数仓常用工具和方法
数仓常用工具和方法
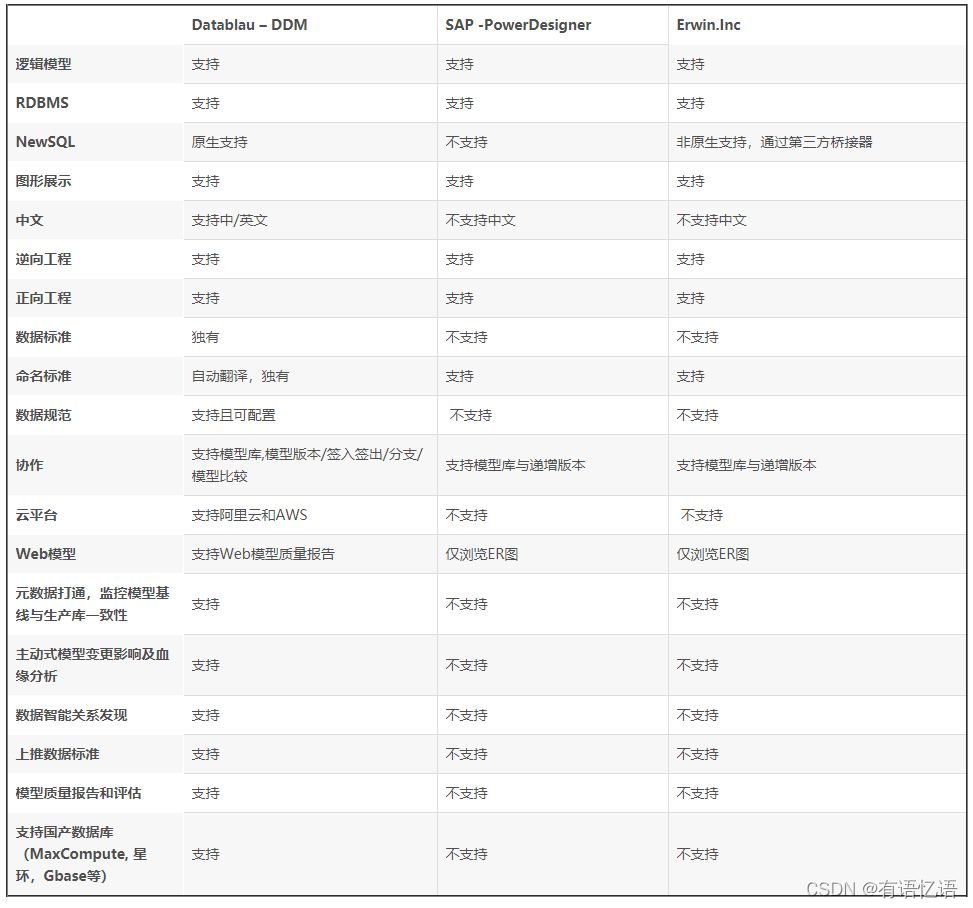
1、数仓建模工具有哪些?
erwin、PowerDesigner、Datablau-DDM
2、数仓建模的好处?
1、性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐;
2、成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果符用,极大地降低大数据系统中的存储和计算成本
3、效率:良好的数据模型能极大地改善用户使用数据的体验,提高数据使用效率
4、质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性。
其实总体来说,数仓建模也是随着互联网的发展,逐渐演变的,贴合业务需求。业务的复杂度、多样性;数据的复杂度、多样性、数据量大。演变数据仓库,到数据建模,更好的将数据整理起来,分类归纳与更好的应用。
3、建模有哪些方式?
数据仓库建模在数据仓库建设中有很重要的地位,是继业务梳理后的第二大要点,是将概念模型转化为物理模型的一个过程。关于建模一向被吹得神乎其神,相关介绍文章以及招聘需求中对此都要求很高,那么了解主流的建模方法和各自的优劣势以及应用场景就变得至关重要了。
选择合适的建模方法要考虑几点要素,分别是:性能、成本、效率和质量,性能是能够快速的查询所需的数据,减少数据IO的吞吐;成本是减少不必要的冗余,实现计算结果的复用,减少大数据系统的计算成本和存储成本;效率则是改善使用数据的效率,计算、查询效率也算在内;质量是改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量、一致性的数据访问平台。在实际应用中则会根据这几点要素所占权重的不同来选择合适的建模方法。
ER模型
将事务抽象为“实体”、“属性”和“关系”来表示数据的关联和事物的描述,这种对事务的抽象建模通常称为 E-R 实体关系模型。数据仓库之父Bill Inmon提出的建模方法,从全企业的高度设计一个 3NF 模型,用实体关系( Entity Relationship )模型来描述企业业务,满足 3NF。
数据仓库的 3NF 与 OLTP 系统中的 3NF 的区别在于,它是站在企业角度面向主题的抽象,而不是针对某个具体的业务流程。采用 E-R模型建设数据仓库模型的出发点是整合数据,对各个系统的数据以整个企业角度按主题进行相似的组合和合并,并进行一致性处理,为数据分析决策服务,但是并不能直接用于分析决策。
作为一种标准的数据建模方案,它的实施周期非常长,一致性和扩展性比较好,能经得起时间的考验。但是随着企业数据的高速增长、复杂化,数仓如果全部使用 E-R 模型进行建模就显得越来越不适合现代化复杂、多变的业务组织,因此一般只有在数仓底层 ODS、DWD 会采用 E-R 关系模型进行设计。
维度建模
维度建模是数据仓库领域另一位大师 Ralph Kimball 所倡导,是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。维度建模是专门用于分析型数据库、数据仓库、数据集市建模的方法。
维度建模的主要构成是维度表和事实表。每一张维度表对应现实世界中的一个对象或者一个主题,例如:客户、产品、时间、地区等,通常是包含了多个属性的列,通常数据量不会太大;事实表则是描述业务的多条记录,包含了描述业务的度量值以及和维度表相关联的外键,外键和维度表通常是多对多的关系,数据量大而且经常发生变化。
