将数据写入数据库,然后再修改缓存。
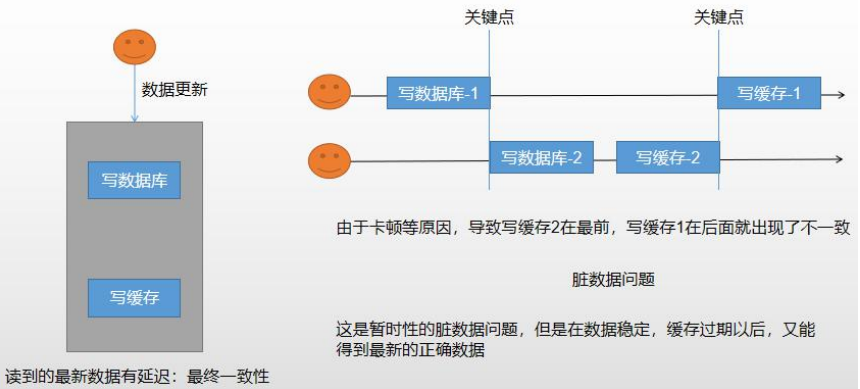
4.4.2 失效模式
只要更新数据库数据,在更新完成后就删除缓存中的数据,使缓存失效。
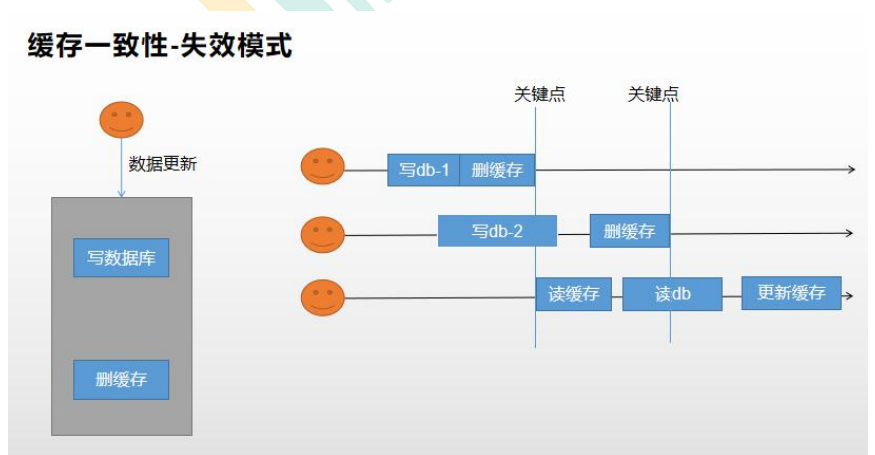
但是两种都会产出数据不一致的问题。
4.4.3 改进方法
(1)分布式读写锁
分布式读写锁。读数据等待写数据整个操作完成
(2)使用alibaba的cananl
cananl会记录数据库的更新,会将变动的信息记录到cananl中,然后对redis进行更新。
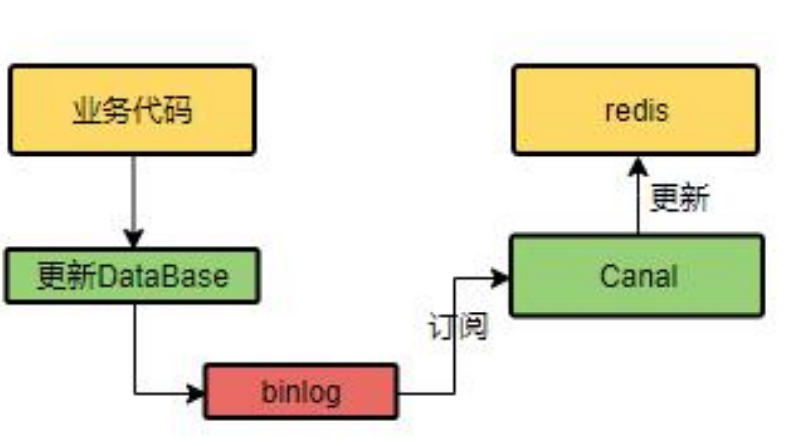
4.5 SpringCache
总结之前的业务逻辑:
在进行读取数据的操作的时候,需要先查看缓存中是否有我们想要的数据,如果有数据就直接从缓存中获取数据返回,没有,就要查询数据库,然后向缓存中放置一份,再返回。
进行写操作和读操作的时候需要设置读写锁,但是每个方法都要我们手动操作会,这样十分麻烦,所以要引入SpringCache,SpringCache已经为我们封装好了相关的操作。
4.5.1 简介
- Spring 从 3.1 开始定义了
org.springframework.cache.Cache 和 org.springframework.cache.CacheManager接口来统一不同的缓存技术; 并支持使用JCache(JSR-107)注解简化我们开发。
注: jsr是Java Specification Requests的缩写,意思是Java 规范提案。
-
Cache 接口为缓存的组件规范定义,包含缓存的各种操作集合; Cache 接 口 下 Spring 提 供 了 各 种
xxxCache的 实 现 ; 如RedisCache,EhCacheCache,ConcurrentMapCache -
每次调用需要缓存功能的方法时,Spring 会检查检查指定参数的指定的目标方法是否已 经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓 存结果后返回给用户。下次调用直接从缓存中获取。
使用 Spring 缓存抽象时我们需要关注以下两点:
(1) 确定方法需要被缓存以及他们的缓存策略
(2) 从缓存中读取之前缓存存储的数据
4.5.2 基础概念
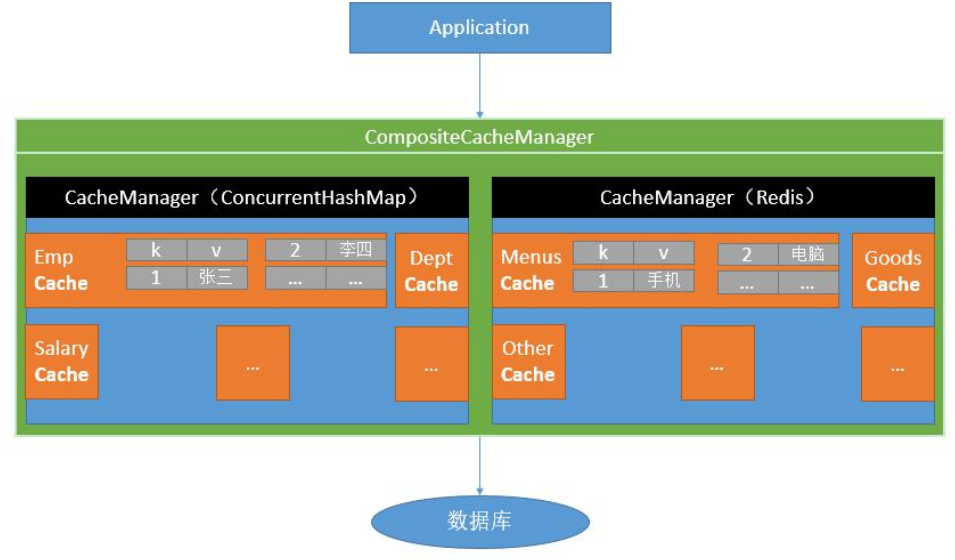
4.5.3 引入&配置
(1)引入依赖:
spring-boot-starter-cache、spring-boot-starter-data-redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!--引入redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<!--排除lettuce-->
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
(2)写配置
配置使用redis作为缓存
spring.cache.type=redis
4.5.4 注解
@Cacheable触发缓存填充,(触发将数据保存到缓存的操作)@CacheEvict触发逐出缓存(触发将数据从缓存删除的操作)@CachePut更新缓存,而不会干扰方法的执行@Caching重新组合要在一个方法上应用的多个缓存操作(组合多个以上操作)@CacheConfig在类级别共享一些与缓存相关的常见设置
4.5.5 使用&细节
(1)开启缓存功能 @EnableCaching
示例:
@Cacheable({"category"})
@Override
public List<CategoryEntity> getLevel1Categorys() {
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", 0));
return categoryEntities;
}
1、每一个需要缓存的数据我们都要来指定要放到那个名字的缓存。【缓存的分区(按照业务类型分)】
2、@Cacheable
代表当前方法的结果需要缓存,如果缓存中有,方法不调用。
如果缓存中没有,会调用方法,左后将方法的结果放入缓存。
3、默认行为
1)如果缓存中有数据,方法不会被调用
2)key默认自动生成:category::SimpleKey []
3)缓存的value值,默认使用jdk序列化机制,将序列化好的数据存到redis中
4)ttl(默认生存时间):-1 永不过期
4、自定义
1)指定生成的缓存使用的key:key属性的指定,接受一个SpEL表达式
2)指定缓存中数据的存活时间:配置文件中修改ttl
3)将数据保存为json格式
如果我们没有自己指定配置,就会使用默认的配置
编写自定义配置类:
//开启加载preperties的功能
@EnableConfigurationProperties(CacheProperties.class)
@Configuration
@EnableCaching
public class MyCacheConfig {
// @Autowired
// public CacheProperties cacheProperties;
/**
* 配置文件的配置没有用上
* @return
*/
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
// config = config.entryTtl();
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//将配置文件中所有的配置都生效
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
spring.cache.type=redis
spring.cache.redis.time-to-live=3600000
#设置是否为空值, 防止缓存穿透
spring.cache.redis.cache-null-values=true
#如果指定了前缀,就用我们指定的前缀,如果没有,就默认使用缓存的名字作为前缀
#spring.cache.redis.key-prefix=CACHE_
#是否使用前缀
spring.cache.redis.use-key-prefix=true
(2)@CachePut(更新某个数据并更新指定的缓存)
可以用来解决缓存一致性中的双写模式,要求在更新完数据后返回最新的数据才可以使用,但一般更新操作返回值为void,所以一般来说用不到
(3)@CacheEvict
根据业务逻辑,进入后台管理系统进行更新操作,需要先修改数据库然后删除缓存。
但是要删除的缓存涉及到redis中创建的category中的两个缓存: CACHE_getCatalogJson 和CACHE_getLevel1Categorys
删除方式一:
@Caching(evict = {
@CacheEvict(value = "category",key = "'getLevel1Categorys'"),
@CacheEvict(value = "category",key = "'getCatalogJson'")
})
/**
* 级联更新所有关联的数据
* @CacheEvict:失效模式
* @CachePut:双写模式,需要有返回值
* 1、同时进行多种缓存操作:@Caching
* 2、指定删除某个分区下的所有数据 @CacheEvict(value = "category",allEntries = true)
* 3、存储同一类型的数据,都可以指定为同一分区
* @param category
*/
// @Caching(evict = {
// @CacheEvict(value = "category",key = "'getLevel1Categorys'"),
// @CacheEvict(value = "category",key = "'getCatalogJson'")
// })
@CacheEvict(value = "category",allEntries = true) //删除某个分区下的所有数据
@Transactional(rollbackFor = Exception.class)
@Override
public void updateCascade(CategoryEntity category) {
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("catalogJson-lock");
//创建写锁
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
this.baseMapper.updateById(category);
categoryBrandRelationService.updateCategory(category.getCatId(), category.getName());
} catch (Exception e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
//同时修改缓存中的数据
//删除缓存,等待下一次主动查询进行更新
}
4.5.6 Spring-Cache的不足之处
(1) 读模式
-
缓存穿透:查询一个null数据。解决方案:缓存空数据
-
缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:加锁 ? 默认是无加锁的;使用
sync = true来解决击穿问题 -
缓存雪崩:大量的key同时过期。解决:加随机时间。加上过期时间
(2) 写模式:(缓存与数据库一致)
- 读写加锁。
- 引入Canal,感知到MySQL的更新去更新Redis
- 读多写多,直接去数据库查询就行
4.5.7 总结
常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用Spring-Cache):写模式(只要缓存的数据有过期时间就足够了)
特殊数据:特殊设计
原理:
CacheManager(RedisCacheManager) -> Cache(RedisCache) -> Cache负责缓存的读写
五、异步&线程池
5.1 线程回顾
5.1.1初始化线程的方式
(1)继承 Thread 类
class Thread01 extends Thread {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("线程名: " + Thread.currentThread().getName() + ", 线程号: " + Thread.currentThread().getId() + " : " + i);
}
}
}
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread01 t1 = new Thread01();
t1.start();
}
}
(2)实现 Runnable 接口
class Thread03 implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 5; i++) {
System.out.println("线程名: " + Thread.currentThread().getName() + ", 线程号: " + Thread.currentThread().getId() + " : " + i);
sum += i;
}
return sum;
}
}
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread02 thread02 = new Thread02();
new Thread(thread02).start();
}
}
(3)实现 Callable 接口 + FutureTask (可以拿到返回结果,可以处理异常)
class Thread03 implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 5; i++) {
System.out.println("线程名: " + Thread.currentThread().getName() + ", 线程号: " + Thread.currentThread().getId() + " : " + i);
sum += i;
}
return sum;
}
}
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread03 thread03 = new Thread03();
FutureTask<Integer> futureTask = new FutureTask<>(thread03);
new Thread(futureTask).start();
Integer integer = futureTask.get();
System.out.println("sum = " + integer);
}
}
(4)线程池
class Thread03 implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 5; i++) {
System.out.println("线程名: " + Thread.currentThread().getName() + ", 线程号: " + Thread.currentThread().getId() + " : " + i);
sum += i;
}
return sum;
}
}
public class ThreadTest {
public static ExecutorService service = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread03 thread03 = new Thread03();
FutureTask<Integer> futureTask = new FutureTask<>(thread03);
Future<Integer> submit = service.submit(thread03);
System.out.println(submit.get());
service.shutdown();
}
}
5.1.2 区别
- 1、2不能获取任务执行后的返回值,3可以返回值
- 1、2、3都不能控制资源,每当要使用时都要创建一个新的线程
- 4 可以控制资源,性能等
5.2 CompletableFuture异步编排
Future 是 Java 5 添加的类,用来描述一个异步计算的结果。
你可以使用isDone方法检查计 算是否完成,或者使用get阻塞住调用线程,直到计算完成返回结果,你也可以使用cancel 方法停止任务的执行。
虽然Future以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不 方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的 初衷相违背,轮询的方式又会耗费无谓的 CPU 资源,而且也不能及时地得到计算结果,为什么不能用观察者设计模式当计算结果完成及时通知监听者呢?
很多语言,比如 Node.js,采用回调的方式实现异步编程。Java 的一些框架,比如 Netty,自己扩展了 Java 的 Future接口,提供了addListener等多个扩展方法;Google guava 也提供了 通用的扩展 Future;Scala 也提供了简单易用且功能强大的 Future/Promise 异步编程模式。
作为正统的 Java 类库,是不是应该做点什么,加强一下自身库的功能呢?
在 Java 8 中, 新增加了一个包含 50 个方法左右的类: CompletableFuture,提供了非常强大的 Future 的扩展功能,可以帮助我们简化异步编程的复杂性,提供了函数式编程的能力,可以通过回调的方式处理计算结果,并且提供了转换和组合 CompletableFuture 的方法。 CompletableFuture 类实现了 Future 接口,所以你还是可以像以前一样通过get方法阻塞或 者轮询的方式获得结果,但是这种方式不推荐使用。
CompletableFuture 和 FutureTask 同属于 Future 接口的实现类,都可以获取线程的执行结果。
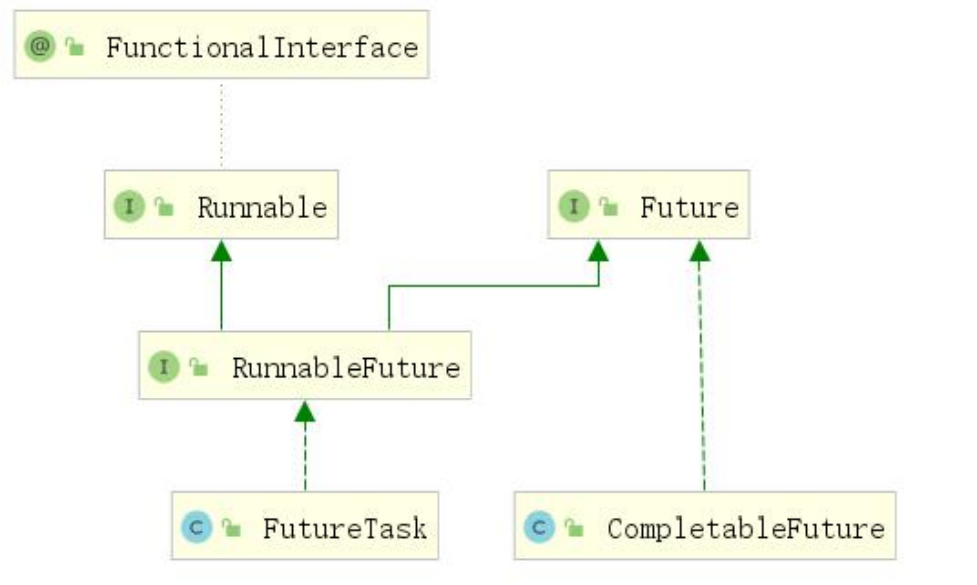
5.2.1 创建异步对象
CompletableFuture 提供了四个静态方法来创建一个异步操作

- runXxxx 都是没有返回结果的,supplyXxx 都是可以获取返回结果的
- 可以传入自定义的线程池,否则就用默认的线程池
5.2.2 计算完成时回调方法
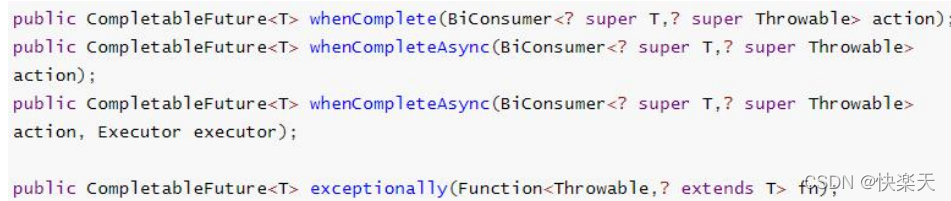
whenComplete 可以处理正常和异常的计算结果,exceptionally 处理异常情况。
whenComplete 和whenCompleteAsync 的区别:
- whenComplete:是执行当前任务的线程执行继续执行 whenComplete 的任务。
- whenCompleteAsync:是执行把 whenCompleteAsync 这个任务继续提交给线程池 来进行执行
方法不以 Async 结尾,意味着 Action 使用相同的线程执行,而 Async 可能会使用其他线程 执行(如果是使用相同的线程池,也可能会被同一个线程选中执行)
实例代码:
public class CompletableFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture future = CompletableFuture.supplyAsync(new Supplier<Object>() {
@Override
public Object get() {
System.out.println(Thread.currentThread().getName() + "\t
completableFuture");
int i = 10 / 0;
return 1024;
}
}).whenComplete(new BiConsumer<Object, Throwable>() {
@Override
public void accept(Object o, Throwable throwable) {
System.out.println("-------o=" + o.toString());
System.out.println("-------throwable=" + throwable);
}
}).exceptionally(new Function<Throwable, Object>() {
@Override
public Object apply(Throwable throwable) {
System.out.println("throwable=" + throwable);
return 6666;
}
});
System.out.println(future.get());
}
}
5.2.3 handle方法

