会话存档-如何高性能存储海量聊天记录
场景每天大约500w条数据,存档消息,并对消息进行统计分析。大概计算一下:每天的工作时间是8小时,大约是8小时处理400w条数据就足够了,为避免某时刻的峰值超负荷,还按照8小时处理500w条数据的标准来搭建环境;每秒钟大概要处理180条数据;客户提供了3台应用服务器(8核16G),单台机器每秒需处理60条数据每条消息(不考虑文件等消息,只考虑文本)平均大小为1kb,每天大约产生5个G的数据思路需求
场景
每天大约500w条数据,存档消息,并对消息进行统计分析。
大概计算一下:
- 每天的工作时间是8小时,大约是8小时处理400w条数据就足够了,为避免某时刻的峰值超负荷,还按照8小时处理500w条数据的标准来搭建环境;每秒钟大概要处理180条数据;
- 客户提供了3台应用服务器(8核16G),单台机器每秒需处理60条数据
- 每条消息(不考虑文件等消息,只考虑文本)平均大小为1kb,每天大约产生5个G的数据
思路
需求已经提出来了,只做其中的一个功能,就是获取消息,保存数据(数据查询、分析是其他需求);
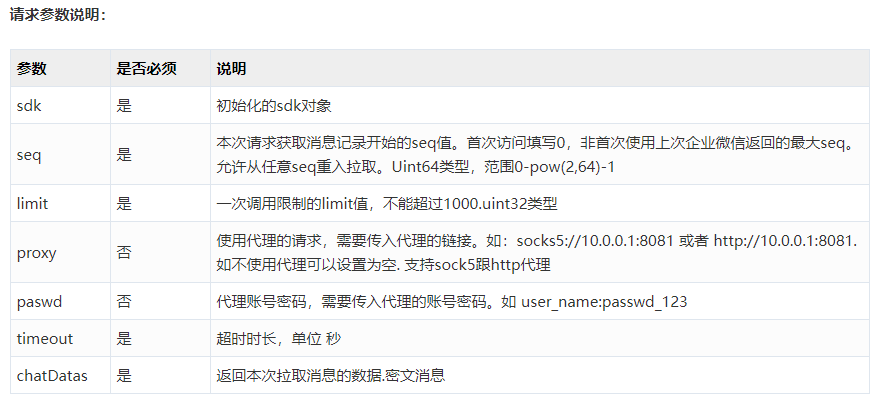
企业微信API:
- 通过本sdk接口来获取公司一段时间内的会话记录。一次拉取调用上限1000条会话记录,可以通过分页拉取的方式来依次拉取。调用频率不可超过600次/分钟。
- 获取会话记录内容不能超过3天,如果企业需要全量数据,则企业需要定期拉取聊天消息。返回的ChatDatas内容为json格式。
技术选择
因为海量数据的检索,所以需要使用 elasticsearch,但是用elasticsearch来存储的话,太多不需要进行查询的数据会占用大量的存储空间(服务器不够啊),而且很影响检索的速度,数据维护起来还很麻烦;所以还是需要将数据都存入MySQL,es中只存储一些需要查询的关键信息;这样既保留了完整的数据,又能提升检索速度
redis肯定必不可少;分布式锁、处理队列、缓存热点信息等;
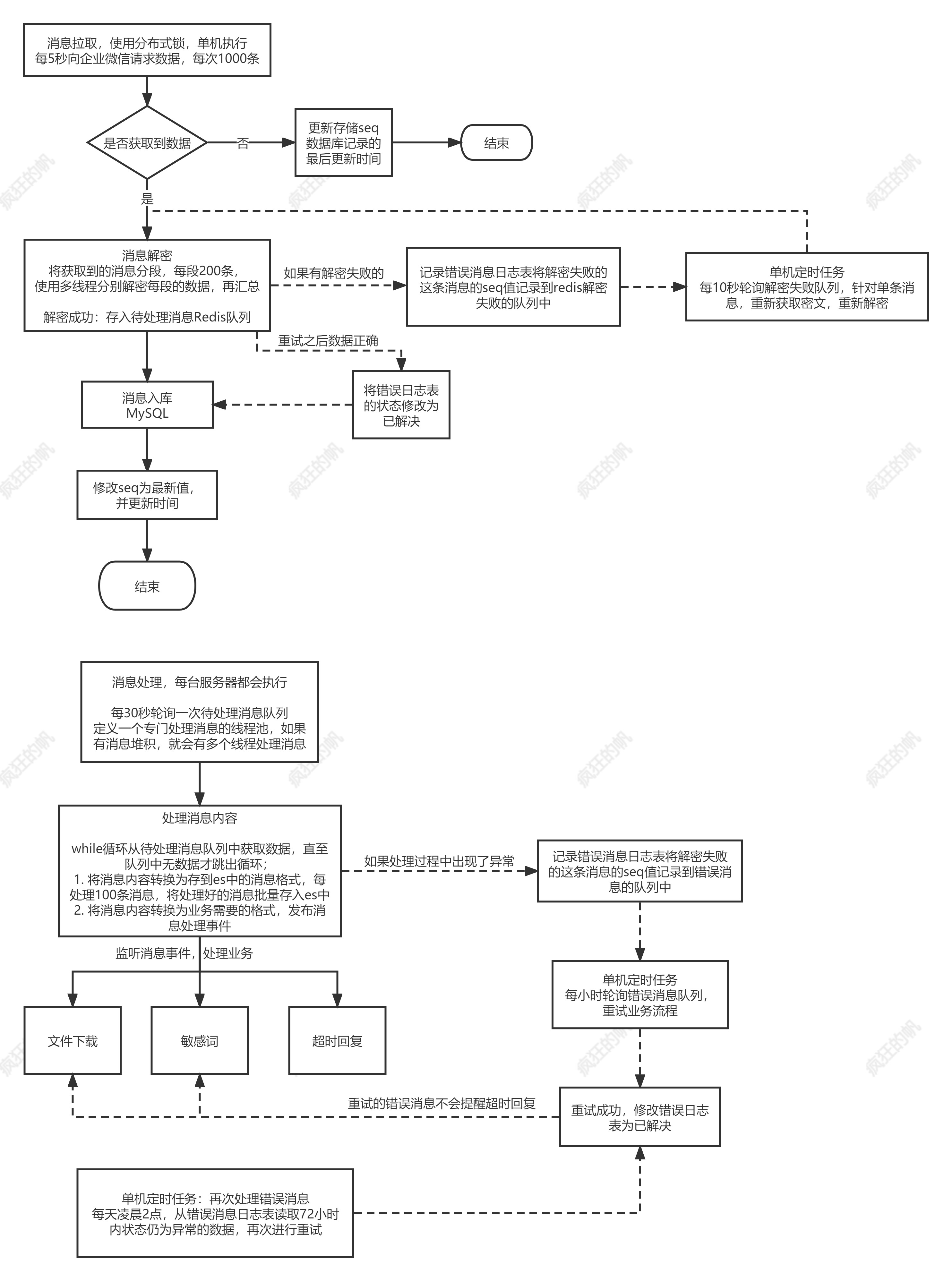
大致流程
msgSeq的就是消息的序号;唯一且递增
// 获取 msgSeq
seq = selectSeq();
// 请求企业微信,获取加密消息
encryptionMsg = getEncryptionMsg();
// 消息解密;解密的时候只能一条一条解密
msgList = getDencryptionMsg();
// 消息存mysql;
insertAll(msgList);
// 处理消息结构,以便存入es
