

1. 什么是服务注册与发现
我们先来看下什么是服务注册与服务发现?
服务注册,就是将提供某个服务的模块信息(通常是这个服务的ip和端口)注册到1个公共的组件上去(比如: zookeeper\consul)。
服务发现,就是新注册的这个服务模块能够及时的被其他调用者发现。不管是服务新增和服务删减都能实现自动发现。
你可以理解为:
//服务注册
NameServer->register(newServer);
//服务发现
NameServer->getAllServer();
那么,为啥要这样弄呢?在回答这个问题前,我们先来看下数据请求模型的进化史。
2. web1.0数据请求模型架构
在传统的数据请求架构中,其实是没有什么服务注册和发现之说的。因为请求模型足够的简单。下图是传统的服务请求模型图:

各个客户端请求server服务器,所有的业务逻辑都是在这个server端内完成,这是常见的网络请求模型架构,对于小型的服务而已,这个架构是最合适的,因为它稳定且简单。server服务器的更新和维护也很简单。
3. web2.0数据请求模型架构
后期,随着我们的用户数渐渐变多,单台服务器的压力扛不住的时候,我们就要用到负载均衡技术,增加多台服务器来抗压,后端的数据库也可以用主从的方式来增加并发量,模型如下图所示:
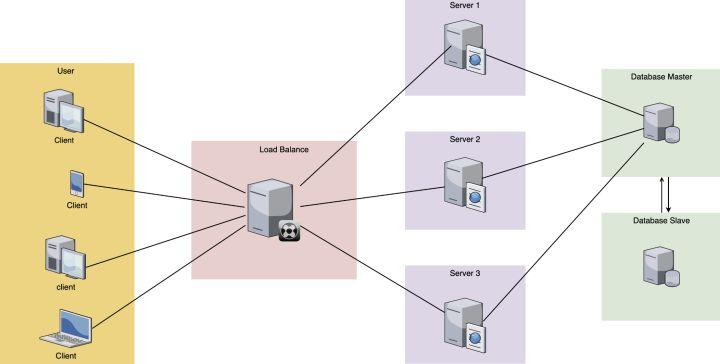
然而这个时候,依然没有服务发现和注册的影子,因为这个架构依然足够的简单和清晰。只要不断的增加后端的server服务器的数量,那么我们的整体稳定性就会得到保证。各个server服务器的更新和维护也依旧很简单。
那么啥时候才需要用到服务注册和发现呢?答案是分布式微服务时代。
4. 微服务时代的服务管理
在微服务时代,我们所有的服务都被劲量拆分成最小的粒度,原先所有的服务都在混在1个server里,现在就被按照功能或者对象拆分成N个服务模块,这样做的好处是深度解耦,1个模块只负责自己的事情就好,能够实现快速的迭代更新。坏处就是服务的管理和控制变得异常的复杂和繁琐,人工维护难度变大。还有排查问题和性能变差(服务调用时的网络开销)
比如还是上面的模型架构,在微服务时代就会变成这样子:

各个微服务相互独立,每个微服务,由多台机器或者单机器不同的实例组成,各个微服务之间错综复杂的相互关联调用。
比如上面的图中,我们将原先1个server的服务进行了拆分,拆出了User服务,Order服务,Goods服务,Search服务等等。每个服务里有N台机器或者实例。每个服务还相互关联和调动。这种错综复杂的网络架构,使得这种服务的维护成本变得比之前困难了很多。
