Oracle性能优化(11g)
oracle性能优化思路分析
优化的常见思路
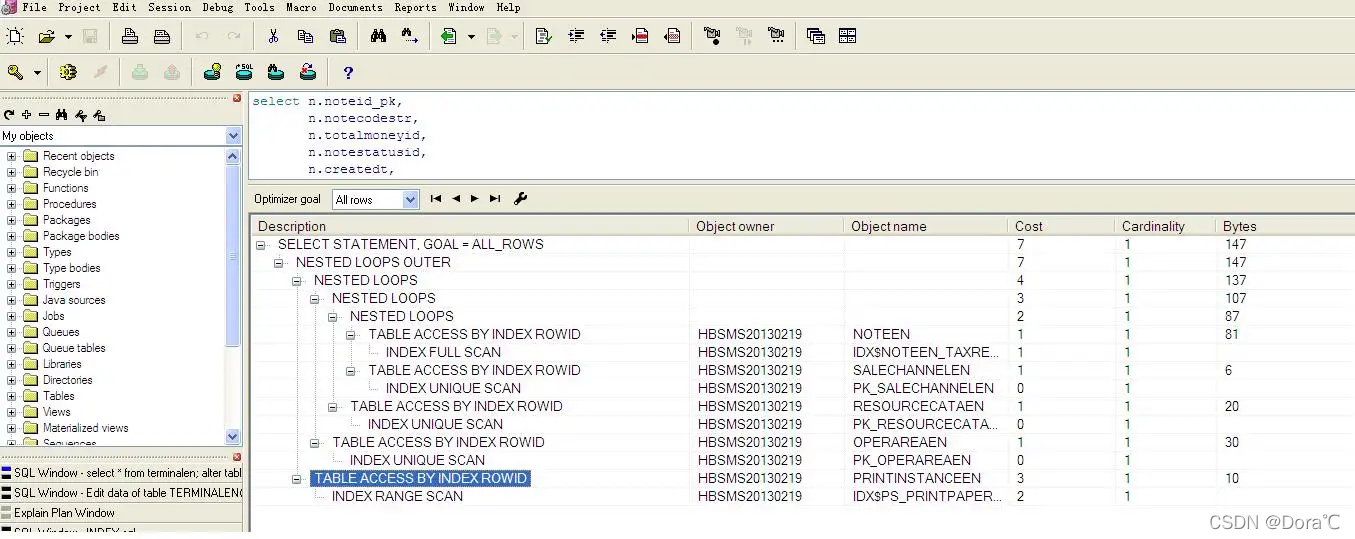
Oracle优化必不可少的就是看优化器。下面简单介绍一下优化器里面,我认为比较重要的名词
1、优化器的基本概念
优化器上我们需要关注的字段,Cost(耗费),Cardinality(基数),CPU cost(CPU耗费),Depth(纵深),IO cost(IO耗费),Access predicates(访问谓词),Filter predicates(过滤器谓词)。
耗费:约等于CPU耗费和IO耗费的综合所得
基数:优化器预估筛选出来的行数
CPU耗费,IO耗费:字面意思
纵深:执行顺序,数字越大执行就越在前面。也可以通过树状结构看出来。
访问谓词:使用索引时所使用的筛选条件。组合索引时候,可以看出来使用了某个索引的那几个字段
过滤器谓词:不使用索引时所使用的筛选条件。
2、索引的基本概念
简单介绍一下各个索引的不同。
索引大概分为以下几种
1、index scan(索引扫描)
数据库通过遍历索引来检索一行,使用语句中指 定的索引列的值。(该值为索引列,这是前提)
如果数据库为一个值扫索引,那么它将在 n 次 I/O 中找到这个值,其中 n 是 B-树索引的高度。这是 Oracle 数据库索引背后的基本原理。
如果一个 SQL 语句仅访问索引列,那么数据库直接从索引而不是表中读取值。如果语句访问除索引列外的列,那么数据库使用 rowid 来查找表中的行。
2、full index scan(完全索引扫描)
数据库按顺序读取整个索引。
前提条件:如果谓词(predicate)(谓词就是指WHERE语句的条件)在SQL语句中引用了索引中的列, 或者在某些情况下没有任何指定谓词时,full index scan是可用的。
full index scan可以消除排序,因为数据本身就是基于索引键排序的。
假设一个应用程序运行下面的查询:
SELECT department_id, last_name, salary FROM employees
WHERE salary > 5000 ORDER BY department_id, last_name;
再假定 department_id,last_name 和 salary 是索引中的组合键。Oracle 数据库进行索引的完全扫描,按照排序顺序读取(通过 department_id,last_name 顺序)并在salary 上过滤。
通过这种方式,数据库只需扫描一个小于雇员表的数据集,而不用扫描那些未包含在查询中的列,并避免了对该数据进行排序。
3、fast full index scan(快速完全索引扫描)
是一种完全索引扫描,数据库在索引本身中访问数据,而不用访问表,并且数据库读取索引块没有固定的顺序。
当以下两个条件都满足的情况下,快速完全索引扫描是全表扫描 (full table scan)的一种替代:
索引键中至少一列具有 NOT NULL 约束
索引包含了查询所需的所有列
SELECT last_name, salary
FROM employees;
如果姓氏和工资都是索引中的复合键,那么快速索引扫描可以读取索引中的条目来获取所需的信息:
4、index range scan(索引范围扫描)
这个是我们需要最常见的
索引范围扫描是对索引的有序扫描。
例如,一个用户查询哪位员工的姓氏起始是 A。假设 last_name 列被索引,
数据库可以使用范围扫描,因为在谓词中指定了 last_name 列,而且每个索引键可能对应多个 rowids。
例如有两个雇员名叫 Austin,所以有两个 rowids 都与索引键 Austin 相关联。
范围扫描可以使用唯一索引或非唯一索引。当索引列构成ORDER BY/GROUP BY子句时,范围扫描可避免排序。
5、index unique scan(唯一索引扫描)最快
唯一索引扫描必须是0 个或1个rowid 与索引键相关联。(即根据索引键,只能找到0个或1个的值)
当一个谓词使用相等运算符引用了唯一索引键的所有列时,数据库将执行唯一扫描。只要找到了第一个记录,唯一索引扫描就停止处理,因为不可能有第二个记录满足条件。
6、index skip scan(索引跳跃扫描)
该类索引比较慢,是优化时需要观察的
