建立数据库模型:从业务模型、概念模型到逻辑模型
在上一集中,我们从业务场景出发,定义业务问题后,形成了具体的数据库赋能业务的框架。接下来的这一集,就是把此前的目标,转为数据需求。那如何把业务问题转为数据需求?那就是今天要讨论的数据建模。本文通过黄金思维圈(what-why-how)的逻辑来呈现。(为了与数据分析场景中建模的概念区分,本文的数据建模可以理解为 数据库建模。)数据建模是什么?数据建模是一个过程,是对业务现实各类数据进行抽象组织后,确
在上一集中,我们从业务场景出发,定义业务问题后,形成了具体的数据库赋能业务的框架。接下来的这一集,就是把此前的目标,转为数据需求。那如何把业务问题转为数据需求?那就是今天要讨论的数据建模。
本文通过黄金思维圈(what-why-how)的逻辑来呈现。
(为了与数据分析场景中建模的概念区分,本文的数据建模可以理解为 数据库建模。)
数据建模是什么?
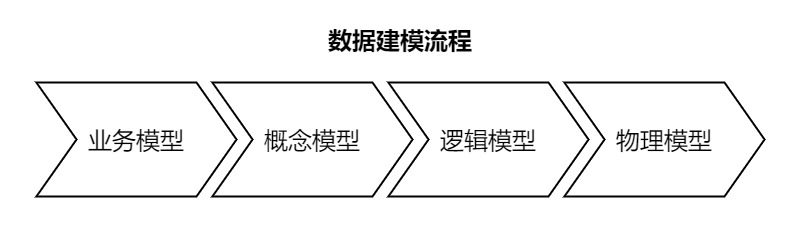
数据建模是一个过程,是对业务现实各类数据进行抽象组织后,确定数据库范围、数据组织形式及实现数据库开发的过程;这个过程中,需要对具体业务场景进行分析形成业务模型,基于此抽象出划分数据域的概念模型,基于此明确实体以及各实体之间关系,形成逻辑模型,最后形成用于建立数据库实体的物理模型。
简单来说,数据建模是把业务现实映射到数字逻辑的过程,是从具体到抽象,再到具体的过程。
为什么要建模?
数据建模其实是一个逻辑严谨的过程。为什么不能直接把做报表的数据源导入数据库就交差,而是要进行复杂的建模?
- 帮助梳理业务流程:数据中心是服务业务,其数据逻辑也应该反映业务现实,通过数据建模可以确保这种映射关系的有效性
- 建立全方位的数据视角,统一业务逻辑:之所以叫数据中心,就是因为服务的不止是一个部门,而是把多个业务单元的数据汇总,而背后是打通业务逻辑,所以需要建立全方位的数据视角来完成这件事,否则容易陷入到无尽的临时需求里。
- 减少建设过程中的“不确定”:在做决策过程中,经常会遇到这个数据要不要?要不要新建某个表?的问题 。数据建模的过程就是解决问题的框架,
- 确保最终落地的数据中心能支撑业务发展
如何建模?