在不用服务注册之前,我们可以想象一下,怎么去维护这种复制的关系网络呢?答案就是:写死!。将其他模块的ip和端口写死在自己的配置文件里,甚至写死在代码里,每次要去新增或者移除1个服务的实例的时候,就得去通知其他所有相关联的服务去修改。随之而来的就是各个项目的配置文件的反复更新、每隔一段时间大规模的ip修改和机器裁撤,非常的痛苦。
在微服务时代,我们会上云,会用k8s,会有docker,这样一个服务从创建到上线会变得异常的频繁,每一个接口依赖的服务,可能会随时的动态改变,靠人手的去写配置和变更配置,对于运维和开发同学来说简直就是灾难。
那么如何去解决这种问题呢?于是聪明的人类发明了服务注册和服务发现这种聪明的东西,来解放双手,提高效率。
5. 服务注册
还是上面服务模块的例子,我们看下用了服务注册和服务发现之后,我们的网络请求模块,发生了怎么的变化呢?先来看下,服务注册是怎么操作的。看下面的图:
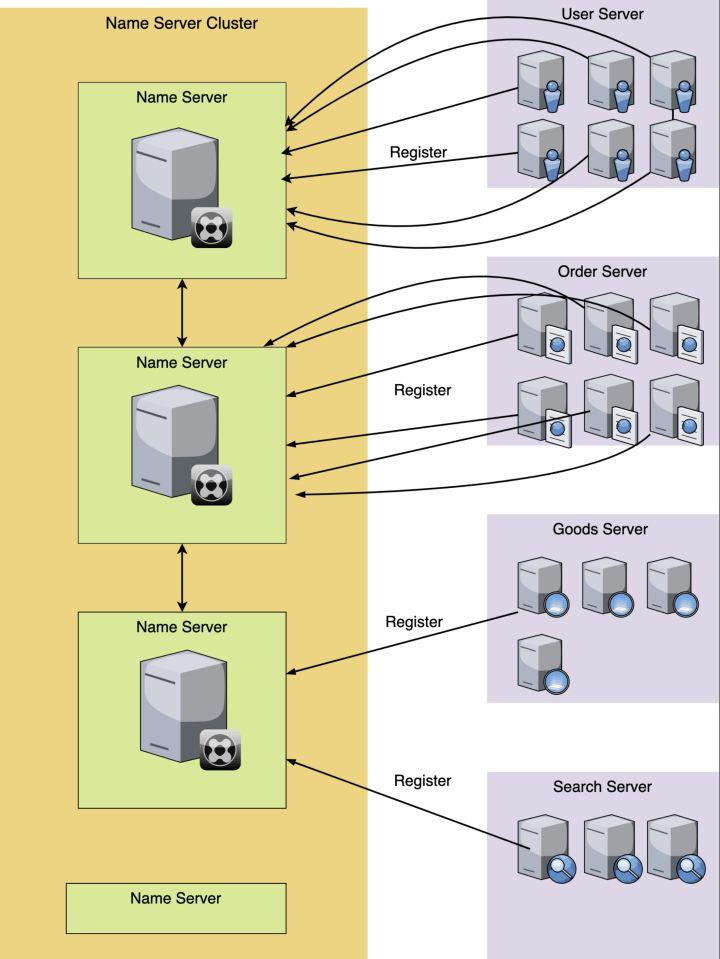
每一个服务对应的机器或者实例在启动运行的时候,都去向名字服务集群注册自己,比如图中,User服务有6个docker实例,那么每个docker实例,启动后,都去把自己的信息注册到名字服务模块上去,同理Order服务也是一样。
对应的伪代码可以表示如下:
//给User服务申请1个独有的专属名字
UserNameServer = NameServer->apply('User');
//User服务下的6台docker实例启动后,都去注册自己
UserServer1 = {ip: 192.178.1.1, port: 3445}
UserNameServer->register(UserServer1);
......
UserServer6 = {ip: 192.178.1.6, port: 3445}
UserNameServer->register(UserServer6);
//给Order服务申请1个独有的专属名字
OrderNameServer = NameServer->apply('Order');
//开始注册
OrderServer1 = {ip: 192.178.1.1, port: 3446}
OrderNameServer->register(OrderServer1);
//给Search服务申请1个独有的专属名字
SearchNameServer = NameServer->apply('Search');
//开始注册
SearchServer1 = {ip: 192.178.1.1, port: 3447}
SearchNameServer->register(SearchServer1);
