
Flink SQL 优化实战 - 维表 JOIN 优化
从源码层面分析维表 Join 原理及调优方案
作者:龙逸尘,腾讯 CSIG 高级工程师
背景介绍
维表(Dimension Table)是来自数仓建模的概念。在数仓模型中,事实表(Fact Table)是指存储有事实记录的表,如系统日志、销售记录等,而维表是与事实表相对应的一种表,它保存了事实表中指定属性的相关详细信息,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。
在实际生产中,我们经常会有这样的需求,以原始数据流作为基础,关联大量的外部表来补充一些属性。例如,在订单数据中希望能获取订单收货人所在市区的名称。一般来说订单中会记录所在市区的 ID,需要根据 ID 去查询外部的表补充市区名称属性。这种查询操作就是典型的维表 JOIN。
使用维度表有许多好处,例如:
-
缩小了事实表的大小。
-
便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。
-
维度表可以为多个事实表重用,以减少重复工作。
Flink SQL 维表 JOIN 的用法
在实时数仓中,同样也有维表与事实表的概念,其中事实表通常为实时流数据,维表通常存储在外部设备中(如 MySQL、HBase 等)。对于每条流式数据,可以关联外部数据源,查询并补充维度属性。
由于维表是一张不断变化的表(静态表视为动态表的一种特例),因此在维表 JOIN 时,需指明这条记录关联维表快照的对应时刻。Flink SQL 的维表 JOIN 语法引入了 Temporal Table 的标准语法,用于声明流数据关联的是维表哪个时刻的快照。
需要注意是,目前原生 Flink SQL 的维表 JOIN 仅支持事实表对当前时刻维表快照的关联(处理时间语义),而不支持事实表 rowtime 所对应的维表快照的关联(事件时间语义)。
语法说明
Flink SQL 中使用 for SYSTEM_TIME as of PROC_TIME() 的语法来标识维表 JOIN,仅支持 INNER JOIN 与 LEFT JOIN。
SELECT column-names
FROM table1 [AS <alias1>]
[LEFT] JOIN table2 FOR SYSTEM_TIME AS OF table1.proctime [AS <alias2>]
ON table1.column-name1 = table2.key-name1注意:table1.proctime 表示 table1 的 proctime 属性(可使用计算列)。
使用示例
下面用一个简单的示例来展示维表 JOIN 语法。假设我们有一个 Orders 订单数据流,希望根据用户 ID 补全订单中的用户信息,因此需要跟 Customer 维度表进行关联。
CREATE TABLE Orders (
id INT,
price DOUBLE,
quantity INT,
proc_time AS PROCTIME(),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'datagen',
'fields.id.kind' = 'sequence',
'rows-per-second' = '10'
);
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
CREATE TABLE OrderDetails (
id INT,
total_price DOUBLE,
country STRING,
zip STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/orderdb',
'table-name' = 'orderdetails'
);
-- enrich each order with customer information
INSERT INTO OrderDetails SELECT o.id, o.price*o.quantity, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.id = c.id;Flink SQL 维表 JOIN 的原理
Flink SQL 执行流程
Apache Calcite 是一款开源的 SQL 解析工具,被广泛使用于各个大数据项目中,主要用于解析 SQL 语句。SQL 的执行流程一般分为四个主要阶段:
-
Parse:语法解析,把 SQL 语句转换成抽象语法树(AST),在 Calcite 中用 SqlNode 来表示;
-
Validate:语法校验,根据元数据信息进行验证,例如查询的表、使用的函数是否存在等,校验之后仍然是 SqlNode 构成的语法树;