- 建立业务模型
业务场景既是数据工作的起点,又是数据工作最终赋能的落地点。
所以数据建模的第一步就是要梳理业务流程,明确业务目标,进而抽象出公司整体的业务模型。
这一步的目的是为后面步骤提供明确的业务逻辑。 - 建立概念模型
将业务场景抽象成概念模型 - 建立逻辑模型
将概念落地,建立具体的表间逻辑关系 - 建立物理模型
按数据库语法建立物理模型,即可形成数据库
业务模型
业务模型是对业务层面的分解和程序化,为了达到这个目的需要先对业务流程进行梳理。
那要如何做?可以借助点线面的思考逻辑。链接:如何建立业务模型深入理解业务
- 公司层「面」:划分业务单元(可按业务部门划分),及梳理业务部门之间的协作关系。
- 业务「线」:深入了解部门内的具体业务流程,并将其程序化
- 节「点」:关注流程每个节点,数据点
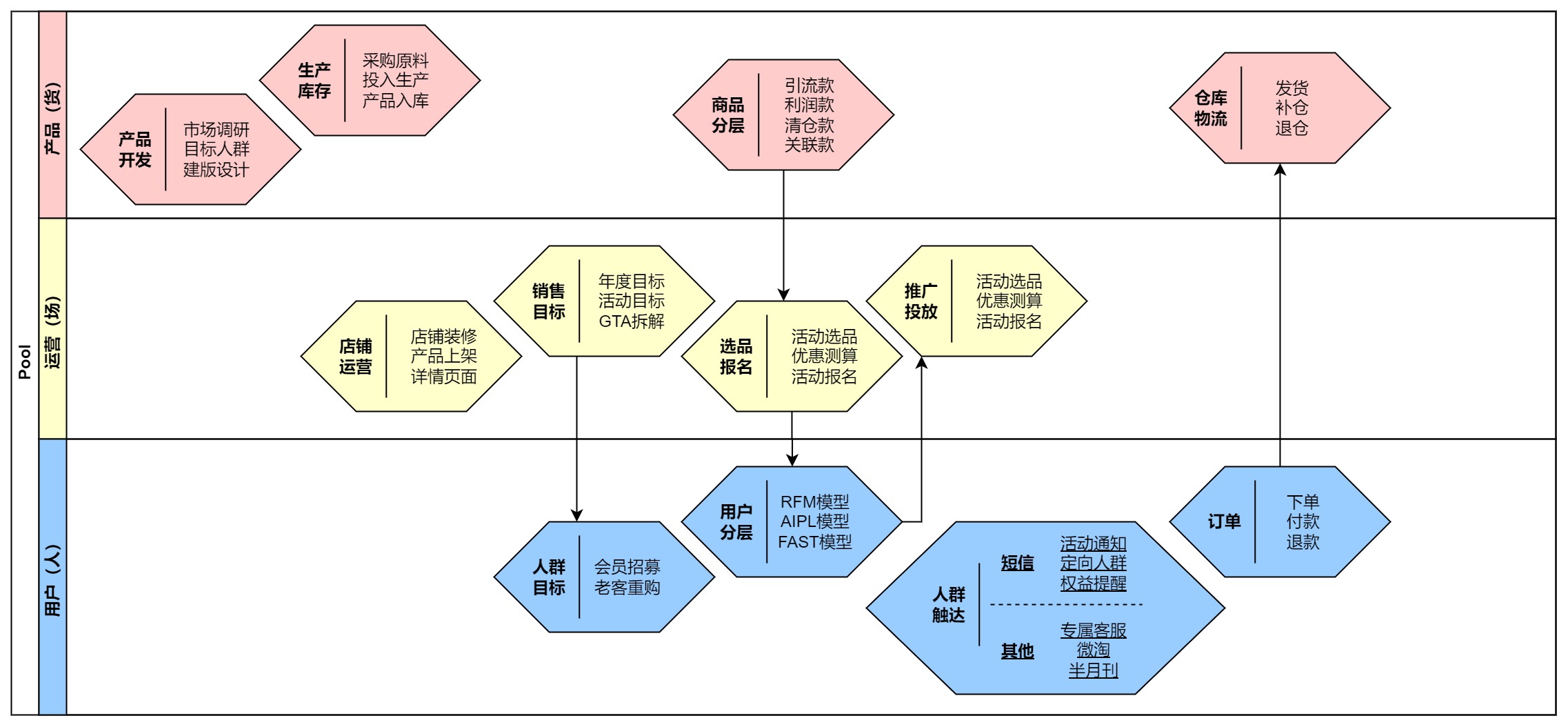
业务流程
此次案例中,虽然服务的对象是用户运营部门,产品部门,但是还是从公司层面的核心业务出发,才能窥探全局。所以借助零售行业的人货场模型,对业务流程进行梳理,产出下图。
明确目标:分析主题与指标定义
开篇:从零建立赋能业务的数据中心「逻辑框架」
从业务流程的梳理到业务模型的建立,是为了深入理解业务。回到建立数据库模型的场景中,在了解业务阶段,还需要进一步明确此次建模的目的:分析主题与指标定义。
用户分析
目标是通过建立「RFM模型」对人群进行分层,并形成不同人群的营销策略。
RFM建模逻辑:
- 数据清洗
- RFM阈值定义
- 用户RFM指标计算
- 打上RFM标签
- 分组统计
指标定义:
- 计算周期范围:近两年
