MySQL使用count(*) 很慢
count(*)慢
1、继上一次 一次mysql联表 join 后 order by desc 慢的排查 的问题,测试又测出一个问题。count(*) 很慢
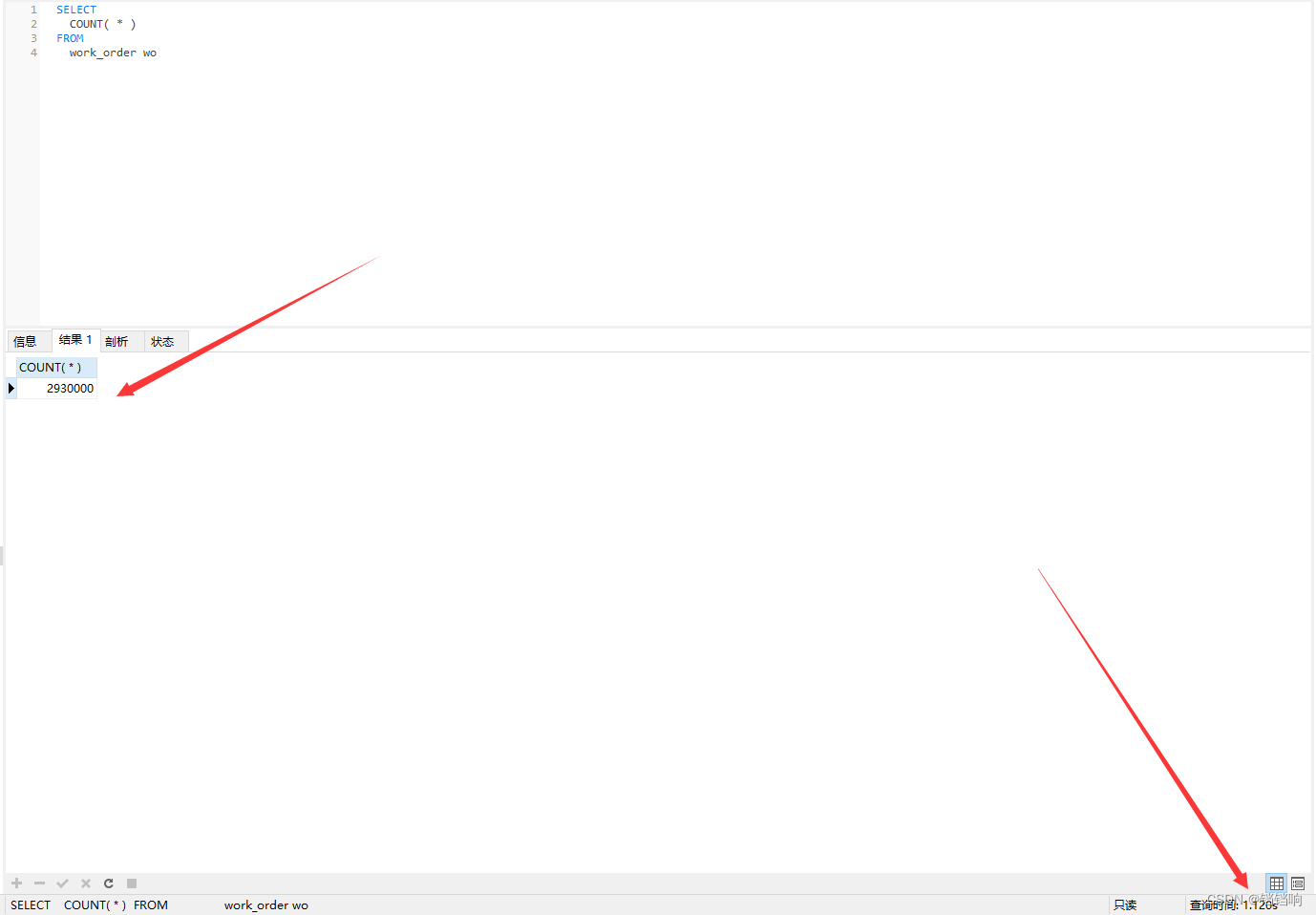
2、处理方案网上有很多,但是都不是太理想,很多都是接近1秒左右,个人认为说的比较好的是这篇 故障分析 | MySQL 优化案例 - select count(*) ,这篇文章已经说了解决方案了,其实我上面的1.12秒 就是已经走了二级索引了。
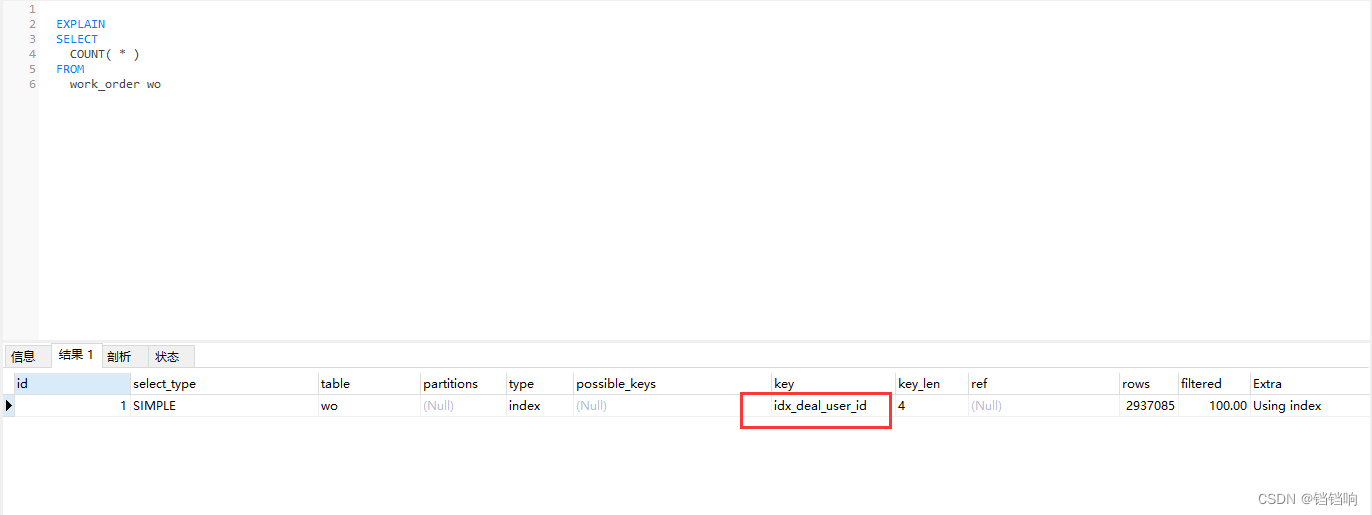

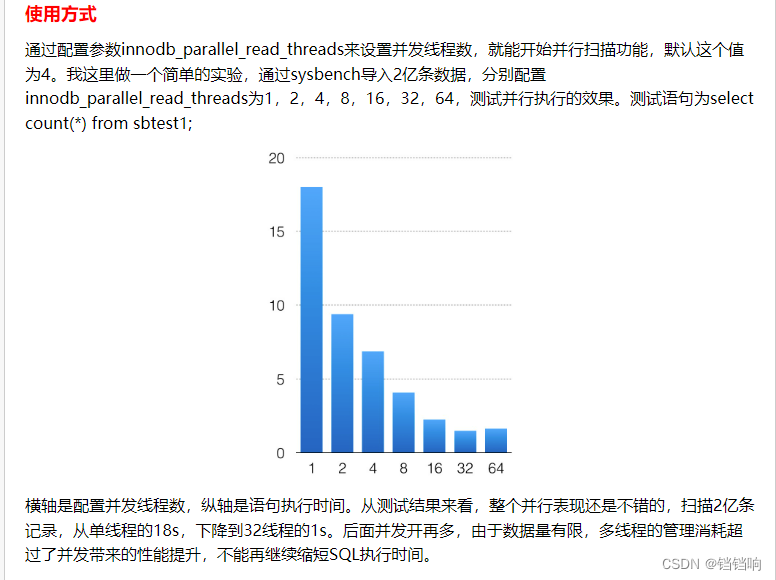
3、但是效果还是1秒多,至于后面提到的MySQL8开启并行,我这边也测试了,但是效果还是很不理想,可以参考这篇文章 MySQL8.0 InnoDB并行执行,可能是我的数据太少了,他测试的都是以亿级别的,我才300万。
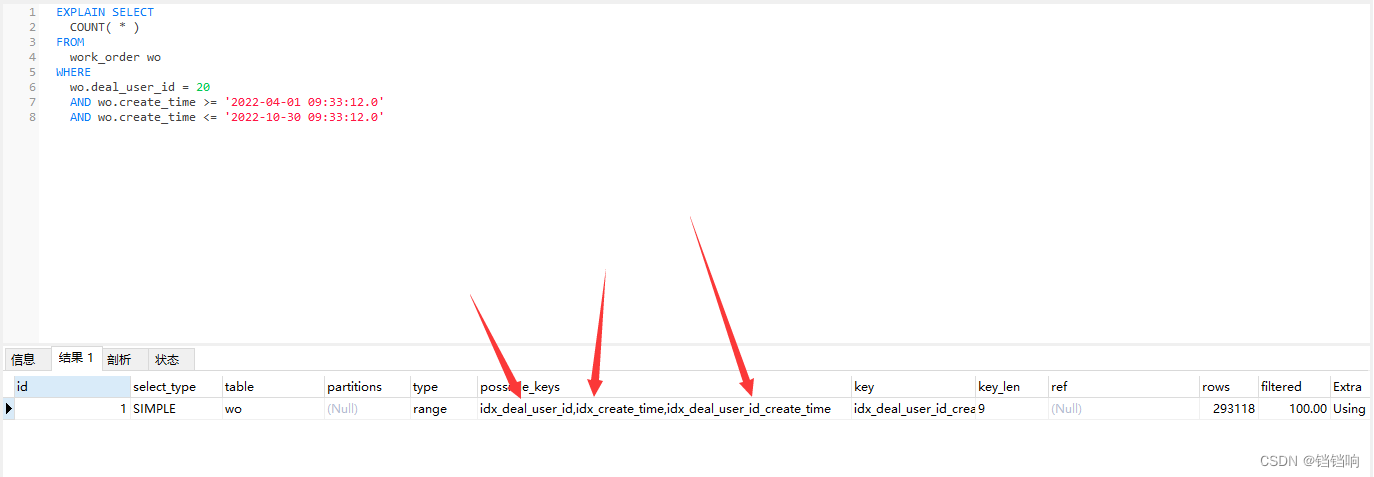
4、这里我又测试其他带有查询条件的情况,比如下述例子,需要耗时1.5秒。
SELECT
COUNT( * )
FROM
work_order wo
WHERE
