Mysql中的索引
1 索引概述MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。索引的本质:索引是数据结构。可以简单理解为“排好序的快速查找数据结构”,满足特定查找算法。这些数据结构以某种方式指向数据, 这样就可以在这些数据结构的基础上实现 高级查找算法 。2.优点(1)类似大学图书馆建书目索引,提高数据检索的效率,降低 数据库的IO成本 ,这也是创建索引最主 要的原因。(2)
目录
1 索引概述
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的本质:索引是数据结构。
可以简单理解为“排好序的快速查找数据结构”,满足特定查找算法。
这些数据结构以某种方式指向数据, 这样就可以在这些数据结构的基础上实现 高级查找算法 。
2.优点
(1)类似大学图书馆建书目索引,提高数据检索的效率,降低 数据库的IO成本 ,这也是创建索引最主 要的原因。
(2)通过创建唯一索引,可以保证数据库表中每一行 数据的唯一性 。
(3)在实现数据的 参考完整性方面,可以 加速表和表之间的连接 。换句话说,对于有依赖关系的子表和父表联合查询时, 可以提高查询速度。
(4)在使用分组和排序子句进行数据查询时,可以显著 减少查询中分组和排序的时 间 ,降低了CPU的消耗。
3 缺点
增加索引也有许多不利的方面,主要表现在如下几个方面:
(1)创建索引和维护索引要 耗费时间 ,并 且随着数据量的增加,所耗费的时间也会增加。 (2)索引需要占 磁盘空间 ,除了数据表占数据空间之 外,每一个索引还要占一定的物理空间, 存储在磁盘上 ,如果有大量的索引,索引文件就可能比数据文 件更快达到最大文件尺寸。
(3)虽然索引大大提高了查询速度,同时却会 降低更新表的速度 。当对表 中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。 因此,选择使用索引时,需要综合考虑索引的优点和缺点。
Mysql中索引的B+树
单个页所表示的结构
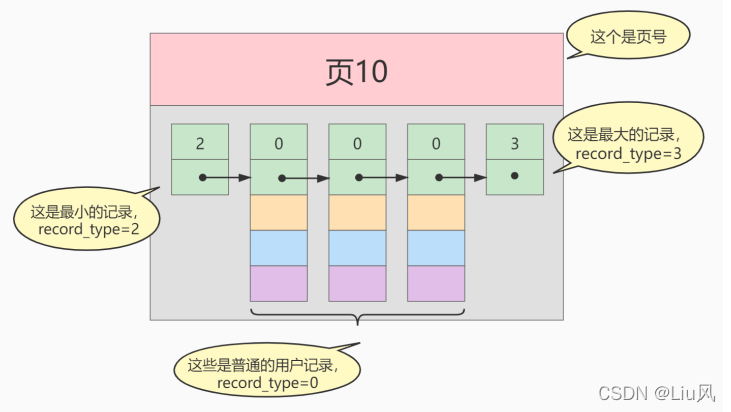
B+树结构
目录页和叶子结点 都使用双向链表的形式 将相邻的两个页联系起来
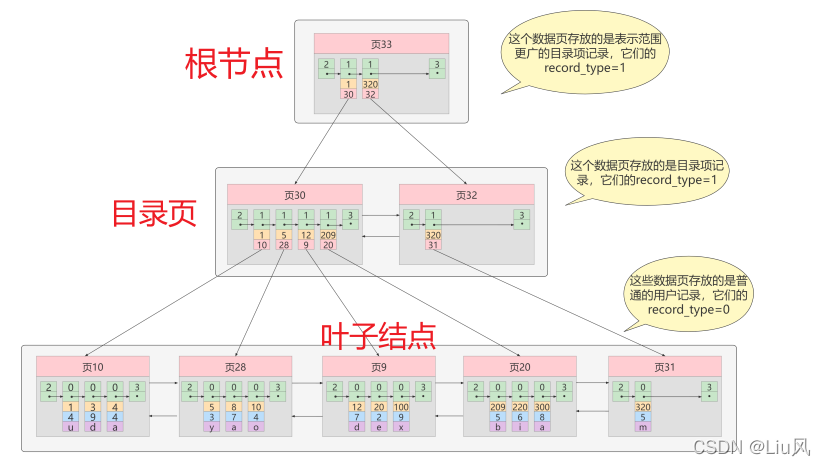
InnoDB的B+树索引的注意事项
1. 根页面位置万年不动
2. 非叶子节点中目录项记录的唯一性
3. 一个页面最少存储2条记录
B树
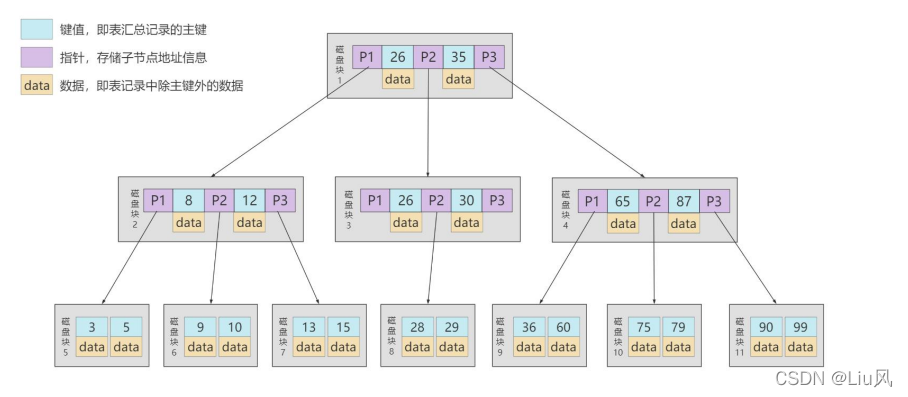
B+ 树和 B 树的差异
1. 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1。
2. 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最 小)。
3. 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中, 非 叶子节点既保存索引,也保存数据记录 。
4. 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大 小从小到大顺序链接。
B+树的优点
1.B+树中间节点并不存储数据
2.B+树查询效率更稳定
3.B+树查询效率更高
4.在查询范围,B+树的效率也比B树高
思考题
B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO
InnoDB 存储引擎中页的大小为16KB,一般表的主键类型为INT (占用4个字节)或BIGINT (占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储
16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为10^3。也就是说一个深度为3的B+Tree索引可以维护10^3*10^3*10^3=10亿条记录。(这里假定一个数据页也存储10^3条行记录数据了)
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree 的高度一般都在2~4层。MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1-3次磁盘I/O操作
思考题:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
1、B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2.B+树的查询效率更加稳定由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)