- R:最近消费日期与当前距离(单位:日)
- F:累计消费频次
- M:累计消费金额
产品分析
明确需求是要对新品做「存销分析」,即综合库存和销售情况来判断新品表现,进而调整生产及库存计划。
分析逻辑:
- 看库存数量:后续分析占比、比值类型指标时,需要参考绝对值,比如计算周转时,库存基数太小,比值就没有意义
- 看商品周转率,即是指商品从入库到售出所经过的时间和效率。衡量商品周转水平的最主要指标是:周转次数和周转天数
- 实行简单策略:对于高周转产品,及时补货; 对于低周转产品,及时清仓。
指标定义:
- 统计周期:存销比一般以月为单位考核比较有意义。存销比可以以数量为单位,也可以以金额为单位。
- 新品定义:上架日期至今三个月以内
- 周转次数=销售额/平均库存额,平均库存=(期初库存+期末库存)/2
- 周转天数:库存周转一次所需的天数,周转天数=365/周转次数。
- 售罄率=期间销售数量/进货数量,金额计算亦可。单独看意义不大,要配合配货量
概念模型
在上一阶段,我们从业务场景中明确了分析主题,接下来就需要围绕着分析主题进行概念模型建模。
概念数据模型是数据库概念和实体之间的关系的有组织的视图。创建概念数据模型的目的是建立实体,实体的属性和关系。
为什么需要概念模型?
概念模型的一个重要作用的就是划分数据库范围,也就是回答数据库项目要做到什么程度的问题。
概念模型好比是中学学习物理时的极限思维,抓主要矛盾:光滑的平面、真空自由落体等,这些条件在现实是很难实现,但是可以帮助解决物理问题。同样,在数据库建模中,概念模型着重表达清楚实体和实体之间的关系,包括描述重要的属性,而选择忽略干扰判断的过多细节。
