性能测试基础及loadRunner的使用(超详细)
狭义的并发用户数:同一时刻,使用系统的同一个功能(发送请求)的用户数量。(后面使用loadRunnner进行性能测试都是狭义的)广义的并发用户数:同一时刻,给服务器产生压力(发送请求) 的用户数量。不用严格要求使用的是不是同一个功能。系统用户数:注册这个系统的用户数量。在线用户数:某一时刻登录系统的数量。狭义和广义的并发放用户数,都是基于在给服务器发送请求的基础上计算的。而系统用户数和在线用户数它
文章目录
一、性能测试的基本概念
1.广义用户数、狭义用户数、系统用户、在线用户
狭义的并发用户数:同一时刻,使用系统的同一个功能(发送请求)的用户数量。(后面使用loadRunnner进行性能测试都是狭义的)
广义的并发用户数:同一时刻,给服务器产生压力(发送请求) 的用户数量。不用严格要求使用的是不是同一个功能。
系统用户数:注册这个系统的用户数量。
在线用户数:某一时刻登录系统的数量。
狭义和广义的并发放用户数,都是基于在给服务器发送请求的基础上计算的。而系统用户数和在线用户数它们不一定都正在给服务器发送请求。
例如:系统用户数中有注册后不再使用的,就不给服务器发送请求了。在线用户数中,如果是用户在浏览其中的页面,没有点击什么按钮发送请求,就不算是在线用户数。
问:1000个系统用户,500个用户在线,100个用户已经打开网页在浏览,200个用户在进行查询操作,100个用户在进行提交操作,100个用户去吃饭洗衣服,那么请问,给服务器产生压力的用户数有多少?
广义用户数来看,有300个。包括在进行查询操作的200个用户,在进行提交操作的100个用户。
2.响应时间(RT)、平均响应时间(ART)、事务响应时间(TRT)、每秒事务通过数(TPS)
响应时间:用户发送请求到期待的结果出现所经历的时间。(loadRunner中帮我们算了)
响应时间=人的反应时间+网络传输时间(来回)+服务器的处理时间+数据库的响应时间
而平均响应时间是系统的各个功能的响应时间的平均值,用来衡量系统的性能的其中一个指标。
事务反应时间:
首先:什么是事务?
事务是一组密切相关操作的集合。例如:在支付的系统中,就包含了事务的处理。即集合中的操作全部成功才算成功,一个失败就算失败。
事务反应时间就是:服务器处理一个事务所用的时间。
每秒事务通过数(Transaction Per Second):
TPS 是指每秒系统能够处理的事务数。它是衡量系统处理能力的重要指标。
当压力加大时,TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈了。如果环境没有发生大的变化,对于同一系统会存在一个最大处理事务能力,它并不随着并发用户的增减而改变。
如:
地铁检票机:
只有十台进站检票的机器,一台机器一秒能进一个人
并发用户数为5,则TPS为5
并发用户数为10,则TPS为10
并发用户数为100,则TPS仍为
3.点击率、吞吐量、资源利用率
