大数据三种主流架构(Lambda、Kappa、IOTA)
数据湖内的数据在利用的时候一般会遵循Lambda架构或者Kappa架构或IOTA架构等数据处理的架构思想为指导。当然,不遵循这两种架构思想也是可以的,如果你有自己的想法去做设计也是没问题的。只是,一般Lambda架构和Kappa架构作为成熟的大数据分析架构,用在处理数据湖内的数据也是很适合的。
文章目录
前言
数据湖内的数据在利用的时候一般会遵循Lambda架构或者Kappa架构或IOTA架构等数据处理的架构思想为指导。
当然,不遵循这两种架构思想也是可以的,如果你有自己的想法去做设计也是没问题的。只是,一般Lambda架构和Kappa架构作为成熟的大数据分析架构,用在处理数据湖内的数据也是很适合的。
Lambda架构
Lambda架构的介绍
Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理架构。Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lambda架构是其根据多年进行分布式大数据系统的经验总结提炼而成。
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
Lambda架构的关键性
Robust and fault-tolerant(容错性和鲁棒性(注1)):对大规模分布式系统来说,机器是不可靠的,可能会宕机,但是系统需要是健壮、行为正确的,即使是遇到机器错误。除了机器错误,人更可能会犯错误。在软件开发中难免会有一些Bug,系统必须对有Bug的程序写入的错误数据有足够的适应能力,所以比机器容错性更加重要的容错性是人为操作容错性。对于大规模的分布式系统来说,人和机器的错误每天都可能会发生,如何应对人和机器的错误,让系统能够从错误中快速恢复尤其重要。
Low latency reads and updates(低延时):很多应用对于读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
Scalable(横向扩容):当数据量/负载增大时,可扩展性的系统通过增加更多的机器资源来维持性能。也就是常说的系统需要线性可扩展,通常采用scale out(通过增加机器的个数)而不是scale up(通过增强机器的性能)。
General(通用性):系统需要能够适应广泛的应用,包括金融领域、社交网络、电子商务数据分析等。
Extensible(可扩展):需要增加新功能、新特性时,可扩展的系统能以最小的开发代价来增加新功能。
Allows ad hoc queries(方便查询):数据中蕴含有价值,需要能够方便、快速的查询出所需要的数据。
Minimal maintenance(易于维护):系统要想做到易于维护,其关键是控制其复杂性,越是复杂的系统越容易出错、越难维护。
Debuggable(易调试):当出问题时,系统需要有足够的信息来调试错误,找到问题的根源。其关键是能够追根溯源到每个数据生成点。
Lambda的三层架构
Lambda的三层架构
一般情况下,任何的查询都可以表示为:Query = Function(All data),但是,如果在数据量非常大的时候,且还要支持实时查询,就会消耗巨大的系统资源,或者难以达到。
那么,一个解决方式就是:预运算查询函数(precomputed query function)
预运算查询函数可以在系统空闲的时候根据业务需要的设计,去运行查询分析作业,然后生成结果我们称之为Batch view (批视图)
