常见索引类型
日常开发工作中,涉及到的数据存储,要做查询优化或想深入了解存储引擎,需要对索引知识有个起码的了解,下面介绍下最常见的四种索引结构。位图索引哈希索引BTREE索引倒排索引1、位图索引(BitMap)位图索引适用于字段值为可枚举的有限个数值的情况位图索引使用二进制的数字串(bitMap)标识数据是否存在,1标识当前位置(序号)存在数据,0则表示当前位置没有数据。图1 为用户表,存储了性别和婚姻状况两
日常开发工作中,涉及到的数据存储,要做查询优化或想深入了解存储引擎,需要对索引知识有个起码的了解,下面介绍下最常见的四种索引结构。
- 位图索引
- 哈希索引
- BTREE索引
- 倒排索引
1、位图索引(BitMap)
位图索引适用于字段值为可枚举的有限个数值的情况
位图索引使用二进制的数字串(bitMap)标识数据是否存在,1标识当前位置(序号)存在数据,0则表示当前位置没有数据。
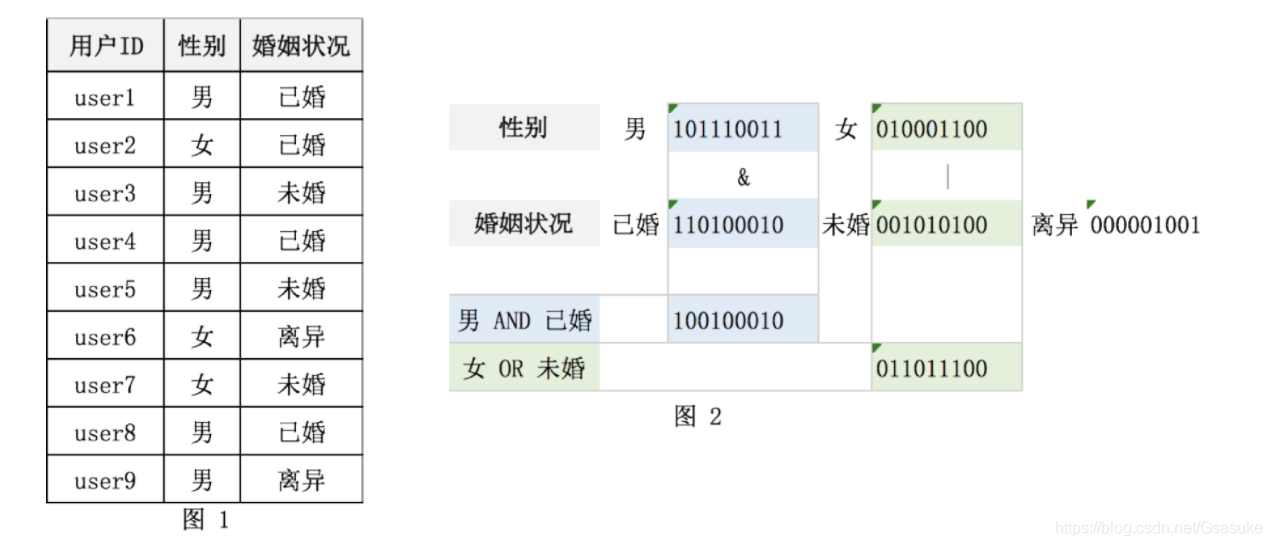
图1 为用户表,存储了性别和婚姻状况两个字段。
图2中 分别为性别和婚姻状态建立了两个位图索引;
例如:性别->男对应索引为:101110011,表示第1、3、4、5、8、9个用户为男性。其他属性以此类推。
使用位图索引查询:
男性 并且已婚 的记录 = 101110011 & 11010010 = 100100010,即第1、4、8个用户为已婚男性。
