Mysql哈希索引
哈希索引原理哈希索引原理其实就是hash表,搜索时间效率O(1),搜索效率好,也意味着磁盘IO花费少,mysql底层使用的是链式哈希表,结构如下,每一个bucket就是一个个哈希桶,也就是哈希链表的头结点。哈希结构天然的需要耗费空间资源,是一种用空间换时间的做法哈希要点:解决哈希冲突的几种方式再哈希的参数碰撞因子或者说负载因子说白了就是用的拉链法去解决的哈希冲突,也正是这个结构造成了哈希索引的一些
哈希索引原理
哈希索引原理其实就是hash表,搜索时间效率O(1),搜索效率好,也意味着磁盘IO花费少,mysql底层使用的是链式哈希表,结构如下,每一个bucket就是一个个哈希桶,也就是哈希链表的头结点。哈希结构天然的需要耗费空间资源,是一种用空间换时间的做法
哈希要点:
- 解决哈希冲突的几种方式
- 再哈希的参数碰撞因子或者说负载因子
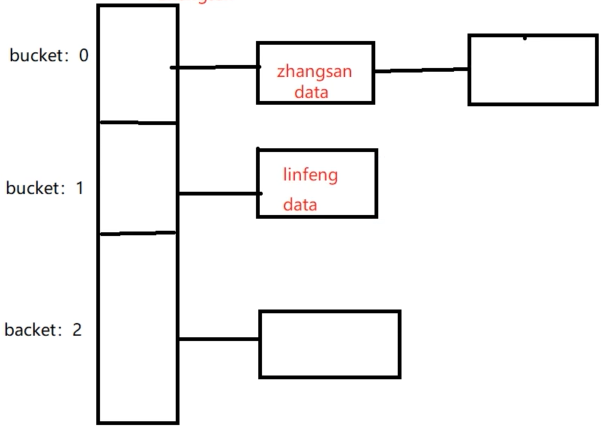
说白了就是用的拉链法去解决的哈希冲突,也正是这个结构造成了哈希索引的一些特性
- 哈希表没有顺序可言,只能进行等值查询,不支持范围搜索
- 哈希表不稳定,效率最差可能变为O(n),因为哈希冲突链表可能会变长
- 天然不能减少磁盘IO,要基于内存
- 会锁住桶,有可能造成阻塞
创建哈希索引sql语句如下
create index nameidx on student(name) using hash;
提示一下即使创建的是hash索引,也不一定就是哈希结构,Mysql会自动优化,具体用的是什么索引还是需要看看的,依然有可能使用的还是BTREE索引
show indexes from student;
自适应哈希索引
不讲人话部分
在MySQL 5.7中,自适应哈希索引搜索系统是分区的。每个索引被绑定到具体分区,每个分区由一个单独的锁闩保护。
分区由innodb_adaptive_hash_index_parts配置选项控制。在在早期版本中,自适应哈希索引搜索系统是由一个锁存器保护的在繁重的工作负载下可能会成为争论的焦点。的Innodb_adaptive_hash_index_parts选项默认设置为8。最大可设置为512。
哈希索引总是基于表上现有的b -树索引构建的。InnoDB可以构建一个为b -树定义的键的任意长度的前缀上的哈希索引,这取决于InnoDB对B-tree索引的搜索模式。一个散列索引可以是部分的,只覆盖那些经常被访问的索引页。对自适应哈希索引的使用和对其使用的争用SHOW ENGINE INNODB STATUS命令输出的信号量部分。如果你看到如果有很多线程在btr0sea.c中创建一个RW-latch,那么禁用它可能会很有用自适应哈希索引。
这段话很难理解,我也觉得mysql官方文档这段不讲人话,那接下来往下看
讲人话部分
自适应哈希索引其实是MySql自己创建的索引,前面关于聚簇索引跟非聚簇索引有说到,辅助索引在数据没有覆盖的情况下需要二次回表,也就是使用先使用辅助索引再使用主键索引
辅助索引不带有实际的数据,那么可不可以对辅助索引做一个优化呢,自适应哈希索引就是这么诞生的
Innodb存储引擎检测到某个二级索引不断被使用,那么他就会根据这个二级索引,在内存上根据二级索引B+树的结构创建一个哈希索引,用于加速搜索
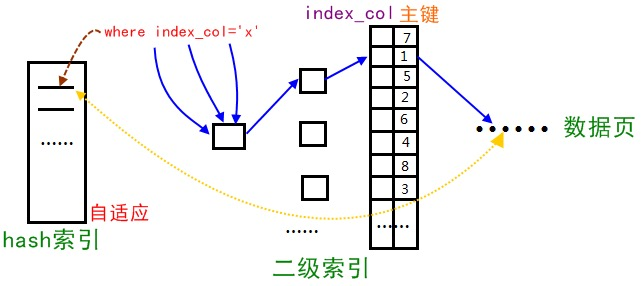
自适应哈希索引创建后,就会在等值查询的时候直接查询哈希索引,哈希索引上有数据的地址,这样就省下了辅助索引跟主键索引的搜索时间
其实创建哈希索引也是比较消耗资源的,这里有些衡量参数,要根据衡量参数决定是否打开或者关闭自适应哈希索引,mysql官方文档里面也讲了这个,上面不讲人话部分就是对何时创建自适应哈希索引以及如何禁用哈希索引、哈希索引锁的说明。
查看自适应哈希索引是否开启的命令
show variables like 'innodb_adaptive_hash_index';
查看自适应哈希分区(或者说桶)
show variables like 'innodb_adaptive_hash_index_parts';
两个比较重要的信息要注意,查看命令如下
show engine innodb status\G
- 能看到RW-latch等待的线程数量,自适应哈希索引默认分配了8个分区,同一个分区等待的线程数量过多
- 走自适应哈希索引搜索的频率和二级索引树搜索的频率
个人常用课程

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)