这样,每个服务的机器实例在启动后,就完成了注册的操作。注册的方式有很多的形式,不同的名字服务软件方式不一样,有HTTP接口形式,有RPC的方式,也有使用JSON格式的配置表的形式的。方式虽然不同,但是结果都是一样。
实例注册到名字服务上之后,接下来就是服务发现了。
6. 服务发现
我们把每个服务的机器实例注册到了名字服务器上之后,接下来,我们如何去发现我们需要调用的服务的信息呢?这就是服务发现了。
我们看下,服务发现是怎么做的:
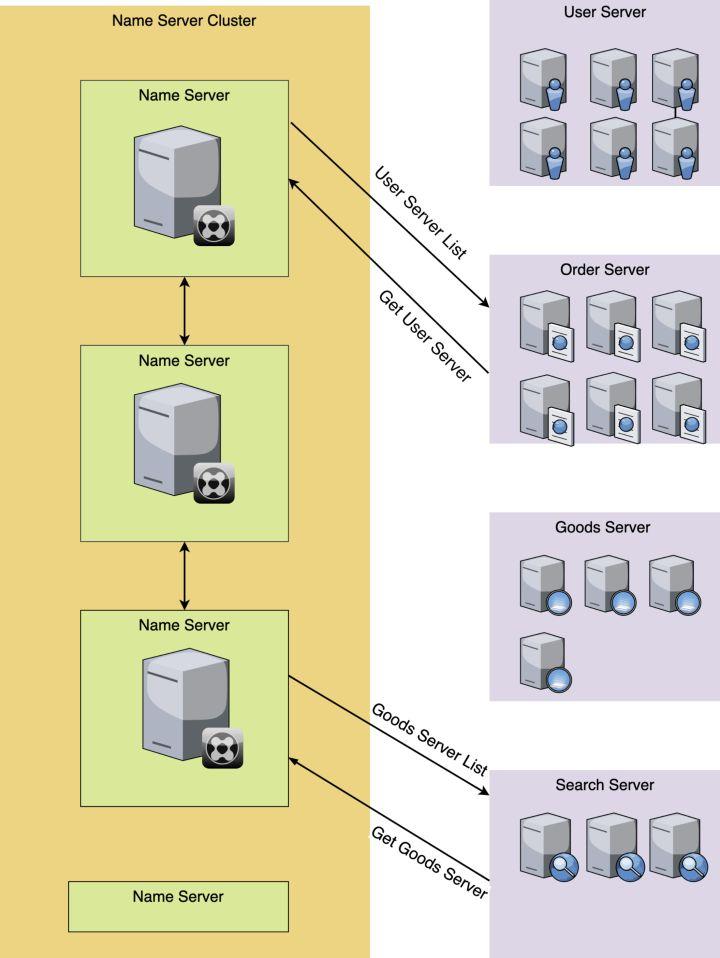
在上图中,Order服务想要获取User服务相关的信息,首先向注册集群中心发送请求获取,然后就能收到User服务相关的信息。
伪代码可以表示如下:
//服务发现,获取User服务的列表
list = NameServer->getAllServer('User');
//list的内容
[
{
"ip": "192.178.1.1",
"port": 3445
},
{
"ip": "192.178.1.2",
"port": 3445
},
......
{
"ip": "192.178.1.6",
"port": 3445
}
]
//服务发现,获取Goods服务的列表
list = NameServer->getAllServer('Goods');
//list的内容
[
{
"ip": "192.178.1.1",
"port": 3788
},
{
"ip": "192.178.1.2",
"port": 3788
},
......
{
"ip": "192.178.1.4",
"port": 3788
}
]
我们通过服务发现,就获得了User模块的所有的ip列表,然后,我们再用一定的负载均衡算法,或者干脆随机取1个ip,进行调用。
当然,也有些注册服务软件也提供了DNS解析功能或者负载均衡功能,它会直接返回给你一个可用的ip,你直接调用就可以了,不用自己去做选择。
这样,我们获取了服务的IP信息后,就可以进行调用了,如图所示:
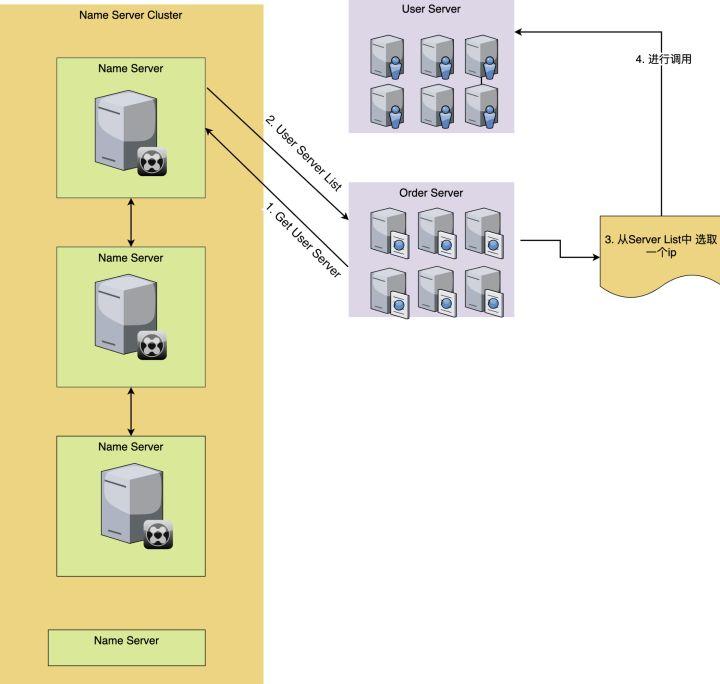
和服务注册的方式一样,服务发现的方式,不同的名字服务软件的方式也会不一样,有的是得自己发送HTTP接口去轮训调用,如果发现有更新,就更新自己本地的配置文件。有的是可以通过实时的sub/pub的方式实现的自动发现服务,当我订阅的这个服务内容发生了更新,就实时更新自己的配置文件。也有的是通过RPC的方式。方式虽然不同,但是结果都是一样。
这样一来,我们就可以通过服务注册和发现的方式,维护各个服务IP列表的更新,各个模块只需要向名字服务中心去获取某个服务的IP就可以了,不用再写死IP。整个服务的维护也变得轻松了很多。彻底解放了双手!