和 complete 一样,可对结果做最后的处理(可处理异常),可改变返回值。
5.2.4 线程串行化方法

thenApply 方法:当一个线程依赖另一个线程时,获取上一个任务返回的结果,并返回当前 任务的返回值。
thenAccept 方法:消费处理结果。接收任务的处理结果,并消费处理,无返回结果。
thenRun 方法:只要上面的任务执行完成,就开始执行 thenRun,只是处理完任务后,执行 thenRun 的后续操作。
带有 Async 默认是异步执行的。同之前。 以上都要前置任务成功完成。
Function <? super , ? extends U>
T:上一个任务返回结果的类型
U:当前任务的返回值类型
5.2.5 两任务组合 - 都要完成

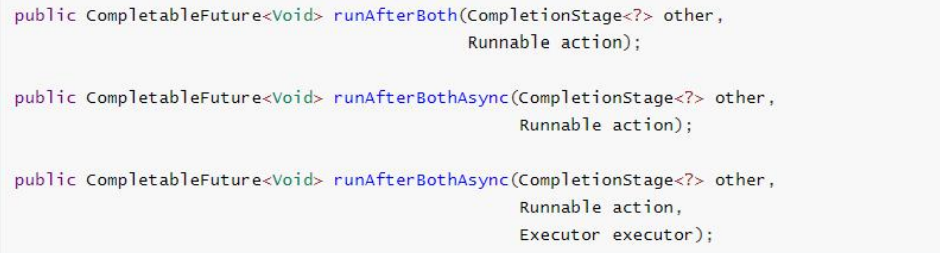
两个任务必须都完成,触发该任务。
thenCombine:组合两个 future,获取两个 future 的返回结果,并返回当前任务的返回值
thenAcceptBoth:组合两个 future,获取两个 future 任务的返回结果,然后处理任务,没有 返回值。
runAfterBoth:组合两个 future,不需要获取 future 的结果,只需两个 future 处理完任务后, 处理该任务
5.2.6 两任务组合 - 一个完成

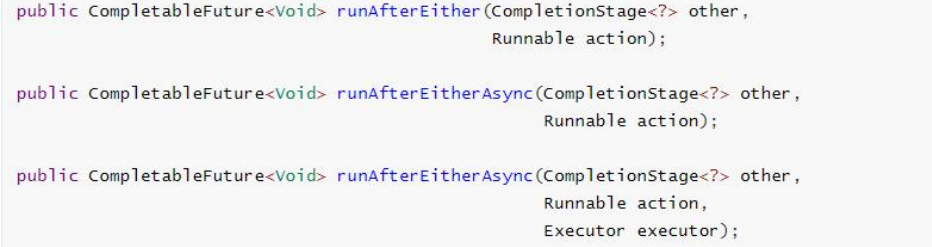
当两个任务中,任意一个 future 任务完成的时候,执行任务。
applyToEither:两个任务有一个执行完成,获取它的返回值,处理任务并有新的返回值。
acceptEither:两个任务有一个执行完成,获取它的返回值,处理任务,没有新的返回值。
runAfterEither:两个任务有一个执行完成,不需要获取 future 的结果,处理任务,也没有返 回值。
5.2.7 多任务组合

allOf:等待所有任务完成
anyOf:只要有一个任务完成
5.3 异步编排优化案例
业务场景:
查询商品详情页的逻辑比较复杂,有些数据还需要远程调用,必然需要花费更多的时间。

假如商品详情页的每个查询,需要如下标注的时间才能完成 那么,用户需要 5.5s 后才能看到商品详情页的内容。很显然是不能接受的。 如果有多个线程同时完成这 6 步操作,也许只需要 1.5s 即可完成响应。
业务代码:
@Override
public SkuItemVo item(Long skuId) throws ExecutionException, InterruptedException {
SkuItemVo skuItemVo = new SkuItemVo();
CompletableFuture<SkuInfoEntity> infoFuture = CompletableFuture.supplyAsync(() -> {
//1 设置sku基本信息
SkuInfoEntity info = getById(skuId);
skuItemVo.setInfo(info);
return info;
}, executor);
CompletableFuture<Void> saleAttrFuture = infoFuture.thenAcceptAsync((res) -> {
//3 获取sku的销售属性组合
List<SkuItemSaleAttrVo> saleAttrVos = skuSaleAttrValueService.getSaleAttrsBySpuId(res.getSpuId());
skuItemVo.setSaleAttr(saleAttrVos);
}, executor);
CompletableFuture<Void> descFuture = infoFuture.thenAcceptAsync((res) -> {
//4 获取spu的介绍 pms_spu_info_desc
SpuInfoDescEntity spuInfoDescEntity = spuInfoDescService.getById(res.getSpuId());
skuItemVo.setDesc(spuInfoDescEntity);
}, executor);
CompletableFuture<Void> attrFuture = infoFuture.thenAcceptAsync((res) -> {
//5、获取spu的规格参数信息
List<SpuItemAttrGroupVo> attrGroupVos = attrGroupService.getAttrGroupWithAttrsBySpuId(res.getSpuId(), res.getCatalogId());
skuItemVo.setGroupAttrs(attrGroupVos);
}, executor);
// 以上future都是有关联的,所有需要公用同一个future对象,而下面的获取sku图片信息与其他任务没有关联所以可以使用一个新的future来执行
CompletableFuture<Void> imageFuture = CompletableFuture.runAsync(() -> {
//2 sku图片信息
List<SkuImagesEntity> images = skuImagesService.getImagesBySkuId(skuId);
skuItemVo.setImages(images);
}, executor);
// 等待所有异步任务都完成
CompletableFuture.allOf(infoFuture, saleAttrFuture, descFuture, attrFuture, imageFuture).get();
return skuItemVo;
}
六、认证服务
6.1 环境搭建
创建一个新的module

6.2 整合短信验证码
6.2.1 WebMvcConfigurer的使用
更多详情:
SpringBoot—WebMvcConfigurer详解_zhangpower1993的博客-CSDN博客_webmvcconfigurer
以往,每当要跳转到一个页面都要在controller层中写一个方法,用来跳转到页面,十分麻烦,所以可以使用WebMvcConfigurer
(1) 编写配置类
将我们的跳转页面操作都放到配置类中,极大程度简化了开发。
@Configuration
public class GulimallWebConfig implements WebMvcConfigurer {
@Override
public void addViewControllers(ViewControllerRegistry registry) {
registry.addViewController("/login.html").setViewName("login");
registry.addViewController("/reg.html").setViewName("reg");
}
}
6.2.2 引入阿里云短信服务
-
第一步:先购买阿里云的短信服务

-
第二步:在第三方服务的module中编写短信发送组件
gulimall-third-party(配置类)
@ConfigurationProperties(prefix = "spring.cloud.alicloud.sms")
@Data
@Component
public class SmsComponent {
private String host;
private String path;
private String appcode;
public void sendSmsCode(String phone,String code) {
// String host = "https://dfsns.market.alicloudapi.com";
// String path = "/data/send_sms";
String method = "POST";
// String appcode = "809227c6f6c043319ecd98f03ca61bed";
Map<String, String> headers = new HashMap<String, String>();
//最后在header中的格式(中间是英文空格)为Authorization:APPCODE 83359fd73fe94948385f570e3c139105
headers.put("Authorization", "APPCODE " + appcode);
//根据API的要求,定义相对应的Content-Type
headers.put("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
Map<String, String> querys = new HashMap<String, String>();
Map<String, String> bodys = new HashMap<String, String>();
bodys.put("content", "code:" + code);
bodys.put("phone_number", phone);
bodys.put("template_id", "TPL_0000");
try {
/**
* 重要提示如下:
* HttpUtils请从
* https://github.com/aliyun/api-gateway-demo-sign-java/blob/master/src/main/java/com/aliyun/api/gateway/demo/util/HttpUtils.java
* 下载
*
* 相应的依赖请参照
* https://github.com/aliyun/api-gateway-demo-sign-java/blob/master/pom.xml
*/
HttpResponse response = HttpUtils.doPost(host, path, method, headers, querys, bodys);
System.out.println(response.toString());
//获取response的body
//System.out.println(EntityUtils.toString(response.getEntity()));
} catch (Exception e) {
e.printStackTrace();
}
}
}
相应的配置文件:
spring:
cloud:
alicloud:
sms:
host: https://dfsns.market.alicloudapi.com
path: /data/send_sms
appcode: 809227c6f6c043319ecd98f03ca61bed
更多操作可以参考短信服务相关帮助文档。
6.2.3 编写短信服务controller
发送验证码的流程
先有前台页面向注册相关的微服务发送请求,再由该服务调用发送短信的第三发微服务,然后由短信服务发送短信。
同时在发送验证码的时候,发送验证码的接口是对外暴露的,所以要加入redis实现接口防刷功能。
准备工作:
- 引入Redis依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 在application配置文件中添加配置,指定redis的地址以及端口号
spring.redis.host=192.168.190.131
spring.redis.port=6379
短信服务controller
@ResponseBody
@GetMapping("/sms/sendcode")
public R sendCode(@RequestParam("phone") String phone) {
// 通过手机号从redis中获取验证码
String redisCode = redisTemplate.opsForValue().get(AuthServerConstant.SMS_CODE_CACHE_PREFIX + phone);
// 判断redis是否保存过验证码
if (!StringUtils.isEmpty(redisCode) || !(redisCode == null)) {
long l = Long.parseLong(redisCode.split("_")[1]);
// 60秒内不能再发送短信验证码
if (System.currentTimeMillis() - l < 60000) {
return R.error(BizCodeEnume.SMS_CODE_EXCEPTION.getCode(), BizCodeEnume.SMS_CODE_EXCEPTION.getMsg());
}
}
// 如果没有设置过验证码或者发送验证码时间过了60s, 就重新生成验证码
String code = UUID.randomUUID().toString().substring(0, 5) + "_" + System.currentTimeMillis();
//向redis中设置key-value key: sms:code手机号 value: 验证码
redisTemplate.opsForValue().set(AuthServerConstant.SMS_CODE_CACHE_PREFIX + phone, code, 10, TimeUnit.MINUTES);
// 使用OpenFeign远程调用第三方服务的接口,发送验证码
thirdPartFeignService.sendCode(phone, code.split("_")[0]);
return R.ok();
}
第三方相关服务controller
@Autowired
SmsComponent smsComponent;
@ResponseBody
@GetMapping("/sendcode")
public R sendCode(@RequestParam("phone") String phone, @RequestParam("code") String code) {
smsComponent.sendSmsCode(phone, code);
return R.ok();
}
6.2.4 注册功能的实现
先要考虑我们注册的流程:
先是从前端出来的表单数据进行封装,所以创建一个UserRegistVo对其进行封装(封装的同时要对其中的数据进行校验),然后需要判断校验信息中是否有错误,如果有错误就返回错误信息,并且请求重定向会注册页面。如果没有错误就先从根据手机号去redis中获取验证证码,如果获取的结果是null说明验证码过期,需要重定向会到登录页,如果获取的不是null就判断验证码是否正确,正确就调用远程服务进行注册操作,并且删除验证码(令牌机制),根据远程服务接口返回的信息判断是否注册成功,成功请求重定向到登录页面,否则重定向回到注册页面。
(1) 注册表单数据校验
注册时要提交的表单:
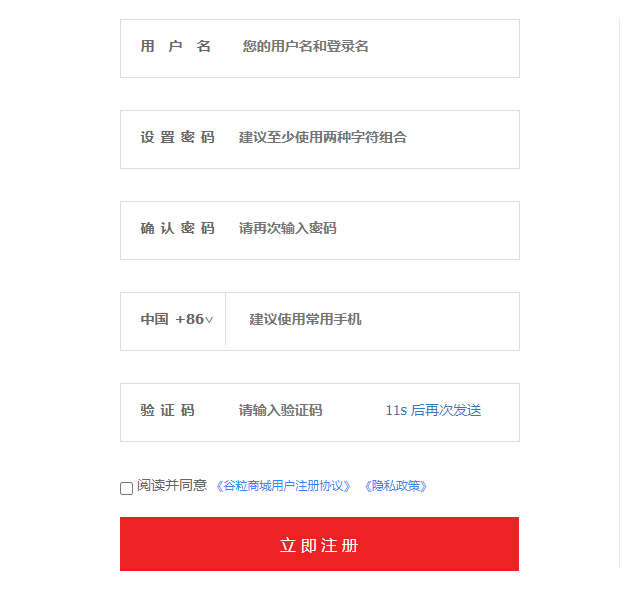
根据表单提交的数据封装成一个Vo:
UserRegistVo
不止前端部分需要进行校验,后端也要对表单数据进行校验,所以加入JSR303校验规则。
@Data
public class UserRegistVo {
@NotEmpty(message = "用户名必须提交")
@Length(min = 6, max = 18 , message = "用户名必须是6-18位字符")
private String username;
@NotEmpty(message = "密码必须提交")
@Length(min = 6, max = 18 , message = "密码必须是6-18位字符")
private String password;
@NotEmpty(message = "手机号必须填写")
@Pattern(regexp = "^[1]([3-9])[0-9]{9}$", message = "手机号格式不正确")
private String phone;
@NotEmpty(message = "验证码必须填写")
private String code;
}
同时,需要在接受数据的相关controller中加入@Valid注解并在参数中加入 BindingResult result 参数用来获取校验中出现的异常信息。
(2) MD5&盐值&Bcrypt
(1) MD5
MD5全称是Message-Digest Algorithm 5(信息-摘要算法)
MD5消息摘要算法,属Hash算法一类。MD5算法对输入任意长度的消息进行运行,产生一个128位的消息摘要(32位的数字字母混合码)。
在谷粒商城注册的业务逻辑中我们使用org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder包中的BCryptPasswordEncoder
BCryptPasswordEncoder会为我们生成随机盐值,并进行加密操作。
简单使用:
//密码进行加密存储
// 加密操作
BCryptPasswordEncoder bCryptPasswordEncoder = new BCryptPasswordEncoder();
memberEntity.setPassword(bCryptPasswordEncoder.encode(vo.getPassword()));
// 解密操作
String password = vo.getPassword();
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
//maches方法,第一个参数是明文,第二个参数是密文,调用maches方过后会返回一个bool值
boolean matches = passwordEncoder.matches(password, memberEntity.getPassword());
(3) controller层方法编写
认证服务(gulimall-auth-server)的controller:
@PostMapping("/regist")
public String regist(@Valid UserRegistVo vo, BindingResult result,
RedirectAttributes redirectAttributes) {
// 判断表单数据校验是否有错误
if (result.hasErrors()) {
// 将错误属性与错误信息一一封装
Map<String, String> errors = result.getFieldErrors().stream().collect(Collectors.toMap(FieldError::getField,
fieldError -> fieldError.getDefaultMessage(),
(fieldError1, fieldError2) -> {
return fieldError2;
}));
// addFlashAttribute 这个数据只取一次
redirectAttributes.addFlashAttribute("errors", errors);
return "redirect:http://auth.gulimall.com/reg.html";
}
//校验验证码是否正确
String redisCode = redisTemplate.opsForValue().get(AuthServerConstant.SMS_CODE_CACHE_PREFIX + vo.getPhone());
if (!StringUtils.isEmpty(redisCode)) {
if (vo.getCode().equalsIgnoreCase(redisCode.split("_")[0])) {
// 验证码正确
//删除验证码,令牌机制
redisTemplate.delete(AuthServerConstant.SMS_CODE_CACHE_PREFIX + vo.getPhone());
//验证码通过,调用远程服务进行注册
R r = memberFeignService.regist(vo);
if (r.getCode() == 0) {
//成功
// 注册成功,请求从定向到登录页
return "redirect:http://auth.gulimall.com/login.html";
} else {
//失败
Map<String, String> errors = new HashMap<>();
errors.put("msg", r.getData(new TypeReference<String>() {
}));
redirectAttributes.addFlashAttribute("errors", errors);
return "redirect:http://auth.gulimall.com/reg.html";
}
} else {
Map<String, String> errors = new HashMap<>();
errors.put("code", "验证码错误");
redirectAttributes.addFlashAttribute("errors", errors);
return "redirect:http://auth.gulimall.com/reg.html";
}
} else {
Map<String, String> errors = new HashMap<>();
errors.put("code", "验证码过期");
redirectAttributes.addFlashAttribute("errors", errors);
return "redirect:http://auth.gulimall.com/reg.html";
}
}
会员服务(gulimall-member)的controller:
@Transactional
@Override
public void regist(MemberRegistVo vo) {
MemberEntity memberEntity = new MemberEntity();
//设置默认等级
MemberLevelEntity levelEntity = this.baseMapper.getDefaultLevel();
memberEntity.setLevelId(levelEntity.getId());
//设置手机号
//预先检查用户名、手机号是否唯一,如果不唯一就会抛出异常
checkPhoneUnique(vo.getPhone());
checkUsernameUnique(vo.getUsername());
memberEntity.setMobile(vo.getPhone());
memberEntity.setUsername(vo.getUsername());
//密码进行加密存储
BCryptPasswordEncoder bCryptPasswordEncoder = new BCryptPasswordEncoder();
memberEntity.setPassword(bCryptPasswordEncoder.encode(vo.getPassword()));
save(memberEntity);
}
如果操作成功,会在数据库中查到一条新的数据,同时会从注册页面重定向到登录页面。
6.2.5 登录功能的实现
梳理流程:
先从前台页面获取到登录的表单数据,然后远程调用会员服务进行登录逻辑的判断。
因为使用OpenFeign进行远程调用的时候,传递都是json格式的数据,所以要封装一个Vo对象封装数据进行传输。同时要注意是Post请求方式。
最终会员服务service层的逻辑是根据传来的数据向数据库中查询数据,然后再controller层判断,如果获取到的数据时null,则封装错误信息并返回。
(1) 注册表单数据校验
controller层的方法:
@PostMapping("/login")
public R login(@RequestBody MemberLoginVo vo) {
MemberEntity memberEntity = memberService.login(vo);
if (memberEntity != null) {
return R.ok();
} else {
return R.error(BizCodeEnume.LOGINACCT_PASSWORD_EXCEPTION.getCode(), BizCodeEnume.LOGINACCT_PASSWORD_EXCEPTION.getMsg());
}
}
service层方法:
@Override
public MemberEntity login(MemberLoginVo vo) {
String loginacct = vo.getLoginacct();
// 去数据库查询
MemberEntity memberEntity = this.baseMapper.selectOne(new QueryWrapper<MemberEntity>()
.eq("username", loginacct)
.or().eq("email", loginacct)
.or().eq("mobile", loginacct));
if (memberEntity == null) {
return null;
} else {
String password = vo.getPassword();
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
boolean matches = passwordEncoder.matches(password, memberEntity.getPassword());
if (matches) {
return memberEntity;
} else {
return null;
}
}
}
6.3 社交登录
6.3.1 Oauth2.0
- 简介
OAuth简单说就是一种授权的协议,只要授权方和被授权方遵守这个协议去写代码提供服务,那双方就是实现了OAuth模式。OAuth2.0是OAuth协议的延续版本。OAuth 2.0关注客户端开发者的简易性。要么通过组织在资源拥有者和HTTP服务商之间的被批准的交互动作代表用户,要么允许第三方应用代表用户获得访问的权限。同时为Web应用,桌面应用和手机,和起居室设备提供专门的认证流程。
不如说:我们想要登录CSDN但是还是没注册账号,因为注册账号比较麻烦所以想要更快捷的方式进行登录,所以可以选择QQ或者微博登录。
- 流程图