-
Optimize:查询计划优化,包含两个阶段,1)将 SqlNode 语法树转换成关系表达式 RelNode 构成的逻辑树,2)使用优化器基于规则进行等价变换,例如谓词下推、列裁剪等,经过优化器优化后得到最优的查询计划;
-
Execute:将逻辑查询计划翻译成物理执行计划,生成对应的可执行代码,提交运行。
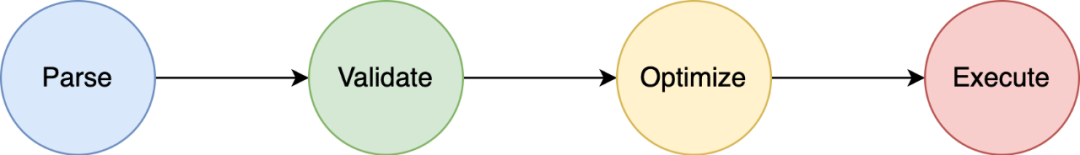
Flink SQL 的执行基本上遵循上述处理流程,主要依赖于 Calcite 来完成。
当在 Flink SQL 作业中显式执行 tEnv.executeSql() 方法时,就会真正开始运行 Flink SQL 程序。代码入口可以参考 TableEnvironmentImpl.executeSql()。
接下来我们详细分析一下 Flink SQL 的执行流程。
SQL 解析
SQL 的解析在 PlannerImpl.parse() 中实现,主要分为 4 个阶段:
-
首先使用 Calcite parser 解析出抽象语法树 SqlNode;
-
结合元数据验证 SQL 语句的合法性;
-
将 SqlNode 转换为 RelNode;
-
将 RelNode 封装为 Flink 内部对查询操作的抽象 PlannerQueryOperation。
SQL 转换
在将 SQL 语句解析成 Operation 后,为了得到 Flink 运行时的具体操作算子,需要进一步将 Operation 转换为 Transformation。需要注意的是,只有 ModifyOperation 才能进行转换,而 ModifyOperation 对应的是 DML 的操作,在将 SQL 查询结果插入到一张结果表或者调用 toDataStream 方法转化为 DataStream 时,才会得到 ModifyOperation。
SQL 的转换在 PlannerBase.translate() 中实现,主要流程分为四个阶段:
-
将 Operation 转换为 RelNode;
-
优化 RelNode,最终得到 FlinkPhysicalRel;
-
优化后的 FlinkPhysicalRelNode 转换成 ExecNode;
-
ExecNode 转换为底层的 Transformation 算子。
SQL 优化
得到 RelNode 后,Flink 使用 Calcite 对 RelNode 进行了一系列优化流程。这些优化流程在 PlannerBase.optimize() 中实现。
Caclite 对逻辑计划的优化是一套基于规则的框架,用户可以通过添加规则进行扩展,Flink 基于自定义规则来实现整个的优化过程。Flink 构造了一个链式的优化流程,可以按顺序使用多套规则集合完成 RelNode 的优化过程。
Flink Table Planner 在 FlinkStreamProgram 中定义了一系列扩展规则,用于构造逻辑计划的优化器,应用在 SQL 优化的各个阶段,将 SQL 从 原始的 RelNode 转化为 FlinkLogicRel,最后转化为 FlinkPhysicalRel。
维表 JOIN 涉及的主要优化阶段包含 temporal_join_rewrite、logical、physical 等。不同阶段生成的逻辑树如下所示:
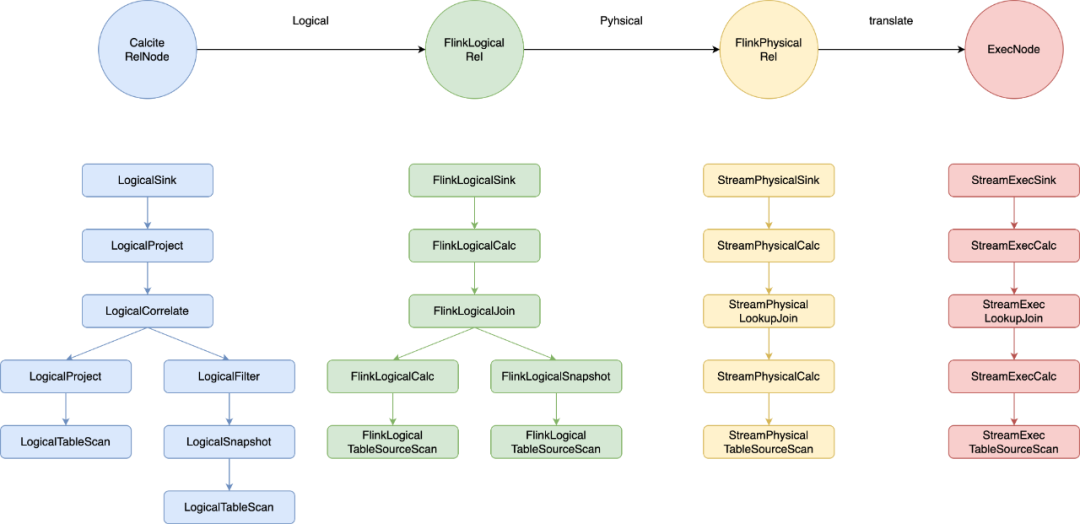
经过优化器处理后,得到的逻辑树中的所有节点都是 FlinkPhysicRel。首先调用 PlannerBase.translateToExecNodeGraph(optimizedRelNodes) 将 FlinkPhysicalRel 构成的 DAG 转换成 ExecNode 构成的 DAG;随后调用 PlannerBase.translateToPlan(execGraph) 将 ExecNode 节点转换为 Flink 内部的 Transformation 算子。不同的 ExecNode 按照各自的需求生成不同的 Transformation,基于这些 Transformation 构建 Flink 的 StreamGraph。
梳理过后,我们可以得出,维表 JOIN 算子对应的 ExecNode 为 StreamExecLookupJoin,最终转化成的 JOIN Operator 是 LookupJoinRunner。
SQL 执行
经过 SQL 优化步骤,得到 Transformation 后,利用 Transformation 生成 StreamGraph 后就可以提交 Flink 任务了。根据 Transformation 列表生成 StreamGraph 的实现比较简单,依次将算子添加到 StreamExecutionEnvironment 中即可。
CommonExecLookupJoin