7. 健康检查
可能你会说,这样加了1个中间代理,饶了一个大圈子,感觉也挺费劲的,难道仅仅是为了解决新增服务,动态获取IP的问题吗?
当然不是!服务注册和服务发现,不仅仅解决了服务调用这种写死IP以及杂乱无章的管理的状态,更重要的一点是它还管理了服务器的存活状态,也就是健康检查。
很多名字服务软件都会提供健康检查功能。注册服务的这一组机器,当这个服务组的某台机器,如果出现宕机或者服务死掉的时候,就会标记这个实例的状态为故障,或者干脆剔除掉这台机器。这样一来,就实现了自动监控和管理。
健康检查有多重实现方式,比如有几秒就发一次健康检查心跳,如果返回的HTTP状态不是200,那么就判断这台服务不可用,对它进行标记。也可以执行一个shell脚本,看执行的返回结果,来标记状态等等。
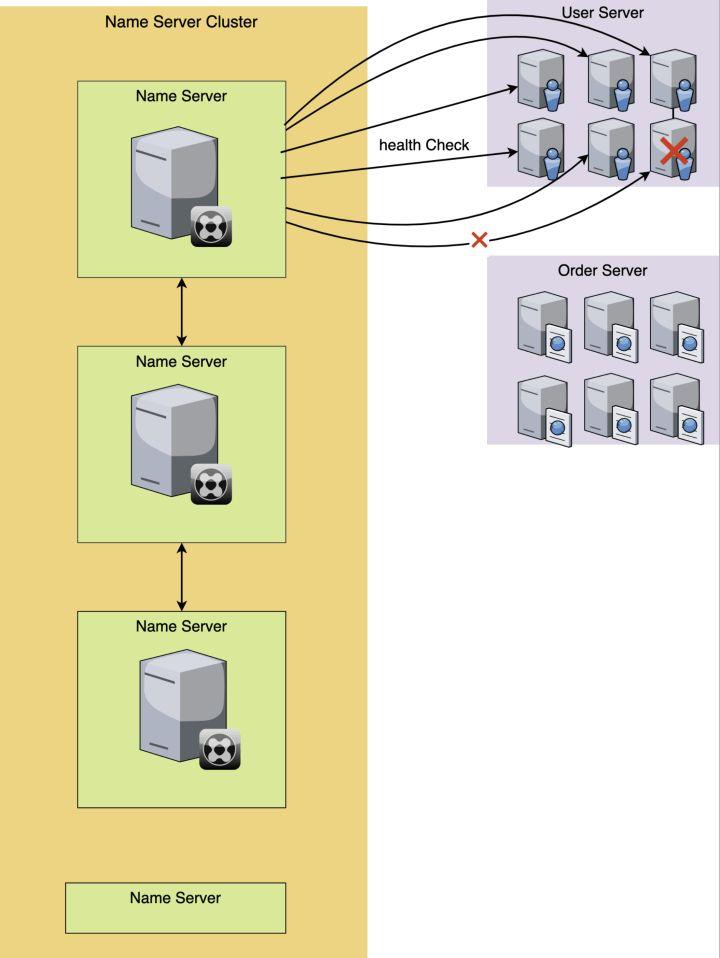
上图中,用心跳发送的方式来检查健康状态,当有1台机器出现异常,这样我们获取服务的时候,就能知道服务的健康状态了。
比如伪代码如下:
//服务发现,获取User服务的列表
list = NameServer->getAllServer('User');
//list的内容
[
{
"ip": "192.178.1.1",
"port": 3445,
"status": "success"
},
{
"ip": "192.178.1.2",
"port": 3445,
"status": "success"
},
......
