SQL汇总统计: 在SQL中使用CUBE和ROLLUP实现数据多维汇总
前面偶然在网上看到一篇文章,讲到数据汇总,提到了CUBE,感觉有些晦涩,想试着自己表述一下。同时,个人也认为CUBE还是很有用的,对SQL或数据分析感兴趣的小伙伴不妨了解一下,或许有用呢!首先,我们设定个需求,想要分别按【性别】、【籍贯】、【年龄】或【成绩级别】统计下表中学生的数量,再进一步,需要将这些条件相结合统计,同时满足某两项或更多条件的学生数量。数据表格如下:我们可以逐层来理解**【GRO
前面
偶然在网上看到一篇文章,讲到数据汇总,提到了CUBE,感觉有些晦涩,想试着自己表述一下。同时,个人也认为CUBE还是很有用的,对SQL或数据分析感兴趣的小伙伴不妨了解一下,或许有用呢!
首先,我们设定个需求,想要分别按【性别】、【籍贯】、【年龄】或【成绩级别】统计下表中学生的数量,再进一步,需要将这些条件相结合统计,同时满足某两项或更多条件的学生数量。数据表格如下:
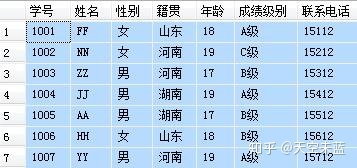
我们可以逐层来理解**【GROUP BY】【WITH ROLLUP】【WITH CUBE】**如何完成数据汇总。
第一层:【GROUP BY】
【GROUP BY】从字面意义上理解就是根据【BY】指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。可以先利用【GROUP BY】按条件进行分组,然后计算各组的数量。看个例子。
按学生性别统计学生的数量,SQL语句如下:
SELECT 性别, COUNT(学号) AS 数量
FROM STUDENT
GROUP BY 性别

结果分析:可以看出,已经按性别顺利统计出“男”、“女”各占的数量,但这距离事先的需求(要统计多个条件,甚至是多条件组合下的学生数量的小计以及合计)差距有点远,【GROUP BY】还是有点弱。
第二层:【GROUP BY】+【WITH ROLLUP】
为【GROUP BY】加上【WITH ROLLUP】子句,看ROLLUP能不能提供更多的统计结果。前面说到多条件,其实说多维度更准确些。看个例子先:
--语句1 只用了【性别】一个维度进行汇总
SELECT 性别, COUNT(学号) AS 数量
FROM STUDENT
GROUP BY 性别 WITH ROLLUP
--语句2 用了【性别】和【籍贯】两个维度进行汇总
SELECT 性别, 籍贯, COUNT(学号) AS 数量
FROM STUDENT
GROUP BY 性别, 籍贯 WITH ROLLUP
--语句3 用了【性别】、【籍贯】、【年龄】三个维度进行汇总
SELECT 性别, 籍贯, 年龄, COUNT(学号) AS 数量
FROM STUDENT
GROUP BY 性别, 籍贯, 年龄 WITH ROLLUP
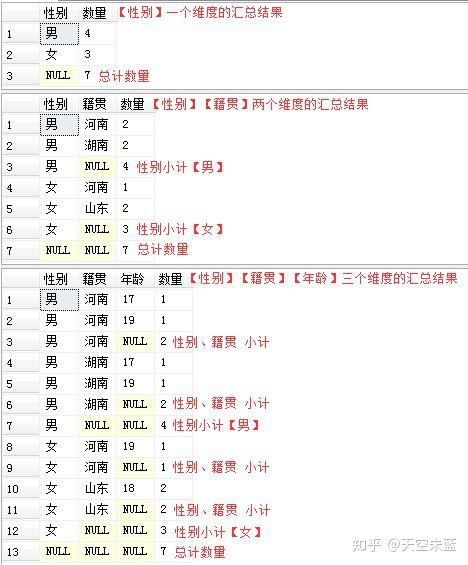
结果分析:可以看出,ROLLUP提供了更多的统计数据,并且在结果中包含了很多“NULL”值的数据行,其实这些含“NULL”的数据行就是ROLLUP提供的汇总项,再仔细分析一下,不难看出,ROLLUP计算了指定分组(就是汇总的维度)的多个层次的数量小计以及合计,先逐步创建高一级别的小计,最后再创建一行总计。整体结果都是以【性别】这一层次进行数据聚合(这也是与CUBE的不同之处)。
第三层:【GROUP BY】+【WITH CUBE】
还有没有更多组合的数据聚合,CUBE可以提供所选择列的所有组合的聚合。简单说,CUBE生成的结果是个多维数据集,就是包含各个维度的所有可能组合的交叉表格。看个例子:
--语句只用了【性别】和【籍贯】两个维度进行汇总
SELECT 性别, 籍贯, COUNT(学号) AS 数量
FROM STUDENT
GROUP BY 性别, 籍贯 WITH CUBE

结果分析:与上面的ROLLUP的结果进行对比,是不是可以看到更多的结果数据。不仅有性别的小计,还有籍贯的小计。CUBE可以为指定的列创建各种不同组合的小计,是一种比 ROLLUP更细粒度的分组统计语句。如果将统计维度调整到三个维度,会与ROLLUP有更大的差异,三个维度下的CUBE结果有点多,篇幅有限,就用个GIF展示下,感兴趣的小伙伴可以自己试一下。

最后,引用一下书面的总结,CUBE和ROLLUP之间的区别在于:
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
感觉也可以这样来说:ROLLUP就是将GROUP BY后面的第一列名称求总和,而其他列并不要求,而CUBE则会将每一个列名称都求总和。
SQL Server中cube:多维数据集实例详解
1、cube:生成多维数据集,包含各维度可能组合的交叉表格,使用with关键字连接 with cube
根据需要使用union all 拼接
判断 某一列的null值来自源数据还是 cube 使用GROUPING关键字
GROUPING([档案号]) = 1 : null值来自cube(代表所有的档案号)