6.3.2 微博认证登录
(1) 流程
微博认证流程图:
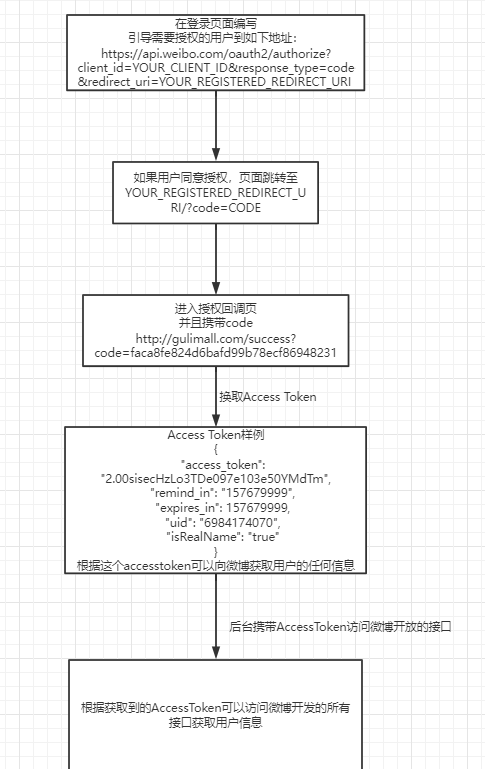
大致流程就是通过我们的页面访问微博的登录页,登录成功后微博会根据我们填写的认证授权回调页,如:http://gulimall.com/success进行请求重定向,并且会在请求参数中携带一个code,我们自己的服务器后端根据这个code,加上App Key,App Secret,向微博获取AccessToken,随后,我们就可以通过微博的官方文档查看微博提供的相关接口,利用AccessToken获取用户信息。
同时要注意code会过期,并且使用过后就会失效。
(2) 认证服务Controller
package com.atguigu.gulimall.auth.controller;
/**
* 第三方认证登录controller
*/
@Slf4j
@Controller
public class OAuth2Controller {
@Autowired
MemberFeignService memberFeignService;
@GetMapping("/oauth2.0/weibo/success")
public String weibo(@RequestParam("code") String code) throws Exception {
Map<String, String> map = new HashMap<String, String>();
map.put("client_id", "3182348399");
map.put("client_secret", "d3ca776d45c0c4158f4b200d85cd213e");
map.put("grant_type", "authorization_code");
map.put("redirect_uri", "http://auth.gulimall.com/oauth2.0/weibo/success");
map.put("code", code);
// 获取AccessToken
//使用HttpUtils
HttpResponse response = HttpUtils.doPost("https://api.weibo.com", "/oauth2/access_token", "post", new HashMap<String, String>(), new HashMap<String, String>(), map);
if (response.getStatusLine().getStatusCode() == 200) {
String json = EntityUtils.toString(response.getEntity());
// 将获取到的AccessToken等的相关信息封装到SocialUser对象中
SocialUser socialUser = JSON.parseObject(json, SocialUser.class);
// 如果社交账号是第一次登录,就为其注册,远程调用member服务
R r = memberFeignService.oauth2Login(socialUser);
if (r.getCode() == 0) {
MemberRespVo memberRespVo = r.getData("data", new TypeReference<MemberRespVo>() {
});
log.info("返回的用户信息: {}", memberRespVo);
return "redirect:http://gulimall.com";
} else {
return "redirect:http://auth.gulimall.com/login.html";
}
} else {
return "redirect:http://auth.gulimall.com/login.html";
}
}
}
(3) 远程调用的认证登录方法
/**
* 社交账号登录login方法
*
* @param socialUser
* @return
*/
@Override
public MemberEntity login(SocialUser socialUser) {
// 登录和注册合并逻辑
String uid = socialUser.getUid();
MemberEntity memberEntity = this.baseMapper.selectOne(new QueryWrapper<MemberEntity>().eq("social_uid", uid));
// 判断当前社交用户是否已经登录过此系统
if (memberEntity != null) {
MemberEntity update = new MemberEntity();
update.setId(memberEntity.getId());
update.setAccessToken(socialUser.getAccess_token());
update.setExpiresIn(socialUser.getExpires_in());
this.baseMapper.updateById(update);
memberEntity.setAccessToken(socialUser.getAccess_token());
memberEntity.setExpiresIn(socialUser.getExpires_in());
return memberEntity;
} else {
//没有查到用户信息就要自己注册一个
MemberEntity regist = new MemberEntity();
// 相关的用户信息使用HttpUtils访问微博提供的接口获取
try {
Map<String, String> query = new HashMap<String, String>();
query.put("access_token", socialUser.getAccess_token());
query.put("uid", socialUser.getUid());
//https://api.weibo.com/2/users/show.json
HttpResponse response = HttpUtils.doGet("https://api.weibo.com", "/2/users/show.json", "get", new HashMap<String, String>(), query);
// 判断远程获取社交用户信息是否成功
if (response.getStatusLine().getStatusCode() == 200) {
String json = EntityUtils.toString(response.getEntity());
JSONObject jsonObject = JSON.parseObject(json);
String name = jsonObject.getString("name");
String gender = jsonObject.getString("gender");
regist.setNickname(name);
regist.setGender("m".equals(gender) ? 1 : 0);
// TODO 还可以设置更多其他信息...
}
regist.setAccessToken(socialUser.getAccess_token());
regist.setExpiresIn(socialUser.getExpires_in());
regist.setSocialUid(uid);
int insert = this.baseMapper.insert(regist);
} catch (Exception e) {
e.printStackTrace();
}
return regist;
}
}
**总结:**先向微博发送请求获取认证用户的信息,获取到的信息有用户唯一的uid,拿到用户信息后需要远程调用member服务的认证登录方法,在member认证登录方法中,需要先判断当前认证用户是否第一次登录,如果是第一次登录就要获取根据AccessToken获取认证用户的信息,同时创建一个新的MemberEntity对象,此对象用作封装认证用户的相关信息,并且保存到数据库中,最后返回MemberEntity。如果不是第一次登录,就要更新数据库中对应此用户的AccessToken和Expires_in(AccessToken过期时间),最后返回此用户的相关信息(通过MemberEntity对象)。
问题: 认证登录成功后需要将登录的信息在商城首页进行回显,但是认证登录时的域名是auth.gulimall.com,商城首页的域名是gulimall.com,就涉及到了跨域数据无法共享的问题。
6.4 分布式Session
6.4.1 Session原理
session的本质是服务器内存中的一个对象,可以将session看成一个Map集合。服务器中所有的session都放在sessionManager中进行管理。

6.4.2 分布式Session两大问题问题
在进行登录操作后,会跳转到首页,但是,登录成功的信息需要进行回显,就需要利用到session来存放我们需要的信息。
session是基于cookie的,当客户端访问服务端的时候,服务端会向客户端颁发一个cookie,cookie中会保存一个JSSESSIONID,第二次登录时,浏览器就会带着这个JSSESSIONID去找到服务端内存中响应的Session,从而获取相关数据信息。
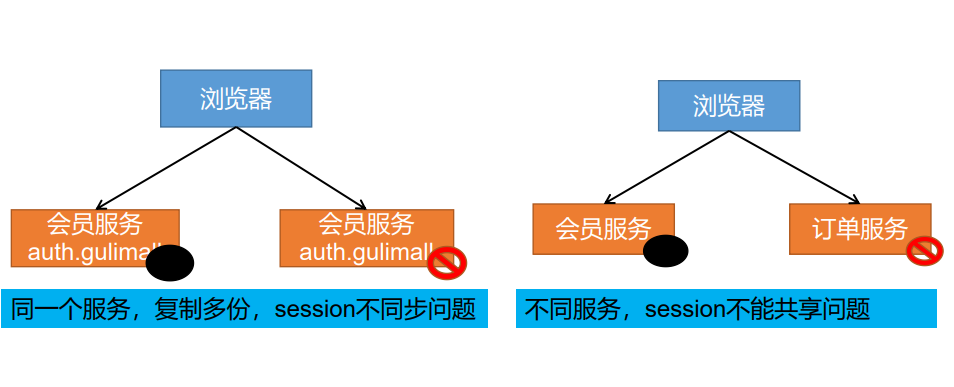
但是在分布式的场景下会出现问题:
- 问题一:
session不会跨域
- 问题二:
集群情况下session会失效
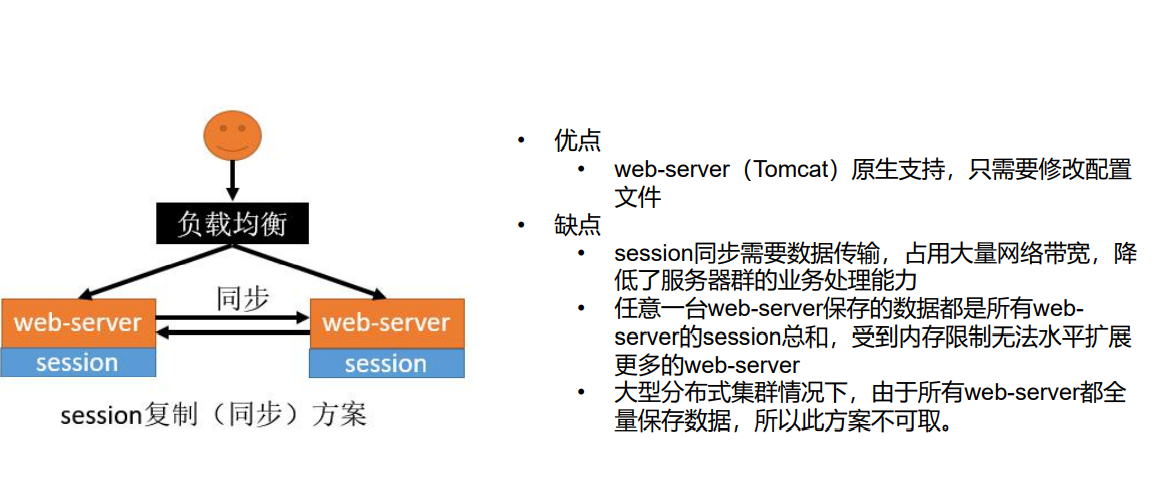
解决方案1:session复制
解决方案2:客户端存储

