RDD 和 DataFrame 的区别是什么?
前言本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系正文结构的区别RDD 和 DataFrame 均为 Spark 平台对数据的一种抽象,一种组织方式,但是两者的地位或者说设计目的却截然不同。RDD 是整个 Spark 平台的存储、计算以及任务调度的逻辑基础,更
前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
正文
结构的区别
RDD 和 DataFrame 均为 Spark 平台对数据的一种抽象,一种组织方式,但是两者的地位或者说设计目的却截然不同。
RDD 是整个 Spark 平台的存储、计算以及任务调度的逻辑基础,更具有通用性,适用于各类数据源,
而 DataFrame 是只针对结构化数据源的高层数据抽象,其中在 DataFrame 对象的创建过程中必须指定数据集的结构信息( Schema ),
所以 DataFrame 生来便是具有专用性的数据抽象,只能读取具有鲜明结构的数据集
下图直观地体现了 DataFrame 和 RDD 的区别。
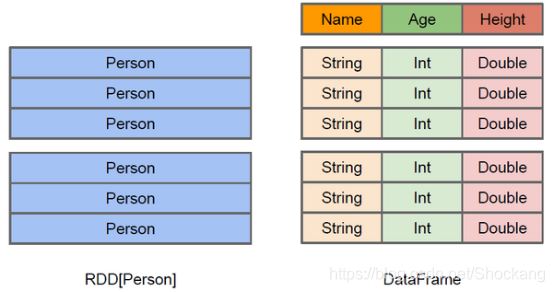
左侧的 RDD[Person] 虽然以 Person 类为类型参数,但 Spark 平台本身并不了解 Person 类的内部结构。
而右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame 多了数据的结构信息,即 schema 。
RDD 是分布式的 Java 对象的集合, DataFrame 则是分布式的 Row 对象的集合。
DataFrame 除了提供了比 RDD 更丰富的算子操作以外,更重要的特点是利用已知的结构信息来提升执行效率、减少数据读取以及执行计划的优化,比如 filter 下推、裁剪等。
正是由于 RDD 并不像 DataFrame 提供详尽的结构信息,所以 RDD 提供的 API 功能上并没有像 DataFrame 强大丰富且自带优化,所以又称为 Low - levelAPI ,相比之下, DataFrame 被称为 high - level 的抽象,其提供的 API 类似于 SQL 这种特定领域的语言( DSL )来操作数据集。
使用场景的区别
RDD 是 Spark 的数据核心抽象, DataFrame 是 Spark 四大高级模块之一 Spark SQL 所处理数据的核心抽象,
所谓的数据抽象,就是当为了解决某一类数据分析问题时,根据问题所涉及的数据结构特点以及分析需求在逻辑上总结出的典型、普适该领域数据的一种抽象,一种泛型,一种可表示该领域待处理数据集的模型。
而 RDD 是作为 Spark 平台一种基本、通用的数据抽象,基于其不关注元素内容及结构的特点,我们对结构化数据、半结构化数据、非结构化数据一视同仁,都可转化为由同一类型元素组成的 RDD 。
但是作为一种通用、普适的工具,其必然无法高效、便捷地处理一些专门领域具有特定结构特点的数据,因此,这就是为什么, Spark 在推出基础、通用的 RDD 编程后,
还要在此基础上提供四大高级模块来针对特定领域、特定处理需求以及特定结构数据,
比如 SparkStreaming 负责处理流数据,进行实时计算(实时计算),
而 Spark SQL 负责处理结构化数据源,更倾向于大规模数据分析,
而 MLlib 可用于在 Spark 上进行机器学习。
因此,若需处理的数据是上述的典型结构化数据源或可通过简易处理可形成鲜明结构的数据源,且其业务需求可通过典型的 SQL 语句来实现分析逻辑,我们可以直接引入 Spark SQL 模块进行编程。
使用 RDD 的一般场景
- 你需要使用 low - level 的转化操作和行动操作来控制你的数据集;
- 你得数据集非结构化,比如,流媒体或者文本流;
- 你想使用函数式编程来操作你得数据,而不是用特定领域语言( DSL )表达;
- 你不在乎 schema ,比如,当通过名字或者列处理(或访问)数据属性不在意列式存储格式;
- 你放弃使用 DataFrame 和 DataSet 来优化结构化和半结构化数据集。
DataFrame 和 RDD 的优缺点
RDD
优点
- 编译时类型安全 - 开发会进行类型检查,在编译的时候及时发现错误
- 具有面向对象编程的风格
缺点
-
构建大量的java对象占用了大量heap堆空间,导致频繁的GC
由于数据集RDD它的数据量比较大,后期都需要存储在heap堆中,这里有heap堆中的内存空间有限,出现频繁的垃圾回收(GC),程序在进行垃圾回收的过程中,所有的任务都是暂停。影响程序执行的效率 -
数据的序列化和反序列性能开销很大
在分布式程序中,对象(对象的内容和结构)是先进行序列化,发送到其他服务器,进行大量的网络传输,然后接受到这些序列化的数据之后,再进行反序列化来恢复该对象
DataFrame
DataFrame引入了schema元信息和off-heap(堆外)
优点
- DataFrame引入off-heap,大量的对象构建直接使用操作系统层面上的内存,不在使用heap堆中的内存,这样一来heap堆中的内存空间就比较充足,不会导致频繁GC,程序的运行效率比较高,它是解决了RDD构建大量的java对象占用了大量heap堆空间,导致频繁的GC这个缺点。
- DataFrame引入了schema元信息—就是数据结构的描述信息,后期spark程序中的大量对象在进行网络传输的时候,只需要把数据的内容本身进行序列化就可以,数据结构信息可以省略掉。这样一来数据网络传输的数据量是有所减少,数据的序列化和反序列性能开销就不是很大了。它是解决了RDD数据的序列化和反序列性能开销很大这个缺点
缺点
DataFrame引入了schema元信息和off-heap(堆外)它是分别解决了RDD的缺点,同时它也丢失了RDD的优点
- 编译时类型不安全 - 编译时不会进行类型的检查,这里也就意味着前期是无法在编译的时候发现错误,只有在运行的时候才会发现
- 不在具有面向对象编程的风格

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 19
19 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)