现在让我们详细看下 LookupJoin 对应的 Operator 是如何进行维表关联的。
前往 CommonExecLookupJoin.translateToPlanInternal() 方法[1],可以看到这个 Operator 的 operatorFactory 由 createAsyncLookupJoin 或者 createSyncLookupJoin 生成,最终生成的 LookupJoinRunner 算子使用用户定义的 LookupFunction 来作为最终访问外部维表的函数。
Lookup JOIN 算子的调用链如下图所示:
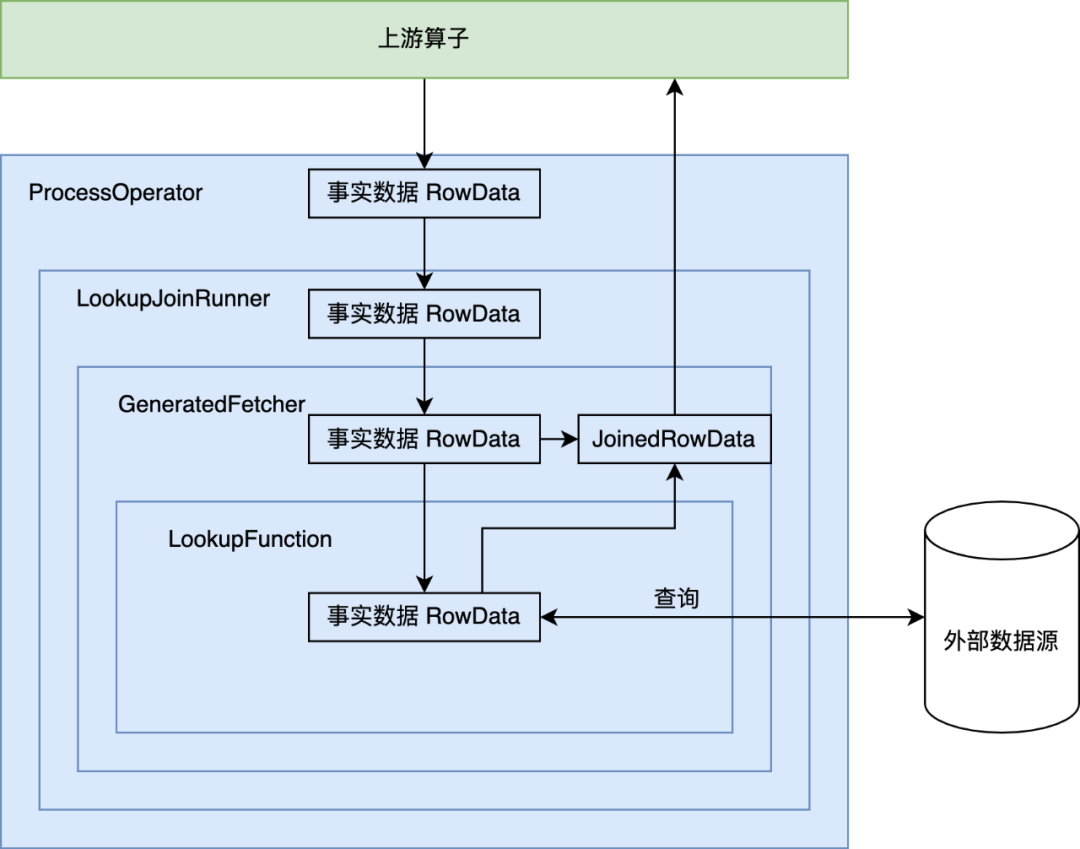
LookupTableSource 和 LookupFunction
通过上面的分析,我们知道维表 JOIN 实际上基于 Flink SQL 的 LookupTableSource 实现。LookupTableSource 的 scan 逻辑基于 UDF LookupFunction,当事实表的数据到来时,调用 LookupFunction 的 eval 方法,前往外部数据源进行关联查询。代码详情请关注 LookupTableSource.java。
LookupFunction 的实现通常分为以下几个部分:
-
在 open() 方法中建立并维护与外部系统的连接;
-
eval() 方法实现与外部系统的关联逻辑。
Flink SQL 维表 JOIN 的优化
维表 JOIN 的常见问题
维表 Join 的默认策略是实时、同步查询维表,每条流数据到来时,在 Flink 算子中直接访问维表数据源来进行关联。这种方式可以保证维表数据是最新的,但是当数据流量过大时,频繁的维表实时查询会对外部系统带来巨大的压力,可能导致连接失败、处理线程打满等情况,出现线程阻塞、数据返回缓慢等后果,影响任务整体的吞吐量。而且这种方案对外部系统能承受的 QPS 要求较高,在大数据实时计算场景下,QPS 远高于普通的后台系统,峰值高达百万甚至千万,导致整体作业处理瓶颈转移到外部系统。
此外,维表并不是永远不变的,而维表的变化可能导致无法关联。例如维表有新增维度,而 JOIN 操作发生在维度新增之前,由于维表 JOIN 只能关联处理时间的快照,就会导致事实数据关联不上。这也是很多用户的使用痛点。
优化点 1:Async I/O
维表 JOIN 默认为同步访问方式,上游每输入一条数据就会前往外部表中查询一次,等待返回后输出关联结果,期间的网络耗时与外部表的查询延迟极大地阻碍了流作业的吞吐,加大了数据处理延迟。为了解决同步访问外部数据源的问题,可以引入异步模式处理查询请求,使得连续的关联请求之间不需要阻塞等待。
同步请求和异步请求外部维表,对比图如下:
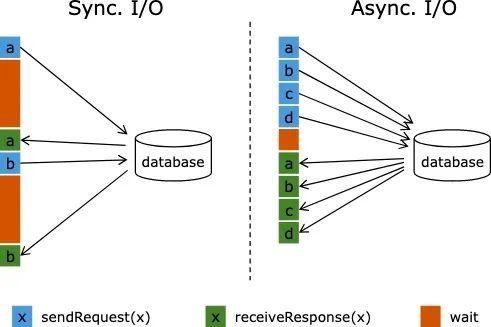
基于 Flink Async I/O 和异步客户端,我们可以实现维表 JOIN 的异步化,极大地提高维表 JOIN 的吞吐率。
在 Flink SQL 中,通过继承 AsyncTableFunction,实现异步的 eval() 方法,即可完成异步维表 JOIN。以 HBaseAsyncLookupFunction [2] 为例,简单分析异步化维表 JOIN 的实现:
public class HBaseRowDataAsyncLookupFunction extends AsyncTableFunction<RowData> {
@Override
public void open(FunctionContext context) {
// 建立线程池
final ExecutorService threadPool =
Executors.newFixedThreadPool(
THREAD_POOL_SIZE,
new ExecutorThreadFactory(
"hbase-async-lookup-worker", Threads.LOGGING_EXCEPTION_HANDLER));
Configuration config = prepareRuntimeConfiguration();
// 异步建立 HBase 连接
CompletableFuture<AsyncConnection> asyncConnectionFuture =
ConnectionFactory.createAsyncConnection(config);
asyncConnection = asyncConnectionFuture.get();
table = asyncConnection.getTable(TableName.valueOf(hTableName), threadPool);