如何建立概念模型?
- 抽取关键业务概念,并将之抽象化。
- 将业务概念分组,按照业务主线聚合类似的分组概念。
- 理清分组概念之间的关联,形成完整的领域概念模型。
- 借用ER实体模型工具来表达实体间的关系
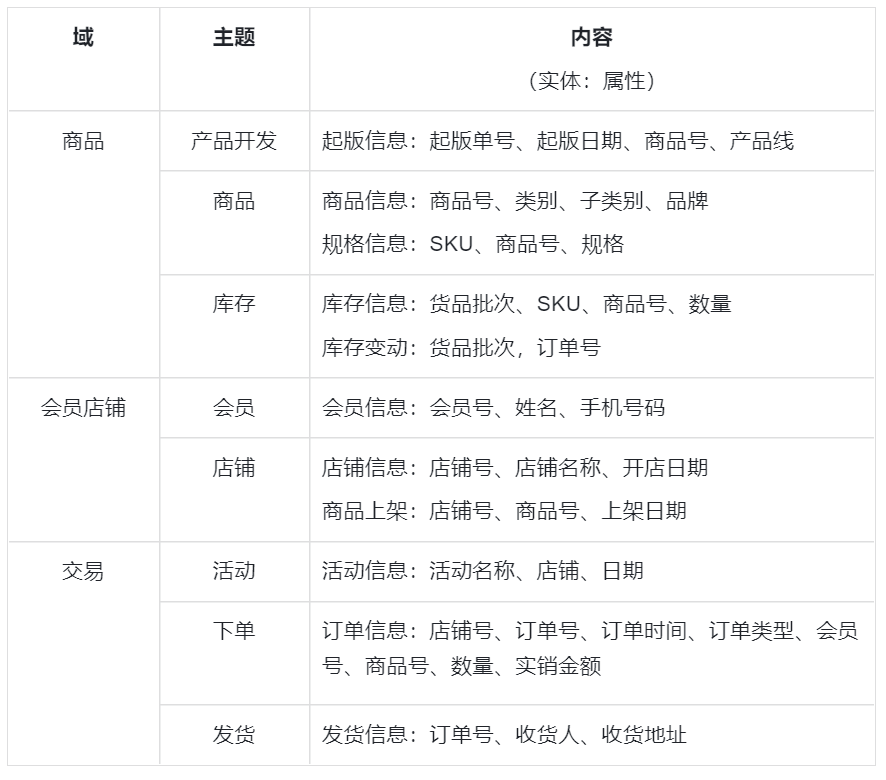
主题域/数据域
第三步中,对业务进行领域划分,形成主题域,或者说数据域。
划分方法主要有:按系统分、按业务部门分、按业务分析需求划分,这里,我们的目的是建立分析性数据库赋能业务,所以我们选择按业务分析需求来划分。
下表是基于业务场景划分的数据域:
ER实体模型
定义数据域后,则要进一步明确域内不同数据之间的关系(表间关系),为了更好地描述它们,可以借助ER实体模型工具,也就是步骤中的第四步。
什么是ER
数据系统中,将事物抽象为实体(Entity)、关系(Relationship)、属性来表示数据关联和事物的描述,这种对数据的抽象建模通常被称为ER实体关系模型

- 实体:参与到业务过程中的客观存在,比如会员、订单、商品
- 属性:对实体的描述,比如名称、尺寸
- 关系:实体与实体之间的联系,比如会员购买商品
- 实体与实体之间的对应关系:
- 一对一:比如人和身份证之间,每个人只有一张身份证,而一个身份证也只对应一个人;比如会员号和手机号码,(一般来说)每个会员只有一个手机号,而一个手机号只对应一个会员
- 一对多:比如学生和班级之间,每个学生只属于一个班级,但是一个班级有多个学生;比如商品号和SKU之间,每个SKU只有一个商品号,但是一个商品号有多个SKU