{
"ip": "192.178.1.6",
"port": 3445
"status": "error" //故障,出现错误
}
]
我们通过判断列表里的status的状态是不是success来确认调用的服务是可用的。有些名字服务会提供DNS解析功能,直接就会把有问题的机器给去掉,你服务发现后的机器服务就是正常可用的。
同时,当服务不可用的时候,有些名字服务软件也会提供发送邮件或者消息功能,及时的提示你服务出现故障。这样一来,我们就通过健康检查功能,来帮我们及时的去规避问题,降低影响。
当出现故障的服务被修复后,服务重新启动后,健康检查会检查通过,然后这台机器就会被标记为健康,这样,服务发现,就又可以发现这台机器了。
这样,整个服务注册和服务发现,就实现了闭环。
8. 服务注册和服务发现的难点
上面通过一系列的例子,我们解释了服务注册和服务发现的整个过程,以及通过它给我们带来的一系列优秀的变化。那如果我要自己去做一个提供服务注册和发现的这样一款软件,难吗?
答案是:难!非常难!
我们先看下这个软件的功能清单:
- 集群: 得组成集群,这样单台出现故障,不至于服务宕机
- 数据同步: 组成了集群,得要数据同步,注册的信息,在1台注册了,在其他机器上也能看到,不然的话,1台挂了,他这台的数据都丢失了。
- 强一致性: 数据同步,在多台要有一致性的要求,保证数据不会出现不一致的情况。
- 高并发高可用: 要能保证请求量比较大的情况下,服务还能保持高可用。
- 选举机制: 在有集群和数据同步以及一致性要求的情况下,得有一个master来主持整个运作,那就要有选取机制,确保选举公平和稳定。
- 分布式: 随着微服务上云,各个机器可能近在眼前,却远在天边,如何支撑分布式上的不同环境的机器互联,这也是一个很大的问题。
- 安装简单: 一个软件好不好用,是否亲民,安装的易用性是一个很大的因素,如果一个软件安装简单,调试方便,那么就会很受欢迎。
所以,你看,开发一款注册发现的软件还是有非常大的挑战的。
9. 市面上业界的解决方案
目前市面上已经有了服务注册和服务发现的解决方案,代表作是:zookeeper和consul以及etcd,他们功能强大,安全稳定,高并发高可用,强一致性,目前市面上都是用这几个来实现自己的服务注册和发现的。
以下是这3款软件的优缺点对比:

其中,consul 是后起之秀,源于它安装简单,功能强大,提供健康检查,web管理后台,支持多数据中心,暴露了方便的HTTP接口,使得它被更多的人所使用,唯一不足的是它不支持sub/pub订阅机制,所以服务发现,得使用者自己去HTTP轮训发现变更。
后期我会写篇文件详细的介绍一下consul的安装和使用过程。
10. 鹅厂的服务注册和服务发现解决方案
我们大鹅厂,也有自己的服务注册和服务发现解决方案,我们每天都在用,可能你没发现而已,那就是大名鼎鼎的L5。
L5已经深入到鹅厂开发的每一个角落,现在服务提供者几乎都在使用L5来提供服务发现功能。
还记得L5是如何使用的吗?