女性 或者未婚的记录 = 010001100 | 001010100 = 011011100, 即第2、3、5、6、7个用户为女性或者未婚。
注:位图索引查询主要进行“与/或”操作,性能非常高;并且空间占用少;一个常见的场景就是用着统计标签化用户上,对用户进行分类;Redis提供了方便的位图操作命令,使用很方便;但位图“位资源”的回收不方便,且稀松的位图会浪费空间,位图进行非运算较困难
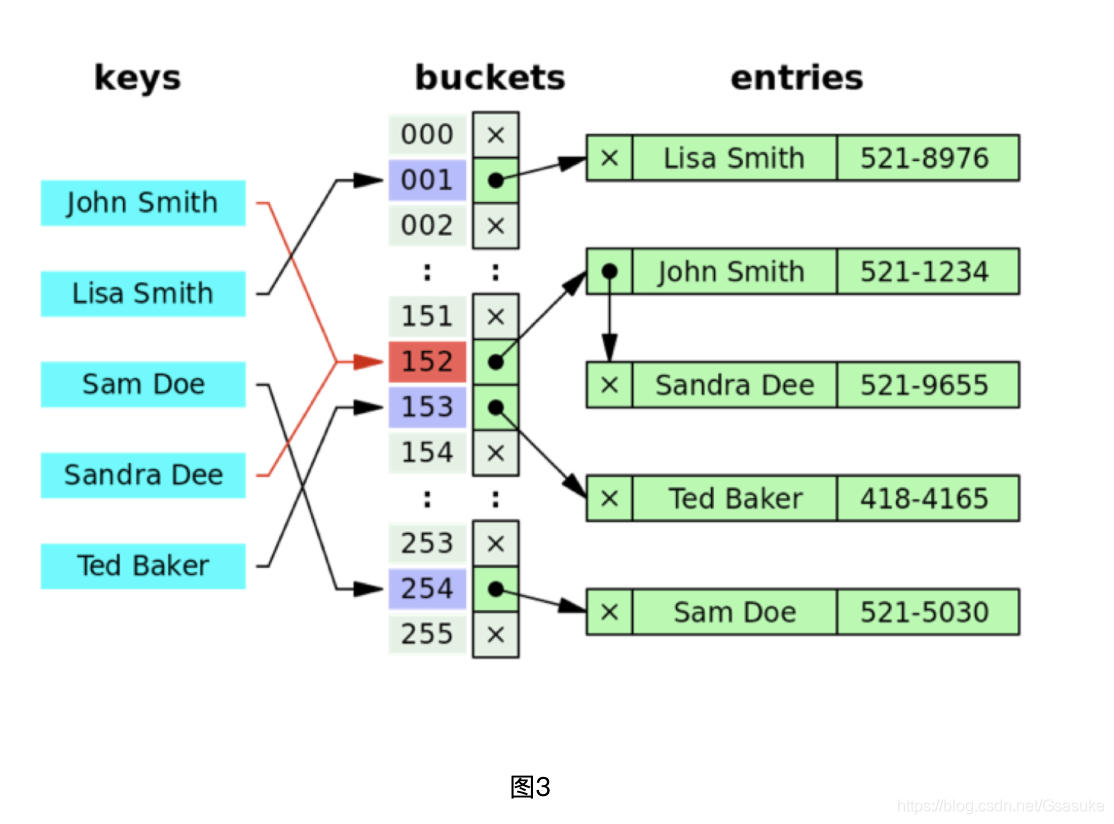
2、哈希索引
顾名思义,是指使用某种哈希函数实现key->value 映射的索引结构。
哈希索引适用于等值检索,通过一次哈希计算即可定位数据的位置。
下图3 展示了哈希索引的结构,与JAVA中HashMap的实现类似,是用冲突表的方式解决哈希冲突的。
3、BTREE索引
BTREE索引是关系型数据库最常用的索引结构,方便了数据的查询操作。
BTREE: 有序平衡N叉树, 每个节点有N个键值和N+1个指针, 指向N+1个子节点
一棵BTREE的简单结构如下图4所示,为一棵2层的3叉树,有7条数据:

以Mysql最常用的InnoDB引擎为例,描述下BTREE索引的应用。
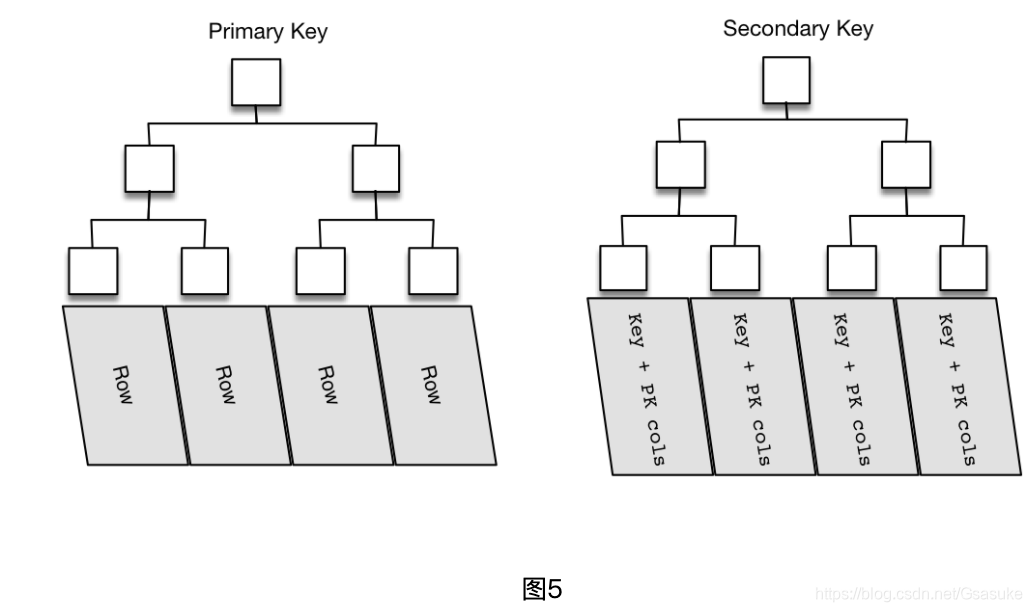
Innodb下的表都是以索引组织表形式存储的,也就是整个数据表的存储都是B+tree结构的,如图5所示。