- 多对多:比如学生和课程之间,每个学生都可以选择多个课程,一个课程也有多个学生;比如会员和商品号之间,每个会员可以买多个商品号,一个商品号可以对应多个会员
逻辑模型
将领域模型的概念实体及实体之间的关系进行数据库层次的逻辑化。
前面基于业务流程,完成建立了业务模型。对业务行为产生的数据进行抽象,并基于不同主题进行划分后,形成概念模型。
至此,还只是停留在对业务的梳理阶段,在新建数据库实体之前,还需要进入到逻辑建模阶段:需要包含所有的逻辑表、字段、关系和约束;需要具体定义在概念模型中忽略的细节(比如子类关系、关联属性),也就是抽象到具体的过程。
那逻辑模型要如何实现?可以借助工具:维度建模。
维度建模
维度建模是专门用于分析型数据库、数据仓库、数据集市建模的方法。
什么是维度建模?
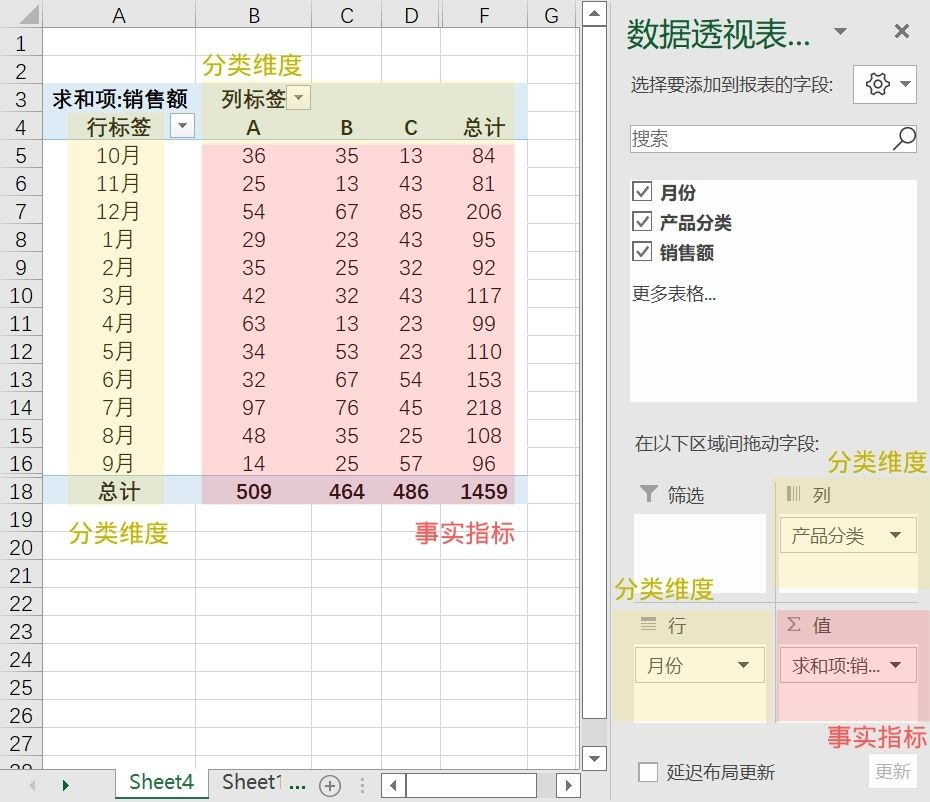
为了更好地理解,我们先回归到数据分析的底层逻辑:报表分析 = 分类维度 x 事实指标。
比如业务提数据需求说:要按月看不同品类的销售额。
在这个需求中,业务要看的事实指标是 销售额,其余描述该指标的“形容词”就是分类维度:按月(时间日期分类)、不同品类(商品品类分类)。
更直观地从Excel透视表来看,行、列标签就是需要透视的维度,表格中的值则是按公式计算的事实指标:
基于该分析逻辑,从应用分析层反推到数据库层面,就是维度建模:把表分为维度表与事实表。在具体使用时,只需要从维度表中选择需要透视(分析)的维度,再从事实表计算指标即可完成报表分析。
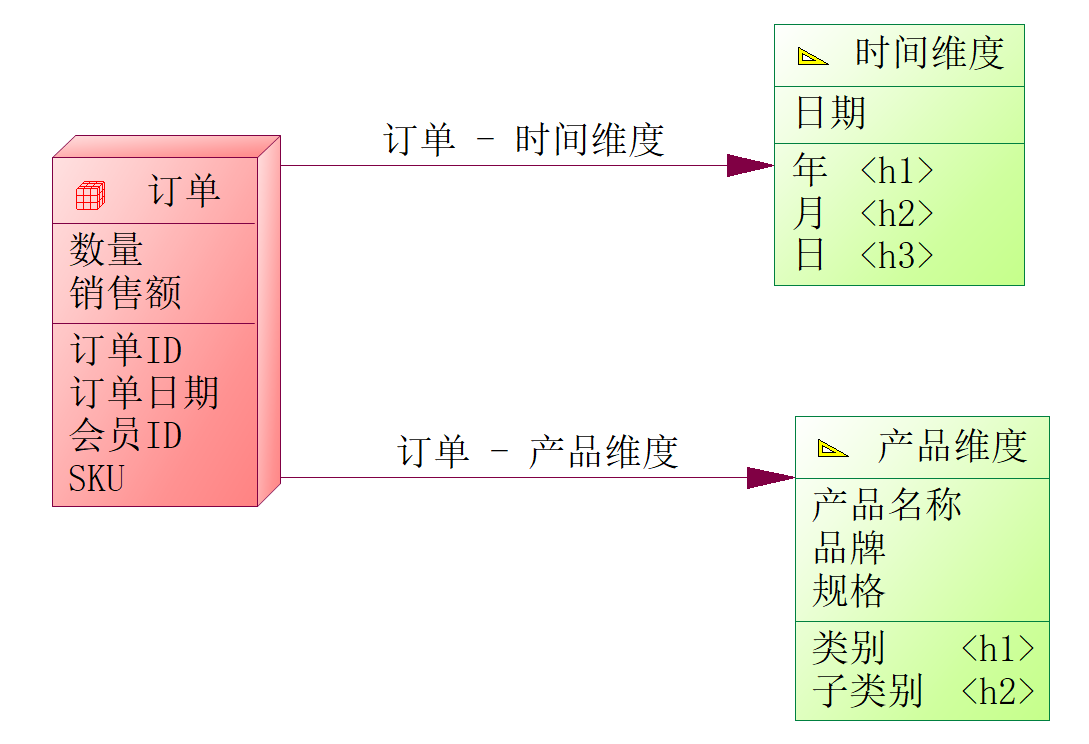
维度表