点击率:每秒向服务器发送的HTTP请求的个数。
吞吐量(吞吐率):服务器在单位信息处理的信息量。单位有:bytes、TPS
思考时间:思考时间就是用户进行操作时,每个请求或者操作之间的间隔时间,是为了更加真实地模拟用户的操作场景。
资源利用率:不同系统资源的使用情况。CPU,Memory,磁盘,网络的占用情况。
二、性能测试模型
1.曲线拐点模型
下图的吞吐量指的是平均吞吐量。
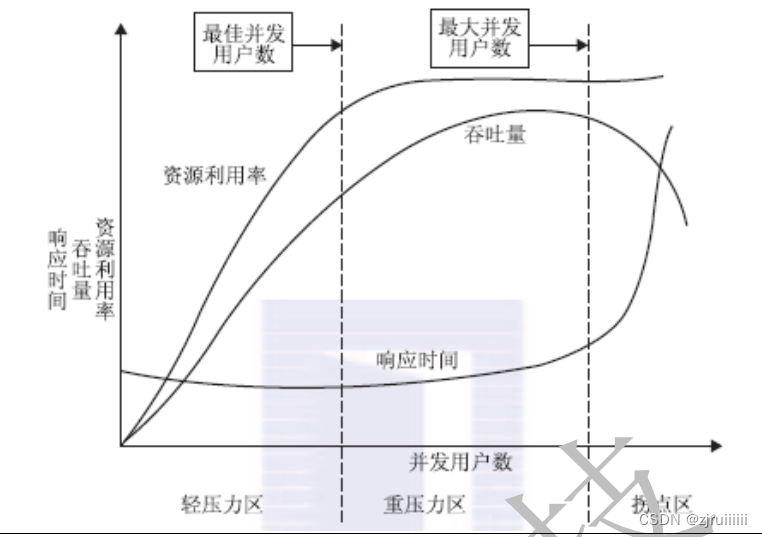
拐点:系统处理信息的能力是有限的,它有最大的信息处理量,一旦超过这个系统所能承受的处理信息量后,系统的性能就会发生极大的改变,开始转变的点就称为拐点。
一般进行性能测试的时候,找出拐点是很重要的,因为我们能够基于他来提升系统的性能,通过测试不同的功能、算法,看看是哪一块还可以改善,因此就可以再优化系统的性能了。
2.地铁模型
假设:
某地铁站进站只有3个刷卡机。
人少的情况下,每位乘客很快就可以刷卡进站,假设进站需要1s。
乘客耐心有限,如果等待超过30min,就暴躁、唠叨,甚至放弃。
场景一:只有1名乘客进站时,这名乘客可以在1s的时间内完成进站,且只利用了一台刷卡机,剩余2台等待着。
场景二:只有2名乘客进站时,2名乘客仍都可以在1s的时间内完成进站,且利用了2台刷卡机,剩余1台等待着。
场景三:只有3名乘客进站时,3名乘客还能在1s的时间内完成进站,且利用了3台刷卡机,资源得到充分利用。
场景四:A、B、C三名乘客进站,同时D、E、F乘客也要进站,因为A、B、C先到,所以D、E、F乘客需要排队。
那么,A、B、C乘客进站时间为1s,而D、E、F乘客必须等待1s,所以他们3位在进站的时间是2s。
场景五:假设这次进站一次来了9名乘客,有3名的“响应时间”为1s,有3名的“响应时间”为2s(等待1s+进站1s),还有3名的“响应时间”为3s(等待2s+进站1s)。
场景六:如果地铁正好在火车站,每名乘客都拿着大小不同的包,包太大导致卡在刷卡机堵塞,每名乘客的进站时间就会又不一样。刷卡机有加宽的和正常宽度的两种类型,那么拿大包的乘客可以通过加宽的刷卡机快速进站(增加带宽)。
场景七:进站的乘客越来越多,3台刷卡机已经无法满足需求,为了减少人流的积压,需要再多开几个刷卡机,增加进站的人流与速度(提升TPS、增大连接数)。
场景八:终于到了上班高峰时间了,乘客数量上升太快,现有的进站措施已经无法满足,越来越多的人开始抱怨、拥挤,情况越来越糟。单单增加刷卡机已经不行了,此时的乘客就相当于“请求”,乘客不是在地铁进站排队,就是在站台排队等车,已经造成严重的“堵塞”,那么增加发车频率(加快应用服务器、数据库的处理速度)、增加车厢数量(增加内存、增大吞吐量)、增加线路(增加服务的线程)、限流、分流等多种措施便应需而生。
三、性能测试分类介绍
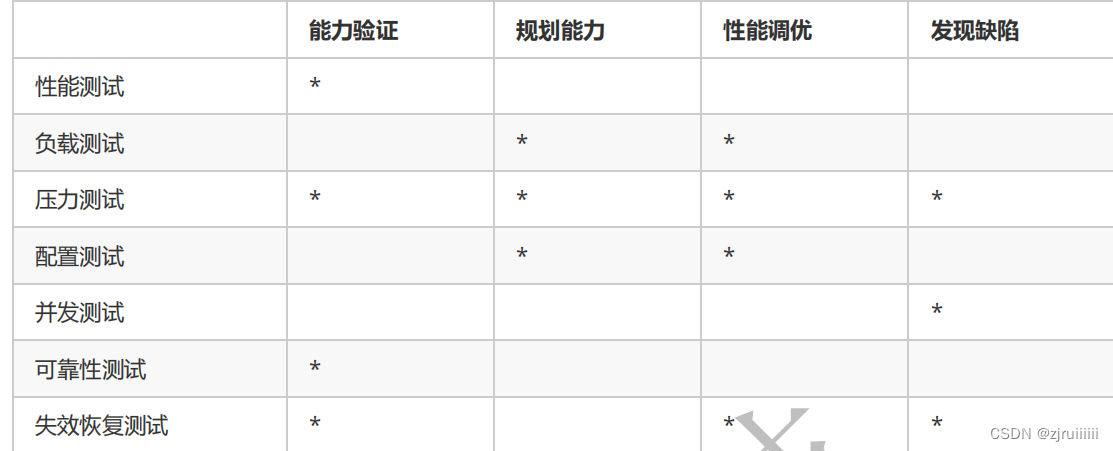
1.基准测试