this.serde = new HBaseSerde(hbaseTableSchema, nullStringLiteral);
}
public void eval(CompletableFuture<Collection<RowData>> future, Object rowKey) {
Get get = serde.createGet(rowKey);
// 去 HBase 表中查询
CompletableFuture<Result> responseFuture = table.get(get);
responseFuture.whenCompleteAsync(
(result, throwable) -> {
if (throwable != null) {
// 发生异常时,调用 future.completeExceptionally
resultFuture.completeExceptionally(
new RuntimeException("HBase table '" + hTableName + "' not found.",throwable));
} else {
RowData rowData = serde.convertToNewRow(result);
// 正常返回时,调用 future.complete,向下游发送消息
resultFuture.complete(Collections.singletonList(rowData));
}
}
)
}
}从代码中可以看出,维表 JOIN 异步化的关键点在于:
-
需要支持异步查询的外部数据源客户端;
-
eval 方法中使用 CompletableFuture 处理异步请求的结果。
优化点 2:维表缓存
除了将同步查询改为异步,我们还可以缓存维表中的数据,保存到 Flink 作业 TaskManager 的内存中,流数据到来时,只需要查询本地缓存中的数据,无需与远程数据源进行交互,可以极大提升数据处理的吞吐量。
维表缓存的实现有多种方式,可以用一张表格进行总结:
| 缓存类型 | 实现细节 | 优点 | 缺点 |
|---|---|---|---|
| 全量缓存 | LookupFunction 的 open() 方法中预加载维表全量数据,并保存到本地缓存中。eval() 方法先查询缓存,无法找到再查询维表外部数据源。 | 1.实现简单;2.有效提高维表 JOIN 的吞吐。 | 1.数据全量保存,无法应对超大维表;2.维表数据更新比较困难。 |
| LRU 缓存 | LookupFunction 的 open() 方法中初始化 LRU 缓存。eval() 方法先查询缓存,无法找到再查询维表外部数据源,返回的结果存入缓存以备下次查询。需要设置缓存 TTL 和缓存 Size 来控制缓存数据的失效时间和缓存大小。 | 1.降低数据库的查询压力;2.降低内存消耗。 | 1.QPS 很高的情况下缓存命中率较低;2.需要合理设置 TTL 和缓存大小。 |
| Partitioned 缓存 | LookupFunction 的 open() 方法中初始化 LRU/全量 缓存。事实数据关联维表前,先按照 JOIN Key 进行 Hash 操作。 | 每个 Subtask 加载所需的维表数据到缓存,降低内存消耗,提高吞吐。 | Hash 操作消耗额外的网络和CPU资源。 |
全量缓存和 LRU 缓存的实现都比较简单,只需调整 LookupFunction 即可,而 Partitioned 缓存的实现涉及的改动点很多,下面进行详细分析。
通过观察作业拓扑和执行计划,我们发现 Cacl 算子和 LookupJoin 算子是 Chain 在一起的。维表 JOIN 是一种等值 JOIN,天然具有 Hash 属性,如果能在 Cacl 算子和 LookupJoin 算子之间生成 Hash 算子,即可实现 Partitioned cache。
方案 1
方案1:在 ExecNodeGraph 生成 Transformation 时进行调整。考虑在 CaclTransformation 和 LookupJoin Transformation 之间添加 PartitionTransformation。
修改 LookupJoin 对应的 ExecNode CommonExecLookupJoin,调整 translateToPlanInternal()方法,在生成的 outputTransformation 和上游的 inputTransformation 之间添加 PartitionTransformation,根据 JOIN Key 进行 Hash。
public Transformation<RowData> translateToPlanInternal(PlannerBase planner) {
// 之前的代码省略