第一步,我们创建1个SID,由2个数子组成,比如:13232323:5332323232,这个SID就相当于服务注册里面的服务名,我们通过这个唯一的名字,来实现服务注册和服务发现。
伪代码可以表示如下:
//其他生成
UserNameServer = NameServer->apply('User');
//L5生成
UserNameServer = L5->apply('User');
//UserNameServer=> 13232323:5332323232
第二步,服务注册,我们需要把机器的ip和port注册到SID上去,我们可以通过接口加入,也可以通过CL5平台提供的界面操作加入:
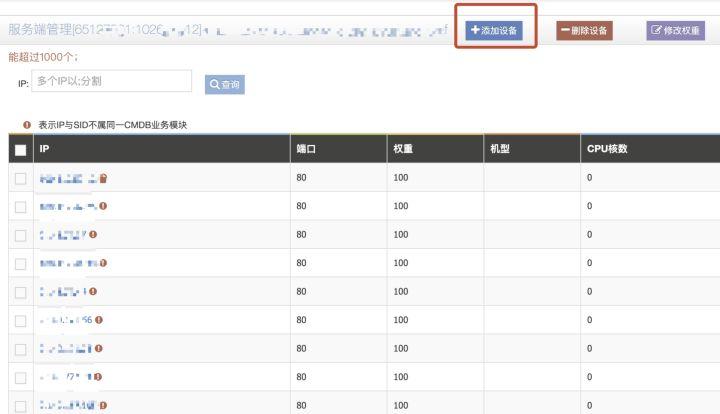
第三步,服务发现,我们在代码里直接通过相关语言的L5扩展函数,就可以实现发现服务功能。值得一说的是,L5也实现了负载均衡功能,服务发现并不是给你所有的IP列表,而是通过负载均衡算法,直接给出了你一个可用的IP和port,非常方便。
以下代码是PHP语言获取L5服务发现的简略过程:
$l5Info = [
'modId' => $modId,
'cmdId' => $cmdId,
];
$ret = L5ApiGetRoute($l5Info, 0.2);
//获得IP和port
$ip = $l5Info['hostIp'];
$port = $l5Info['hostPort'];
//其他业务逻辑和上报逻辑省略
好了,服务注册和服务发现就说完了,希望这篇文章足够的清晰和简单,让你能明白为什么要用服务注册和发现,以及用了之后,实实在在的给我们开发者提供了优秀的生产力功能。
-----------------------------------------------------------------
深入理解RPC之服务注册与发现篇
在我们之前 RPC 原理的分析中,主要将笔墨集中在 Client 和 Server 端。而成熟的服务治理框架中不止存在这两个角色,一般还会有一个 Registry(注册中心)的角色。一张图就可以解释注册中心的主要职责。
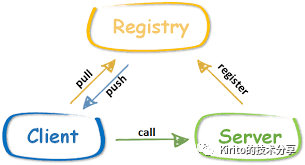
- 注册中心,用于服务端注册远程服务以及客户端发现服务
- 服务端,对外提供后台服务,将自己的服务信息注册到注册中心
- 客户端,从注册中心获取远程服务的注册信息,然后进行远程过程调用
目前主要的注册中心可以借由 zookeeper,eureka,consul,etcd 等开源框架实现。互联网公司也会因为自身业务的特性自研,如美团点评自研的 MNS,新浪微博自研的 vintage。
本文定位是对注册中心有一定了解的读者,所以不过多阐述注册中心的基础概念。
注册中心的抽象
借用开源框架中的核心接口,可以帮助我们从一个较为抽象的高度去理解注册中心。例如 motan 中的相关接口:
服务注册接口
public interface RegistryService {
//1. 向注册中心注册服务 void register(URL url); //2. 从注册中心摘除服务 void unregister(URL url); //3. 将服务设置为可用,供客户端调用 void available(URL url); //4. 禁用服务,客户端无法发现该服务 void unavailable(URL url); //5. 获取已注册服务的集合 Collection<URL> getRegisteredServiceUrls(); }服务发现接口
public interface DiscoveryService {
//1. 订阅服务 void subscribe(URL url, NotifyListener listener); //2. 取消订阅 void unsubscribe(URL url, NotifyListener listener); //3. 发现服务列表 List<URL> discover(URL url); }主要使用的方法是 RegistryService#register(URL) 和 DiscoveryService#discover(URL)。其中这个 URL 参数被传递,显然也是很重要的一个类。
public class URL {
private String protocol;//协议名称 private String host; private int port; // interfaceName,也代表着路径 private String path; private Map<String, String> parameters; private volatile transient Map<String, Number> numbers; }注册中心也没那么玄乎,其实可以简单理解为:提供一个存储介质,供服务提供者和服务消费者共同连接,而存储的主要信息就是这里的 URL。但是具体 URL 都包含了什么实际信息,我们还没有一个直观的感受。
注册信息概览
以元老级别的注册中心 zookeeper 为例,看看它实际都存储了什么信息以及它是如何持久化上一节的 URL。
为了测试,我创建了一个 RPC 服务接口 com.sinosoft.student.api.DemoApi ,并且在 6666 端口暴露了这个服务的实现类,将其作为服务提供者。在 6667 端口远程调用这个服务,作为服务消费者。两者都连接本地的 zookeeper,本机 ip 为 192.168.150.1。
使用 zkClient.bash 或者 zkClient.sh 作为客户端连接到本地的 zookeeper,执行如下的命令:
[zk: localhost:2181(CONNECTED) 1] ls /motan/demo_group/com.sinosoft.student.api.DemoApi > [client, server, unavailableServer]zookeeper 有着和 linux 类似的命令和结构,其中 motan,demo_group,com.sinosoft.student.api.DemoApi,client, server, unavailableServer 都是一个个节点。可以从上述命令看出他们的父子关系。