解决方案3:Hash一致性
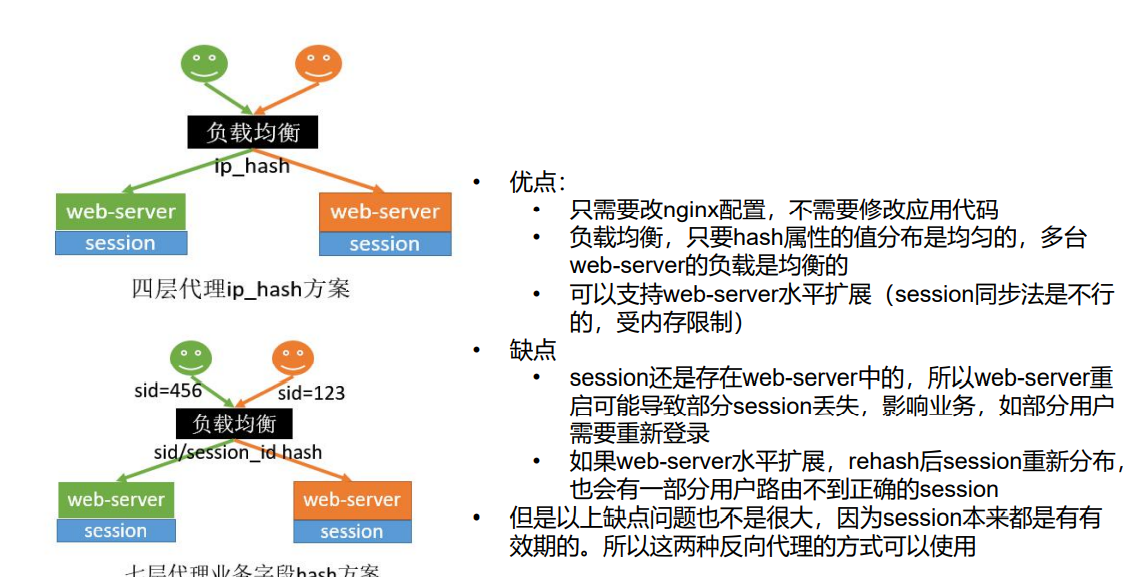
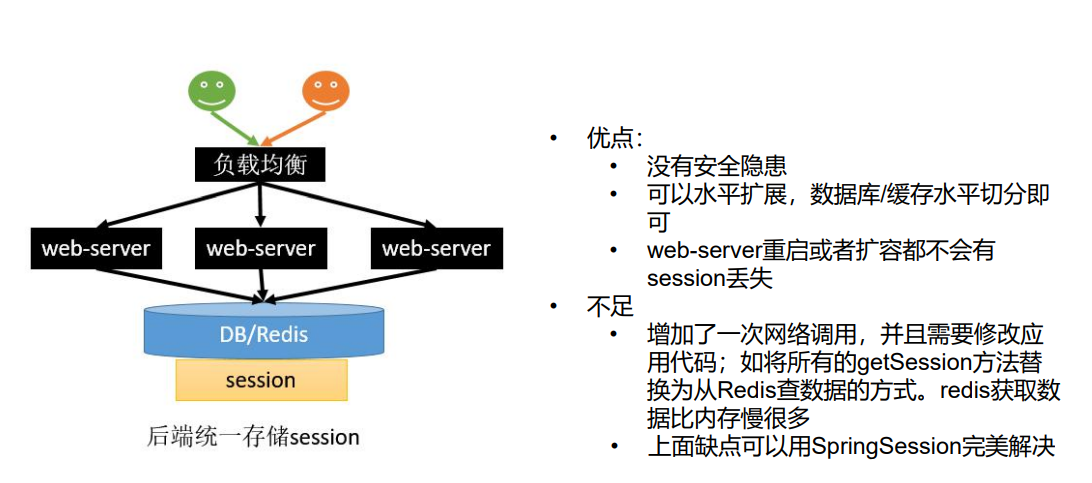
解决方案4:使用SpringSession
- 问题三:
子域不共享问题
将cookie中的jsessionid设置为.gulimall.com
这样,auto.gulimall.com等子域名就都能共享session中的数据了
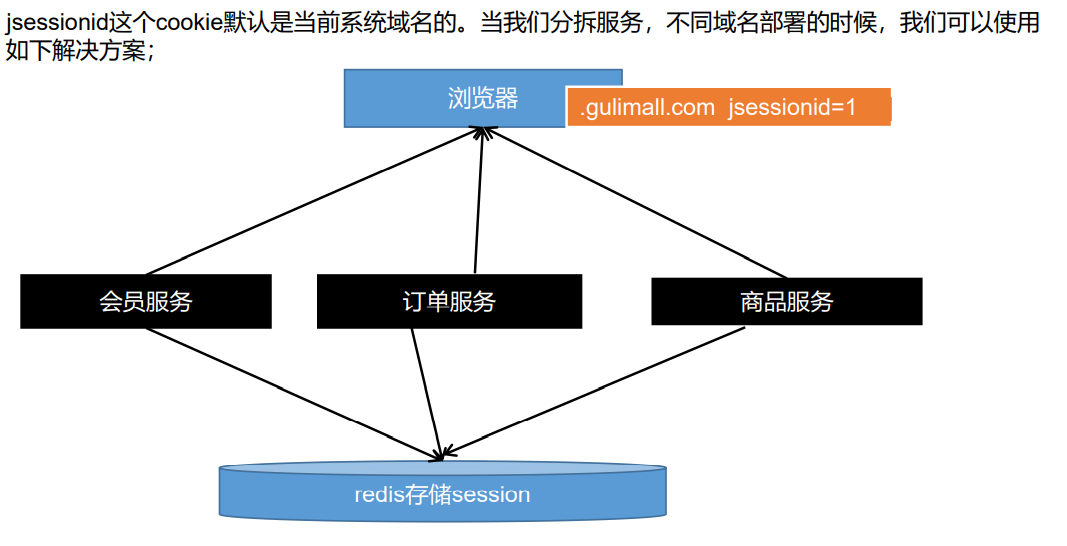
浏览器的cookie是由我们的服务器默认颁发的,要想自定义颁发的cookie内容,需要我们手动去修改,但是引入SpringSession就可以解决此问题.
6.4.3 SpringSession
可参考博客:https://blog.csdn.net/qq_43371556/article/details/100862785
更多详情可以参考Spring官方文档。
(1) 配置SpringSession
- 引入依赖
<!-- 整合SpringSession解决session共享问题 -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 配置application.properties
spring.session.store-type=redis # Session store type.
- 在配置类上标记注解
@EnableRedisHttpSession
@EnableRedisHttpSession
@EnableDiscoveryClient
@EnableFeignClients
@SpringBootApplication
public class GulimallAuthServerApplication {
public static void main(String[] args) {
SpringApplication.run(GulimallAuthServerApplication.class, args);
}
}
- 编写配置类
@Configuration
public class SessionConfig {
/**
* 配置Cookie序列化机制,将session对象转换为JSON格式,并且设置域名
* @return
*/
@Bean
public CookieSerializer cookieSerializer() {
DefaultCookieSerializer cookieSerializer = new DefaultCookieSerializer();
cookieSerializer.setDomainName("xxx.com");
cookieSerializer.setCookieName("YOUR_SESSION_NAME");
return cookieSerializer;
}
/**
* 配置序列化机制
* @return
*/
@Bean
public RedisSerializer<Object> springSessionDefaultRedisSerializer() {
return new GenericJackson2JsonRedisSerializer();
}
}
(2) SpringSession原理
在要使用SpringSession的服务的主启动类上标记了@EnableRedisHttpSession注解
@EnableRedisHttpSession
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Import(RedisHttpSessionConfiguration.class)// 导入配置
@Configuration
public @interface EnableRedisHttpSession {
@EnableRedisHttpSession中导入了RedisHttpSessionConfiguration这个配置类
而RedisHttpSessionConfiguration这个配置类中,为IOC容器中添加了一个组件: RedisOperationsSessionRepository 用于使用redis操作session,也就是session的增删改查封装类。
public class RedisHttpSessionConfiguration extends SpringHttpSessionConfiguration
implements BeanClassLoaderAware, EmbeddedValueResolverAware, ImportAware,
SchedulingConfigurer {
RedisHttpSessionConfiguration继承了SpringHttpSessionConfiguration,
而SpringHttpSessionConfiguration中为容器添加了另一个重要的组件:SessionRepositoryFilter
SessionRepositoryFilter是session存储的过滤器。SessionRepositoryFilter继承了OncePerRequestFilter,而OncePerRequestFilter实现了Filter接口,所以SessionRepositoryFilter是一个servlet的过滤器,所有的请求过来都需要经过filter。
SessionRepositoryFilter中重写了最核心的方法: doFilterInternal,这个方法在SessionRepositoryFilter的父类中的doFilter中被引用,也就是说是OncePerRequestFilter重写了Fliter接口的doFilter,doFilterInternal在doFilter中被调用实现了核心的功能。
doFilterInternal方法:
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
request.setAttribute(SESSION_REPOSITORY_ATTR, this.sessionRepository);
// 将原生的request用一个包装类SessionRepositoryRequestWrapper包装起来
SessionRepositoryRequestWrapper wrappedRequest = new SessionRepositoryRequestWrapper(
request, response, this.servletContext);
// 将原生的response用一个包装类包SessionRepositoryResponseWrapper装起来
SessionRepositoryResponseWrapper wrappedResponse = new SessionRepositoryResponseWrapper(
wrappedRequest, response);
try {
//最后在filter链中放行的是包装过后的request和response
filterChain.doFilter(wrappedRequest, wrappedResponse);
}
finally {
wrappedRequest.commitSession();
}
}
SpringSession主要是使用了装饰者模式,将原生的request和response进行了封装,原来我们获取session对象是用request.getSession()获取,而现在是使用wrapperRequest.getSession从RedisOperationsSessionRepository中获取Session,这样我们对session的增删改查就是在Redis中进行的了。
// session是使用sessionRepository的createSession()方法进行创建的
S session = SessionRepositoryFilter.this.sessionRepository.createSession();
最后,在Redis中储存的Session过期时间也会自动延期。
6.5 单点登录
什么是单点登录?单点登录全称Single Sign On(简称SSO),是指在多系统应用群中登录一个系统,便可在其他所有系统中得到授权而无需再次登录,包括单点登录与单点注销两部分。
比如在微博登录过后,发现在微博的其他产品的网站都显示已经登录了,即便域名不一样。
SSO单点登录核心原理:
首先需要有一个中央认证服务器,关键在用户对一个服务进行访问并且进行登录操作,服务器会访问中央认证服务器,并在SSO服务器留下登录痕迹,也就是服务器将登录的信息保存起来,生成一个token,并对浏览器进行发卡操作,就是生成一个cookie保存token信息,当用户再到其他服务进行登录时,浏览器就会带着cookie,而cookie中带有token的信息,服务器后台获取token信息,并携带token信息到中央认证服务器去获取用户的相关信息,从而实现单点登录功能。
七、购物车
7.1 购物车数据模型分析
7.3.1 购物车需求
- 用户可以在登录状态下将商品添加到购物车【用户购物车/在线购物车】
- 放入数据库 - mongodb - 放入 redis(采用) 登录以后,会将临时购物车的数据全部合并过来,并清空临时购物车;
- 用户可以在未登录状态下将商品添加到购物车【游客购物车/离线购物车/临时购物车】
- 放入 localstorage(客户端存储,后台不存)
- cookie - WebSQL - 放入 redis(采用) 浏览器即使关闭,下次进入,临时购物车数据都在
- 用户可以使用购物车一起结算下单
- 给购物车添加商品 - 用户可以查询自己的购物车
- 用户可以在购物车中修改购买商品的数量。
- 用户可以在购物车中删除商品。
- 选中不选中商品
- 在购物车中展示商品优惠信息
- 提示购物车商品价格变化
7.3.2 VO编写
Cart
/**
* 整个购物车,对计算商品数量、商品类型数量和商品总价的get方法进行了特殊处理,在调用get方法计算数量或总价
*/
public class Cart {
List<CartItem> items;
private Integer countNum;// 商品数量
private Integer countType;//商品类型数量
private BigDecimal totalAmount;//商品总价
private BigDecimal reduce = new BigDecimal("0.00");//减免价格
public Integer getCountNum() {
int count = 0;
if (this.items != null && this.items.size() > 0) {
for (CartItem item : this.items) {
count += item.getCount();
}
}
return count;
}
public Integer getCountType() {
return this.items != null && this.items.size() > 0 ? this.items.size() : 0;
}
public BigDecimal getTotalAmount() {
BigDecimal amount = new BigDecimal("0");
//计算价格总和
if (items.size() > 0 && items != null) {
for (CartItem item : this.items) {
BigDecimal totalPrice = item.getTotalPrice();
amount = amount.add(totalPrice);
}
}
//减去优惠价格
amount = amount.subtract(getReduce());
return amount;
}
}
CartItem
public class CartItem {
private Long skuId;
private Boolean check = true;
private String title;
private String image;
private List<String> skuAttr;
private BigDecimal price;
private Integer count;
private BigDecimal totalPrice;
/**
* 计算当前购物项总价
* @return
*/
public BigDecimal getTotalPrice() {
return this.price.multiply(new BigDecimal("" + this.count));
}
}
7.2 购物车和离线购物车功能
7.2.1 问题描述
参考京东和淘宝之前都有离线购物车功能,就是在用户未登录的时候也可以将商品加入购物车,并且,用户进行登录之后,临时购物车的商品并不会丢失,而是会加到用户的购物车里。
问题是:如何保留购物车中的商品?
我们可以将购物车中的商品保存到Redis中,Redis具有持久化策略,服务器宕机了也可以恢复数据。
但是,如何怎么去记住是那些用户将商品添加到了购物车?也就是Redis中的key应该是什么?
如果我们登录的话,这个key可以利用用户的账号生成,但是临时用户如何保存呢?
学习jd的解决方案可以这样来做:
用户第一次访问购物车的时候为用户颁发一个Cookie(无论是否登录都颁发),cookie的key就叫user-key,value在后台随机生成。同时要设置cookie的过期时间为1个月,还有cookie的作用域。
同时,在我们进入购物车页面的时候,要判断用户是否登录,同时要是否已经想用户颁发了cookie。
如果我们在每一个controller层的方法都进行判断的话,会使代码变得冗余。
所以,我们使用SpringMVC的拦截器机制。
7.2.2 编写拦截器
想要使用SpringMVC的拦截器机制,需要先编写一个类,实现HandlerInterceptor接口,根据y业务需求重写接口中的方法。
同时,还要指定拦截器作用在那些请求上。
(1) 拦截器逻辑代码
/**
* 在执行目标方法之前,判断用户登录状态,并封装传递给controller目标请求
*/
public class CartInterceptor implements HandlerInterceptor {
public static ThreadLocal<UserInfoTo> threadLocal = new ThreadLocal<UserInfoTo>();
/**
* 业务执行前拦截
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HttpSession session = request.getSession();
MemberRespVo member = (MemberRespVo) session.getAttribute(AuthServerConstant.LOGIN_USER);
UserInfoTo userInfoTo = new UserInfoTo();
if (member != null) {
// 用户登录
userInfoTo.setUserId(member.getId());
}
Cookie[] cookies = request.getCookies();
if (cookies != null && cookies.length > 0) {
for (Cookie cookie : cookies) {
String name = cookie.getName();
if (CartConstant.TEMP_USER_COOKIE_NAME.equals(name)) {
userInfoTo.setUserKey(cookie.getValue());
userInfoTo.setHasUserKey(true);
break;
}
}
}
// 如果user-key为空就分配一个
if (StringUtils.isEmpty(userInfoTo.getUserKey())) {
String uuid = UUID.randomUUID().toString();
userInfoTo.setUserKey(uuid);
}
// 将封装好的UserInfo放到threadLocal中
threadLocal.set(userInfoTo);
return true;
}
/**
* 业务执行之后拦截
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
UserInfoTo userInfoTo = CartInterceptor.threadLocal.get();
if (!userInfoTo.isHasUserKey()) {
Cookie cookie = new Cookie(CartConstant.TEMP_USER_COOKIE_NAME, userInfoTo.getUserKey());
//设置作用域
cookie.setPath("gulimall.com");
cookie.setMaxAge(CartConstant.TEMP_USER_COOKIE_TIMEOUT);
response.addCookie(cookie);
}
}
}
(2) WebConfig配置类
@Configuration
public class GulimallWebConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 配置CartInterceptor拦截器拦截所有请求
registry.addInterceptor(new CartInterceptor()).addPathPatterns("/**");
}
}
7.2.3 ThreadLocal
因为在拦截器向controller层传递一个UserInfoVo对象,所以为了获取到这个对象,使用ThreadLocal
ThreadLocal同一个线程内共享数据,一个请求,拦截器->controller->service->dao都是同一个线程。
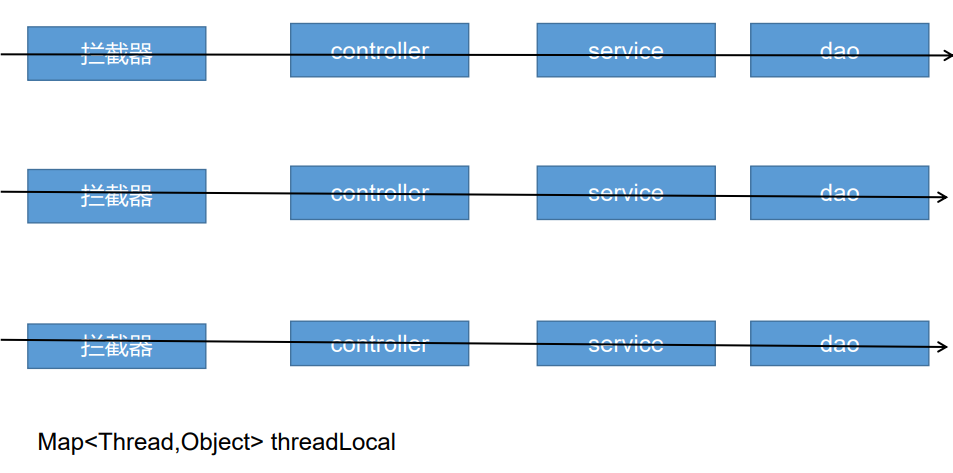
所以在拦截器处设置一个静态的ThreadLocal变量:
public static ThreadLocal<UserInfoTo> threadLocal = new ThreadLocal<UserInfoTo>();
放上数据后就可以传递给后面。
关于ThreadLocal的更多操作可以参考这篇文章:
https://blog.csdn.net/u010445301/article/details/111322569?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164125953316780357242735%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=164125953316780357242735&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-2-111322569.first_rank_v2_pc_rank_v29&utm_term=threadlocal&spm=1018.2226.3001.4187
八、消息队列 Message Queue
8.1 消息中间件概述
1.大多应用中,可通过消息服务中间件来提升系统异步通信、扩展解耦能力
2.消息服务中两个重要概念:
- 消息代理(message broker)和目的地(destination)
- 当消息发送者发送消息以后,将由消息代理接管,消息代理保证消息传递到指定目的地。
3.消息队列主要有两种形式的目的地
- 队列(queue):点对点消息通信(point-to-point)
- 主题(topic):发布(publish)/订阅(subscribe)消息通信
4.点对点式
- 消息发送者发送消息,消息代理将其放入一个队列中,消息接收者从队列中获 取消息内容,消息读取后被移出队列
- 消息只有唯一的发送者和接受者,但并不是说只能有一个接收者
5.发布订阅式:
- 发送者(发布者)发送消息到主题,多个接收者(订阅者)监听(订阅)这个 主题,那么就会在消息到达时同时收到消息
6.JMS(Java Message Service)JAVA消息服务:
- 基于JVM消息代理的规范。ActiveMQ、HornetMQ是JMS实现
7.AMQP(Advanced Message Queuing Protocol)
-
高级消息队列协议,也是一个消息代理的规范,兼容JMS
-
RabbitMQ是AMQP的实现
8.Spring支持
-
spring-jms提供了对JMS的支持
-
spring-rabbit提供了对AMQP的支持
-
需要ConnectionFactory的实现来连接消息代理
-
提供JmsTemplate、RabbitTemplate来发送消息
-
@JmsListener(JMS)、@RabbitListener(AMQP)注解在方法上监听消息代理发布的消息
-
@EnableJms、@EnableRabbit开启支持
9.Spring Boot自动配置
-
**JmsAutoConfiguration **
-
RabbitAutoConfiguration
10.市面上的MQ产品
•ActiveMQ、RabbitMQ、RocketMQ、Kafka
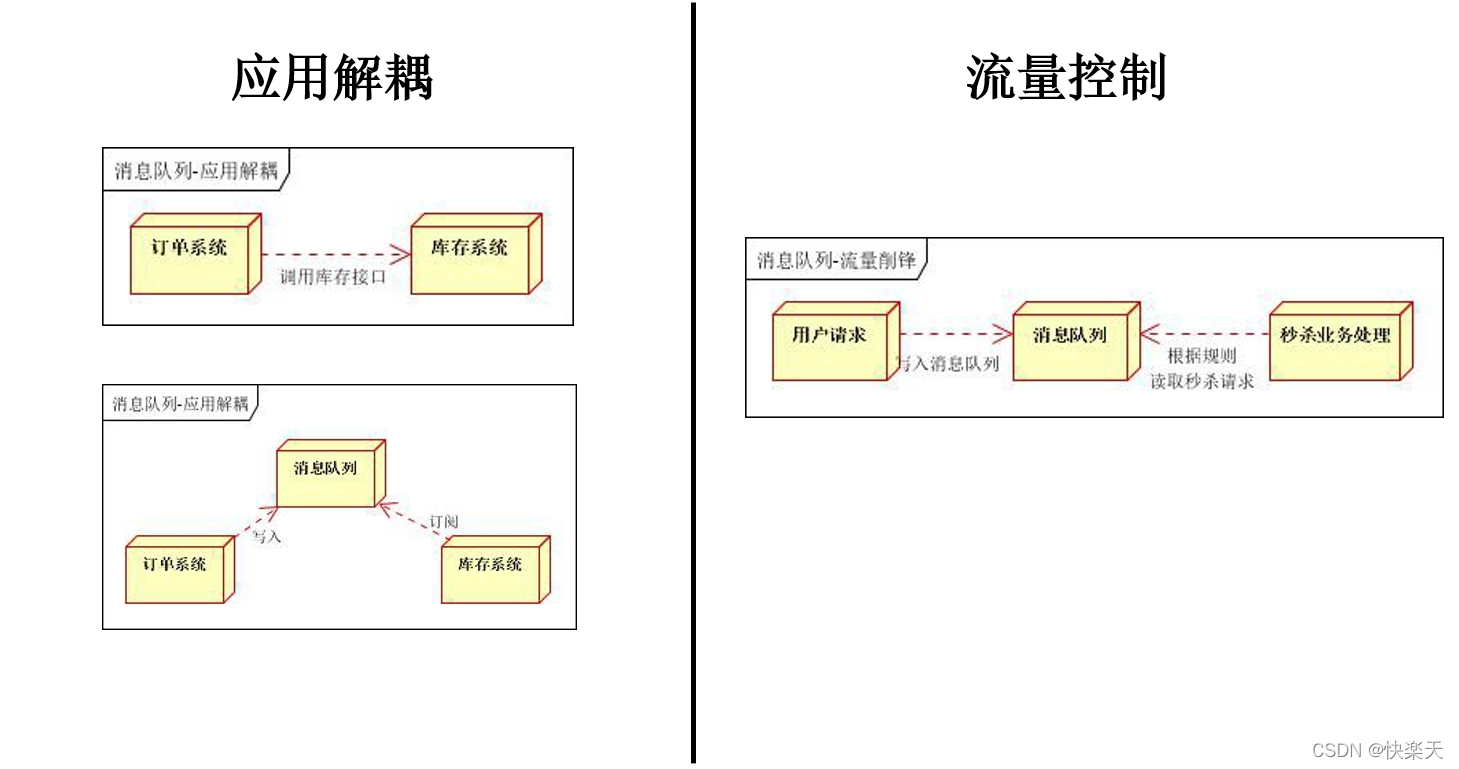
提到消息中间件就要想到:异步、消峰、解耦
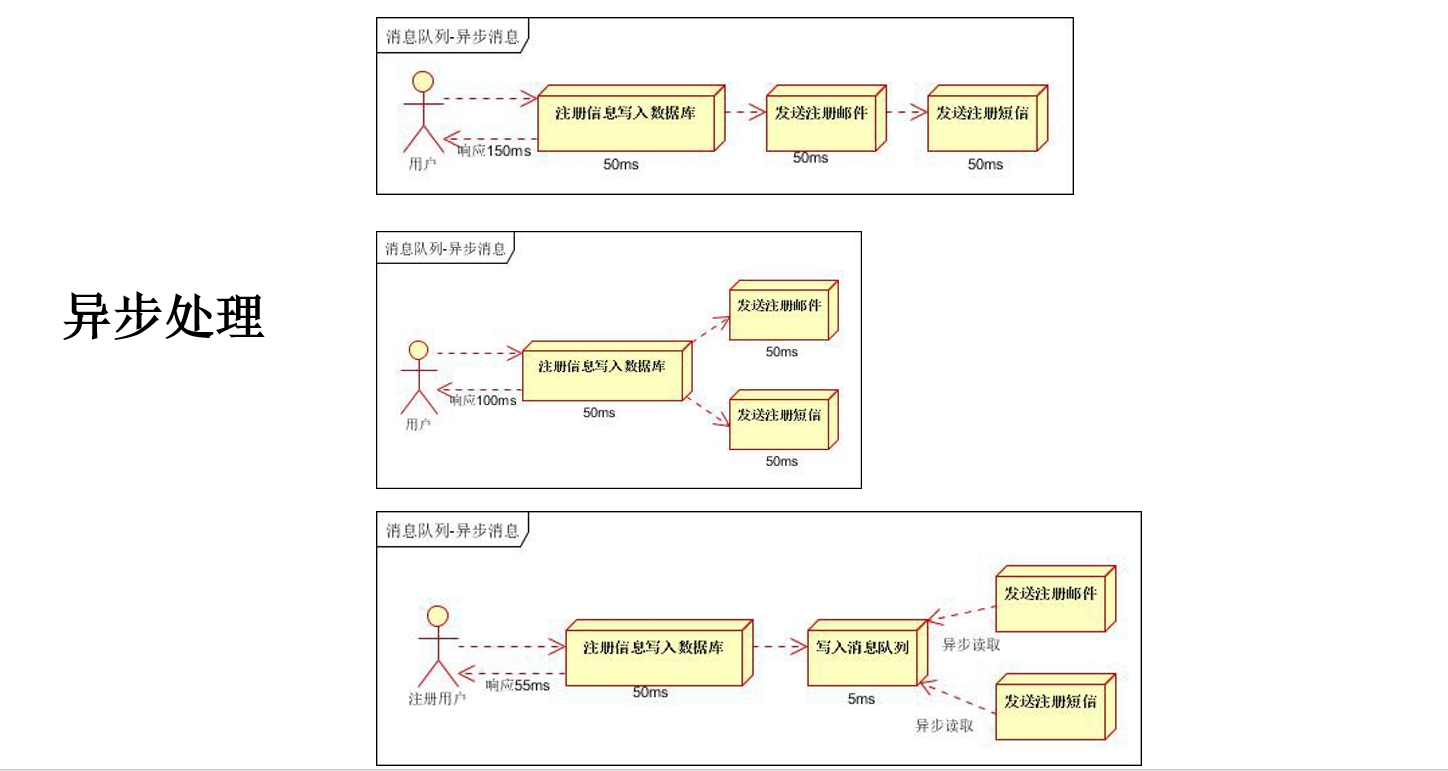
消息队列主要分为两大类:一类是JMS(Java Message Service)JAVA消息服务,另一类是:AMQP(Advanced Message Queuing Protocol)