GROUPING([档案号]) = 0 : null值来自源数据
举例:
SELECT * INTO ##GET
FROM
(SELECT *
FROM ( SELECT
CASE
WHEN (GROUPING([档案号]) = 1) THEN
'合计'
ELSE [档案号]
END AS '档案号',
CASE
WHEN (GROUPING([系列]) = 1) THEN
'合计'
ELSE [系列]
END AS '系列',
CASE
WHEN (GROUPING([店长]) = 1) THEN
'合计'
ELSE [店长]
END AS '店长', SUM (剩余次数) AS '总剩余',
CASE
WHEN (GROUPING([店名]) = 1) THEN
'合计'
ELSE [店名]
END AS '店名'
FROM ##PudianCard
GROUP BY [档案号], [店名], [店长], [系列]
WITH cube
HAVING GROUPING([店名]) != 1
AND GROUPING([档案号]) = 1 --AND GROUPING([系列]) = 1 ) AS M
UNION
ALL
(SELECT *
FROM ( SELECT
CASE
WHEN (GROUPING([档案号]) = 1) THEN
'合计'
ELSE [档案号]
END AS '档案号',
CASE
WHEN (GROUPING([系列]) = 1) THEN
'合计'
ELSE [系列]
END AS '系列',
CASE
WHEN (GROUPING([店长]) = 1) THEN
'合计'
ELSE [店长]
END AS '店长', SUM (剩余次数) AS '总剩余',
CASE
WHEN (GROUPING([店名]) = 1) THEN
'合计'
ELSE [店名]
END AS '店名'
FROM ##PudianCard
GROUP BY [档案号], [店名], [店长], [系列]
WITH cube
HAVING GROUPING([店名]) != 1
AND GROUPING([店长]) != 1 ) AS P )
UNION
ALL
(SELECT *
FROM ( SELECT
CASE
WHEN (GROUPING([档案号]) = 1) THEN
'合计'
ELSE [档案号]
END AS '档案号',
CASE
WHEN (GROUPING([系列]) = 1) THEN
'合计'
ELSE [系列]
END AS '系列',
CASE
WHEN (GROUPING([店长]) = 1) THEN
'合计'
ELSE [店长]
END AS '店长', SUM (剩余次数) AS '总剩余',
CASE
WHEN (GROUPING([店名]) = 1) THEN
'合计'
ELSE [店名]
END AS '店名'
FROM ##PudianCard
GROUP BY [档案号], [店名], [店长], [系列]
WITH cube
HAVING GROUPING([店名]) != 1
AND GROUPING([店长]) != 1 ) AS W )
UNION
ALL
(SELECT *
FROM ( SELECT
CASE
WHEN (GROUPING([档案号]) = 1) THEN
'合计'
ELSE [档案号]
END AS '档案号',
CASE
WHEN (GROUPING([系列]) = 1) THEN
'合计'
ELSE [系列]
END AS '系列',
CASE
WHEN (GROUPING([店长]) = 1) THEN
'合计'
ELSE [店长]
END AS '店长', SUM (剩余次数) AS '总剩余',
CASE
WHEN (GROUPING([店名]) = 1) THEN
'合计'
ELSE [店名]
END AS '店名'
FROM ##PudianCard
GROUP BY [档案号], [店名], [店长], [系列]
WITH cube
HAVING GROUPING([店名]) = 1
AND GROUPING([店长]) = 1
AND GROUPING([档案号]) = 1 ) AS K ) ) AS T
2、rollup:功能跟cube相似
3、将某一列的数据作为列名,动态加载,使用存储过程,拼接字符串
DECLARE @st nvarchar (MAX) = '';SELECT @st =@st + 'max(case when [系列]=''' + CAST ([系列] AS VARCHAR) + ''' then [总剩余] else null end ) as [' + CAST ([系列] AS VARCHAR) + '],'
FROM ##GET
GROUP BY [系列]; print @st;
4、根据某一列分组,分别建表
SELECT