维度建模一般包含三个,一般是根据业务需求和业务复杂性加以区分,有区分的方法但没有比较清晰地界限。分别是星型模型、雪花模型和星座模型。
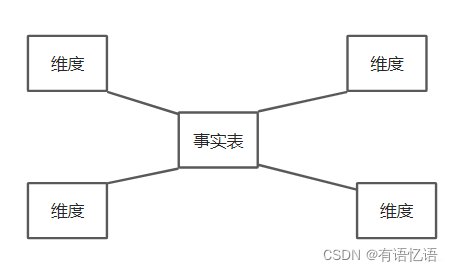
星型模型
星型模式(Star Schema)是面向主题的常用模式,主要由一个事实表和多个维度表构成,不存在二级维度表
雪花模型
雪花模型(Snowflake Schema)是在星型模型基础上将维表再次扩展,每个维表可以继续向外连接多个子维表。
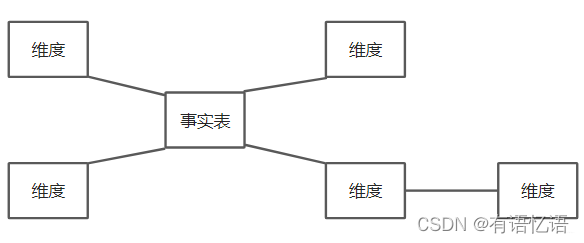
雪花模型相当于将星型模型的大维表拆分成小维表,满足了规范化设计,因为很少会有事实表只关联一层维度的,往往维度还会细分,钻取。然而这种模式在实际应用中很少见,因为跨表查询时效率很慢,所以现在的做法是将部分维度表整合到事实表中,形成宽表,在查询汇总的时候只需要group by就可以了,不需要再进行join操作。
星座模型
星座模型(Fact Constellations Schema)也是星型模型的扩展,存在多个事实表且可共用同一个维表。实际上数仓模型建设后期,大部分维度建模都是星座模型。
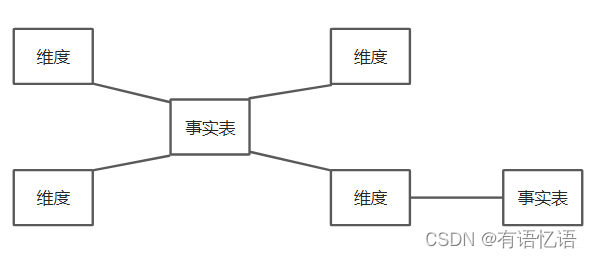
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表可能被多个事实表用到。在业务发展的后期,绝大部分维度建模都采用的都是星座模型。
Data Vault模型
Data Vault 是 Dan Linstedt 发起创建的一种模型,它是 E-R 模型的衍生,其设计的出发点也是为了实现数据的整合,但不能直接用于数据分析决策。主要在对自然界中发现的复杂网络建模。
Data Vault 是面向细节的,可追踪历史的,一组有连接关系的规范化的表的集合。这些表可以支持一个或多个业务功能。从建模风格上看,它采用了一种由第三范式方法(3NF)与维度建模方法混合而成的方式,以二者的独特组合来满足企业需求。
同时它基于主题概念将企业数据进行结构化组织,并引入了更进一步的范式处理来优化模型,以应对源系统变更的扩展性。 Data Vault 型由以下几部分组成:
Hub - 中心表:是企业的核心业务实体,由实体 Key、数仓序列代理键、装载时间、数据来源组成,不包含非键值以外的业务数据属性本身。
Link - 链接表:代表 Hub 之间的关系,一个链接表意味着两个或多个中心表之间有关联。这里与 ER 模型最大的区别是将关系作为一个独立的单元抽象,可以提升模型的扩展性。它可以直接描述 1:1、1:2 和 n:n 的关系,而不需要做任何变更。它由 Hub 的代理键、装载时间、数据来源组成。
Satellite - 卫星表:数仓中数据的主要载体,包括对链接表、中心表的数据描述、数值度量等信息。Anchor 模型
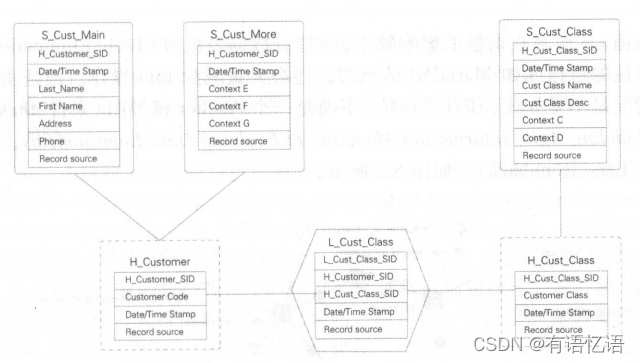
Data Vault 模型比 E-R 模型更容易设计和产出,它的 ETL 加工可实现配置化。我们可以将 Hub 想象成人的骨架,那么 Link 就是连接骨架的韧带,而 SateIIite 就是骨架上面的血肉。
Anchor模型
Anchor 是对 Data Vault 模型做了进一步的规范化处理,它的核心思想是所有的扩展只是添加而不是修改,因此将模型规范到6NF,基本变成了 k-v 结构化模型。