规范来说,什么是维度表?就是对分析主题所属类型的描述,比如销售流程(会员A在2022年1月1日付费200元购买了1件产品B)就是以销售为主题进行分析,可以从中提取的维度:时间维度(2022年1月1日)、商品维度(产品B),也就是在excel表中需要透视的维度有时间、品类。
事实表
什么是事实表?就是对分析主题的度量,上述销售流程的例子中,200元、1件就是事实信息。在业务活动中,每个流程都会产生一个事实表,涉及多个实体,而上述例子涉及的实体就是会员、产品。
维度建模的分类
维度模型主要分为星型模型、雪花模型。
很多情况下,我们来学习数据库理论的过程中,经常看到设计范式的概念,在确定维度模型前,我们先来看看什么是数据库的设计范式。
数据库设计范式
专业的定义:数据库的设计范式是数据库设计所需要满足的规范,数据库的规范化是优化表的结构和优化把数据组织到表中的方式,这样使数据更明确,更简洁。
简单的说,范式是为了消除重复数据减少冗余数据,从而让数据库内的数据更好的组织。对数据分析师来说,我们只需要关注范式的前三个层级:
第一范式1NF
简单的说,第一范式就是每一个属性都不可再分,不符合第一范式则不能称为关系数据库。
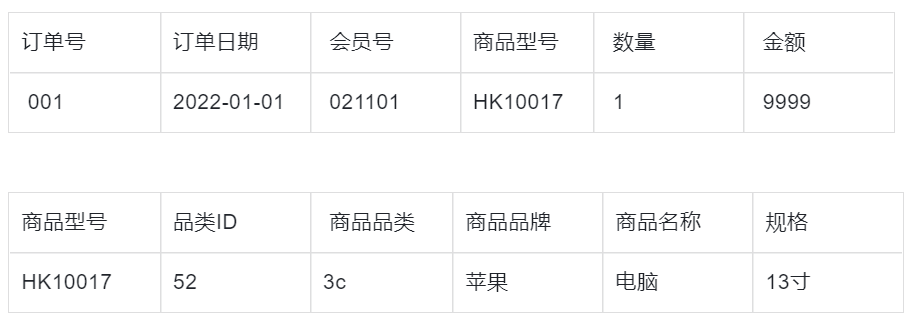
比如不符合1NF的表:我们看到商品字段下把多个属性放在了一起,因此不符合第一范式。

我们把它修改成符合1NF:把商品里的数据拆开成品类、品牌、名称、型号、规格。这样每个属性都不能再拆,因此符合1NF。

第二范式2NF
更深一层,到2NF就需要考虑主键,简单来说就是考虑分表的问题。1NF案例中的表是大宽表,把所有信息都放在了一起,这种表在实际业务中Excel里非常常见,有利于直接透视分析,但是问题也同样明显:就是对于数据量稍大的表格就跑不动了,到数据库里是同样的道理,我们需要对它按下图进行拆表,也就符合2NF了。