那么,有了这个Batch view后,我们对数据的查询可以改为:
Batch view = Query Function(All data)
Query = Function(Batch view)
从表达式中我们可以看出,真正的业务查询实际上是查询的 批处理视图,也即是我们预先准备好的数据内容。
我们也可以把这一步称之为:中间数据生成
那么,在Lambda架构中,把Batch view的生成这一步,就称之为Batch Layer 批处理层。
在Batch Layer中,有两个特性:
存储Master Dataset, 这是一个持续增长的数据集(对应All data,也就是在数据湖中我们需要利用的数据集)
在Master Dataset上执行预计算函数,构建查询所需的对应的view
我们把预处理结果称之为view,通过view可以快速得到结果(或者说对比query All data 简单太多)
可以看出,预计算函数,本质上就是一个批处理,那么就比较适合使用MR、Spark等计算引擎进行处理。
并且,采用这种形式生成的view均支持再次计算,如果对view不满意或者执行错误,重新执行一次即可。
该工作看似简单,实质非常强大。任何人为或机器发生的错误,都可以通过修正错误后重新计算来恢复得到正确结果。
Speed Layer 速度层
Batch Layer可以很好的处理离线数据,但是在我们的系统中,有许多的实时增量数据,而Speed Layer这一层就是用来处理实时增量数据的。
Speed Layer和Batch Layer比较类似,Speed Layer层是对数据进行计算并生成一个Realtime View,其主要区别在于:
Speed Layer处理的数据是最近的增量数据流,Batch Layer处理的全体数据集
Speed Layer为了效率,接收到新数据时不断更新Realtime View,而Batch Layer根据全体离线数据集直接得到Batch View。
Speed Layer是一种增量计算,而非重新计算(recomputation)
Speed Layer因为采用增量计算,所以延迟小,而Batch Layer是全数据集的计算,耗时比较长
综上所诉,Speed Layer是Batch Layer在实时性上的一个补充。Speed Layer可总结为:
realtime view=function(realtime view,new data)
Lambda架构将数据处理分解为Batch Layer和Speed Layer有如下优点:
容错性。
Speed Layer中处理的数据也不断写入Batch Layer,当Batch Layer中重新计算的数据集包含Speed Layer处理的数据集后,当前的Realtime View就可以丢弃,这也就意味着Speed Layer处理中引入的错误,在Batch Layer重新计算时都可以得到修正。
这点也可以看成是CAP理论中的最终一致性(Eventual Consistency)的体现。
复杂性隔离。
Batch Layer处理的是离线数据,可以很好的掌控。
Speed Layer采用增量算法处理实时数据,复杂性比Batch Layer要高很多。通过分开Batch Layer和Speed Layer,把复杂性隔离到Speed Layer,可以很好的提高整个系统的鲁棒性和可靠性。