Anchors :类似于 Data Vault 的 Hub ,代表业务实体,且只有主键。
Attributes :功能类似于 Data Vault 的 Satellite,但是它更加规范化,将其全部 k-v 结构化, 一个表只有一个 Anchors 的属性描述。
Ties :就是 Anchors 之间的关系,单独用表来描述,类似于 Data Vault 的 Link ,可以提升整体模型关系的扩展能力。
Knots :代表那些可能会在 Anchors 中公用的属性的提炼,比如性别、状态等这种枚举类型且被公用的属性。
由于过度规范化,使用中牵涉到太多的Join操作,这里我们就仅作了解。
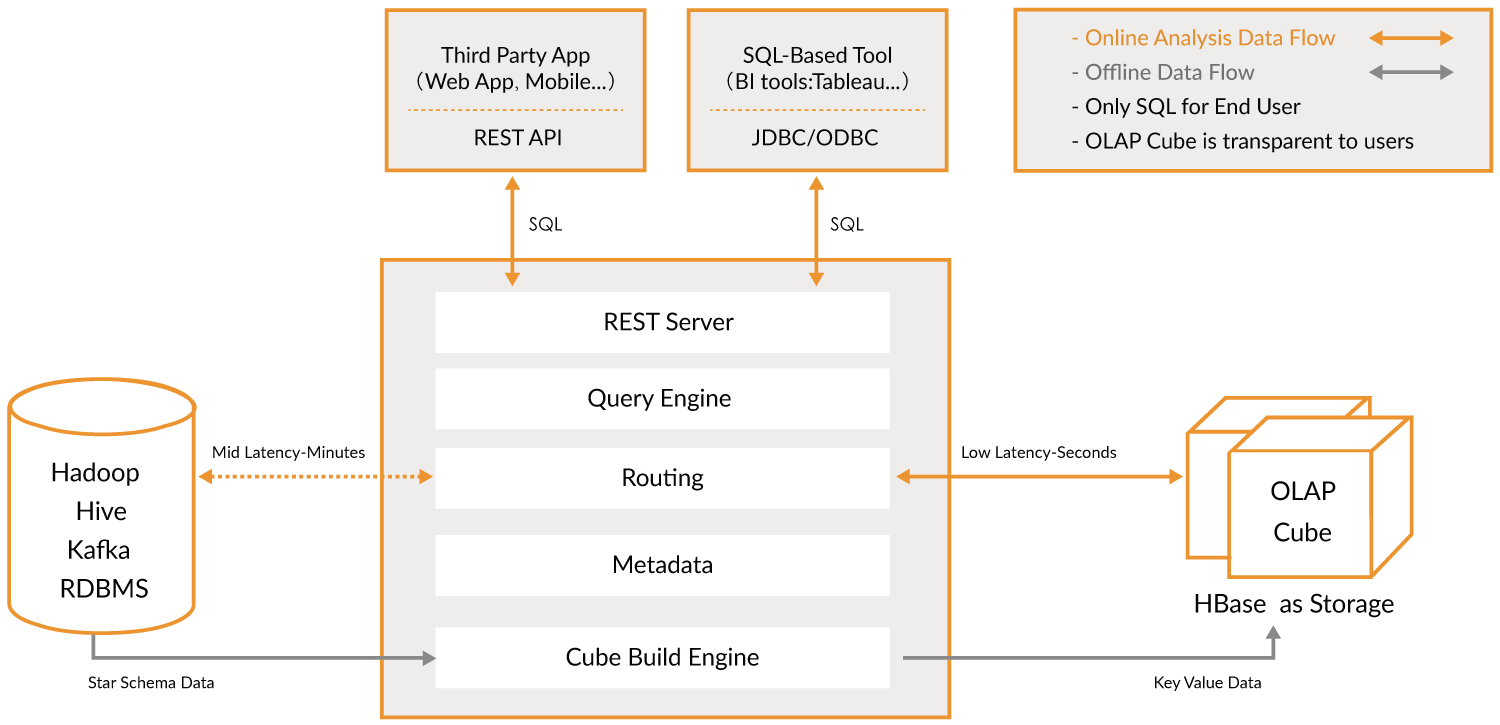
MOLAP
MOLAP区别于以上几种建模方法,适用于 ADS 层。它是将数据进行预结算,并将结果存到 CUBE 模型中,在查询的时候效率就会快很多。CUBE模型以多维数组的形式,存储在系统中,加快后续的查询,但是需要耗费巨大的时间和空间成本,维度预处理可能会导致数据膨胀。

常见的MOLAP产品有Kylin和Druid,其中Kylin使用的会比较多一点,它是将数据仓库中的数据抽取过来进行维度组合,加工成CUBE后存储到Hbase数据库(Hbase具有并发能力,所以查询性能会很高)中,业务端或者前端需要数据的时候Kylin则会从Hbase中将数据取出并返回。
原文链接:https://blog.csdn.net/m0_61192794/article/details/120492718
4、数据如何进行建模的
数据建模的基本流程主要包含六个步骤:确定分析目标、数据理解、数据准备、建立模型、模型评估、模型发布与应用。
数据建模是以业务为驱动,基于数据构建科学模型应用于实际中去解决问题的过程。这个过程并不以模型构建、或者模型落地就终止的,而是随着业务在不断地循环改进的。我参考了跨行业数据挖掘标准流程 CRISP-DM 和个人的一些拙见,对数据建模的六个环节进行整理,具体如下:
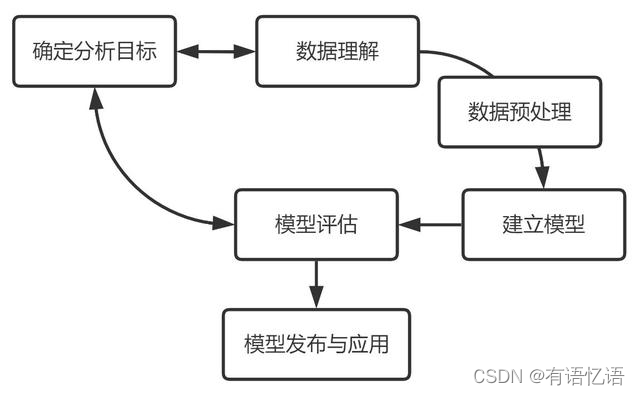
1.确定分析目标
一切分析的开始都是要基于明确的分析目标,不论何种业务场景,在分析前都需要了解好业务背景、业务需求,明确这次分析是为了解决什么业务问题,分析工作的最核心的需求是什么。如何理解业务需求可以做好以下两点:
与相关进行需求讨论,内容围绕业务逻辑、需求合理性、可行性等方面进行。
确定好分析需求后,指定分析框架和项目计划表。分析框架主要包括:目标变量的定义,大致的分析思路,数据抽样规则,潜在自变量的罗列,项目风险评估,大致的落地应用方案。
2. 数据理解
数据理解阶段的重点是放在数据采集获取上。在工作中就是常说的“提数”,这个过程可以进行一系列的数据探索和熟悉,识别数据质量问题,发现数据的内部属性等,可以初步形成一些对数据的假设。
提数是数据建模的基础工作,也是影响模型输出结论的最重要的一步。如果源数据就错了,就不要想分析结果是对的。所以常常会有人说,数据分析工作其实是需要花大概80%的时间在数据上的。
在提数的过程中,需要注意:
要足够熟悉业务,一定要和业务相关人员进行深入沟通,确定好需要什么样的数据指标;
数据常常是有时效的,要考虑抽取的数据是否符合现在的业务需求;
核实数据源的真实性,数据的规范性等等。
3. 数据准备(预处理)
拿到数据后,需要思考,这些数据质量有没有问题?以及需要进行怎么样的加工?