8.2 RabbitMQ
8.2.1 RabbitMQ简介
RabbitMQ是一个由erlang开发的AMQP(Advanved Message Queue Protocol)的开源实现。
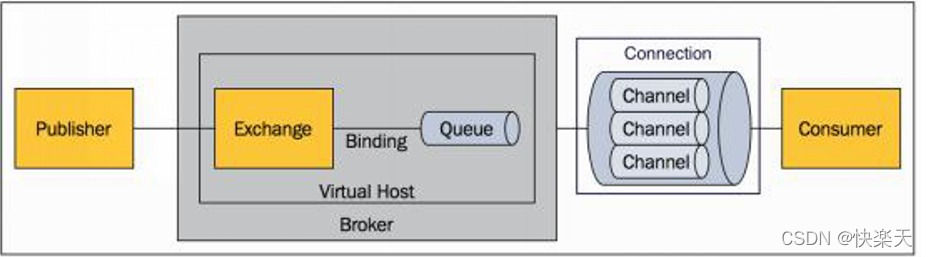
8.2.2 核心概念
Message
消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成, 这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可 能需要持久性存储)等。
Publisher
消息的生产者,也是一个向交换器发布消息的客户端应用程序。
Exchange
交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
Exchange有4种类型:direct(默认),fanout, topic, 和headers,不同类型的Exchange转发消息的策略有所区别
Queue
消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直 在队列里面,等待消费者连接到这个队列将其取走。
Binding
绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交 换器理解成一个由绑定构成的路由表。
Exchange 和Queue的绑定可以是多对多的关系。
Connection
网络连接,比如一个TCP连接。
Channel
信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,AMQP 命令都是通过信道 发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都 是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
Consumer
消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
Virtual Host
虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥 有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时 指定,RabbitMQ 默认的 vhost 是 / 。
Broker
表示消息队列服务器实体。
8.2.3 docker安装rabbitmq
安装命令:
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management
对应端口号解释:
- 4369, 25672 (Erlang发现&集群端口)
- 5672, 5671 (AMQP端口)
- 15672 (web管理后台端口)
- 61613, 61614 (STOMP协议端口)
- 1883, 8883 (MQTT协议端口)
可访问 ip地址 : 15672 访问控制页面
8.2.4 RabbitMQ运行机制
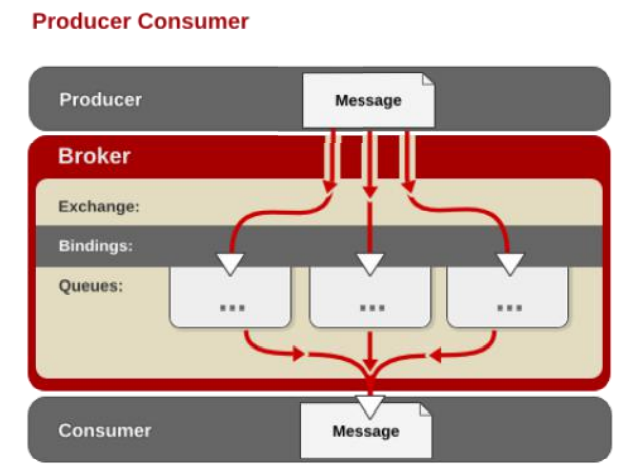
AMQP中的消息路由
AMQP 中消息的路由过程和 Java 开 发者熟悉的 JMS 存在一些差别, AMQP 中增加了 Exchange 和 Binding 的角色。
生产者把消息发布 到 Exchange 上,消息最终到达队列 并被消费者接收,而 Binding 决定交 换器的消息应该发送到那个队列。
Exchange类型
Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、 fanout、topic、headers 。
headers 匹配 AMQP 消息的 header 而不是路由键, headers 交换器和 direct 交换器完全一致,但性能差很多,目前几乎用不到了,所以直接 看另外三种类型。
Direct Exchange
消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器 就将消息发到对应的队列中。路由键与队 列名完全匹配,如果一个队列绑定到交换 机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发 “dog.puppy”,也不会转发“dog.guard” 等等。它是完全匹配、单播的模式

Fanout Exchange
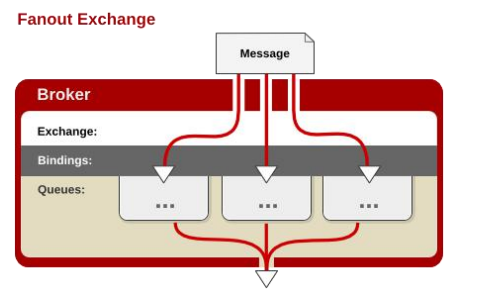
每个发到 fanout 类型交换器的消息都 会分到所有绑定的队列上去。
fanout 交换器不处理路由键,只是简单的将队列 绑定到交换器上,每个发送到交换器的 消息都会被转发到与该交换器绑定的所 有队列上。
很像子网广播,每台子网内 的主机都获得了一份复制的消息。
fanout 类型转发消息是最快的。
Topic Exchange
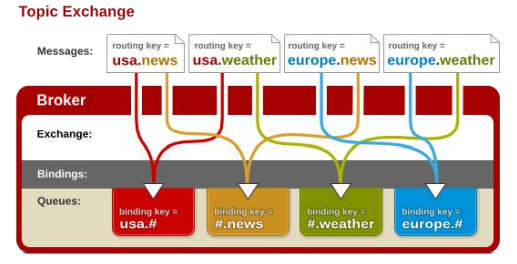
topic 交换器通过模式匹配分配消息的 路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。
它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号“*”。
#匹配0个或多个单词,* 匹配一个单词。
8.3 RabbitMQ整合SpringBoot
向pom.xml中引入springboot-starter:
<!-- 引入RabbitMQ -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
观察RabbitAutoConfiguration类可以看出,该配置类向容器中注入了几个重要的Bean对象:CachingConnectionFactory、RabbitTemplate、AmqpAdmin
(1) CachingConnectionFactory
RabbitTemplate使用CachingConnectionFactory作为连接工厂
配置类上标有这样的注解:@EnableConfigurationProperties(RabbitProperties.class)
向容器中注入CachingConnectionFactory的代码中是从配置文件中加载配置信息的。
spring.rabbitmq为配置的前缀,可以指定一些端口号,ip地址等信息。
#配置域名和端口号
spring.rabbitmq.host=192.168.190.131
spring.rabbitmq.port=5672
#配置虚拟地址
spring.rabbitmq.virtual-host=/
(2) AmqpAdmin
AmqpAdmin是org.springframework.amqp.core下的类,通过此类,可以用代码的方式创建Exchange、Queue还有Binding。
@Autowired
AmqpAdmin amqpAdmin;
@Test
public void createBinding() {
// String destination 目的地
// DestinationType destinationType 绑定类型:队列/交换机
// String exchange 交换机名称
// String routingKey 路由键
//、Map<String, Object> arguments 参数
Binding binding = new Binding("hello.queue" , Binding.DestinationType.QUEUE, "hello", "hello.queue",null);
amqpAdmin.declareBinding(binding);
}
@Test
public void createMQ() {
/**
* @param name 队列的名称
* @param durable 是否持久化队列
* @param exclusive 是否声明为一个独占队列
* @param autoDelete 如果服务不在使用时是否自动删除队列
*/
Queue queue = new Queue("hello.queue", true, false, false);
String s = amqpAdmin.declareQueue(queue);
log.info("创建queue成功... {}", queue);
}
@Test
public void createExchange() {
// String name 交换机名称
// boolean durable 是否持久化
// boolean autoDelete 是否自动删除
Exchange exchange = new DirectExchange("hello", true, false);
amqpAdmin.declareExchange(exchange);
log.info("创建exchange成功...");
}
(2) RabbitTemplate
通过RabbitTemplate类中的方法,可以像使用Rabbit客户端一样向队列发送消息以及更多其他的操作,并且多个重载的”send“(发送消息)方法。
@Autowired
RabbitTemplate rabbitTemplate;
@Test
public void test() {
// 发送消息
rabbitTemplate.convertAndSend("hello", "hello.queue" ,"msg");
}
发送的消息不仅可以是一个序列化的对象,还可以是Json格式的文本数据。
通过指定不同的MessageConverter来实现,可以向容器中注入我们想要的MessageConverter从而使用。

@Configuration
public class MyRabbitConfig {
@Bean
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}
}
(3) @RabbitListener和@RabbitHandler注解
@RabbitListener注解和@RabbitHandler都可以接受消息队列中的消息,并进行处理。
@RabbitListener注解:
可以标记方法或类上进行使用
自定义方法的参数可以为以下类型:
1、Message message:原生消息详细信息。头 + 体
2、T <发送的消息的类型> 可以是我们自定义的对象
3、Channel channel :当前传输数据的信道。
@RabbitListener(queues = {"hello.queue"})
public String receiveMessage(Message message, OrderEntity content) {
//消息体信息
byte[] body = message.getBody();
// 消息头信息
MessageProperties messageProperties = message.getMessageProperties();
log.info("收到的消息: {}", content);
return "ok";
}
同时要注意:Queue可以由很多方法来监听,只要收到消息,队列就删除消息,并且只能有一个方法收到消息。并且一个方法接收消息是一个线性的操作,只有处理完一个消息之后才能接收下条消息。
@RabbitHandler注解:
@RabbitHandler标在方法上。
@RabbitHandler标记的方法结合@RabbitListener,@RabbitHandler使用可以变得更加灵活。
比如说,当两个方法对一个消息队列进行监听时,用于监听的两个方法用于接收消息内容的参数不同,根据消息的内容可以自动的确定使用那个方法。
@Slf4j
@Controller
@RabbitListener(queues = {"hello.queue"})
public class RabbitController {
@RabbitHandler
public String receiveMessage(Message message, OrderReturnReasonEntity content) {
//消息体信息
byte[] body = message.getBody();
// 消息头信息
MessageProperties messageProperties = message.getMessageProperties();
log.info("收到的消息: {}", content);
return "ok";
}
@RabbitHandler
public String receiveMessage2(Message message, OrderEntity content) {
//消息体信息
byte[] body = message.getBody();
// 消息头信息
MessageProperties messageProperties = message.getMessageProperties();
log.info("收到的消息: {}", content);
return "ok";
}
}
8.4 RabbitMQ消息确认机制
概念:
-
保证消息不丢失,可靠抵达,可以使用事务消息,但是性能会下降250倍,为此引入确认机制
-
publisher confirmCallback 确认模式
-
publisher returnCallback 未投递到 queue 退回模式
-
consumer ack机制
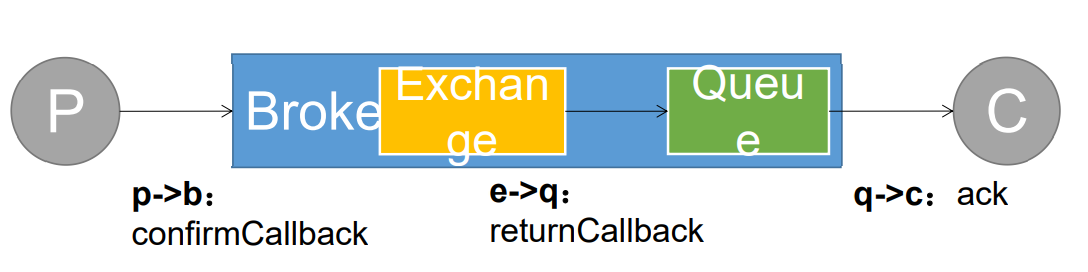
8.4.1 消息确认机制-可靠抵达(发送端)
① ConfirmCallback
ConfirmCallback和RetruhnCallback一样都是RabbitTemplate内部的接口。
消息只要被 broker 接收到就会执行 confirmCallback,如果是 cluster 模式,需要所有 broker 接收到才会调用 confirmCallback。
也就是说当消息到达RabbitMQ的服务器就会执行回调方法。
首先需要修改配置文件:
spring.rabbitmq.publisher-confirms=true
然后准备一个发送消息使用的接口和两个用来监听消息队列并接收消息的方法
发送消息接口:
@RestController
public class SendMsgController {
@Autowired
RabbitTemplate rabbitTemplate;
@GetMapping("/sendMsg")
public String sendMsg() {
for (int i = 0; i < 10; i++) {
if (i % 2 == 0) {
OrderEntity orderEntity = new OrderEntity();
orderEntity.setId(1L);
orderEntity.setMemberUsername("Tom");
orderEntity.setReceiveTime(new Date());
rabbitTemplate.convertAndSend("hello-java-exchange", "hello.news", orderEntity, new CorrelationData(UUID.randomUUID().toString()));
} else {
OrderReturnReasonEntity orderReturnReasonEntity = new OrderReturnReasonEntity();
orderReturnReasonEntity.setCreateTime(new Date());
orderReturnReasonEntity.setId(2L);
orderReturnReasonEntity.setName("test");
orderReturnReasonEntity.setSort(1);
rabbitTemplate.convertAndSend("hello-java-exchange", "hello.news", orderReturnReasonEntity, new CorrelationData(UUID.randomUUID().toString()));
}
}
return "ok";
}
}
监听消息队列并接收消息的方法:
@RabbitListener(queues = {"hello.news"})
@Slf4j
@Service("orderItemService")
public class OrderItemServiceImpl extends ServiceImpl<OrderItemDao, OrderItemEntity> implements OrderItemService {
@RabbitHandler
public void receiveMessage1(Message message, OrderReturnReasonEntity content, Channel channel) {
//消息体信息
byte[] body = message.getBody();
// 消息头信息
MessageProperties messageProperties = message.getMessageProperties();
System.out.println("receiveMessage1 接收消息: " + content);
}
@RabbitHandler
public void receiveMessage2(Message message, OrderEntity content, Channel channel) {
//消息体信息
byte[] body = message.getBody();
// 消息头信息
MessageProperties messageProperties = message.getMessageProperties();
System.out.println("receiveMessage2 接收消息: " + content);
}
}
第三步,在配置类中定制RedisTemplate:
@Configuration
public class MyRabbitConfig {
@Autowired
RabbitTemplate rabbitTemplate;
@PostConstruct // 该注解表示在初始化构造器之后就调用,初始化定制 RabbitTemplate
public void initRabbitTemplate() {
// 设置确认回调
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
/**
*
* @param correlationData 当前消息的唯一相关数据 (这个是消息的唯一id)
* @param ack 消息是否成功收到
* @param cause 失败的原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
System.out.println("ConfirmCallback... correlationData: [" + correlationData + "] ==> ack: [" + ack + "] ==> cause: [" + cause + "]");
}
});
}
}
然后访问localhost:9000/sendMsg,就会发送消息,观察结果:
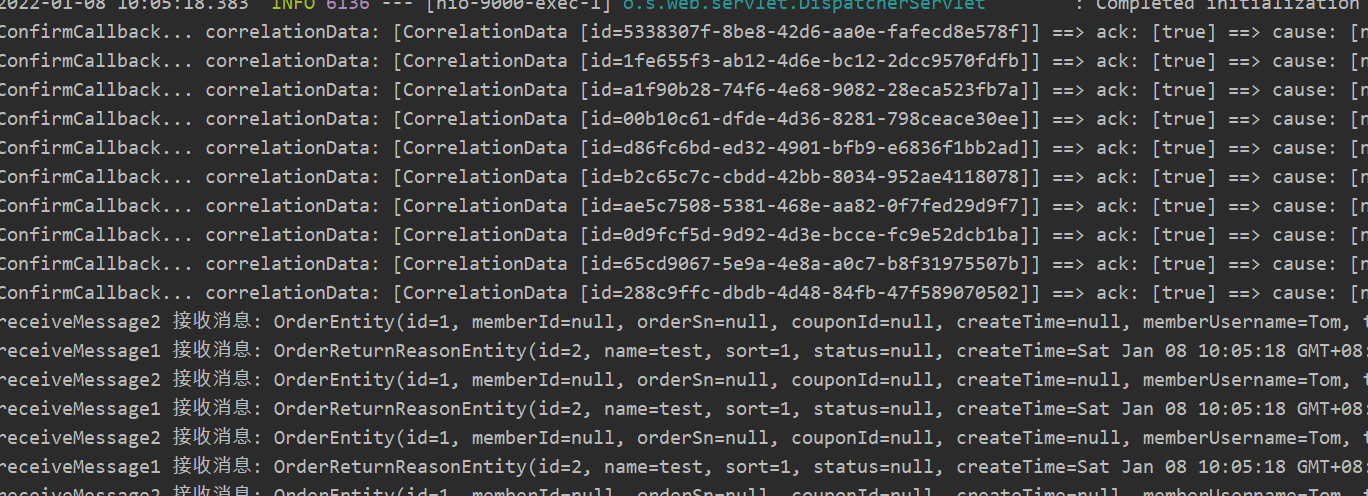
用于接收消息的两个方法都接收到了消息,并且自定义的ConfirmCallback回调方法会打印相关信息。
② ReturnCallback
被 broker 接收到只能表示 message 已经到达服务器,并不能保证消息一定会被投递到目标 queue 里。所以需要用到接下来的 returnCallback 。
如果在交换机将消息投递到queue的过程中,发生了某些问题,最终导致消息投递失败,就会触发这个方法。
为定制的RabbitTemplate添加这个方法:
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
/**
* @param message 投递失败的消息的详细信息
* @param replyCode 回复的状态码
* @param replyText 回复的文本内容
* @param exchange 但是这个消息发给哪个交换机
* @param routingKey 当时这个消息使用哪个路由键
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("FailMessage: [" + message + "] ==> replyCode: [" + replyText + "] ==> exchange: [" + exchange + "] ==> routingKey: [" + routingKey + "]");
}
});
我们在发送消息的一端故意写错路由键,致使exchange投递消息失败。最后会看到回调方法ReturnCallback中打印的内容:

FailMessage: [(Body:'{"id":2,"name":"test","sort":1,"status":null,"createTime":1641608721639}' MessageProperties [headers={spring_returned_message_correlation=b6b21f2d-73ad-473d-9639-feec76953c7b, __TypeId__=com.atguigu.gulimall.order.entity.OrderReturnReasonEntity}, contentType=application/json, contentEncoding=UTF-8, contentLength=0, receivedDeliveryMode=PERSISTENT, priority=0, deliveryTag=0])] ==> replyCode: [NO_ROUTE] ==> exchange: [hello-java-exchange] ==> routingKey: [hello.news1]
补充:在发送消息的时候还可以指定一个CorrelationData类型的参数(可以回顾上文的发送消息的方法),这个CorrelationData类的构造器参数可以填一个UUID,代表消息的唯一id,在重写ConfirmCallback中的方法的第一个参数就是这个,通过这个参数就可以获取消息的唯一id。
注意:监听方法返回值必须为void,否则控制台会不断打印报错信息。(血的教训)
8.4.2 消息确认机制-可靠抵达(消费端)
ACK(Acknowledge)消息确认机制
消费者获取到消息,成功处理,可以回复Ack给Broker
- basic.ack用于肯定确认;broker将移除此消息
- basic.nack用于否定确认;可以指定broker是否丢弃此消息,可以批量
- basic.reject用于否定确认;同上,但不能批量
在默认状况下,ACK消息确认机制是当消息一旦抵达消费方法就会直接出队(删除),但是如果在消息消费过程中服务器宕机了,这些消息也会被删除,这就造成了消息丢失的问题。
通过配置可以开启消息需要经过手动确认,才能从队列中删除消息
#手动ack消息
spring.rabbitmq.listener.simple.acknowledge-mode=manual
改写方法:
@RabbitHandler
public void receiveMessage2(Message message, OrderEntity content, Channel channel) {
//消息体信息
byte[] body = message.getBody();
// 消息头信息
MessageProperties messageProperties = message.getMessageProperties();
long deliveryTag = messageProperties.getDeliveryTag();
//手动接收消息
//long deliveryTag相当当前消息派发的标签,从messageProperties中获取,并且在Channel中自增的
//boolean multiple 是否批量确认
try {
channel.basicAck(deliveryTag, false);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("receiveMessage2 接收消息: " + content);
}
我们在上方的代码打上断点并观察RabbitMQ客户端的状况:

对中总共有5条消息,并且进入了Unacked,即未被确认的状态。
但是这里使用debug模式启动然后关掉服务模拟服务器宕机会发生一个问题,就是在关闭服务之前,idea会将未执行完的方法先执行完再关闭服务。
所以可以在cmd杀掉进程模拟宕机。
这时,由于打了断点,没有走到消息确认的那一行代码,随机,服务器宕机,所有没有确认的消息都会从Unacked的状态回调Ready的状态。
有接收消息的方法就有拒绝消息的方法:basicNack和basicReject
//long deliveryTag 当前消息派发的标签
//boolean multiple 是否批量处理
//boolean requeue 拒绝后是否将消息重新入队
channel.basicNack(deliveryTag, false, true);
channel.basicReject(deliveryTag, true);
basicNack和basicReject都可以用来拒绝消息,但是basicNack比basicReject多了一个参数boolean multiple(是否批量处理)
如果将requeue设置为true,被拒绝的消息就会重新入队等待消费。
8.5 RabbitMQ延时队列(实现定时任务)
场景:
比如未付款订单,超过一定时间后,系统自动取消订单并释放占有物品。
常用解决方案:
spring的 schedule 定时任务轮询数据库
缺点:
消耗系统内存、增加了数据库的压力、存在较大的时间误差
解决:rabbitmq的消息TTL和死信Exchange结合
(1) 消息的TTL(Time To Live)
消息的TTL就是消息的存活时间。
RabbitMQ可以对队列和消息分别设置TTL。
对队列设置就是队列没有消费者连着的保留时间,也可以对每一个单独的消息做单独的设置。超过了这个时间,我们认为这个消息就死了,称之为死信。
如果队列设置了,消息也设置了,那么会取小的。所以一个消息如果被路由到不同的队列中,这个消息死亡的时间有可能不一样(不同的队列设置)。这里单讲单个消息的
TTL,因为它才是实现延迟任务的关键。可以通过设置消息的expiration字段或者x-message-ttl属性来设置时间,两者是一样的效果。
(2) Dead Letter Exchanges(DLX)死信路由
一个消息在满足如下条件下,会进死信路由,记住这里是路由而不是队列, 一个路由可以对应很多队列。
什么是死信?
- 一个消息被Consumer拒收了,并且reject方法的参数里requeue是false。也就是说不 会被再次放在队列里,被其他消费者使用。*(basic.reject/ basic.nack)*requeue=false
- 上面的消息的TTL到了,消息过期了。
- 队列的长度限制满了。排在前面的消息会被丢弃或者扔到死信路由上。
**Dead Letter Exchange(死信路由)**其实就是一种普通的exchange,和创建其他exchange没有两样。只是在某一个设置Dead Letter Exchange的队列中有 消息过期了,会自动触发消息的转发,发送到Dead Letter Exchange中去。
我们既可以控制消息在一段时间后变成死信,又可以控制变成死信的消息 被路由到某一个指定的交换机,结合二者,其实就可以实现一个延时队列。
手动ack&异常消息统一放在一个队列处理建议的两种方式
- catch异常后,手动发送到指定队列,然后使用channel给rabbitmq确认消息已消费
- 给Queue绑定死信队列,使用nack(requque为false)确认消息消费失败
延时队列的实现:
方式一:设置一个有过期时间的消息队列

方式二:发送的消息赋予过期时间。
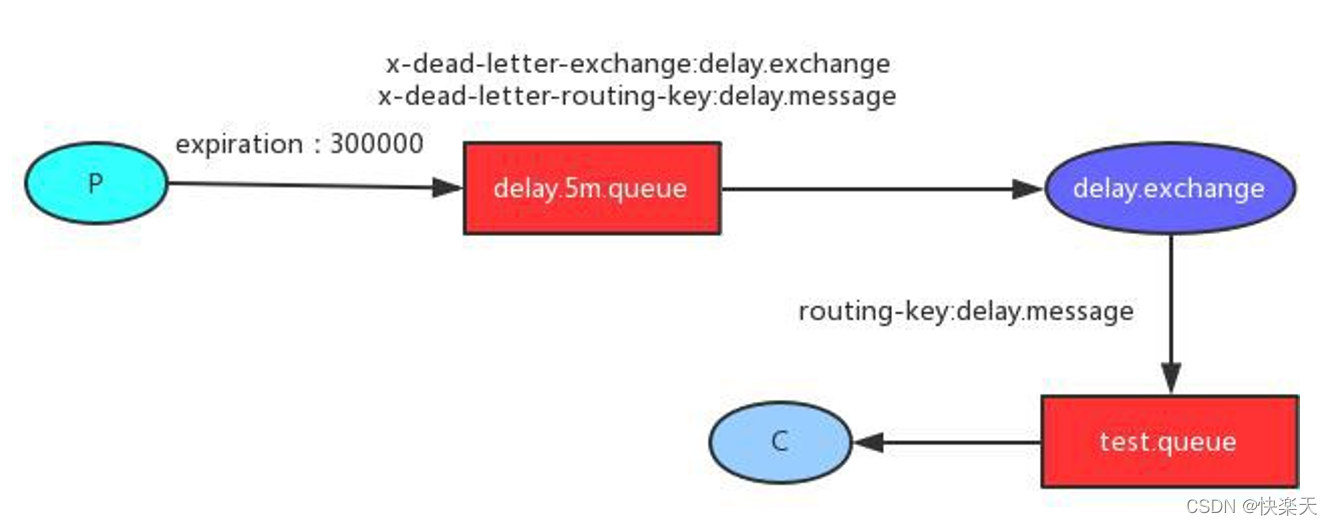
但是基于RabbitMQ对消息的惰性处理,通常选择方式一。
(3) 延迟消息队列样例测试
示意图:
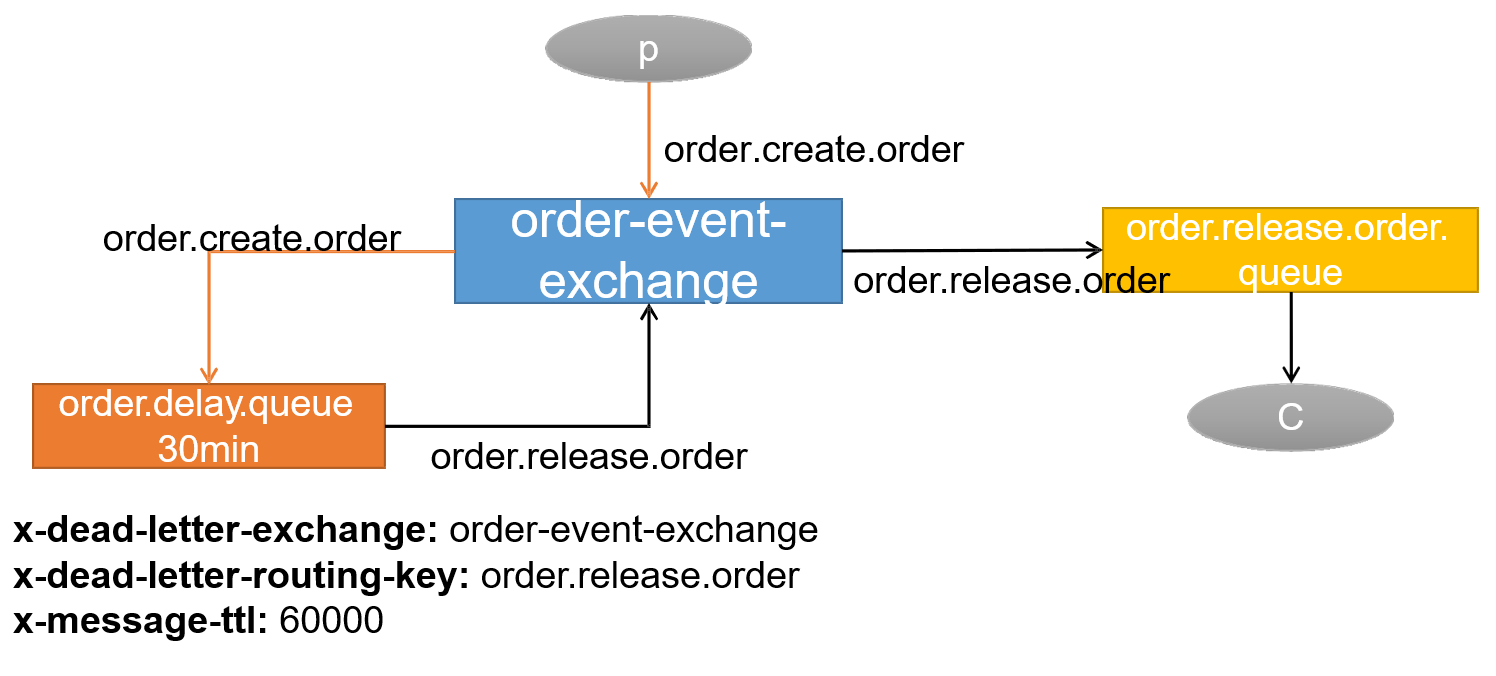
如果没有RabbitMQ中没有创建过消息队列、交换机等,可以通过@Bean注入容器的方式创建。
配置类:
@Configuration
public class MyRabbitMQConfig {
@Bean
public Queue orderDelayQueue() {
/*
Queue(String name, 队列名字
boolean durable, 是否持久化
boolean exclusive, 是否排他
boolean autoDelete, 是否自动删除
Map<String, Object> arguments) 属性
*/
Map<String, Object> arguments = new HashMap<String, Object>();
arguments.put("x-dead-letter-exchange", "order-event-exchange");
arguments.put("x-dead-letter-routing-key", "order.release.order");
arguments.put("x-message-ttl", 60000);
return new Queue("order.delay.queue", true, false, false, arguments);
}
@Bean
public Queue orderReleaseOrderQueue() {
return new Queue("order.release.order.queue", true, false, false);
}
/**
* TopicExchange
* @return
*/
@Bean
public Exchange orderEventExchange() {
/**
* String name,
* boolean durable,
* boolean autoDelete,
* Map<String, Object> arguments
*/
return new TopicExchange("order-event-exchange", true, false);
}
@Bean
public Binding orderCreateBinding() {
/*
* String destination, 目的地(队列名或者交换机名字)
* DestinationType destinationType, 目的地类型(Queue、Exhcange)
* String exchange,
* String routingKey,
* Map<String, Object> arguments
* */
return new Binding("order.delay.queue",
Binding.DestinationType.QUEUE,
"order-event-exchange",
"order.create.order",
null);
}
@Bean
public Binding orderReleaseBinding() {
return new Binding("order.release.order.queue",
Binding.DestinationType.QUEUE,
"order-event-exchange",
"order.release.order",
null);
}
}
发送和接收消息的方法:
@Autowired
RabbitTemplate rabbitTemplate;
@RabbitListener(queues = "order.release.order.queue")
public void listener(Message message, Channel channel, OrderEntity entity) throws IOException {
System.out.println("收到过期的消息,准备关闭的订单:" + entity.getOrderSn());
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}
@ResponseBody
@GetMapping("/test/createOrder")
public String testCreateOrder() {
OrderEntity entity = new OrderEntity();
// 设置订单号
entity.setOrderSn(UUID.randomUUID().toString());
entity.setCreateTime(new Date());
rabbitTemplate.convertAndSend("order-event-exchange",
"order.create.order",
entity);
return "ok";
}
8.6 消息丢失、重复、积压问题
1、消息丢失
(1) 消息发送出去,因为网络问题没有抵达服务器
解决方案:
- 做好容错方法(try-catch),发送消息可能会网络失败,失败后要有重试机制,可记录到数据库,采用定期扫描重发的方式。
- 做好日志记录,每个消息状态是否都被服务器收到都应该记录。
- 做好定期重发,如果消息没有发送成功,定期去数据库扫描未成功的消息进行重发。
(2) 消息抵达Broker,Broker要将消息写入磁盘(持久化)才算成功。此时Broker尚未持久化完成,宕机
解决方案:
- publisher也必须加入确认回调机制,确认成功的消息,修改数据库消息状态。
(3) 自动ACK的状态下。消费者收到消息,但没来得及消息然后宕机
- 一定开启手动ACK,消费成功才移除,失败或者没来得及处理就NoAck并重新入队
2、消息重复
(1) 消息消费成功,事务已经提交,ack时,机器宕机。导致没有ack成功,Broker的消息重新由unack变为ready,并发送给其他消费者。
(2) 消息消费失败,由于重试机制,自动又将消息发送出去
(3) 成功消费,ack时宕机,消息由unack变为ready,Broker又重新发送
解决方案:
- 消费者的业务消费接口应该设计为幂等性的。比如扣库存有 工作单的状态标志。
- 使用防重表(redis/mysql),发送消息每一个都有业务的唯 一标识,处理过就不用处理。
- rabbitMQ的每一个消息都有redelivered字段,可以获取是否是被重新投递过来的,而不是第一次投递过来的。
3、消息积压
(1) 消费者宕机积压
(2) 消费者消费能力不足积压
(3) 发送者发送流量太大
解决方案:
- 上线更多的消费者,进行正常消费
- 上线专门的队列消费服务,将消息先批量取出来,记录数据库,离线慢慢处理
九、订单服务
9.1 Feign远程调用丢失请求头问题
根据业务流程,为了将购物车中的购物项都封装进OrderConfirmVo对象中,需要进行远程调用Cart服务获取购物项信息,在进行远程调用的时候没有传入用户的ID信息,而是通过用户进入订单结算页面的这次请求中的请求头获取Cookie中的信息,从而获取用户ID等相关信息,但是使用Feign进行远程调用的时候就相当于一次新的请求,会丢失原来请求中的请求头信息。
为了解决Feign远程调用丢失请求头的问题,参考Feign相关源码,在Feign送请求之前会先执行拦截器方法,然后再发送请求,所以自定义一个拦截器,在Feign发送请求之前都先调用自定义的拦截器方法,向Feign的请求中加入原本的请求头信息。
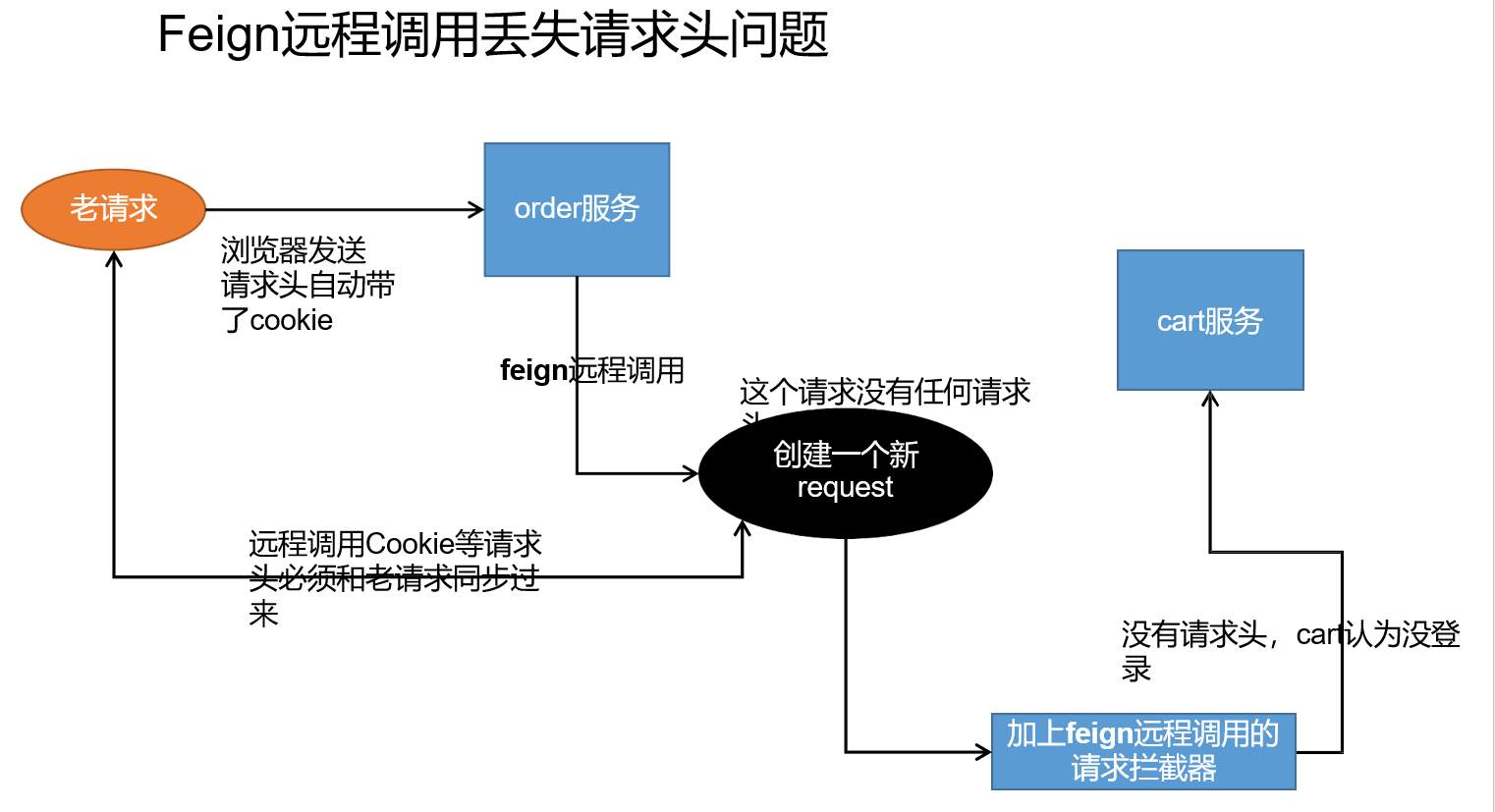
拦截器的编写:
@Configuration
public class GuliFeignConfig {
/**
* 向容器中添加feign的拦截器
* @return
*/
@Bean("requestInterceptor")
public RequestInterceptor requestInterceptor() {
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate requestTemplate) {
// 同步请求头
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
String cookie = request.getHeader("Cookie");
//给feign发出的新请求同步了老请求的cookie
requestTemplate.header("Cookie", cookie);
}
};
}
}
9.2 Feign异步调用丢失请求头问题
在获取订单信息的逻辑中,需要远程调用多个服务才能获取到数据,所以这里需要使用异步操作,但是在拦截器中就会发生空指针的错误,request对象获取不到,是null。