索引跳跃扫描使用复合索引的逻辑子索引。如果数据库正在查找分开的索引,那么它会“跳跃”通过单一索引。跳跃索引是有好处的,如果有几个不同值在复合索引的前列并且许多的不同值在非前列键的索引中。
例如, 假设你对客户在 sh.customers 表中运行下列查询:
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.com';
customers 表中有一 cust_gender 列,其中值是 M 或 F。假设(cust_gender,cust_email)列存在复合索引。
假设复合索引条目数据
F,Wolf@company.com,rowid
F,Wolsey@company.com,rowid
F,Wood@company.com,rowid
F,Woodman@company.com,rowid
M,Abbassi@company.com,rowid
M,Abbey@company.com,rowid
虽然未在 WHERE 子句中指定 cust_gender,数据库可以使用跳跃索引扫描。数据库在逻辑上将该索引拆分为一个具 有 F 键的子索引和另一个具有 M 键的子索引。所以
当搜索电子邮件为 Abbey@company.com 的客户的记录时, 数据库首先搜索 F 值的子索引,然后搜索 M 值的子索引。从概念上讲,数据库这样处理查询,如下所示:
SELECT * FROM sh.customers WHERE cust_gender = 'F'
AND cust_email = 'Abbey@company.com'
UNION ALL
SELECT * FROM sh.customers WHERE cust_gender = 'M'
AND cust_email = 'Abbey@company.com';
3、常见优化问题及解决方式
优化思路:
1、在查看优化器时,要根据depth的来查看,从高的看起。观察是从哪里开始消耗开始变大了。
2、注意索引使用过后,基数依旧很大的索引,谓词是否已经命中。
3、使用的索引类型是否符合
基本上就两个问题,有没有用上索引,用上的索引对不对。
常见现象:
问题一、索引选择量比较大,过滤后变小
解决思路:
1、根据访问谓词,过滤器谓词判断使用的索引是否最佳。
2、查看现存的索引是否能用上。
一般解决方法有增加索引,增加字段筛选。
问题二、使用索引类型不好
类似于使用了位图索引,full index scan,index skip scan
1、位图索引,一般是由于单个索引筛选量不够造成的。解决方法基本上是增加组合索引
2、full index scan,一般是由于索引没有使用上造成的。
3、index skip scan,一般是索引的位置与谓词不对应造成的。结合业务分析是否要更改索引或增加索引。
问题三、类型不一致导致没有用上索引,常见于联表操作
两个表的两个字段需要一致才能用上索引,可以使用TO_CHAR解决。但如果筛选的列加上TO_CHAR等的话,则会使用不上索引。
where dlrcd = to_char(:Dlrcd) --可以使用上
and TO_CHAR(dlrcd) = :Dlrcd --使用不上
问题五、重复访问数据表
1、使用CASE表达式减少查表次数
通常,有需求在各种表上计算不同的汇总。我们可以通过在表上进行多次扫描(union)来实现此目标,但是通过一次扫描表(使用case when
)即可。消除n -1个扫描可以大大提高性能。
例子
select count(*) as cnt from t_student t where t.id > 10
union all
select count(*) as cnt from t_student t where t.id <= 10
可以改成
SELECT
count( CASE WHEN t.id > 10 THEN 1 ELSE NULL END ) AS cnt,
count( CASE WHEN t.id <= 10 THEN 1 ELSE NULL END ) as cnt1
FROM
t_student t
参考文献
https://docs.oracle.com/cd/E11882_01/server.112/e41573/toc.htm

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)