通俗的说,也就是Batch Layer根据其执行的时间间隔,不断的将Batch View 涵盖的范围覆盖到新数据上。而一旦Batch View执行到了某个时间点,这个时间点之前的Realtime View就会被丢弃。也就是说,由于Batch View的高延迟,在需要得到最新数据结果的时候,由Realtime View做补充,然后再后方,Batch View不断的追赶进度。
Serving layer 服务层
Lambda架构中的最高层:Serving Layer层,可以理解为用户层,即响应用户的查询需求的层。
在Serving Layer中,将合并Batch View 以及Realtime View的结果,作为最终的View提供给用户查询。
那么,换算为前面的表达式为:Query = Function(Batch View + Realtime View)
上面分别讨论了Lambda架构的三层:Batch Layer,Speed Layer和Serving Layer。总结下来,Lambda架构就是如下的三个等式:
batch view = function(all data)
realtime view = function(realtime view, new data) # 其中参数中的Realtime view就是不断的对以后的Realtime View进行迭代更新,直到被Batch View追上丢弃。
query = function(batch view, realtime view)
Lambda的缺点
Lambda架构经过这么多年的发展,已经非常的成熟,其优点是稳定,对于实时计算部分的成本可控,而批处理部分可以利用晚上等空闲时间进行计算。这样把实时计算和离线处理的高峰错开来。
这种架构支撑了数据行业的早期发展,但也有一些缺点:
实时和批量结果不一致引起的冲突:由架构中可以得知,架构分实时和离线两部分,两边结果的计算要保持一致就比较困难。理论上来说,对于一些需要全量数据才能计算出的结果,90%的数据计算已经由离线负责完成,剩下10%是当前实时的计算结果,对两个结果合并就能做到100%全量的处理,并且保证低延迟。
但是,这仅仅是理论上以及我们所期望达到的,实际在应用的过程中因为各种原因导致这个时间没有对的上,导致衔接处出现了一些数据遗漏或者数据重复,就会让结果不准确。
并且,当过了一段时间后,离线部分追了上来,对错误进行了修正,又会导致在前端页面导致结果被修改的问题。
也就是说:理论是OK的,实施起来比较复杂,难免出现问题,对技术团队的能力有要求
批量计算无法在时限内计算完成:在IOT时代,数据量越来越多,很多时候的凌晨空闲期有的时候都不够用了,有的计算作业甚至会计算到大中午才结束,这样的话离线部分就大大了落后进度了,这导致实时的压力越来越大,其不断递归迭代的更新数据view越来越困难。
开发和维护的问题:由于要在两个不同的流程中对数据进行处理,那么针对一个业务就产生了两个代码库(一个离线计算、一个实时计算),那么这样的话会让系统的维护更加困难。
服务器存储开销大:由于View也就是中间数据的存在,会导致计算出许多的中间数据用来支撑业务,这样会加大存储的压力。(ps: 目前存储的成本越来越低,这个问题越来越不重要了)
也即是由于Lambda架构的这些局限性,Kappa架构应运而生,它比Lambda架构更加的灵活,我们在下面来看一下Kappa架构的相关细节。
kappa架构
针对Lambda架构的需要维护两套程序等以上缺点,LinkedIn的Jay Kreps结合实际经验和个人体会提出了Kappa架构。
Kappa架构的核心思想是通过改进流计算系统来解决数据全量处理的问题,使得实时计算和批处理过程使用同一套代码。