主键索引为图5的左半部分(如果没有显式定义自主主键,就用不为空的唯一索引来做聚簇索引,如果也没有唯一索引,则innodb内部会自动生成6字节的隐藏主键来做聚簇索引),叶子节点存储了完整的数据行信息(以主键 + row_data形式存储)。
二级索引也是以B+tree的形式进行存储,图5右半部分,与主键不同的是二级索引的叶子节点存储的不是行数据,而是索引键值和对应的主键值,由此可以推断出,二级索引查询多了一步查找数据主键的过程。
维护一颗有序平衡N叉树,比较复杂的就是当插入节点时节点位置的调整,尤其是插入的节点是随机无序的情况;而插入有序的节点,节点的调整只发生了整个树的局部,影响范围较小,效率较高。
可以参考红黑树的节点的插入算法:https://en.wikipedia.org/wiki/Red%E2%80%93black_tree
因此如果innodb表有自增主键,则数据写入是有序写入的,效率会很高;如果innodb表没有自增的主键,插入随机的主键值,将导致B+tree的大量的变动操作,效率较低。这也是为什么会建议innodb表要有无业务意义的自增主键,可以大大提高数据插入效率。
Mysql Innodb使用自增主键的插入效率高。
使用类似Snowflake的ID生成算法,生成的ID是趋势递增的,插入效率也比较高。
4、倒排索引(反向索引)
倒排索引也叫反向索引,可以相对于正向索引进行比较理解。
正向索引反映了一篇文档与文档中关键词之间的对应关系;给定文档标识,可以获取当前文档的关键词、词频以及该词在文档中出现的位置信息,如图6 所示,左侧是文档,右侧是索引。