应用场景:
1)可以在制定的标准下通过基准测试建立一个性能基准,这样以后当系统的环境、参数发生变化之后,再进行一
次相同标准下的测试,即可看出变化对性能的影响。
2)系统进行基准测试可以在较早的阶段发现性能问题。
3)某系统从来没有进行过任何性能测试,需要对该系统做一次性能评估作为后续开发调优的参考。
2.狭义性能测试
向系统中的同一个功能(发送请求)施加压力的性能测试。
3.负载测试
给系统定容定量,在系统上不断增加负载(用户数),看系统最大承受的用户负载是多少,看系统是否达到了需求所需要的性能指标,RT、TRT、吞吐率、资源利用率等。
4.压力(强度)测试
一般是让系统的用户负载达到饱和长时间运行,检查系统资源分配是否合理,线程同步问题,内存泄漏,检查原因。
目的:为了找出系统的性能瓶颈,以及产生系统性能瓶颈的原因。
是一个量变到质变的过程,随着性能的下降后,我们要去查原因,去修改可以提高性能的地方。
负载测试和并发测试都是基于并发测试的基础上的。
5.配置测试
通过测试不同的应用服务器,网络环境,数据库不同的参数,不同的硬件设备,查看系统的性能表现,找出最优最合理的资源配置。
6.可靠性测试
长时间运行系统,查看系统的性能指标(响应时间、TPS、点击率、吞吐量、资源利用率)是否稳定。要求在负载最大的承受范围的70%~90%间进行测试。
7.失效恢复测试
一个一个公司中的服务器不可能是一个,是很多个一起运行的。此时就要人为的破坏其中的一个服务器,看看其它服务器的性能指标的变化是否正常。该方法就是在测试中模拟设备故障,验证预期的恢复技术是否可以正常发挥作用。
但不是所有的系统都需要进行这种类型的测试,尤其是并没有明确给出系统需要持续运行指标的系统。
总结:
四、loadRunner
1.loadRunner的基本概念
功能:LoadRunner是一种适用于许多软件体系架构的自动负载测试工具,从用户关注的响应时间、吞吐量,并发用户和性能计数器等方面来衡量系统的性能表现,辅助用户进行系统性能的优化。
组成:LoadRunner主要包括三个前台功能组件,分别为VuGen(虚拟用户脚本生成器)、Controller(测试控制器)和Analysis(结果分析器)。系统会自动调用后台功能组件LG(负载生成器)和Proxy(用户代理)来完成性能测试工作。
VuGen 是录制与便携脚本的地方。通过录制或编写脚本来模拟用户的行为。
Controller是执行负载测试管理和监控的中心。在这里指定具体的性能测试方案,执行性能测试,收集测试数据,监控测试指标。监控工具将测试过程中收集到的客户机、服务器和网络性能指标数据显示在监控页面上,便于测试人员对系统表现进行随时掌握。
LG是模拟多用户并发访问被测试系统的组件。模拟多用户访问系统的前提是已经具备了虚拟用户脚本,VuGen是录制和编辑虚拟用户脚本的工具,录制好的脚本是不同语言表达的文本文件,在LG执行时被解析和执行。脚本录制和回放过程是在Proxy支持下完成的。