msgEs = handlerData(msgList);
// 消息存es;
insertEs(msgEs);
// 其他业务处理
event();
// 修改msgSeq;
updateSeq();
// 重新执行此流程
存在的问题点以及优化
1️⃣ 分布式服务,多台机器同时执行以上流程,seq的值无法控制,拉取的消息会重复,加锁又会导致只能有一台机器执行,影响效率
解决方式:
拆分上述流程,把拉取消息、解密消息、消息入mysql、修改seq归为一个流程;
-
因为涉及seq的变更,这个流程只能单独一台机器执行;每5秒处理1000条数据也足够使用
-
解密消息,要在入库前进行解密,存储在mysql肯定不能存储密文数据,如果多台机器执行的话,处理流程又多出几步,还需要再依赖redis,性能得不偿失,考虑使用多线程
-
mysql批量插入,只需一条SQL,不浪费时间;同时也必须入库成功了才能修改seq,防止消息丢失
处理结构,存es,对其他业务发布事件等耗时操作归为一个流程
- 该流程不会出现公有数据,可以多机器一起执行
2️⃣ 解密失败怎么办,线程中断吗?之前成功的消息如何处理?
每次批量拉取500条,循环单条解密,如果解密到第499条数据,解密失败了,重新来一次?那肯定不行,浪费时间,可耻
解密失败的消息也不能直接丢了,考虑把这条消息的seq 记录到redis队列中,然后使用定时任务轮询这个队列,尝试重新拉取,解密
3️⃣ 每天500w消息,MySQL和ES怎么存呢?
如果只存一个表和一个索引;那估计过段时间,这个项目就跑不动了;
那就只能分表,分索引:
-
MySQL数据库设计:
-
字段 类型 解释 id bigint 自增主键 mysql为什么建议使用自增主键 - 知乎 (zhihu.com) msg_seq bigint 消息的顺序,也是一个自增的序号 msg_id varchar msgid的命名规则:19~20位随机数字_时间戳,如果是外部消息会以 _external 结尾 content json 消息内容,json格式 create_datetime datatime 创建记录的时间 -
每天按照500w计算,每月大概1.5个亿条数据,因为非工作日产生的数据很少,所以肯定不到1.5亿数据,因为这张表查询的次数很少,所以按照月份分表足够了
-
es索引同样如此,因为简化了大量的数据,es比较最初的结构瘦身了70%,所以es也可以按照月份分索引
解决方案

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)