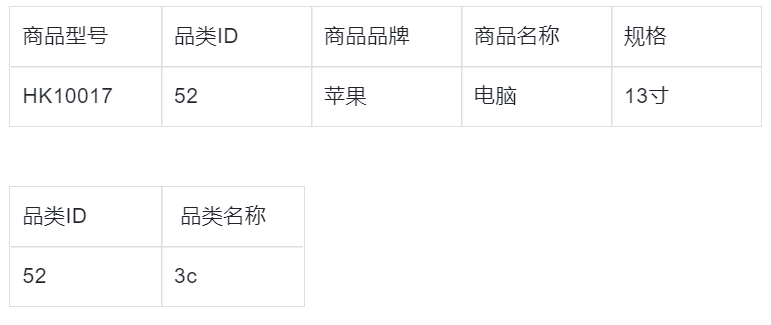
第三范式3NF
到这一层级,专业地说就是要消除数据库中关键字之间的依赖关系。通俗地讲,就是对2NF进一步拆表。2NF案例中的商品表中,我们发现品类ID和商品表混在了一起,需要拆成下图的样子,就是3NF。当然,如果要更严格一些,就需要把品牌单独出来做一个品牌表(字段:品牌ID,品牌名称)。
星型模型与雪花模型
简单了解完设计范式后,就可以来选择维度模型。

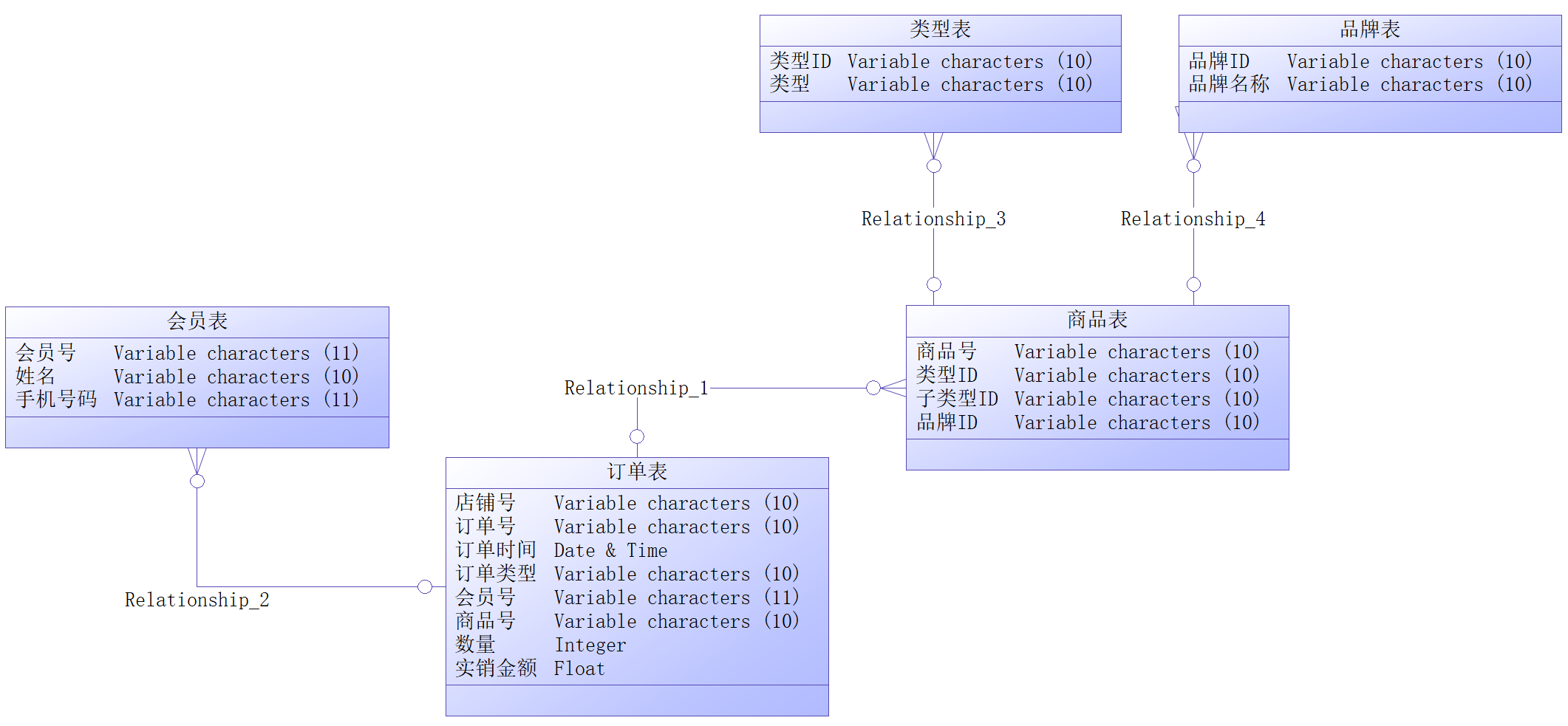
星型模型与雪花模型是最常见的维度模型,它们之间的区别在于雪花模型是符合3NF,而星型模型不符合3NF,数据是冗余的,但也正是因为星型模型数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。
从实现来说,星型结构不用考虑很多正规化的因素,设计与实现都比较简单,所以实际运用中星型模型使用更多,也更有效率。所以我们接下来也会使用星型模型作为逻辑模型的呈现。
物理模型
物理模型是最终用来建立数据库实际对象的,主要解决逻辑模型针对不同关系型数据库的物理化以及性能等一些具体的技术问题。在进入敲代码阶段,将逻辑模型转为SQL SERVER的数据库实体之前,可以借助物理模型帮助实现落地。
由于篇幅关系,物理模型的落地将在下一节内容中呈现,敬请期待!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)