反向索引则是指某关键词和该词所在的文档之间的对应关系;给定了关键词标识,可以获取关键词所在的所有文档列表,同时包含词频、位置等信息,如图7所示。

反向索引(倒排索引)的单词的集合和文档的集合就组成了如图8所示的”单词-文档矩阵“,打钩的单元格表示存在该单词和文档的映射关系。

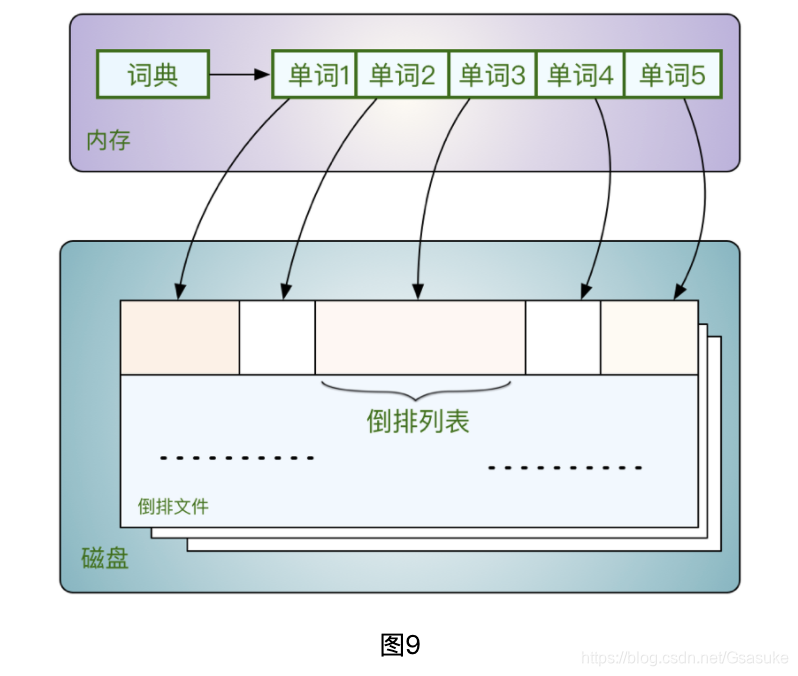
倒排索引的存储结构可以参考图9。其中词典是存放的内存里的,词典就是整个文档集合中解析出的所有单词的列表集合;每个单词又指向了其对应的倒排列表,倒排列表的集合组成了倒排文件,倒排文件存放在磁盘上,其中的倒排列表内记录了对应单词在文档中信息,即前面提到的词频、位置等信息。
下面以一个具体的例子来描述下,如何从一个文档集合中生成倒排索引。
如图10,共存在5个文档,第一列为文档编号,第二列为文档的文本内容。
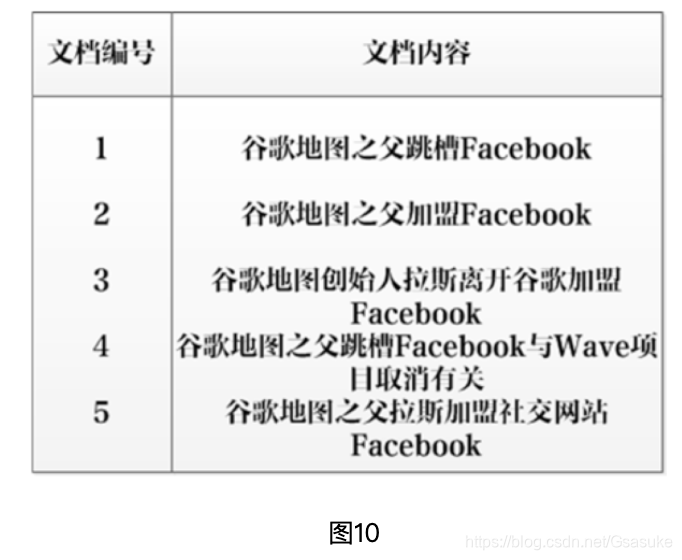
将上述文档集合进行分词解析,其中发现的10个单词为:[谷歌,地图,之父,跳槽,Facebook,加盟,创始人,拉斯,离开,与],以第一个单词”谷歌“为例:首先为其赋予一个唯一标识 ”单词ID“, 值为1,统计出文档频率为5,即5个文档都有出现,除了在第3个文档中出现2次外,其余文档都出现一次,于是就有了图11所示的倒排索引。


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)