wo.deal_user_id = 20
AND wo.create_time >= '2022-04-01 09:33:12.0'
AND wo.create_time <= '2022-10-30 09:33:12.0'
5、使用explain后发现,他使用的是分开的两个单独的索引

6、于是我加上联合索引(注意顺序,不然会失效),发现走了联合索引后,在执行查询,只花费0.046秒。

7、虽然这种联合索引的方式,可行,但是如果我们的条件的很多,组合很多,就不太好处理了,你总不能为每一种情况都加上索引吧,有一种方案就是固定几种组合索引的方式,然后前端没有对应条件时,通过后端优化sql,使其走到先有的索引上。,对于这种方案,我这里举个例子,比如说我前端页面上有三个查询选项。
| 前端页面查询输入框 | 对应后端字段 |
|---|---|
| 处理人 | deal_user_id |
| 时间范围 | create_time |
| 服务类型 | service_type (值只有0,1两种情况) |
那么我就可以建立一个联合的索引,和两个单独的索引,如下
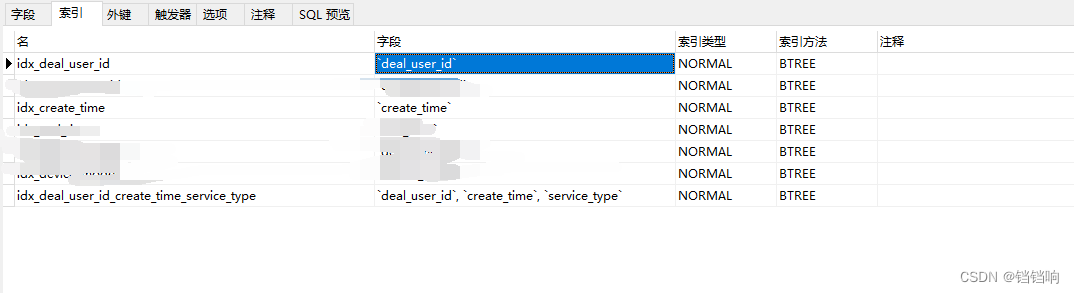
那么前端如果在单独查询deal_user_id和create_time时,都没有问题,会走各自的单独的索引,如果前端输入了两个框,没有输入服务类型,那么我们通过sql的优化拼接来使其走到对应的组合索引中,如下:
SELECT
COUNT( * )
FROM
work_order wo
WHERE
wo.deal_user_id = 20
AND wo.create_time >= '2022-04-01 09:33:12.0'
AND wo.create_time <= '2022-10-30 09:33:12.0' and wo.service_type in (0,1)
或者
SELECT
COUNT( * )
FROM
work_order wo
WHERE
wo.deal_user_id = 20
AND wo.create_time >= '2022-04-01 09:33:12.0'
AND wo.create_time <= '2022-10-30 09:33:12.0' and (wo.service_type = 0 or wo.service_type = 1)
这两种方式都是可以保证能走到我们的组合索引上面的,也不用每种情况都建立一个组合索引,当然可能大家的实际业务不能那么简单,大家可以参考这种方式,减少一部分的索引创建。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)