愿意如上图:因为我们给使用拦截器给Feign的请求加上请求头,但是这个获取请求头的过程是在一个线程执行过程中进行的,但是我们进行的是异步操作,使用到了线程池,这就导致请求头不在一个线程中,最终导致请求头信息丢失。
解决方案: 现在主线程中获取到请求头相关信息,然后再异步调用的过程中将情求头加到正在执行异步操作的线程中,这样,请求头就不会丢失。
//从主线程中获取请求头信息
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
CompletableFuture<Void> getAddressesFuture = CompletableFuture.runAsync(() -> {
RequestContextHolder.setRequestAttributes(requestAttributes);
//获取用户地址信息
List<MemberAddressVo> addresses = memberFeignService.getAddresses(memberRespVo.getId());
orderConfirmVo.setAddress(addresses);
}, executor);
9.3 接口幂等性
1、什么是幂等性
接口幂等性就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用;比如说支付场景,用户购买了商品支付扣款成功,但是返回结果的时候网络异常,此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额返发现多扣钱了,流水记录也变成了两条,这就没有保证接口的幂等性。
简单来说就是无论多少次重复的操作,结果都是一样的。就像数字 1 的无论多少次幂,结果都是 1 。
2、那些情况需要防止
用户多次点击按钮
用户页面回退再次提交
微服务互相调用,由于网络问题,导致请求失败。
feign 触发重试机制 其他业务情况
3、什么情况下需要幂等
以 SQL 为例,有些操作是天然幂等的。
SELECT * FROM table WHER id=?,无论执行多少次都不会改变状态,是天然的幂等。
UPDATE tab1 SET col1=1 WHERE col2=2,无论执行成功多少次状态都是一致的,也是幂等操作。
delete from user where userid=1,多次操作,结果一样,具备幂等性。
insert into user(userid,name) values(1,'a') 如 userid 为唯一主键,即重复操作上面的业务,只 会插入一条用户数据,具备幂等性。
UPDATE tab1 SET col1=col1+1 WHERE col2=2,每次执行的结果都会发生变化,不是幂等的。
insert into user(userid,name) values(1,'a') 如 userid 不是主键,可以重复,那上面业务多次操 作,数据都会新增多条,不具备幂等性。
4、幂等的解决方案
(1) Token机制
① 服务端提供了发送 token 的接口。我们在分析业务的时候,哪些业务是存在幂等问题的, 就必须在执行业务前,先去获取 token,服务器会把 token 保存到 redis 中。
② 然后调用业务接口请求时,把 token 携带过去,一般放在请求头部。
③ 服务器判断 token 是否存在 redis 中,存在表示第一次请求,然后删除 token, 继续执行业务。
④ 如果判断 token 不存在 redis 中,就表示是重复操作,直接返回重复标记给 client,这样就保证了业务代码,不被重复执行。
危险性:
① 先删除 token 还是后删除 token
-
先删除可能导致,业务确实没有执行,重试还带上之前 token,由于防重设计导致,请求还是不能执行。
-
后删除可能导致,业务处理成功,但是服务闪断,出现超时,没有删除 token,别人继续重试,导致业务被执行两遍。
-
我们最好设计为先删除 token,如果业务调用失败,就重新获取 token 再次请求。
② Token 获取、比较和删除必须是原子性
redis.get(token) 、token.equals、redis.del(token)如果这几个操作不是原子,可能导致高并发下,都 get 到同样的数据,判断都成功,继续业务并发执行。
所以可以在 redis 使用 lua 脚本完成这个操作:
if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end
(2) 各种锁机制
1、数据库的悲观锁
select * from xxx where id = 1 for update;
悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,需要根据实际情况选用。 另外要注意的是,id 字段一定是主键或者唯一索引,不然可能造成锁表的结果,处理起来会 非常麻烦。
2、数据库的乐观锁
这种方法适合在更新的场景中:
update t_goods set count = count -1 , version = version + 1 where good_id=2 and versio
根据 version 版本,也就是在操作库存前先获取当前商品的 version 版本号,然后操作的时候 带上此 version 号。我们梳理下,我们第一次操作库存时,得到version 为 1,调用库存服务 version 变成了 2;但返回给订单服务出现了问题,订单服务又一次发起调用库存服务,当订单服务传如的 version 还是 1,再执行上面的 sql 语句时,就不会执行;因为 version 已经变 为 2 了,where 条件就不成立。这样就保证了不管调用几次,只会真正的处理一次。 乐观锁主要使用于处理读多写少的问题。
(3) 业务层分布式锁
如果多个机器可能在同一时间同时处理相同的数据,比如多台机器定时任务都拿到了相同数据处理,我们就可以加分布式锁,锁定此数据,处理完成后释放锁。获取到锁的必须先判断 这个数据是否被处理过。
(4) 各种唯一约束
① 数据库唯一约束
插入数据,应该按照唯一索引进行插入,比如订单号,相同的订单就不可能有两条记录插入。 我们在数据库层面防止重复。
这个机制是利用了数据库的主键唯一约束的特性,解决了在 insert 场景时幂等问题。但主键 的要求不是自增的主键,这样就需要业务生成全局唯一的主键。
如果是分库分表场景下,路由规则要保证相同请求下,落地在同一个数据库和同一表中,要 不然数据库主键约束就不起效果了,因为是不同的数据库和表主键不相关。
② redis set 防重
很多数据需要处理,只能被处理一次,比如我们可以计算数据的 MD5 将其放入 redis 的 set, 每次处理数据,先看这个 MD5 是否已经存在,存在就不处理。
(5) 防重表
使用订单号 orderNo 做为去重表的唯一索引,把唯一索引插入去重表,再进行业务操作,且 他们在同一个事务中。这个保证了重复请求时,因为去重表有唯一约束,导致请求失败,避免了幂等问题。这里要注意的是,去重表和业务表应该在同一库中,这样就保证了在同一个事务,即使业务操作失败了,也会把去重表的数据回滚。这个很好的保证了数据一致性。
之前说的 redis 防重也算。
(6) 全局请求唯一 id
调用接口时,生成一个唯一 id,redis 将数据保存到集合中(去重),存在即处理过。
可以使用 nginx 设置每一个请求的唯一 id。
proxy_set_header X-Request-Id $request_id
十、分布式事务
10.1 本地事务
1、事务的基本性质
数据库事务的几个特性:原子性(Atomicity)、一致性(Consistency)、隔离性或独立性(Isolation) 和持久性(Durabilily),简称就是 ACID。
-
原子性:一系列的操作整体不可拆分,要么同时成功,要么同时失败
-
一致性:数据在事务的前后,业务整体一致。
-
隔离性:事务之间互相隔离。
-
持久性:一旦事务成功,数据一定会落盘在数据库。
在以往的单体应用中,我们多个业务操作使用同一条连接操作不同的数据表,一旦有异常, 我们可以很容易的整体回滚。
- Business:我们具体的业务代码
- Storage:库存业务代码;扣库存
- Order:订单业务代码;保存订单
- Account:账号业务代码;减账户余额
比如买东西业务,扣库存,下订单,账户扣款,是一个整体;必须同时成功或者失败。
一个事务开始,代表以下的所有操作都在同一个连接里面。
2、事务的隔离级别
READ UNCOMMITTED(读未提交)
该隔离级别的事务会读到其它未提交事务的数据,此现象也称之为脏读。
READ COMMITTED(读已提交)
一个事务可以读取另一个已提交的事务,多次读取会造成不一样的结果,此现象称为不可重复读问题,Oracle 和 SQL Server 的默认隔离级别。
REPEATABLE READ(可重复读)
该隔离级别是 MySQL 默认的隔离级别,在同一个事务里,select 的结果是事务开始时时间点的状态,因此,同样的select操作读到的结果会是一致的,但是,会有幻读现象。MySQL 的 InnoDB 引擎可以通过 next-key locks 机制(参考下文"行锁的算法"一节)来避免幻读。
在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
当隔离级别设置为REPEATABLE READ 时,可以避免不可重复读。当A拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),A的老婆就不可能对该记录进行修改,也就是A的老婆不能在此时转账。
幻读(前后多次读取,数据总量不一致):
事务A在执行读取操作,需要两次统计数据的总量,前一次查询数据总量后,此时事务B执行了新增数据的操作并提交后,这个时候事务A读取的数据总量和之前统计的不一样,就像产生了幻觉一样,平白无故的多了几条数据,成为幻读。
SERIALIZABLE(序列化)
在该隔离级别下事务都是串行顺序执行的,MySQL 数据库的 InnoDB 引擎会给读操作隐式加一把读共享锁,从而避免了脏读、不可重读复读和幻读问题。
不可重复读和脏读的区别是:脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
3、事务的传播行为
1、PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
2、PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
3、PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
4、PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
5、PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当 前事务挂起。
6、PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
7、PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与 PROPAGATION_REQUIRED 类似的操作。
4、SpringBoot事务的关键点
(1)事务的自动配置
TransactionAutoConfiguration
(2)事务的问题
在同一个类里面,编写两个方法,内部调用的时候,会导致事务设置失效。原因是没有用到代理对象的缘故。
① 引入spring-boot-starter-aop
② 开启@EnableTransactionManagement(proxyTargetClass = true)
③ 开启@EnableAspectJAutoProxy(exposeProxy=true)
④ 在使用方法时使用AopContext.currentProxy()调用方法
public void a() {
//可以直接强制类型转换,因为AopContext.currentProxy获取的就是当前类的代理对象
XxxServiceImpl o = (XxxServiceImpl)AopContext.currentProxy();
o.b();
o.c();
}
public void b() {
System.out.println("b...");
}
public void c() {
System.out.println("c...");
}
10.2 分布式事务
1、为什么要有分布式事务
分布式系统经常出现的异常
机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的 TCP、存储数据丢失…
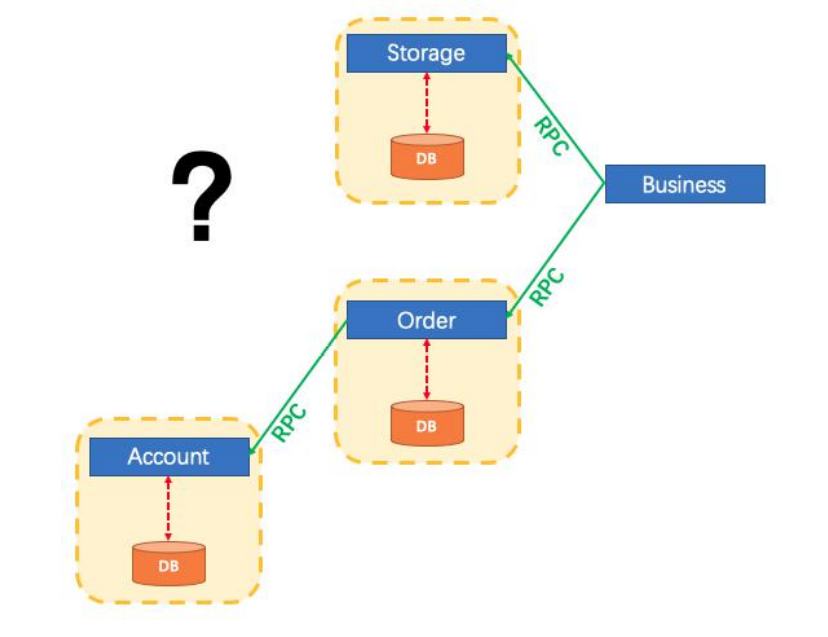
分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个 东西,特别是在微服务架构中,几乎可以说是无法避免。
2、CAP定理与 BASE 理论
(1) CAP定理
CAP 原则又称 CAP 定理,指的是在一个分布式系统中
① 一致性(Consistency)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访 问同一份最新的数据副本)
② 可用性(Availability)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据 更新具备高可用性)
③ 分区容错性(Partition tolerance)
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。 分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务 器放在美国,这就是两个区,它们之间可能无法通信。
CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
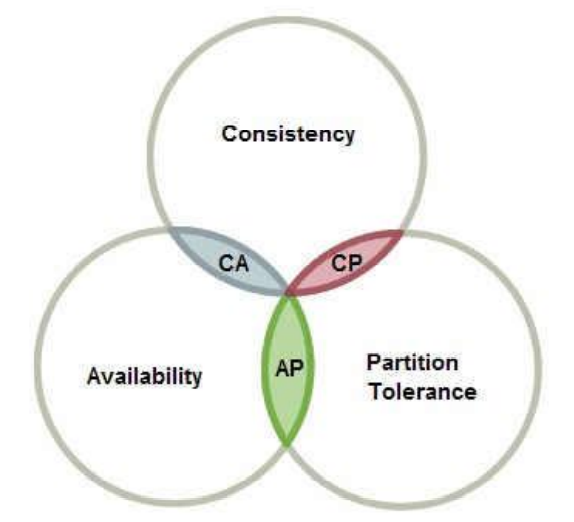
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们, 剩下的 C 和 A 无法同时做到。
可以参考文章:https://blog.csdn.net/chen77716/article/details/30635543
分布式系统中实现一致性的 raft 、paxos
raft动画演示:
Raft (thesecretlivesofdata.com)
(2) 面临的问题
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到 99.99999%(N 个 9),即保证 P 和 A,舍弃 C。
(3) BASE 理论
是对 CAP 理论的延伸,思想是即使无法做到强一致性(CAP 的一致性就是强一致性),但可 以采用适当的采取弱一致性,即最终一致性。
BASE 是指:
基本可用(Basically Available):
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、 功能上的可用性),允许损失部分可用性。需要注意的是,基本可用绝不等价于系统不可用。
- 响应时间上的损失:正常情况下搜索引擎需要在 0.5 秒之内返回给用户相应的 查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了 1~2 秒。
- 功能上的损失:购物网站在购物高峰(如双十一)时,为了保护系统的稳定性, 部分消费者可能会被引导到一个降级页面。
软状态( Soft State):
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体 现。mysql replication 的异步复制也是一种体现。
最终一致性( Eventual Consistency):
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
(4) 强一致性、弱一致性、最终一致性
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求 能访问到更新后的数据,则是最终一致性。
3、分布式事务的几种解决方案
(1) 2PC模式
数据库支持的 2PC【2 phase commit 二阶提交】,又叫做 XA Transactions。 MySQL 从 5.5 版本开始支持,SQL Server 2005 开始支持,Oracle 7 开始支持。 其中,XA 是一个两阶段提交协议,该协议分为以下两个阶段:
第一阶段:事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是 否可以提交.
第二阶段:事务协调器要求每个数据库提交数据。 其中,如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务 中的那部分信息。
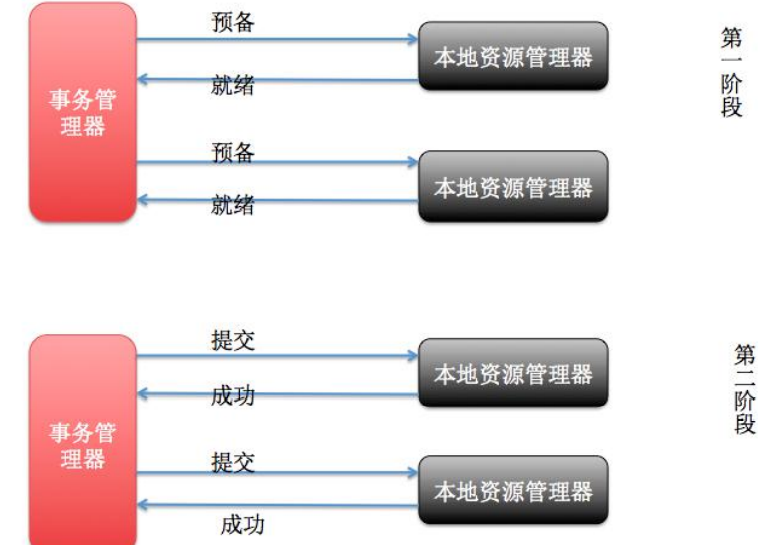
- XA 协议比较简单,而且一旦商业数据库实现了 XA 协议,使用分布式事务的成本也比较 低。
- XA 性能不理想,特别是在交易下单链路,往往并发量很高,XA 无法满足高并发场景
- XA 目前在商业数据库支持的比较理想,在 mysql 数据库中支持的不太理想,mysql 的 XA 实现,没有记录 prepare 阶段日志,主备切换回导致主库与备库数据不一致。
- 许多 nosql 也没有支持 XA,这让 XA 的应用场景变得非常狭隘
- 也有 3PC,引入了超时机制(无论协调者还是参与者,在向对方发送请求后,若长时间 未收到回应则做出相应处理)
(2) 柔性事务-TCC 事务补偿型方案
刚性事务:遵循 ACID 原则,强一致性
柔性事务:遵循 BASE,最终一致性
与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。
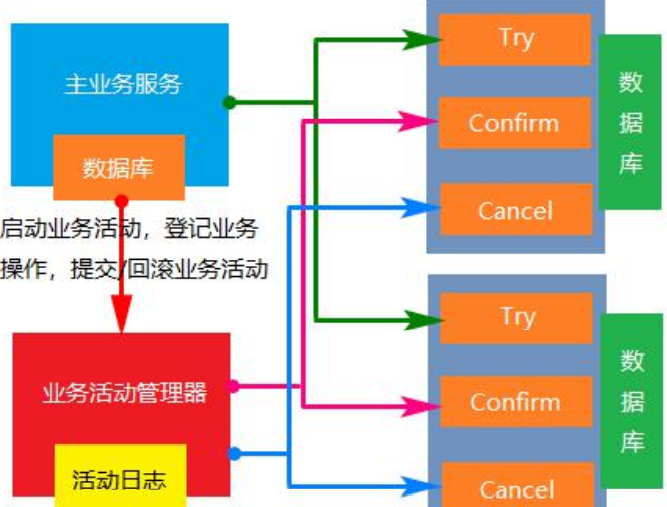
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。