常常涉及到的内容会有:
抽样分析:数据量特别大的时候就需要抽取部分数据进行检查
规模分析:常常与抽样分析结合,用以分析某个指标的总体规模
缺失值处理:灵活运用删除和插值
异常值处理:一般都是直接删除
数据转换:规范化、压缩分布区间、分组、分箱等
筛选有效的自变量:有时候自变量特别多,就需要从中选取贡献度最大的部分自变量,筛选指标有:皮尔逊相关系数、数据降维方法等,对一些共线性的自变量,可以生成一个新的综合性的变量进行替代。
不过实际中的业务往往会很复杂,甚至于业务逻辑更加复杂,使得有些问题的发现和解决往往不是一蹴而就的,需要进行多次尝试,或者在后面的操作中发现问题之后再回过头来进行处理。
- 建立模型
数据模型开发的目的是为了从数据中挖掘有价值的信息。实际中比较常见的应用场景有:预测、评价、聚类、推荐、异常检测。
根据确定的分析目标,搭建相关的数据模型,这些模型往往都是基于基础模型进行优化改进的,实际中复杂的往往是数据,模型有时候逻辑并不复杂,且复杂的模型在实际中的应用效果很多时候反而没那么如意。在这个过程中也可以对比多个模型,选取表现较好或表现较为稳定的。一些场景的常见应对算法:
划分群体:聚类、分类
购物篮分析:相关、聚类
预测:回归、时间序列
推荐:关联分析
满意度调查:回归、聚类、分类…
5. 模型评估
模型的评估是要以分析目标为导向的,是需要模型更快、还是需要模型更准确、还是需要模型的泛化性能更好、抑或是需要模型的稳定性强等等,都是建立在一开始确立的分析业务目标的基础之上。
此外,还需要对得到的模型提出这两个问题:
这个模型解决了什么问题?是否符合一开始的目标;
模型的解决效果是怎么样的?
6. 模型发布与应用
到了这一步,要将模型投入到实际的业务中应用以产生价值,当然,到这里还不算结束,还需要对模型的应用效果做及时的跟踪反馈,以便之后的优化更新。数据模型就像一个产品一样,它的生命周期从一开始到最后淘汰,在这个过程中是需要不断更新迭代的,就算业务变了,数据模型的搭建经验也可以迁移到其他业务中去。
落地前:相关开发人员要撰写清晰的应用文档以便模型高效实施;落地后:跟踪落地效果,及时优化模型及应用方案。最后,对数据模型开发项目做好经验总结。
5、五步数据建模法
数据建模的步骤(一)选择模型或自定义模型
这是建模的第一步,需要基于业务问题,来决定可以选择哪些可用的模型。比如,建立支付风险控制模型,可以选择决策树模型,也可以选择评分模型。如果没有现成的模型可用,你需要自定义模型,也可以聘请专家教授设计模型。
数据建模的步骤(二)训练模型
当模型选择好了以后,就要训练模型。所谓训练模型,就是基于真实的业务数据来确定最合适的模型参数。一旦找到最优参数,模型就可以用了。
找到最优的模型参数,需要依赖于算法。常见的算法有分类(有明确类别)、聚类(无明确类别)、关联、回归等。常见的分类算法有KNN算法(k-近邻算法)、贝叶斯算法、决策树、人工神经网络和支持向量机。
数据建模的步骤(三)评估模型
模型训练好以后,接下来就是评估模型。评估模型,就是决定模型的质量,判断模型是否有用。
模型的好坏是不能够单独评估的,一个模型的好坏需要放在特定的业务场景下来评估,也就是基于特定的数据集下才能知道哪个模型好与坏。
评估一个模型好坏,通常需要设置一些评价指标。比如,数值预测模型中,评价模型质量的常用指标有平均误差率、判定系数R2等等;评估分类预测模型质量的常用指标有正确率、查全率、查准率、ROC曲线和AUC值等等。对于分类预测模型,一般要求正确率和查全率等越大越好,最好都接近100%,表示模型质量好,无误判。
值得注意的是,在真实的业务场景中,评估指标是基于测试集的,而不是训练集。所以,在建模时,务必将原始数据集分成两部分:一部分用于训练模型,即训练集;另一部分用于评估模型,叫测试集或验证集。
为什么评估模型要用两个不同的数据集?这是因为模型是基于训练集构建起来的,从理论上讲模型在训练集上肯定有较好的效果;但在真实的业务应用场景下其预测效果不一定好(这种现象称之为过拟合)。因此,我们需要将训练集、测试集分开来,一个用于训练模型,一个用于评估模型,以便提前发现模型是不是存在过拟合。
如果发现在训练集和测试集上的预测效果差不多,表示模型质量尚好,可以直接使用。如果发现训练集和测试集上的预测效果相差太远,说明模型需要优化。
要特别注意的是,只想验证一次就想准确评估出模型的好坏是不合适的,还需要采用交叉验证的方式进行多次评估,以便找到准确的模型误差。
数据建模的步骤(四)应用模型
如果评估模型质量在可接受的范围内,且没有出现过拟合,就可以开始应用模型了。这一步,需要将可用的模型开发出来,部署在数据分析系统中,形成数据分析的模板和可视化的分析结果,以便实现自动化的数据分析报告。
模型应用,就是将模型应用于真实的业务场景。建模的目的是用于解决工作中的业务问题,如信贷智能审批等。应用模型过程中,要持续收集业务预测结果与真实的业务结果,以检验模型在真实的业务场景中的效果,同时用于后续模型的优化。
数据建模的步骤(五)优化模型
如果发生以下两种情况,就需要模型优化:(1)评估模型中,如出现模型欠拟合,或者过拟合,说明这个模型待优化;(2)在真实应用场景中,定期进行优化,或者当发现模型在真实的业务场景中效果不好时,也要启动优化。模型优化,可以有以下四种情况:
1.重新选择一个新的模型;
2.模型中增加新的考虑因素;
3.尝试调整模型中的阈值到最优;
4.尝试对原始数据进行更多的预处理,如派生新变量。
不同的模型,其模型优化的具体做法也不一样。如回归模型的优化,可以考虑异常数据对模型的影响,也要进行非线性和共线性的检验;再如分类模型的优化,主要是一些阈值的调整,以实现精准性与通用性的均衡。也可以采用元算法来优化模型,就是通过训练多个弱模型,来构建一个强模型来实现模型的最佳效果。
值得注意的是,不可能有一个模型适用于所有业务场景,也不太可能有一个固有的模型就适用于你的业务场景。好模型都是优化出来的。
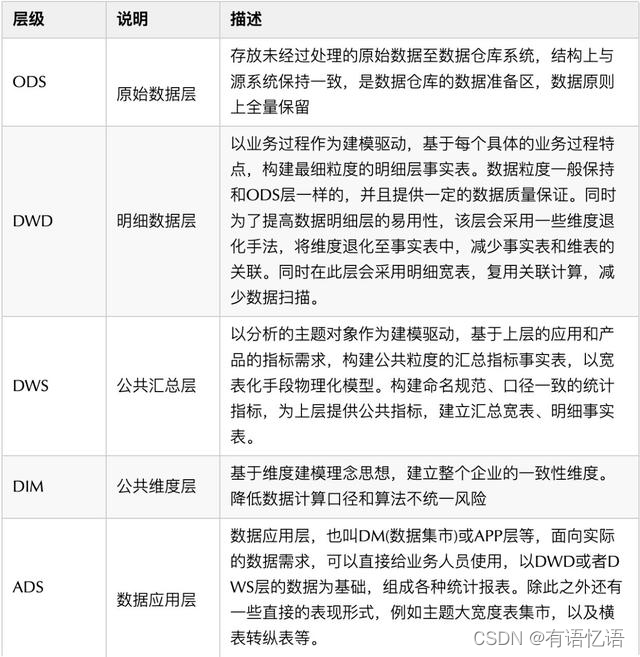
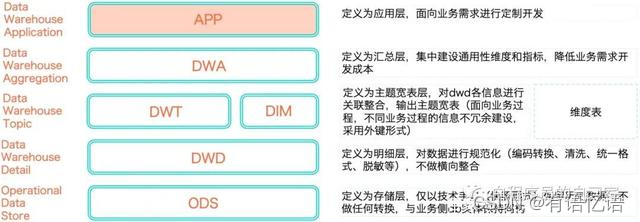
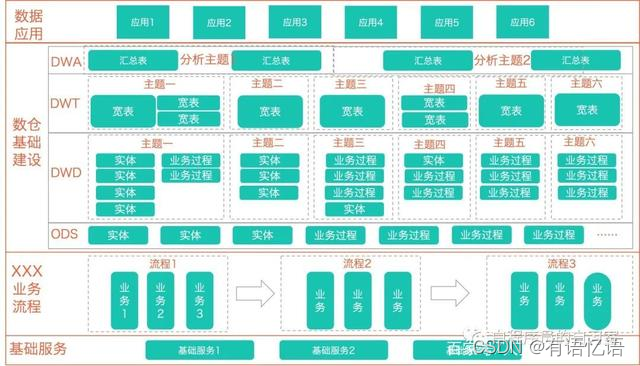
6、数仓如何分层的
CIF层次架构(信息工厂)通过分层将不同的建模方案引入到不同的层次中,CIF将数据仓库分为四层,如图所示:
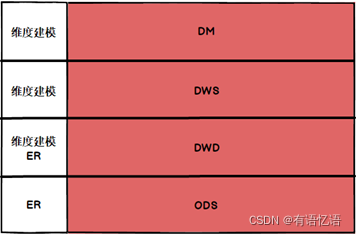
ODS(Operational Data Store):操作数据存储层,往往是业务数据库表格的一对一映射,将业务数据库中的表格在ODS重新建立,数据完全一致;
DWD(Data Warehouse Detail):数据明细层,在DWD进行数据的清洗、脱敏、统一化等操作,DWD层的数据是干净并且具有良好一致性的数据;
DWS(Data Warehouse Service):服务数据层(公共汇总层),在DWS层进行轻度汇总,为DM层中的不同主题提供公用的汇总数据;
DM(Data Market):数据集市层,DM层针对不同的主题进行统计报表的生成;
7、100亿数据找出最大的1000个数字
1、最容易想到的方法是将数据全部排序。该方法并不高效,因为题目的目的是寻找出最大的10000个数即可,而排序却是将所有的元素都排序了,做了很多的无用功。
2、局部淘汰法。用一个容器保存前10000个数,然后将剩余的所有数字一一与容器内的最小数字相比,如果所有后续的元素都比容器内的10000个数还小,那么容器内这个10000个数就是最大10000个数。如果某一后续元素比容器内最小数字大,则删掉容器内最小元素,并将该元素插入容器,最后遍历完这1亿个数,得到的结果容器中保存的数即为最终结果了。此时的时间复杂度为O(n+m^2),其中m为容器的大小。
这个容器可以用(小顶堆)最小堆来实现。我们知道完全二叉树有几个非常重要的特性,就是假如该二叉树中总共有N个节点,那么该二叉树的深度就是log2N,对于小顶堆来说移动根元素到 底部或者移动底部元素到根部只需要log2N,相比N来说时间复杂度优化太多了(1亿的logN值是26-27的一个浮点数)。基本的思路就是先从文件中取出1000个元素构建一个小顶堆数组k,然后依次对剩下的100亿-1000个数字进行遍历m,如果m大于小顶堆的根元素,即k[0],那么用m取代k[0],对新的数组进行重新构建组成一个新的小顶堆。这个算法的时间复杂度是O((100亿-1000)log(1000)),即O((N-M)logM),空间复杂度是M
这个算法优点是性能尚可,空间复杂度低,IO读取比较频繁,对系统压力大。
3、第三种方法是分治法,即大数据里最常用的MapReduce。
a、将100亿个数据分为1000个大分区,每个区1000万个数据
b、每个大分区再细分成100个小分区。总共就有1000*100=10万个分区
c、计算每个小分区上最大的1000个数。
为什么要找出每个分区上最大的1000个数?举个例子说明,全校高一有100个班,我想找出全校前10名的同学,很傻的办法就是,把高一100个班的同学成绩都取出来,作比较,这个比较数据量太大了。应该很容易想到,班里的第11名,不可能是全校的前10名。也就是说,不是班里的前10名,就不可能是全校的前10名。因此,只需要把每个班里的前10取出来,作比较就行了,这样比较的数据量就大大地减少了。我们要找的是100亿中的最大1000个数,所以每个分区中的第1001个数一定不可能是所有数据中的前1000个。
d、合并每个大分区细分出来的小分区。每个大分区有100个小分区,我们已经找出了每个小分区的前1000个数。将这100个分区的1000*100个数合并,找出每个大分区的前1000个数。
e、合并大分区。我们有1000个大分区,上一步已找出每个大分区的前1000个数。我们将这1000*1000个数合并,找出前1000.这1000个数就是所有数据中最大的1000个数。
(a、b、c为map阶段,d、e为reduce阶段)
4、Hash法。如果这1亿个书里面有很多重复的数,先通过Hash法,把这1亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的10000个数。
对于海量数据处理,思路基本上是:必须分块处理,然后再合并起来。
8、增量数据的四种抽取模式