'select ROW_NUMBER() over(order by [卡项] desc) as [序号], [会员],[档案号],[卡项],[剩余次数],[员工],[店名] into ' + ltrim([店名]) + ' from 查询 where [店名]=''' + [店名] + ''' ORDER BY [卡项] desc'
FROM
查询
GROUP BY
[店名]
Sql Server分组统计数据
说明:group by是sql中对数据表中的数据进行分组的,在select列表中出现的字段必须全部出现在group by 字段中,出现在聚合函数中的字段在group by中可有可无,没有出现在select列表中的字段在group by中也可以使用。在group by中不可以使用列别名。
语法:select column_name,aggregate_function(column_name) from table_name where column_name operator value group by column_name
(1)分组计算数据
a.本实例利用sum()函数和group by计算图书销售表(Booksales)中图书的总销售额
select b_code,sum(b_price) from Booksales group by b_code
b.本实例利用avg()函数和group by 计算学生表信息(studenttable) 中男生和女生的平均年龄
select studentsex,avg(studentage) from studenttable group by studentsex
c.本实例利用max()函数和group by 计算学生信息表(studenttable)中男生和女生的最大年龄
select studentsex,max(studentage) from studenttable group by studentsex
d.本实例利用min()函数和group by 计算学生信息表(studenttable)中男生和女生的最小年龄
select studentsex,min(studentage) from studenttable group by studentsex
(2)group by and all
说明:本实例中利用了group by子句和all关键字,在group by 子句中使用all关键字,只有在sql语句中包含where子句时,all才有意义。
a. 查询图书销售表(Booksales)中图书编号为1100010101的图书销售总额,且列出其他图书编号
Select b_code,sum(sal_tot) from Booksales where b_code=’1100010101’ group by all b_code
(3) ROLLUP的使用
说明:ROLLUP关键字是用来生成小计的,利用了with rollup关键字会在结果集的最后显示的行名称为空,而后面对应的值则为计算列的所有值!
a. 利用sum()和with rollup对学生信息表(studenttable)中的所有年龄生成小计
Select studentsex,sum(studentage) from studenttable group by [studentsex] with rollup
b. 利用max()和with rollup 对学生信息表(studenttable) 中的年龄最大值生成小计
Select studentsex,max(studentage) from studenttable group by [studentsex] with rollup
c.利用min()和with rollup对学生信息表(studenttable)中的年龄最小值生成小计
select studentsex,min(studentage) from studenttable group by [studentsex] with rollup
d. 利用avg()和with rollup 对学生表(studenttable)中的年龄平均值生成小计
Select studentsex,avg(studentage) from studenttable group by [studentsex] with rollup
e. 利用count()和with rollup对学生表(studenttable)中的记录数生成小计
Select studentsex,count(*) from studenttable group by [studentsex] with rollup
注意:
当with rollup与sum()一起使用时得出的结果是分组后每组的和的和
当with rollup与max()一起使用时得出的结果是分组后组的较大值
当with rollup与min()一起使用时得出的结果是分组后组的较小值
当with rollup与avg()一起使用时得出的结果是所以记录的平均值
当with rollup与count()一起使用时得出的结果是分组后各组数量的总和
(4)CUBE的使用
说明:CUBE用来生成小计和总计交叉表,group by 分组后由CUBE生成总计和小计!