Transformation<RowData> inputTransformation =
(Transformation<RowData>) inputEdge.translateToPlan(planner);
// TODO: 新增 partitionTransformation
int[] hashKeys = lookupKeys.keySet().stream().mapToInt(key -> key).toArray();
final RowDataKeySelector keySelector =
KeySelectorUtil.getRowDataSelector(hashKeys, InternalTypeInfo.of(inputRowType));
final StreamPartitioner<RowData> partitioner =
new KeyGroupStreamPartitioner<>(
keySelector, DEFAULT_LOWER_BOUND_MAX_PARALLELISM);
final Transformation<RowData> partitionTransformation =
new PartitionTransformation<>(inputTransformation, partitioner);
partitionTransformation.setParallelism(inputTransformation.getParallelism());
OneInputTransformation<RowData, RowData> inputTransform = new OneInputTransformation<>(
partitionTransformation,
getDescription(),
operatorFactory,
InternalTypeInfo.of(resultRowType),
partitionTransformation.getParallelism());
inputTransform.setParallelism(partitionTransformation.getParallelism());
inputTransform.setOutputType(InternalTypeInfo.of(resultRowType));
return inputTransform;
}方案 2
方案 2:在 Logical 优化阶段为节点添加 Hash FlinkRelDistribution Trait,在 Physical 优化阶段该 Trait 会生成 StreamPhysicalExchange Node。
在 StreamPhysicalLookupJoinRule.doTransform() 中将 FlinkLogicalRel 中的默认 FlinkRelDistribution Trait 替换成 Hash。
private def doTransform(
join: FlinkLogicalJoin,
input: FlinkLogicalRel,
temporalTable: RelOptTable,
calcProgram: Option[RexProgram]): StreamPhysicalLookupJoin = {
val joinInfo = join.analyzeCondition
val cluster = join.getCluster
val providedTrait = join.getTraitSet.replace(FlinkConventions.STREAM_PHYSICAL)
var requiredTrait = input.getTraitSet.replace(FlinkConventions.STREAM_PHYSICAL)
val options = temporalTable.asInstanceOf[TableSourceTable].catalogTable.getOptions
// 获取维表配置
val enablePartitionedCache = options.getOrDefault("lookup.enable-partitioned-cache", "false").toBoolean
if (enablePartitionedCache) {
val requiredDistribution = FlinkRelDistribution.hash(joinInfo.leftKeys, true)
requiredTrait = input.getTraitSet
// 替换 FlinkRelDistributionTraitDef
.replace(requiredDistribution)