/motan/demo_group/com.sinosoft.student.api.DemoApi 的结构为 /框架标识/分组名/接口名,其中的分组是 motan 为了隔离不同组的服务而设置的。这样,接口名称相同,分组不同的服务无法互相发现。如果此时有一个分组名为 demo_group2 的服务,接口名称为 DemoApi2,则 motan 会为其创建一个新的节点 /motan/demo_group2/com.sinosoft.student.api.DemoApi2
而 client,server,unavailableServer 则就是服务注册与发现的核心节点了。我们先看看这些节点都存储了什么信息。
server 节点:
[zk: localhost:2181(CONNECTED) 2] ls /motan/demo_group/com.sinosoft.student.api.DemoApi/server > [192.168.150.1:6666] [zk: localhost:2181(CONNECTED) 3] get /motan/demo_group/com.sinosoft.student.api.DemoApi/server/192.168.150.1:6666 > motan://192.168.150.1:6666/com.sinosoft.student.api.DemoApi?serialization=hessian2&protocol=motan&isDefault=true&maxContentLength=1548576&shareChannel=true&refreshTimestamp=1515122649835&id=motanServerBasicConfig&nodeType=service&export=motan:6666&requestTimeout=9000000&accessLog=false&group=demo_group&client 节点:
[zk: localhost:2181(CONNECTED) 4] ls /motan/demo_group/com.sinosoft.student.api.DemoApi/client > [192.168.150.1] [zk: localhost:2181(CONNECTED) 5] get /motan/demo_group/com.sinosoft.student.api.DemoApi/client/192.168.150.1 > motan://192.168.150.1:0/com.sinosoft.student.api.DemoApi?singleton=true&maxContentLength=1548576&check=false&nodeType=service&version=1.0&throwException=true&accessLog=false&serialization=hessian2&retries=0&protocol=motan&isDefault=true&refreshTimestamp=1515122631758&id=motanClientBasicConfig&requestTimeout=9000&group=demo_group&unavailableServer 节点是一个过渡节点,所以在一切正常的情况下不会存在信息,它的具体作用在下面会介绍。
从这些输出数据可以发现,注册中心承担的一个职责就是存储服务调用中相关的信息,server 向 zookeeper 注册信息,保存在 server 节点,而 client 实际和 server 共享同一个接口,接口名称就是路径名,所以也到达了同样的 server 节点去获取信息。并且同时注册到了 client 节点下(为什么需要这么做在下面介绍)。
注册信息详解
Server 节点
server 节点承担着最重要的职责,它由服务提供者创建,以供服务消费者获取节点中的信息,从而定位到服务提供者真正网络拓扑位置以及得知如何调用。demo 中我只在本机 [192.168.150.1:6666] 启动了一个实例,所以在server 节点之下,只存在这么一个节点,继续 get 这个节点,可以获取更详细的信息
motan://192.168.150.1:6666/com.sinosoft.student.api.DemoApi?serialization=hessian2&protocol=motan&isDefault=true&maxContentLength=1548576&shareChannel=true&refreshTimestamp=1515122649835&id=motanServerBasicConfig&nodeType=service&export=motan:6666&requestTimeout=9000000&accessLog=false&group=demo_group&作为一个 value 值,它和 http 协议的请求十分相似,不过是以 motan:// 开头,表达的意图也很明确,这是 motan 协议和相关的路径及参数,关于 RPC 中的协议,可以翻看我的上一篇文章《深入理解RPC之协议篇》。
serialization 对应序列化方式,protocol 对应协议名称,maxContentLength 对应 RPC 传输中数据报文的最大长度,shareChannel 是传输层用到的参数,netty channel 中的一个属性,group 对应分组名称。
上述的 value 包含了 RPC 调用中所需要的全部信息。
Client 节点