a. 利用sum()和CUBE对图书销售表(Booksales)中的销售额生成小计和总计
Select b_code,b_number,sum(sal_tot) from Booksales group by b_code,b_number with cube
b. 利用max()和CUBE对图书销售表(Booksales)中的销售额生成小计和总计
Select b_code,b_number,max(sal_tot) from Booksales group by b_code,b_number with cube
c. 利用min()和CUBE对图书销售表(Booksales)中的销售额生成小计和总计
Select b_code,b_number,min(sal_tot) from Booksales group by b_code,b_number with cube
d. 利用avg()和cube对图书销售表(Booksales)中的销售额生成小计和总计
Select b_code,b_number,avg(sal_tot) from Booksales group by b_code,b_number with cube
e. 利用count()和cube对图书销售表(Booksales)中的销售额生成小计和总计
Select b_code,b_number,count(*)from Booksales group by b_code,b_number with cube
(5)where与having的使用
说明:where子句是对select语句的结果进行筛选,having子句则是对group by子句进行筛选,having子句通常和group by子句一起使用,如果不使用group by子句,则having子句的行为和where子句的行为一样,当having和group by all一起使用时,having子句代替all,在having子句中不能使用text,image和ntext类型,where子句是在进行分组之前应用,而having子句则是在分组后应用,having子句可以包含聚合函数,也可以引用选择列表中出现的任何选项,也可以应用group by中的任何选项,having也可引用没有出现在select列表的而出现在group by列表的字段。
a. 使用group by与having查询图书销售表(Booksales)中图书销售额大于200的图书编号和销售额
Select b_code,sum(b_price) from Booksales group by b_code having sum(p_price)> 200
b. 使用group by 与having查询图书销售表(Booksales)中图书销售记录大于2条的图书编号和销售额
Select b_code,sum(b_price) from Booksales group by b_code having count(*)>2
c. 使用group by与having查询销售数量大于2并且销售额大于50的图书编号和销售额按销售额降序
Select b_code,sum(b_price) from Booksales where b_number>2 group by b_code having sum(b_price)>50 order by sum(b_price) desc
d. 使用group by与having查询联系方式表(contact)中年龄不为20的id号
select id from contact group by id,ages having ages not in (20)
(6)compute与compute by的使用方法
说明:compute是对聚合函数生成小计的,一个select语句中可以有多个compute指定的聚合函数,注意在compute子句的聚合函数中不可以使用列别名,compute输出的结果为两行,
第一行:生成select_list列表中行的明细
第二行:compute子句中聚合函数的小计
Compute by 则是先实现分组然后统计compute子句中聚合函数小计的,在compute by语句中必须要有order by排序并且排序列和by分组列必须相同
第一行:生成select_list列表中行的明细
第二行:compute子句中聚合函数的小计
两个都是输出compute子句中聚合函数的小计,但是不相同的是compute输出的是聚合列在表中的所有值,而compute by 则是输出先按by子句中的字段分组以后每组的聚合列的值!
a. 查询图书销售表(Booksales)中的总销售额,销售个数
Select * from Booksales compute sum(sal_tot),sum(b_number)
b. 查询图书销售表(Booksales)中的销售额最小和最大并按图书编号升序排列
Select * from Booksales order by b_code compute max(sal_tot),min(sal_tot)
c. 查询图书销售表(Booksales)中的总销售额,销售个数按b_code分组
select * from Booksales order by b_code compute sum(sal_tot),sum(b_number) by b_code
(7)group by 和 compute by 的比较
说明:group by与compute by都可以进行分组,但是他们有一定的区别
Group by :生成单个结果集,每一行都只有分组依据列和聚合列,选择列表也只能包含分组依据列和聚合列,可排序也可不排序,如果要排序的话只能先分组后排序,排序列必须和分组列相同或者是分组列的子集或者为聚合函数产生的新列,聚合函数写在select列表中,在group by 子句中不可以使用聚合函数、在聚合函数聚合结果中可以使用列别名。
Compute by:生成多个结果集,一种结果集包括选择列表中的行的明细,另一种结果集则包含聚合以后的小计,在compute by 子句中必须排序,并且排序列必须和compute by的中分组列相同,聚合函数写在compute子句中,分组列写在by子句中,分组列可以是表中的任意列,但不可以使用列别名,在聚合函数聚合结果中不可以使用列别名。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)