.replace(FlinkConventions.STREAM_PHYSICAL)
}
val convInput = RelOptRule.convert(input, requiredTrait)
new StreamPhysicalLookupJoin(
cluster,
providedTrait,
convInput,
temporalTable,
calcProgram,
joinInfo,
join.getJoinType)
}优化点 3:批量关联
维表 JOIN 时,攒一批数据以后调用维表的批量查询接口,进行批量关联,可以减少 RPC 的调用次数,提高吞吐量。
批量关联的实现可以分为以下步骤:
-
添加是否开启 Batch JOIN 对应的配置,设置 Batch Size 和 Batch 触发 TTL;
-
CommonExecLookupJoin 构造 ProcessFunction 时,根据是否开启 Batch JOIN 配置分别构造 LookupJoinRunner 或 BatchLookupJoinRunner;
-
BatchLookupJoinRunner 的 processElement() 方法中实现攒批逻辑,使用 ListState 攒批,通过 timer 触发 批量关联操作;
-
调整 CodeGen 相关类,为 BatchLookupJoinRunner 对应的 generatedFetcher、generatedCollector 和 generatedCalc 赋予正确的输入和输出:
List<RowData>; -
LookupFunction 的 eval 方法调用批量查询接口。
优化点 4:延迟关联
由于维表 JOIN 只能关联处理时间的快照,可能导致事实数据无法关联更新后的维度,造成关联失败。
对于这种场景,我们可以实现延迟关联功能。如果 Join 没有命中,数据无法关联,可以暂时将事实数据缓存在 Flink State 中,等待一段时间后进行重试,并且可以控制等待时间与重试次数。
延迟关联的实现可以分为以下步骤:
-
添加是否开启 Delay JOIN 对应的配置,设置 Delay Join Intervals 和 RetryTimes;
-
CommonExecLookupJoin 构造 ProcessFunction 时,根据是否开启 Delay JOIN 配置分别构造 LookupJoinRunner 或 DelayedLookupJoinRunner;
-
DelayedLookupJoinRunner 的 processElement() 方法中实现延迟 JOIN 逻辑,如果无法关联则将事实数据保存在 ListState 中,通过设置 timer 和重试次数,延时触发关联操作。
总结
本文简述了 Flink SQL 维表 JOIN 的用法与原理,分析了维表 JOIN 遇到的主要问题,并提供了多种维表 JOIN 的优化思路与具体实现方案。
流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发、无缝连接、亚秒延时、低廉成本、安全稳定等特点的企业级实时大数据分析平台。流计算 Oceanus 针对常见的 JOIN 场景也有自己独特的性能优化,欢迎大家体验 1 元试用[3],也欢迎阅读流计算 Oceanus 的专栏文章[4] 。
附录
[1] CommonExecLookupJoin.java 源码。链接:https://github.com/apache/flink/blob/1f3324071a36ef78719e631fbac61c55b1ee3600/flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/plan/nodes/exec/common/CommonExecLookupJoin.java#L214
[2] HBaseRowDataAsyncLookupFunction.java 源码。链接:https://github.com/apache/flink/blob/master/flink-connectors/flink-connector-hbase-2.2/src/main/java/org/apache/flink/connector/hbase2/source/HBaseRowDataAsyncLookupFunction.java
[3] 流计算 Oceanus 一元试用活动。链接:https://cloud.tencent.com/developer/article/1885095
[4] 流计算 Oceanus 专栏。链接:https://cloud.tencent.com/developer/tag/10509

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)