大数据云时代,数据上云ETL已成了最基础,最根本,也是最必须的一个步骤。目前数据传输迁移的工具非常多,比如DataX,DTS,Kettle等等。为了保证云上存储空间的有效利用和数据的整体唯一性,就没必要每天都上一份全量,故几乎所有数据上云的策略都是全量加增量的模式:即第一次上一份初始化全量,后续每天只上增量,这样前一天的全量加上今天的增量就是今天的全量。
T+1(全) = T (全) + T+1(增)
既然是要每天上增量,那么如何获取增量数据便成了一个问题所在,笔者依据书籍资料加上公司的实践经验简单提一下四种获取增量数据的方法
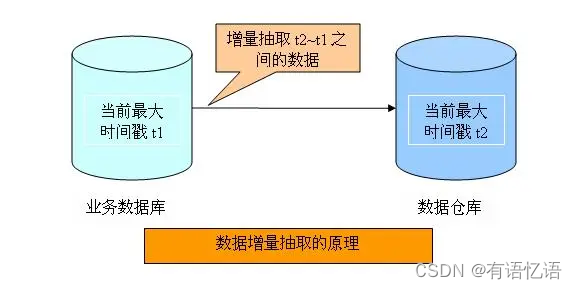
基于日志文件读取增量数据
这种方式可以通过读取数据库的归档日志,比如MySQL的binlog等得到增量数据,然后在目标库或者文档服务器里进行操作
该场景的优势明显,目前适用于绝大多数的实时数据传输场景,常见的日志解析工具有OGG以及阿里开源工具canal等,这类工具可把日志数据解析为可识别的json数据并通过Kafka,MQ等实时消费到目标库
优点:可以做到数据无误差的实时传输,有回滚机制,有容灾备份的能力
缺点:开归档会对源端数据库的磁盘造成压力,增加储存成本,此外大多数数据库的日志都是不对外开放的,只针对数据库本身的工具开放读取,例如ORACLE的OGG
基于全量对比得出增量数据
增量数据即DML操作,无非I(INSERT),D(DELETE),U(UPDATE)三种,故可以拿昨天的全量数据与今天的全量数据进行对比得出昨天的增量,具体方法是通过关联表的主键,唯一键用left join,right join,inner join 等对比出增量数据,参考脚本如下
– 对比出两个时间区间所有的不等数据,得出增量(部分需去重)
SELECT A1.* FROM
(SELECT * FROM T1 WHERE P_DATE <= ‘2021-07-07’)A1 LEFT JOIN
(SELECT * FROM T1 WHERE P_DATE <= ‘2021-07-06’)B1 ON A1.ID = B1.ID
AND A1.P_DATE = B1.P_DATE AND A1.P_NAME = B1.P_NAME WHERE B1.ID IS NULL
UNION ALL
SELECT B1.* FROM
(SELECT * FROM T1 WHERE P_DATE <= ‘2021-07-07’)A1 RIGHT JOIN
(SELECT * FROM T1 WHERE P_DATE <= ‘2021-07-06’)B1 ON A1.ID = B1.ID
AND A1.P_DATE = B1.P_DATE AND A1.P_NAME = B1.P_NAME WHERE A1.ID IS NULL
优点:因为是云上merge对比,所以对源库无影响
缺点:这个操作仅仅适合表有主键,唯一键或者数据量较小的表,不然海量数据中每条数据的每一列都进行逐一比对,很显然这种频繁的I/O操作以及复杂的比对运算会造成很大的性能开销。
基于时间字段切分增量数据
此方法依据表的某一时间字段,在etl工具里进行条件设定即可快速抽取增量数据
比如我们要抽取2021-07-06 13:00:00 到 2021-07-06 16:00:00,则可限定
SELECT * FROM T1
WHERE
P_DATE BETWEEN ‘2021-07-06 13:00:00’
AND ‘2021-07-06 16:00:00’
优点:数据处理逻辑清楚,速度较快,成本低廉,流程简单
缺点:此方法要求表的时间字段必须是随表变动而变动的不为空数据,此外由于是直接读取表数据,该方法无法获取删除类型的数据。
基于建触发器生成增量数据
触发器的概念我们都知道,故我们可以建立IDU三种操作类型的触发器,并由触发器将变更的数据写到库里的临时表里,然后用ETL工具直接抽取这张临时表即可进行增量上云
CREATE
OR REPLACE TRIGGER tri_t1 BEFORE INSERT
OR UPDATE
OR DELETE ON t1 BEGIN
IF
USER <> ‘ADMIN’ THEN
raise_application_error (- 20001, ‘You don’‘t have access to modify this table.’ );
END IF;
END;
优点:是数据库本身的触发器机制,契合度高,可靠性高,不会存在有增量数据未被捕获到的现象
缺点:对于源端有较大的影响,需要建立触发器机制,增加运维人员,还要建立临时表,储存临时表,增加储存成本和运维成本
课后总结
这四种增量获取的方法应用都比较宽泛,各有各的优势和缺点
一般来讲
对于大型数据库,数据变更频率快,表数量多,对数据传输要求有备份,安全,零差数据的采用基于数据库日志的方法
对于小型数据库,且未开归档,但数据变更频率快的采用基于全量对比的方法
对于含有标准时间戳字段,且应用环境适合,表数量较少的采用基于时间字段的方法
至于触发器,由于需要源端运维成本较大,且对源端存储有压力(既然都是对存储有压力为何不用OGG),故很少有客户选择这一种
9、如何每天抽取增量100亿的数据
1、根据某些分布均匀的字段,分段去抽,比如时间字段,一个小时,一个小时的去抽
2、或者直接写入到hdfs,或者kafka.