(3) 柔性事务-最大努力通知型方案
按规律进行通知,不保证数据一定能通知成功,但会提供可查询操作接口进行核对。这种方案主要用在与第三方系统通讯时,比如:调用微信或支付宝支付后的支付结果通知。这种方案也是结合 MQ 进行实现,例如:通过 MQ 发送 http 请求,设置最大通知次数。达到通知次数后即不再通知。
案例:银行通知、商户通知等(各大交易业务平台间的商户通知:多次通知、查询校对、对账文件),支付宝的支付成功异步回调。
(4) 柔性事务-可靠消息+最终一致性方案(异步确保型)
实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不是真正的发送。业务处理服务在业务事务提交之后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才会真正发送。
10.3 Seata
谷粒商城使用Seata作为分布式事务的解决方案。
Seata的使用逻辑:
1、在每一个涉及到分布式事务的相关数据库创建一张叫undo_log的表:
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2、安装事务协调器:seata-server
从Seata官网下载。
更多操作可以参考官方文档。
十一、支付&内网穿透
1、支付
进入蚂蚁金服开放平台,获取支付宝支付的相关接口。
将相关的配置和方法抽取为一个配置类:
@ConfigurationProperties(prefix = "alipay")
@Component
@Data
public class AlipayTemplate {
// 应用ID,您的APPID,收款账号既是您的APPID对应支付宝账号
public String app_id;
// 商户私钥,您的PKCS8格式RSA2私钥
public String merchant_private_key;
// 支付宝公钥,查看地址:https://openhome.alipay.com/platform/keyManage.htm 对应APPID下的支付宝公钥。
public String alipay_public_key;
// 服务器[异步通知]页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问
// 支付宝会悄悄的给我们发送一个请求,告诉我们支付成功的信息
public String notify_url;
// 页面跳转同步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问
//同步通知,支付成功,一般跳转到成功页
public String return_url;
// 签名方式
private String sign_type;
// 字符编码格式
private String charset;
//订单超时时间
private String timeout = "1m";
// 支付宝网关; https://openapi.alipaydev.com/gateway.do
public String gatewayUrl;
public String pay(PayVo vo) throws AlipayApiException {
//AlipayClient alipayClient = new DefaultAlipayClient(AlipayTemplate.gatewayUrl, AlipayTemplate.app_id, AlipayTemplate.merchant_private_key, "json", AlipayTemplate.charset, AlipayTemplate.alipay_public_key, AlipayTemplate.sign_type);
//1、根据支付宝的配置生成一个支付客户端
AlipayClient alipayClient = new DefaultAlipayClient(gatewayUrl,
app_id, merchant_private_key, "json",
charset, alipay_public_key, sign_type);
//2、创建一个支付请求 //设置请求参数
AlipayTradePagePayRequest alipayRequest = new AlipayTradePagePayRequest();
alipayRequest.setReturnUrl(return_url);
alipayRequest.setNotifyUrl(notify_url);
//商户订单号,商户网站订单系统中唯一订单号,必填
String out_trade_no = vo.getOut_trade_no();
//付款金额,必填
String total_amount = vo.getTotal_amount();
//订单名称,必填
String subject = vo.getSubject();
//商品描述,可空
String body = vo.getBody();
alipayRequest.setBizContent("{\"out_trade_no\":\""+ out_trade_no +"\","
+ "\"total_amount\":\""+ total_amount +"\","
+ "\"subject\":\""+ subject +"\","
+ "\"body\":\""+ body +"\","
+ "\"timeout_express\":\""+timeout+"\","
+ "\"product_code\":\"FAST_INSTANT_TRADE_PAY\"}");
String result = alipayClient.pageExecute(alipayRequest).getBody();
//会收到支付宝的响应,响应的是一个页面,只要浏览器显示这个页面,就会自动来到支付宝的收银台页面
System.out.println("支付宝的响应:"+result);
return result;
}
}
要使用时可以直接自动注入的方式使用。
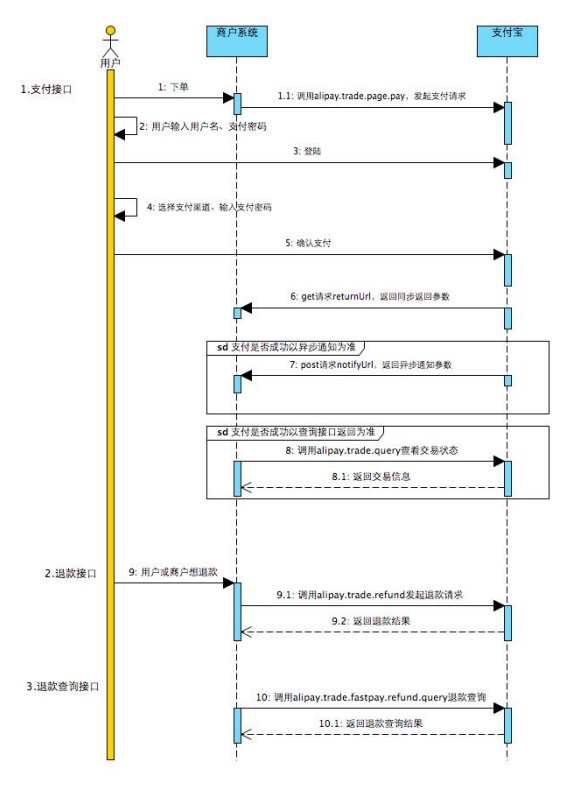
2、内网穿透
内网穿透功能可以允许我们使用外网的网址来访问主机;
正常的外网需要访问我们项目的流程是:
1、买服务器并且有公网固定 IP
2、买域名映射到服务器的 IP
3、域名需要进行备案和审核
所以使用内网穿透来实现相同的功能,这里使用花生壳。
原理:
内网穿透的服务商将他们的子域名租借给我们使用,在使用时只需要配置相关的本机地址和端口号并创建一个映射,就可以通过公网ip访问本机的服务了。
十二、秒杀服务
1、秒杀业务
秒杀具有瞬间高并发的特点,针对这一特点,必须要做限流 + 异步 + 缓存(页面静态化) + 独立部署。
限流方式:
-
前端限流,一些高并发的网站直接在前端页面开始限流,例如:小米的验证码设计
-
nginx 限流,直接负载部分请求到错误的静态页面:令牌算法 漏斗算法
-
网关限流,限流的过滤器
-
代码中使用分布式信号量
-
rabbitmq 限流(能者多劳:chanel.basicQos(1)),保证发挥所有服务器的性能
2、秒杀流程
秒杀商品发放流程:

秒杀流程:
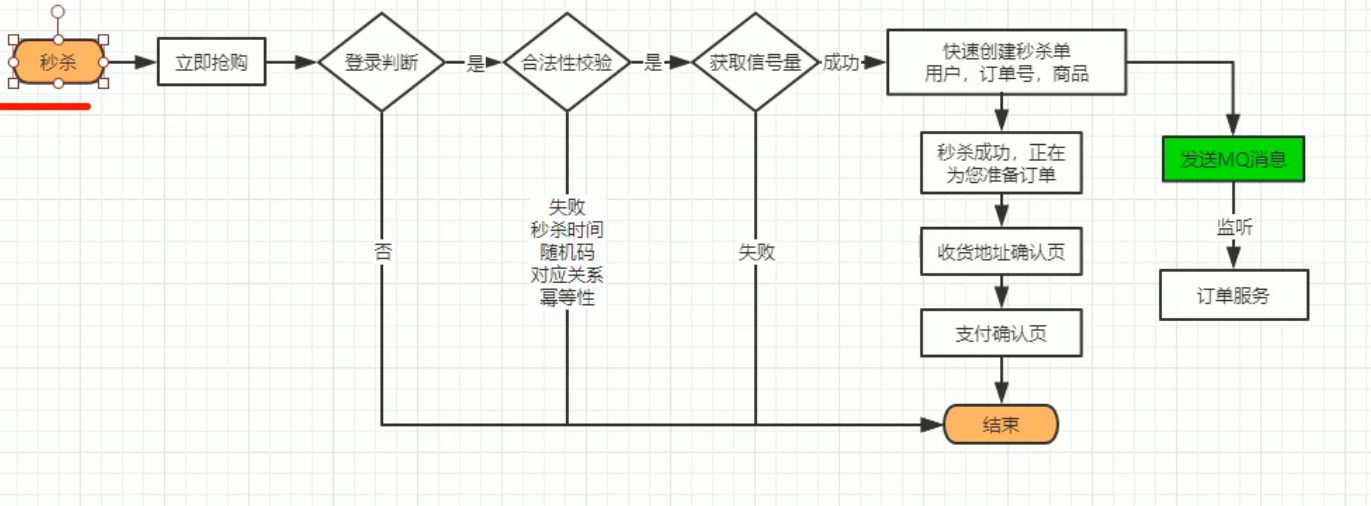
秒杀过程中,需要保证幂等性,每个用户只能秒杀一次,其他的返回结构都一致。
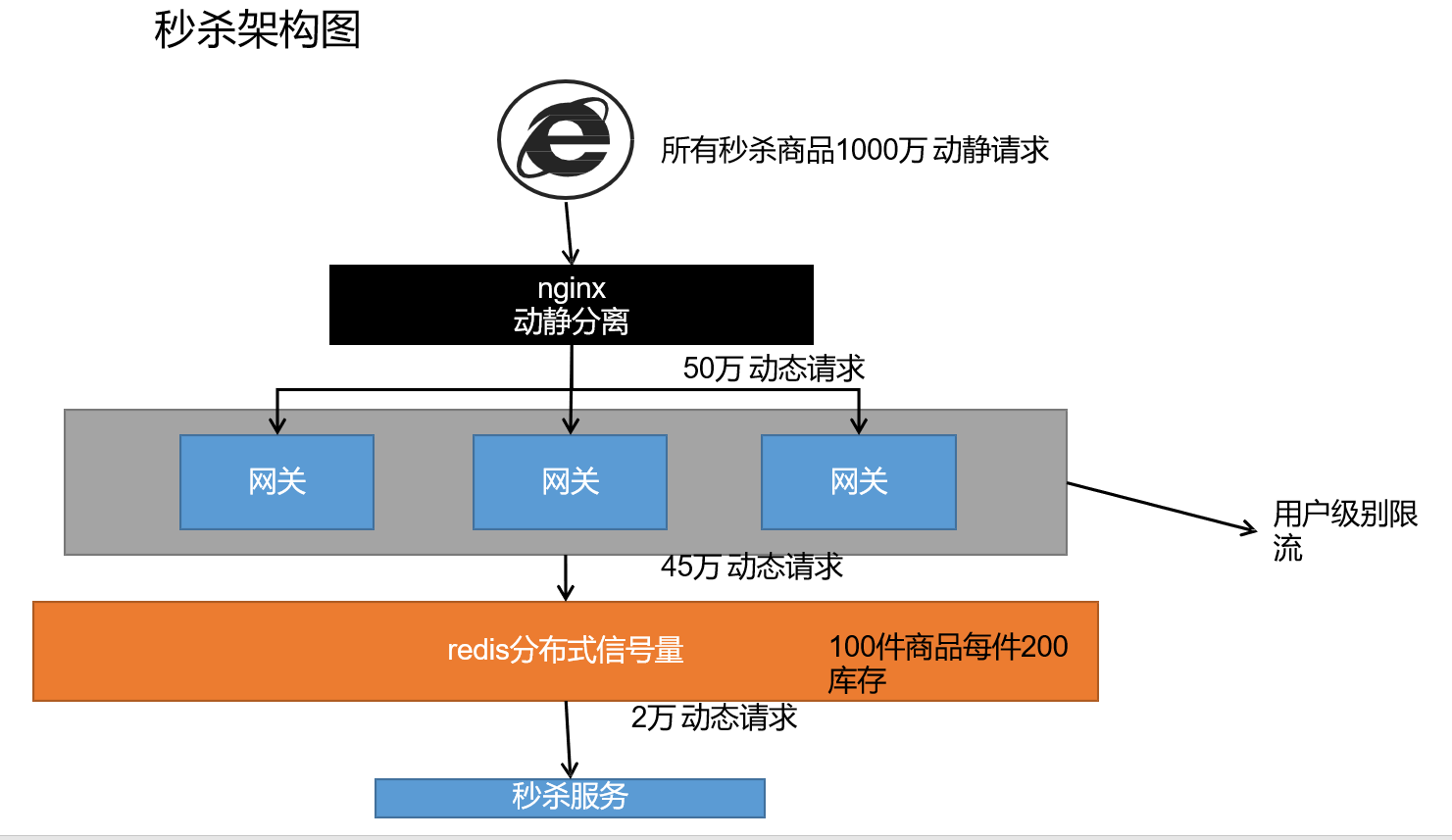

3、定时任务&Cron表达式
使用quartz做定时任务。
在使用时只需要标记相关注解即可。
使用以及相关问题举例:
/**
* 定时任务
* 1、@EnableScheduling 开启定时任务
* 2、@Scheduled开启一个定时任务
*
* 异步任务
* 1、@EnableAsync:开启异步任务
* 2、@Async:给希望异步执行的方法标注
*/
@Slf4j
@Component
@EnableAsync
@EnableScheduling
public class HelloScheduled {
/**
* 1、在Spring中表达式是6位组成,不允许第七位的年份
* 2、在周几的的位置,1-7代表周一到周日
* 3、定时任务不该阻塞。默认是阻塞的
* 1)、可以让业务以异步的方式,自己提交到线程池
* CompletableFuture.runAsync(() -> {
* },execute);
*
* 2)、支持定时任务线程池;设置 TaskSchedulingProperties
* spring.task.scheduling.pool.size: 5
*
* 3)、让定时任务异步执行
* 异步任务
* 解决:使用异步任务 + 定时任务来完成定时任务不阻塞的功能
*/
@Async
@Scheduled(cron = "*/5 * * ? * 4")
public void hello() {
log.info("hello...");
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
}
}
Cron表达式:
可参考博客以及官方文档。
4、秒杀系统需要关注的问题
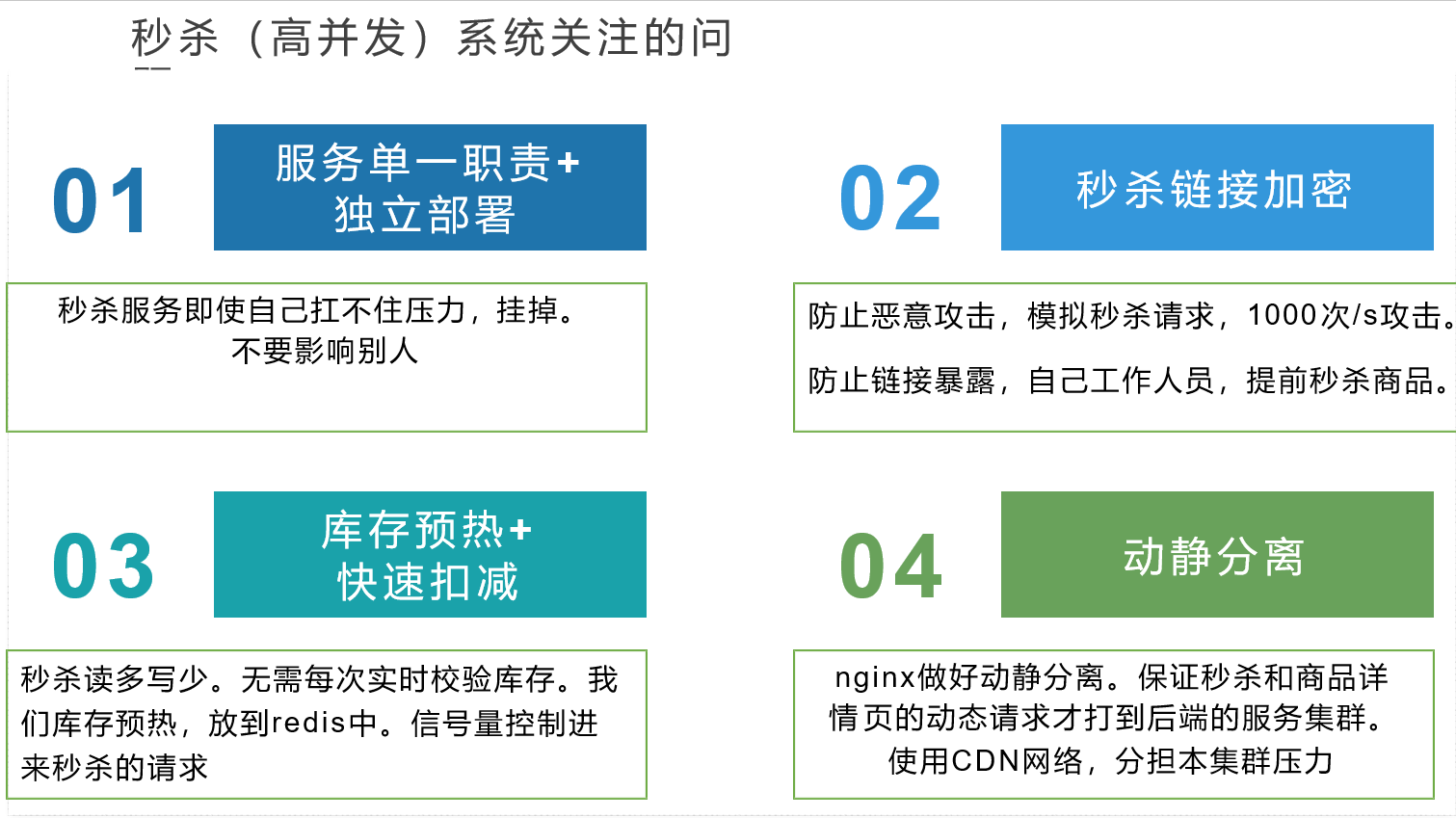

谷粒商城高级篇(完)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)