Analysis在测试完成后,对测试过程中收集到的各种性能数据进行计算、汇总和处理,生成各种图表和报告,为系统性能测试结果分析提供支持。
在使用loadrunner之前,先了解一下几个概念:
1.Scenario:场景。所谓场景,是指在每一个测试过程中发生的事件。
Vusers:虚拟用户。LoadRunner使用多线程或多进程来模拟用户对应用程序操作时产生的压力。一个场景可能包括多个虚拟用户,甚至成千上万个虚拟用户。
2.Vuser Script:脚本。用脚本来描述Vuser在场景中执行的动作。
3.Transactions:事务。事务代表了用户的某个业务过程,需要衡量这些业务过程的性能。
4.rendezvous :集合。当我们测试多个用户并发时,每个用户执行到该事务脚本的先后顺序是不确定的,所以得到的测试结果也并不是一个完全并发的极限测试结果。在开始事务之前 ,插入一个“集合点”,那么在多用户执行时,就可以将用户请求停下来,直到用户数量达到满足的条件(默认是100%的用户都到达集合点)。那么,所有的用户都将同时发出接下来的请求。
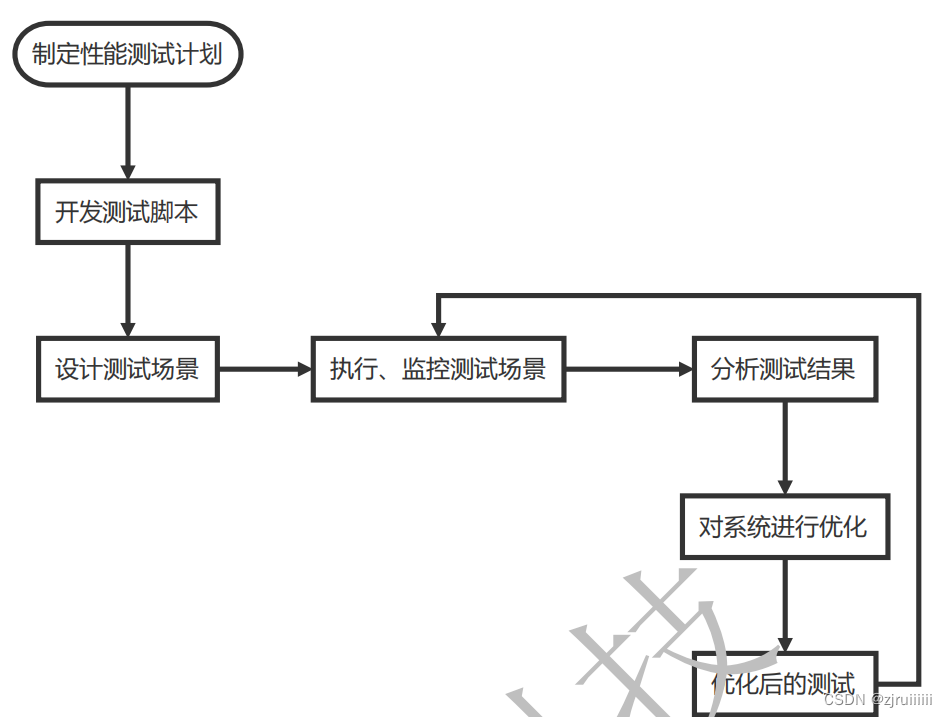
Loadrunner的性能测试过程:
2.开发测试脚本
首先,我们要打开loadRunner安装路径下的WebTours文件夹,在WebTours文件夹中有个StartServer.bat的批处理文件,点击它就启动了loadRunner了。此时再去打开VUGen才会有效。
打开VUGen后,先创建一个Script:
进入到下面的页面:
选择Web-HTTP/HTML的协议即可。设置Script的名字和存放的路径,再进行创建即可。
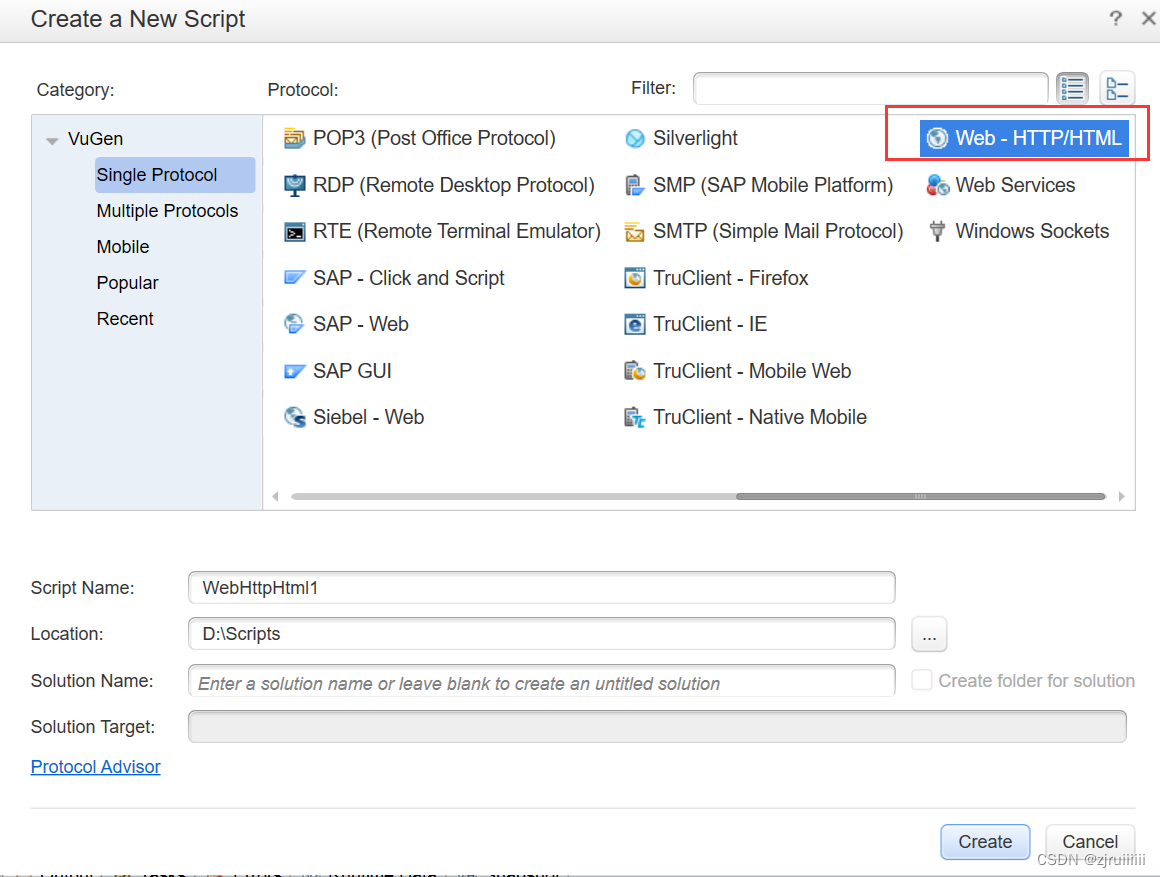
创建完毕后,此时在左上角看到:
有vuser init,Action,vuser end,我们一般关心的是Action。vuser_init用于用户初始化,vuser_end用于用户清理工作。Action用于具体的需要测试的操作。类似于unittest等测试框架。
注意:在重复执行测试脚本时,vuser_init 和vuser_end 中的内容只会执行一次,重复执行的只是Action 中的部分。
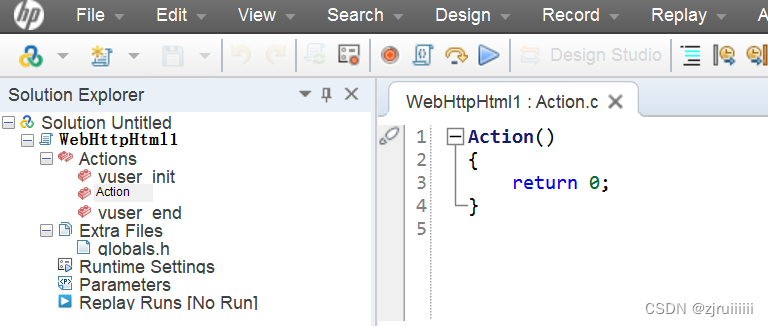
点击红色的圈圈开始录制:
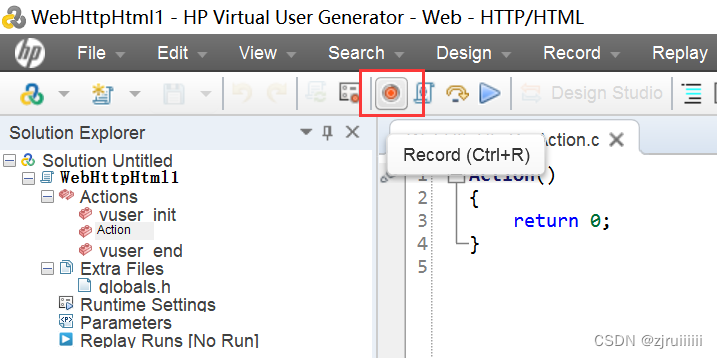
点击它后会有一个弹窗:
Application中是选择录制的浏览器。如果是第一次录制,URL address中是空白的,加上http://127.0.0.1:1080/WebTours/。其它的默认就行。
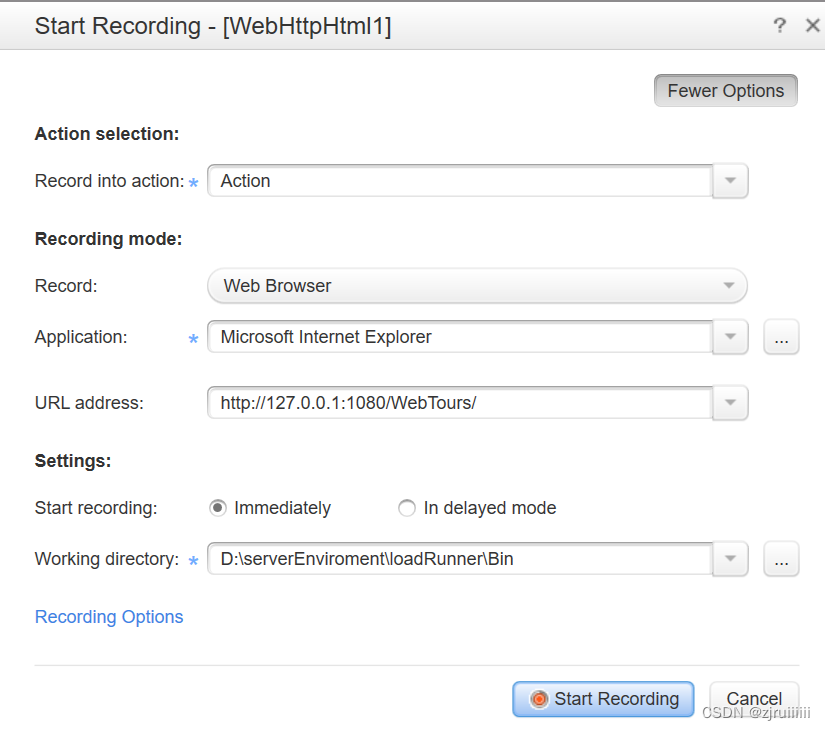
点击start recording后,会弹出ie浏览器的界面,让我们输入用户名和密码:
那么我们如何得知用户名和密码呢?