10、如何保证离线和实时数据的一致性
1、用离线的数据覆盖替换实时的数据结果。
2、批流一体,用离线和实时统一的的数据源
11、Flink如何处理乱序数据?
watermark
12、Flink如何提前关窗?
trigger,比如开个24小时的窗口,但是又不想等到24小时之后看结果,想拉一条看一条结果,则可以来一条触发一次计算,并输出结果,不关窗
13、Flink定时器的原理?
Timer(定时器)是Flink Streaming API提供的用于感知并利用处理时间/事件时间变化的机制。官网上给出的描述如下:
Timers are what make Flink streaming applications reactive and adaptable to processing and event time changes.
对于普通用户来说,最常见的显式利用Timer的地方就是KeyedProcessFunction。我们在其processElement()方法中注册Timer,然后覆写其onTimer()方法作为Timer触发时的回调逻辑。根据时间特征的不同:
处理时间——调用Context.timerService().registerProcessingTimeTimer()注册;onTimer()在系统时间戳达到Timer设定的时间戳时触发。
事件时间——调用Context.timerService().registerEventTimeTimer()注册;onTimer()在Flink内部水印达到或超过Timer设定的时间戳时触发。
举个栗子,按天实时统计指标并存储在状态中,每天0点清除状态重新统计,就可以在processElement()方法里注册Timer。
KeyedProcessFunction用来操作KeyedStream。KeyedProcessFunction会处理流的每一个元素,输出为0个、1个或者多个元素。所有的Process Function都继承自RichFunction接口,所以都有open()、close()和getRuntimeContext()等方法。而KeyedProcessFunction[KEY, IN, OUT]还额外提供了两个方法:
processElement(v: IN, ctx: Context, out: Collector[OUT]), 流中的每一个元素都会调用这个方法,调用结果将会放在Collector数据类型中输出。Context可以访问元素的时间戳,元素的key,以及TimerService时间服务。Context还可以将结果输出到别的流(side outputs)。
onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])是一个回调函数。当之前注册的定时器触发时调用。参数timestamp为定时器所设定的触发的时间戳。Collector为输出结果的集合。OnTimerContext和processElement的Context参数一样,提供了上下文的一些信息,例如定时器触发的时间信息(事件时间或者处理时间)。
Context和OnTimerContext所持有的TimerService对象拥有以下方法:
currentProcessingTime(): Long 返回当前处理时间
currentWatermark(): Long 返回当前watermark的时间戳
registerProcessingTimeTimer(timestamp: Long): Unit 会注册当前key的processing time的定时器。当processing time到达定时时间时,触发timer。
registerEventTimeTimer(timestamp: Long): Unit 会注册当前key的event time 定时器。当水位线大于等于定时器注册的时间时,触发定时器执行回调函数。
deleteProcessingTimeTimer(timestamp: Long): Unit 删除之前注册处理时间定时器。如果没有这个时间戳的定时器,则不执行。
deleteEventTimeTimer(timestamp: Long): Unit 删除之前注册的事件时间定时器,如果没有此时间戳的定时器,则不执行。
定时器源码分析
=》注册 eventTimeTimersQueue.add(new TimerHeapInternalTimer<>(timr,(k
keyContext.getCurrentKey(),namespace));
=》触发 timer.getTimerstamp()<= time ===》定时的时间<=watermark
当定时器timer触发时,会执行回调函数onTimer()。注意定时器timer只能在keyed streams上面使用。
14、Flink如何进行对账?
1、获取执行环境,设置并行度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
2、读取两条流数据转换成bean对象
SingleOutputStreamOperator<OrderEvent> orderDS = env
.readTextFile("input/OrderLog.csv")
.map(new MapFunction<String, OrderEvent>() {
@Override
public OrderEvent map(String value) throws Exception {
String[] datas = value.split(",");
return new OrderEvent(
Long.valueOf(datas[0]),
datas[1],
datas[2],
Long.valueOf(datas[3])
);
}
});
SingleOutputStreamOperator<TxEvent> txDS = env
.readTextFile("input/ReceiptLog.csv")
.map(new MapFunction<String, TxEvent>() {
@Override
public TxEvent map(String value) throws Exception {
String[] datas = value.split(",");
return new TxEvent(
datas[0],
datas[1],
Long.valueOf(datas[2])
);
}
});
3、处理数据,实时对账,两条流connect 起来,通过订单ID匹配,匹配上就是对账成功
对于同一笔订单交易来说,业务系统和交易系统的数据哪个先来,是不一定的
一般两条流connect 的时候,会做keyby,为了要匹配的数据到一起
可以先keyby再connect ,也可以先connect 再keyby
ConnectedStreams<OrderEvent, TxEvent> orderTxCS = (orderDS.keyBy(order -> order.getTxId()))
.connect(txDS.keyBy(tx -> tx.getTxId()));
4、使用process处理
SingleOutputStreamOperator<String> resultDS = orderTxCS.process(
new CoProcessFunction<OrderEvent, TxEvent, String>() {
// 用来存放 交易系统 的数据
private Map<String, TxEvent> txMap = new HashMap<>();
// 用来存放 业务系统 的数据
private Map<String, OrderEvent> orderMap = new HashMap<>();
/**
* 处理业务系统的数据,来一条处理一条
* @param value
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void processElement1(OrderEvent value, Context ctx, Collector<String> out) throws Exception {
// 进入这个方法,说明来的数据是 业务系统的数据
// 判断 交易数据 来了没有?
// 通过 交易码 查询保存的 交易数据 => 如果不为空,说明 交易数据 已经来了,匹配上
TxEvent txEvent = txMap.get(value.getTxId());
if (txEvent == null) {
// 1.说明 交易数据 没来 => 等 , 把自己临时保存起来
orderMap.put(value.getTxId(), value);
} else {
// 2.说明 交易数据 来了 => 对账成功
out.collect("订单" + value.getOrderId() + "对账成功");
// 对账成功,将保存的 交易数据 删掉
txMap.remove(value.getTxId());
}
}
/**
* 处理交易系统的数据,来一条处理一条
* @param value
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void processElement2(TxEvent value, Context ctx, Collector<String> out) throws Exception {
// 进入这个方法,说明来的数据是 交易系统 的数据
// 判断 业务数据 来了没有?