此外Kappa架构认为只有在有必要的时候才会对历史数据进行重复计算,而如果需要重复计算时,Kappa架构下可以启动很多个实例进行重复计算。
一个典型的Kappa架构如下图所示:
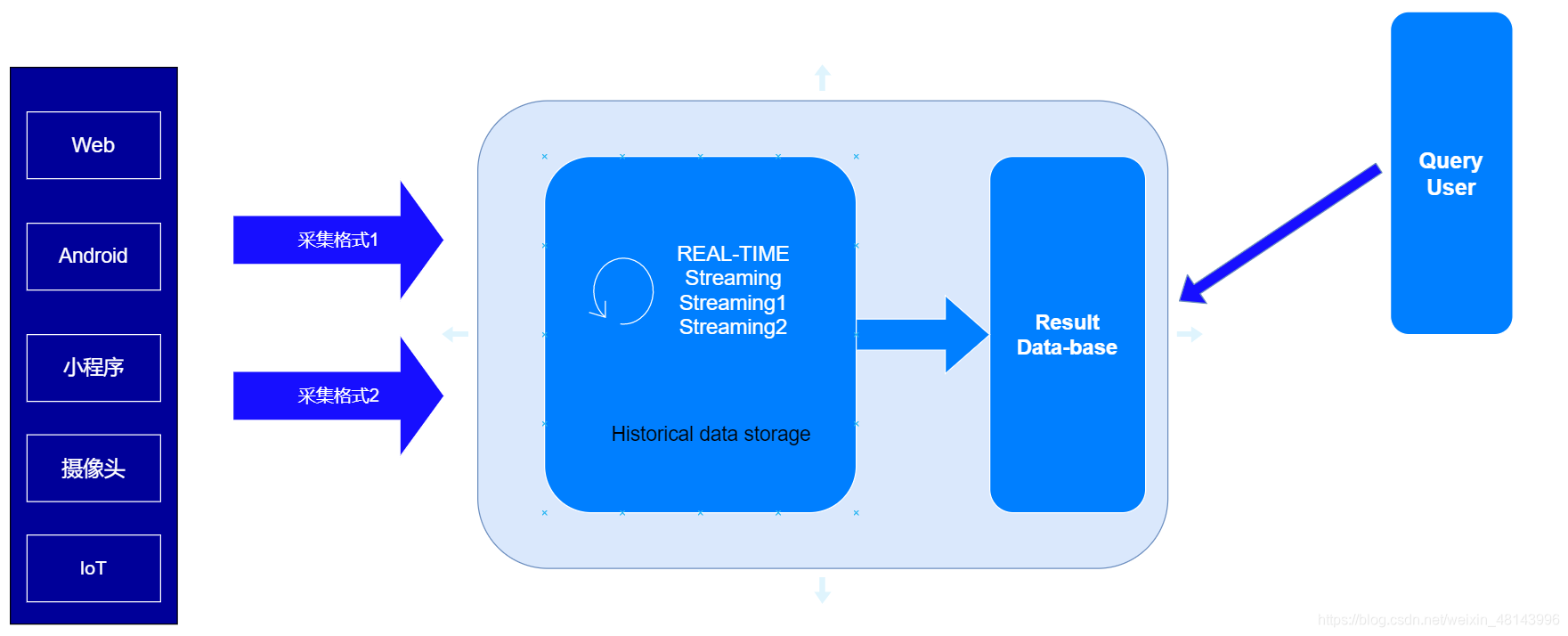
Kappa架构的核心思想,包括以下三点:
1.用Kafka或者类似MQ队列系统收集各种各样的数据,你需要几天的数据量就保存几天。
2.当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
3.当新的实例做完后,停止老的流计算实例,并把老的一些结果删除。
Kappa架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径的问题。而Kappa的缺点也很明显:
● 流式处理对于历史数据的高吞吐量力不从心:所有的数据都通过流式计算,即便通过加大并发实例数亦很难适应IOT时代对数据查询响应的即时性要求。
● 开发周期长:此外Kappa架构下由于采集的数据格式的不统一,每次都需要开发不同的Streaming程序,导致开发周期长。
● 服务器成本浪费:Kappa架构的核心原理依赖于外部高性能存储redis,hbase服务。但是这2种系统组件,又并非设计来满足全量数据存储设计,对服务器成本严重浪费。

IOTA架构
而在IOT大潮下,智能手机、PC、智能硬件设备的计算能力越来越强,而业务需求要求数据实时响应需求能力也越来越强,过去传统的中心化、非实时化数据处理的思路已经不适应现在的大数据分析需求,提出新一代的大数据IOTA架构来解决上述问题
整体思路是设定标准数据模型,通过边缘计算技术把所有的计算过程分散在数据产生、计算和查询过程当中,以统一的数据模型贯穿始终,从而提高整体的预算效率,同时满足即时计算的需要,可以使用各种Ad-hoc Query(即席查询)来查询底层数据:
IOTA整体技术结构分为几部分:
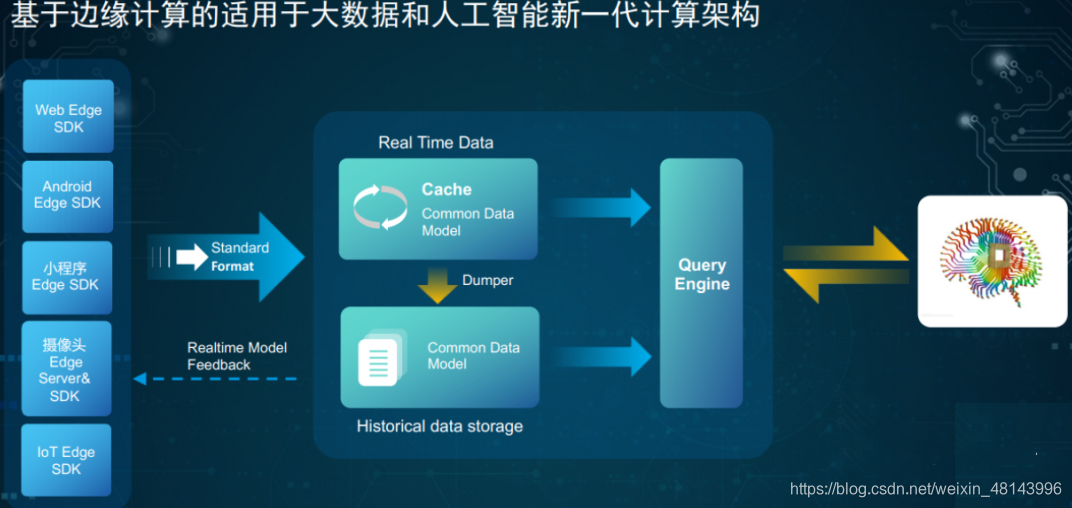
● Common Data Model:贯穿整体业务始终的数据模型,这个模型是整个业务的核心,要保持SDK、cache、历史数据、查询引擎保持一致。对于用户数据分析来讲可以定义为“主-谓-宾”或者“对象-事件”这样的抽象模型来满足各种各样的查询。以大家熟悉的APP用户模型为例,用“主-谓-宾”模型描述就是“X用户 – 事件1 – A页面(2018/4/11 20:00) ”。当然,根据业务需求的不同,也可以使用“产品-事件”、“地点-时间”模型等等。模型本身也可以根据协议(例如 protobuf)来实现SDK端定义,中央存储的方式。此处核心是,从SDK到存储到处理是统一的一个Common Data Model。
● Edge SDKs & Edge Servers:这是数据的采集端,不仅仅是过去的简单的SDK,在复杂的计算情况下,会赋予SDK更复杂的计算,在设备端就转化为形成统一的数据模型来进行传送。例如对于智能Wi-Fi采集的数据,从AC端就变为“X用户的MAC 地址-出现- A楼层(2018/4/11 18:00)”这种主-谓-宾结构,对于摄像头会通过Edge AI Server,转化成为“X的Face特征- 进入- A火车站(2018/4/11 20:00)”。也可以是上面提到的简单的APP或者页面级别的“X用户 – 事件1 – A页面(2018/4/11 20:00) ”,对于APP和H5页面来讲,没有计算工作量,只要求埋点格式即可。