在我安装loadRunner的路径下,D:\serverEnviroment\loadRunner\WebTours\cgi-bin\users下存放的就是用户的用户名和密码,点进去就可以看到是什么了。对于增加用户的数量,我们可以将原来jojo的文件复制,再在里面去修改用户名即可。
得知用户名和密码后,就可以在ie浏览器上登录。
在登录之前,可以先设置一个集合,确保用户数是在同一时刻登录的。然后再开启一个事务,再进行登录。
设置集合和开启事务的方法如下图:左边的图标为开启事务,右边的图标为开启集合。

登录成功后,我们发现浏览器页面上有Weclome,jojo…,等下我们可以用这句话的内容来进行对登录是否成功的测试。
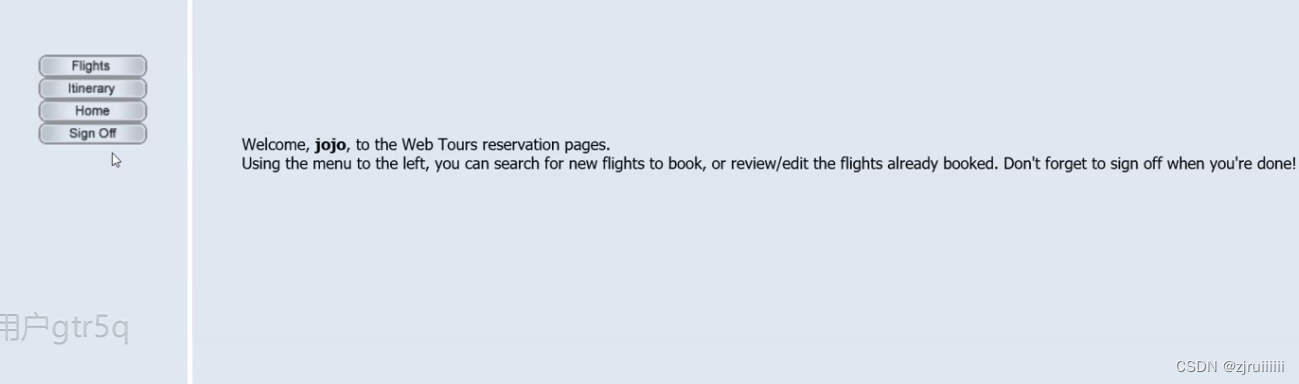
登录好后,终止事务,再停止录制,接着关闭浏览器。
此时再返回Action中,可以看到脚本录制生成了测试的代码。生成脚本后可以点击Replay看看脚本是否有问题:
3.插入检查点
在进行压力测试时,为了检查Web 服务器返回的网页是否正确,VuGen 允许我们插入Text 检查点,这些检查点验证网页上是否存在指定的Text,还可以测试在比较大的压力测试环境中,被测的网站功能是否保持正确。检查点的含义和unittest中的断言功能基本上一致。
首先,如果在页面的底栏没有Snapshot,就点击顶栏的view中的Snapshot即可。

有了Snapshot之后,将鼠标点击在login的代码当中,Snapshot才有效,否则点击不同的位置,Snapshot是不同的。
将Snapshot展开,选择下图对应的选项,就可以看到刚才在登录成功后含有的内容。
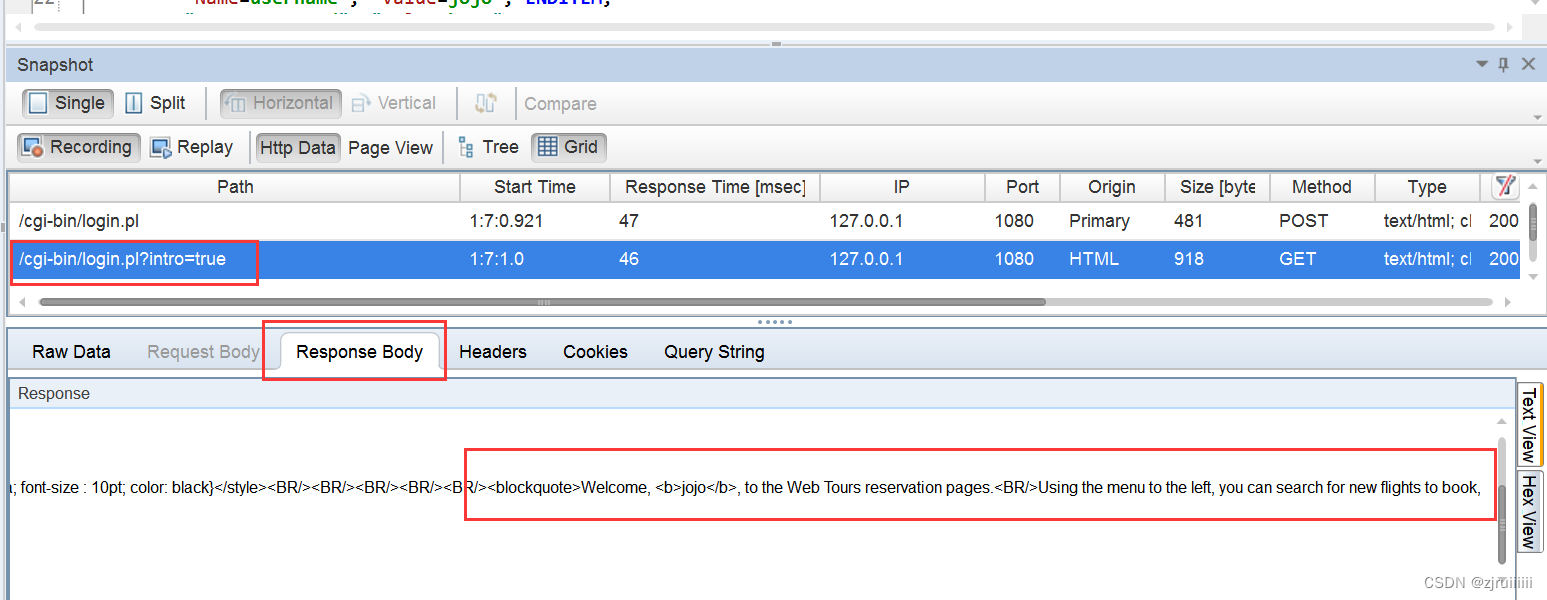
因此,我们可以截取一段,生成一个检查点:
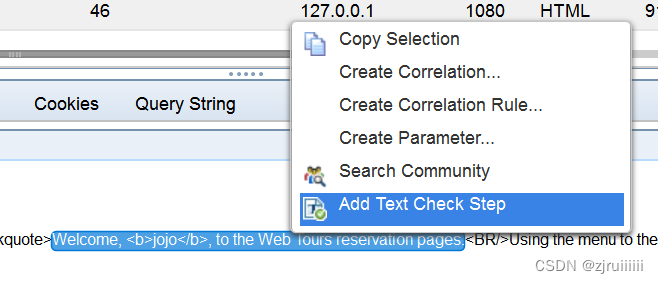