在 motan 中使用 zookeeper 作为注册中心时,客户端订阅服务时会向 zookeeper 注册自身,主要是方便对调用方进行统计、管理。但订阅时是否注册 client 不是必要行为,和不同的注册中心实现有关,例如使用 consul 时便没有注册。
由于我们使用 zookeeper,也可以分析下 zookeeper 中都注册了什么信息。
motan://192.168.150.1:0/com.sinosoft.student.api.DemoApi?singleton=true&maxContentLength=1548576&check=false&nodeType=service&version=1.0&throwException=true&accessLog=false&serialization=hessian2&retries=0&protocol=motan&isDefault=true&refreshTimestamp=1515122631758&id=motanClientBasicConfig&requestTimeout=9000&group=demo_group和 Server 节点的值类似,但也有客户独有的一些属性,如 singleton 代表服务是否单例,check 检查服务提供者是否存在,retries 代表重试次数,这也是 RPC 中特别需要注意的一点。
UnavailableServer 节点
unavailableServer 节点也不是必须存在的一个节点,它主要用来做 server 端的延迟上线,优雅关机。
延迟上线:一般推荐的服务端启动流程为:server 向注册中心的 unavailableServer 注册,状态为 unavailable,此时整个服务处于启动状态,但不对外提供服务,在服务验证通过,预热完毕,此时打开心跳开关,此时正式提供服务。
优雅关机:当需要对 server 方进行维护升级时,如果直接关闭,则会影响到客户端的请求。所以理想的情况应当是首先切断流量,再进行 server 的下线。具体的做法便是:先关闭心跳开关,客户端感知停止调用后,再关闭服务进程。
感知服务的下线
服务上线时自然要注册到注册中心,但下线时也得从注册中心中摘除。注册是一个主动的行为,这没有特别要注意的地方,但服务下线却是一个值得思考的问题。服务下线包含了主动下线和系统宕机等异常方式的下线。
临时节点+长连接
在 zookeeper 中存在持久化节点和临时节点的概念。持久化节点一经创建,只要不主动删除,便会一直持久化存在;临时节点的生命周期则是和客户端的连接同生共死的,应用连接到 zookeeper 时创建一个临时节点,使用长连接维持会话,这样无论何种方式服务发生下线,zookeeper 都可以感知到,进而删除临时节点。zookeeper 的这一特性和服务下线的需求契合的比较好,所以临时节点被广泛应用。
主动下线+心跳检测
并不是所有注册中心都有临时节点的概念,另外一种感知服务下线的方式是主动下线。例如在 eureka 中,会有 eureka-server 和 eureka-client 两个角色,其中 eureka-server 保存注册信息,地位等同于 zookeeper。当 eureka-client 需要关闭时,会发送一个通知给 eureka-server,从而让 eureka-server 摘除自己这个节点。但这么做最大的一个问题是,如果仅仅只有主动下线这么一个手段,一旦 eureka-client 非正常下线(如断电,断网),eureka-server 便会一直存在一个已经下线的服务节点,一旦被其他服务发现进而调用,便会带来问题。为了避免出现这样的情况,需要给 eureka-server 增加一个心跳检测功能,它会对服务提供者进行探测,比如每隔30s发送一个心跳,如果三次心跳结果都没有返回值,就认为该服务已下线。
注册中心对比
|
Feature |
Consul |
zookeeper |
etcd |
euerka |
|---|---|---|---|---|
|
服务健康检查 |
服务状态,内存,硬盘等 |
(弱)长连接,keepalive |
连接心跳 |
可配支持 |
|
多数据中心 |
支持 |
— |
— |
— |
|
kv存储服务 |
支持 |
支持 |
支持 |
— |
|
一致性 |
raft |
paxos |
raft |
— |
|
cap |
ca |
cp |
cp |
ap |
|
使用接口 |
支持http和dns |
客户端 |
http/grpc |
http |
|
watch支持 |
全量/支持long polling |
支持 |
支持 long polling |
支持 long polling/大部分增量 |
|
自身监控 |
metrics |
— |
metrics |
metrics |
|
acl /https |
acl |
https支持 |
— | |
|
spring cloud集成 |
已支持 |
已支持 |
已支持 |
已支持 |
一般而言注册中心的特性决定了其使用的场景,例如很多框架支持 zookeeper,在我自己看来是因为其老牌,易用,但业界也有很多人认为 zookeeper 不适合做注册中心,它本身是一个分布式协调组件,并不是为注册服务而生,server 端注册一个服务节点,client 端并不需要在同一时刻拿到完全一致的服务列表,只要最终一致性即可。在跨IDC,多数据中心等场景下 consul 发挥了很大的优势,这也是很多互联网公司选择使用 consul 的原因。 eureka 是 ap 注册中心,并且是 spring cloud 默认使用的组件,spring cloud eureka 较为贴近 spring cloud 生态。
总结
注册中心主要用于解耦服务调用中的定位问题,是分布式系统必须面对的一个问题。更多专业性的对比,可以期待 spring4all.com 的注册中心专题讨论,相信会有更为细致地对比。







 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)