● RealTime Data:实时数据缓存区,这部分是为了达到实时计算的目的,海量数据接收不可能海量实时入历史数据库,那样会出现建立索引延迟、历史数据碎片文件等问题。因此,有一个实时数据缓存区来存储最近几分钟或者几秒钟的数据。这块可以使用Kudu或者Hbase等组件来实现。这部分数据会通过Dumper来合并到历史数据当中。此处的数据模型和SDK端数据模型是保持一致的,都是Common Data Model,例如“主-谓-宾”模型。
● Historical Data:历史数据沉浸区,这部分是保存了大量的历史数据,为了实现Ad-hoc查询,将自动建立相关索引提高整体历史数据查询效率,从而实现秒级复杂查询百亿条数据的反馈。例如可以使用HDFS存储历史数据,此处的数据模型依然SDK端数据模型是保持一致的Common Data Model。
● Dumper:Dumper的主要工作就是把最近几秒或者几分钟的实时数据,根据汇聚规则、建立索引,存储到历史存储结构当中,可以使用map-reduce、C、Scala来撰写,把相关的数据从Realtime Data区写入Historical Data区。
● Query Engine:查询引擎,提供统一的对外查询接口和协议(例如SQL JDBC),把Realtime Data和Historical Data合并到一起查询,从而实现对于数据实时的Ad-hoc查询。例如常见的计算引擎可以使用presto、impala、clickhouse等。
● Realtime model feedback:通过Edge computing技术,在边缘端有更多的交互可以做,可以通过在Realtime Data去设定规则来对Edge SDK端进行控制,例如,数据上传的频次降低、语音控制的迅速反馈,某些条件和规则的触发等等。简单的事件处理,将通过本地的IOT端完成,例如,嫌疑犯的识别现在已经有很多摄像头本身带有此功能。
IOTA大数据架构,主要有如下几个特点:
● 去ETL化:ETL和相关开发一直是大数据处理的痛点,IOTA架构通过Common Data Model的设计,专注在某一个具体领域的数据计算,从而可以从SDK端开始计算,中央端只做采集、建立索引和查询,提高整体数据分析的效率。
● Ad-hoc即时查询:鉴于整体的计算流程机制,在手机端、智能IOT事件发生之时,就可以直接传送到云端进入realtime data区,可以被前端的Query Engine来查询。此时用户可以使用各种各样的查询,直接查到前几秒发生的事件,而不用在等待ETL或者Streaming的数据研发和处理。
● 边缘计算(Edge-Computing):将过去统一到中央进行整体计算,分散到数据产生、存储和查询端,数据产生既符合Common Data Model。同时,也给与Realtime model feedback,让客户端传送数据的同时马上进行反馈,而不需要所有事件都要到中央端处理之后再进行下发。
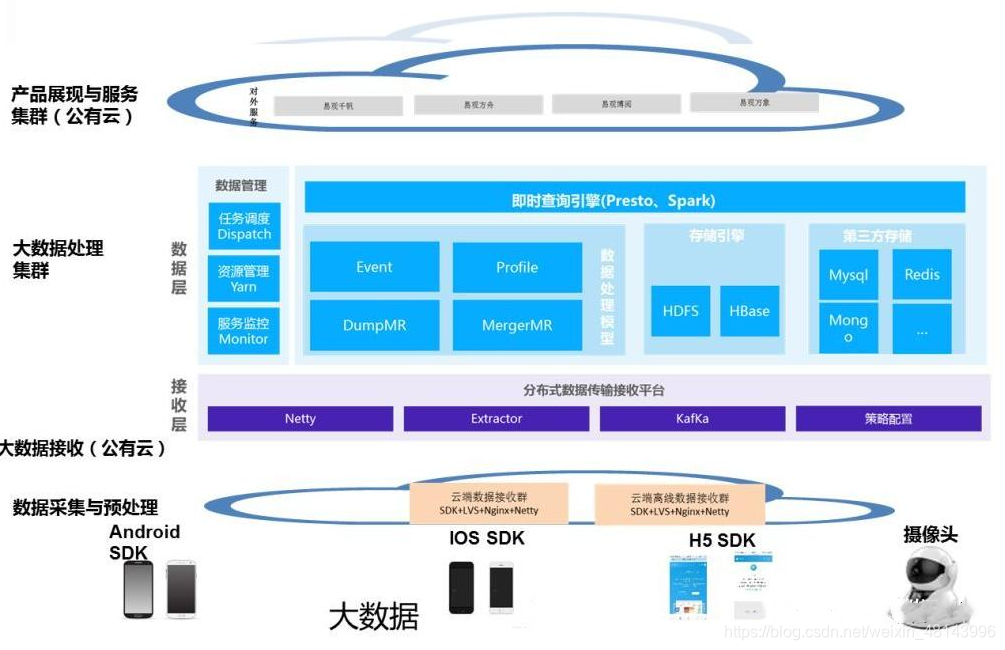
如上图,IOTA架构有各种各样的实现方法,为了验证IOTA架构,很多公司也自主设计并实现了“秒算”引擎
在大数据3.0时代,Lambda大数据架构已经无法满足企业用户日常大数据分析和精益运营的需要,去ETL化的IOTA大数据架构也许才是未来。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 1
1- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)