弹出了一个网页,直接点击OK即可:
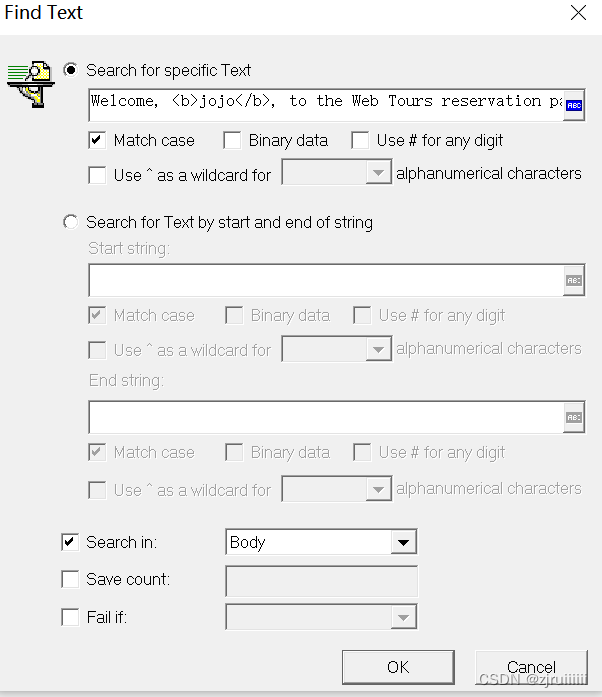
此时就可以看到,在脚本中为我们生成了一段代码:
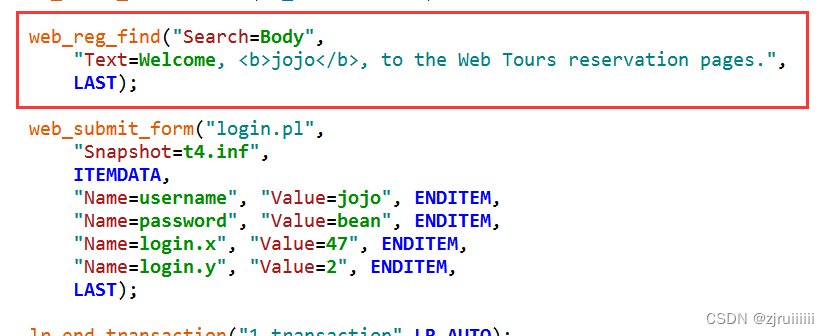
此时直接Replay肯定是不可行的,因为这个检查点是在登录之前,而我们刚才登录之后才看到了该内容。有两个解决办法:
1.将检查点的代码移动到登录的测试代码之后。
2.在检查点的LAST前加入以下代码:"SaveCount=reservation_Count,"就能解决问题了,如:

此时点击Replay就肯定是没有问题的了。
4.插入事务和插入集合点
插入事务和插入集合点的方式很简单,根本不用我们写代码,loadRunner能够帮助我们自动生成。
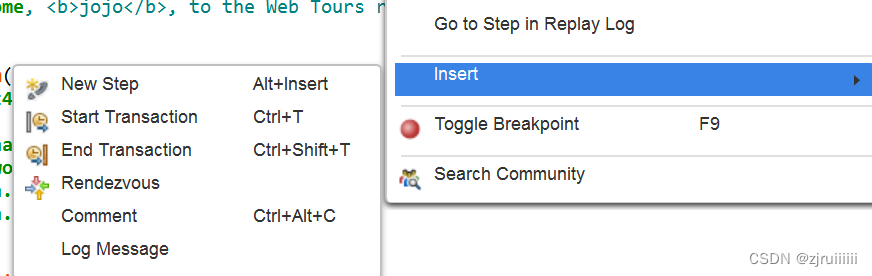
开启事务的语法:lr_start_transaction("register");
结束事务的语法:lr_end_transaction("register", LR_AUTO);
集合点的语法:lr_rendezvous("index");
5.关联和参数化输入
当有这么一个场景,此时需要模拟很多个用户,用户名不同但是密码相同,此时我们不可能将登录的测试代码复制很多,然后将对应的用户名修改。这是很不科学的。因此参数化的输入应运而生。
进行变量的参数化,首先要将变量关联起来。
因为此时的场景是有不同的用户名去登录,则关联的是用户名。
方法:
在Snapshot中找到对应的用户名,右击生成关联:
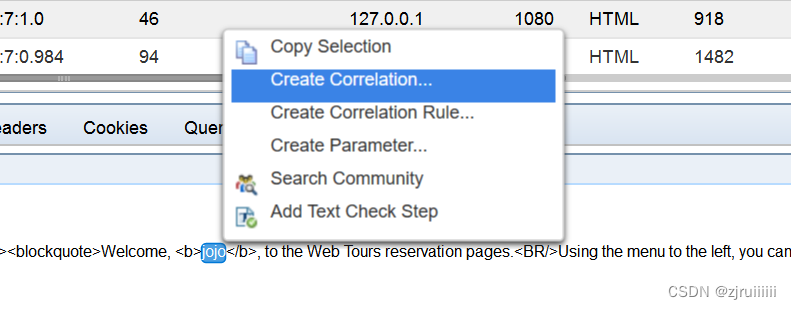
此时弹出个窗口:点击Correlate生成关联:
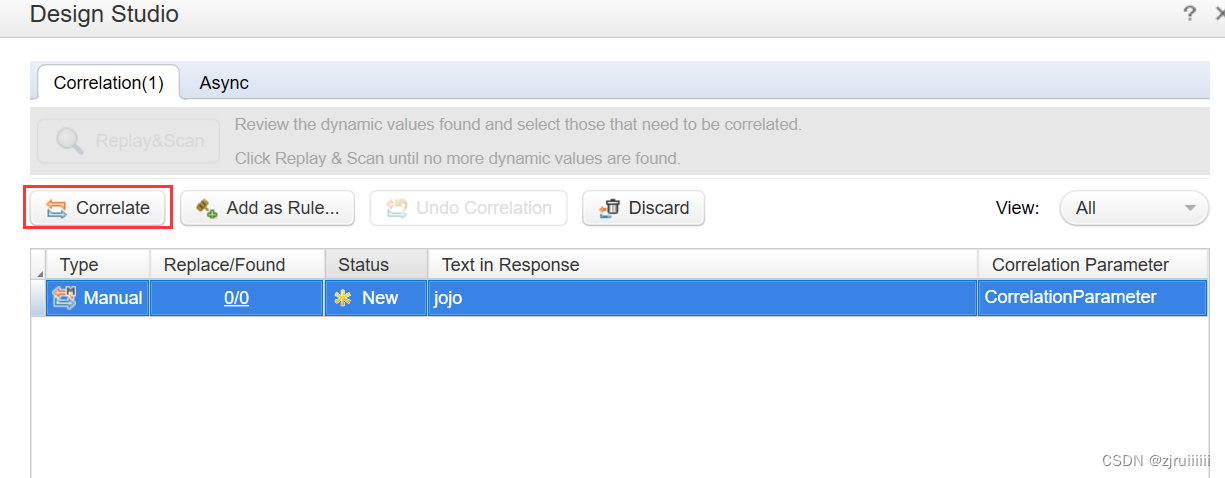
此时在测试的脚本中生成了如下代码:

现在直接Replay的话,肯定是会报错的,报错原因是没有找到匹配的参数。
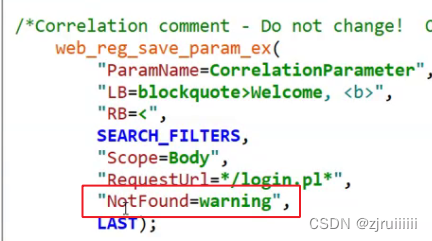
只需要在关联的代码中加上NotFound=warning即可。
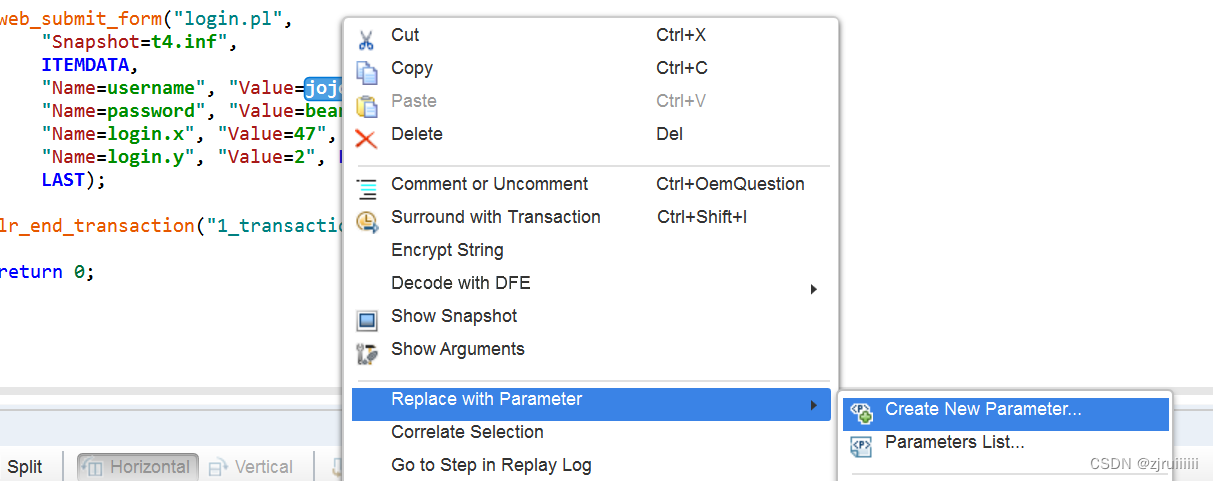
为了达到一个代码能够实现多个用户的登录,此时将用户名参数化:
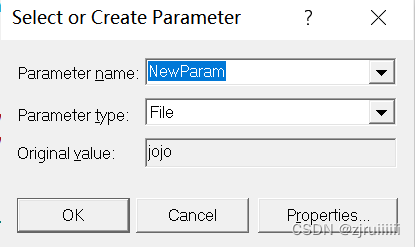
此时个弹窗:修改下参数的名字,现在我们取它为userName后,点击OK。
我们发现,代码中的jojo,全部都被替换成了{userName} 。
但是现在的用户名只有一个”jojo“,即使在user的文件夹中创建了其它的用户,直接去Replay也是不能关联上的,此时就需要添加对应的变量:选择userName(不包含{}),右击,再点击Parameter Properties:
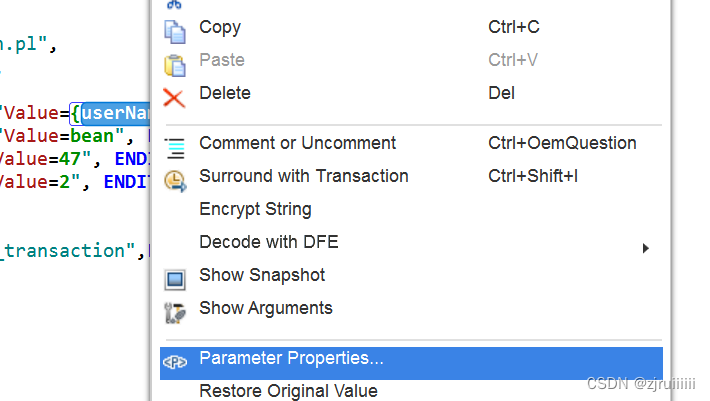
此时添加变量的方式有三种:第一种是直接在空白处添加,需要自己将对应的名字改为user文件夹中我们自己创建的用户名。第二种是直接将.txt文件放入。第三种是弹出一个Notepad,在里面输入变量名。
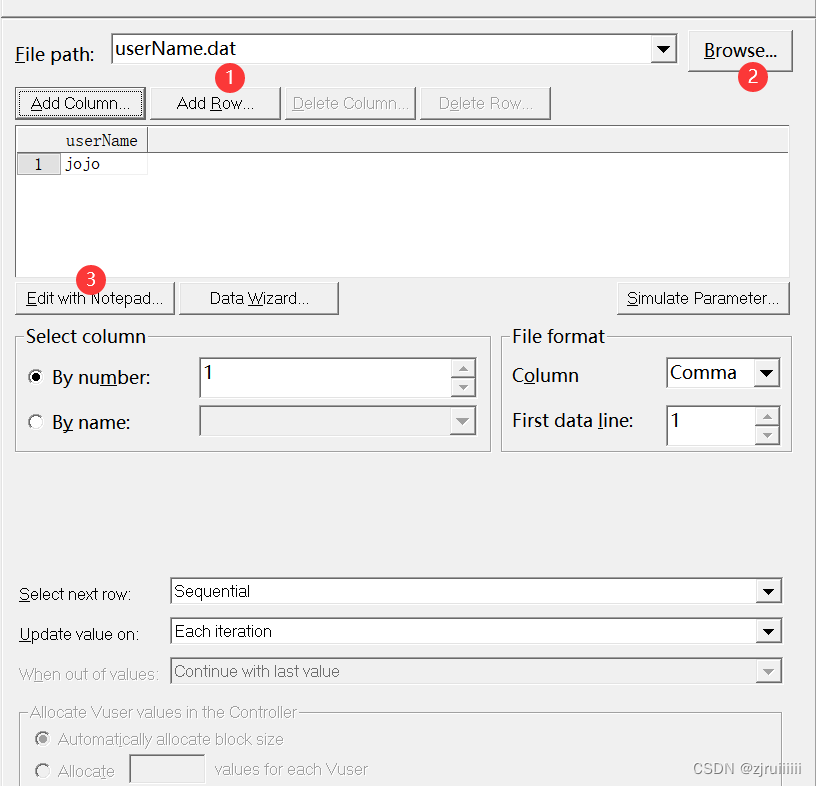
此时我们添加了三个用户,但是Replay后,我们发现运行的次数还是一次:
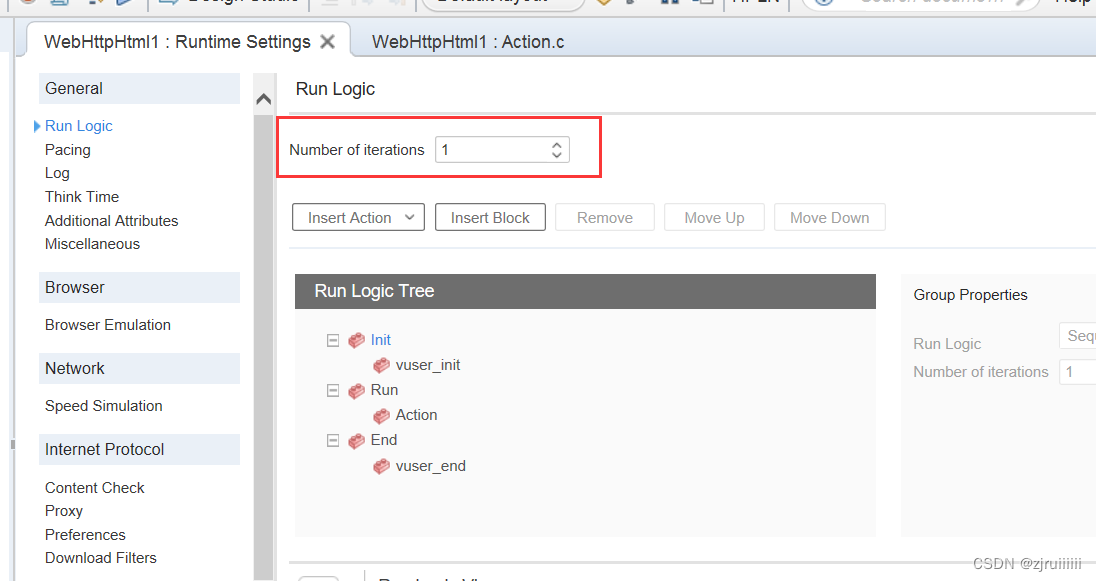
我们可以对运行的次数进行修改:
1.在Action页面中点击Replay:
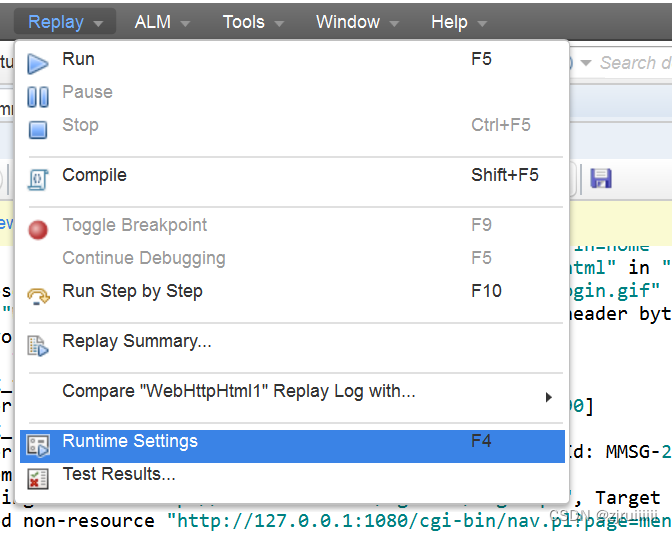
2.修改下图的值为3后进行×掉,保存:
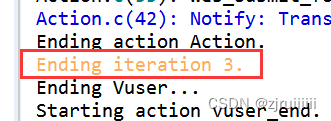
现在再对Action进行Replay,就可以发现运行了三次了:
6.插入函数
1.控制脚本流程
if { } else { }
for{ }
while{ }
2.字符串函数
strcmp 比较两个字符串
strcat 连接两个字符串
strcpy 拷贝字符串
3.输出函数
输出函数在调试脚本时非常有用。
lr_output_message 输出一条消息
4.LoadRunner 提供的标准函数
lr_eval_string 该函数功能是得到参数(参数化输入中)当前的值
lr_eval_string("{userName}")
7.Parameter Properties中的细节
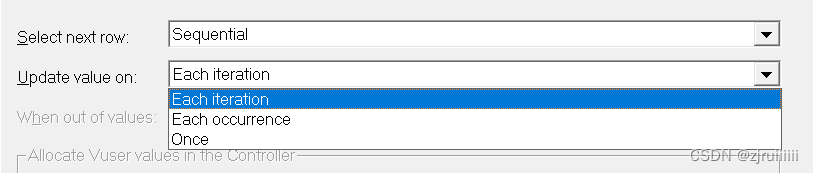
对于参数化中的Parameter Properties界面,在Update value on选项中,Each iteration是按照我们设置的参数的顺序去Replay,而Each occurrence 是随机地抽取变量去Replay,抽取的结果可能会重复,而Once 是选择变量的第一个进行Replay,如果是要Replay三次,那么运行的三次可能都是该变量。
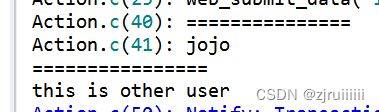
假设选择了Each occurrence选项,再在登录后判断用户名是否为jojo:

奇怪的现象出现了:
(因为选择的Each occurrence选项,jojo是第二个出现的) 我们发现打印的是jojo用户名,但是却打印了this is other user:
原因是:此时判断的是顺序是按照我们在Parameter Properies中添加变量的顺序是相同的。即下图的顺序:


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 26
26 2
2- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)