OrderEvent orderEvent = orderMap.get(value.getTxId());
if (orderEvent == null) {
// 1.说明 业务数据 没来 => 把自己 临时保存起来
txMap.put(value.getTxId(), value);
} else {
// 2.说明 业务数据 来了 => 对账成功
out.collect("订单" + orderEvent.getOrderId() + "对账成功");
// 对账成功,将保存的 业务数据 删掉
orderMap.remove(value.getTxId());
}
}
}
);
比如医疗业务,处方和订单数据有可能差一天的时间差,则需要将昨天的数据放到广播变量里面去对账数据(也可以不用管,因为放到map里面数据不会过期,对完账之后删除即可,如果订单特别多则需要,比如双十一,一个小时几亿的订单,且订单支付时间有半个小时的延迟,则可以)
15、Flink用来处理哪些实时业务? SQL如何写的?
16、Flink如何和Oracle进行交互?保证Exac once ,实现原理?
17、FlinkSQL如何进行双流join
在使用 SQL 进行数据分析的过程中,join 是经常要使用的操作。在离线场景中,join 的数据集是有边界的,可以缓存数据有边界的数据集进行查询,有Nested Loop/Hash Join/Sort Merge Join 等多表 join;而在实时场景中,join 两侧的数据都是无边界的数据流,所以缓存数据集对长时间 job 来说,存储和查询压力很大,另外双流的到达时间可能不一致,造成 join 计算结果准确度不够;因此,Flink SQL 提供了多种 join 方法,来帮助用户应对各种 join 场景。
主要介绍 regular join/interval join/temproal table join 这种 3 种 join 的实战应用,主要包含如下几个部分:
数据准备
Flink SQL join 之 regular join
Flink SQL join 之 interval join
Flink SQL join 之 temproal table join
01 数据准备
一般来说大部分公司的实时的数据是保存在 kafka,维度数据保存在 MySQL 等类似的关系型数据库中,根据 Flink SQL 提供的 Kafka/JDBC connector,我们先注册两张 Flink Kafka Table 以及注册一张 Flink MySQL Table,明细建表语句如下所示:
注册 Flink Kafka Table, 作为两条需要 join 的数据流;对于点击流,我们定义Process time 时间属性,用来做 temproal table join,同时也定义 Event Time 和 watermark,用来做双流 join;对于曝光流,我们定义 Event Time 和watermark,用来做双流 join。
DROP TABLE IF EXISTS flink_rtdw.demo.adsdw_dwd_max_click_mobileapp;
CREATE TABLE flink_rtdw.demo.adsdw_dwd_max_click_mobileapp (
...
publisher_adspace_adspaceId INT COMMENT '广告位唯一ID',
...
audience_behavior_click_creative_impressionId BIGINT COMMENT '受众用户点击的广告创意的ImpressionId',
audience_behavior_click_timestamp BIGINT COMMENT '受众用户点击广告的时间戳(毫秒)',
...
procTime AS PROCTIME(),
ets AS TO_TIMESTAMP(FROM_UNIXTIME(audience_behavior_click_timestamp / 1000)),
WATERMARK FOR ets AS ets - INTERVAL '5' MINUTE
) WITH (
'connector' = 'kafka',
'topic' = 'adsdw.dwd.max.click.mobileapp',
'properties.group.id' = 'adsdw.dwd.max.click.mobileapp_group',
'properties.bootstrap.servers' = 'broker1:9092,broker2:9092,broker3:9092',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-administrator" password="kafka-administrator-password";',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.mechanism' = 'SCRAM-SHA-256',
'avro-confluent.schema-registry.url' = 'http://schema.registry.url:8081',
'avro-confluent.schema-registry.subject' = 'adsdw.dwd.max.click.mobileapp-value',
'format' = 'avro-confluent'
);
注册 Flink Mysql Table, 作为维度表
DROP TABLE IF EXISTS flink_rtdw.demo.adsdw_dwd_max_show_mobileapp;
CREATE TABLE flink_rtdw.demo.adsdw_dwd_max_show_mobileapp (
...
audience_behavior_watch_creative_impressionId BIGINT COMMENT '受众用户观看到的广告创意的ImpressionId',
audience_behavior_watch_timestamp BIGINT COMMENT '受众用户观看到广告的时间(毫秒)',
...
ets AS TO_TIMESTAMP(FROM_UNIXTIME(audience_behavior_watch_timestamp / 1000)),
WATERMARK FOR ets AS ets - INTERVAL '5' MINUTE
) WITH (
'connector' = 'kafka',
'topic' = 'adsdw.dwd.max.show.mobileapp',
'properties.group.id' = 'adsdw.dwd.max.show.mobileapp_group',
'properties.bootstrap.servers' = 'broker1:9092,broker2:9092,broker3:9092',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka-administrator" password="kafka-administrator-password";',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.mechanism' = 'SCRAM-SHA-256',
'avro-confluent.schema-registry.url' = 'http://schema.registry.url:8081',
'avro-confluent.schema-registry.subject' = 'adsdw.dwd.max.show.mobileapp-value',
'format' = 'avro-confluent'
);
02 Flink SQL join 之 regular join
首先介绍 regular join, 因为 regular join 是最通用的 join 类型,不支持时间窗口以及时间属性,任何一侧数据流有更改都是可见的,直接影响整个 join 结果。如果有一侧数据流增加一个新纪录,那么它将会把另一侧的所有的过去和将来的数据合并在一起,因为 regular join 没有剔除策略,这就影响最新输出的结果; 正因为历史数据不会被清理,所以 regular join 支持数据流的任何更新操作。对于 regular join 来说,更适合用于离线场景和小数据量场景。
使用语法
SELECT columns
FROM t1 [AS <alias1>]
[LEFT/INNER/FULL OUTER] JOIN t2
ON t1.column1 = t2.key-name1
使用场景:离线场景和小数据量场景
根据小节 1 中的数据,我们来做一个简单的 regular join,将 click 流和曝光流根据 impressionId 进行 regualr join,输出广告位和 impressionId,具体 SQL语句如下所示:
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId,
adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId as click_impressionId,
adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId as show_impressionId
from adsdw_dwd_max_click_mobileapp
inner join adsdw_dwd_max_show_mobileapp
on adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId = adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId;
03 Flink SQL join 之 interval join
相对于 regular join,interval Join 则利用窗口的给两个输入表设定一个 Join 的时间界限,超出时间范围的数据则对 join 不可见并可以被清理掉,这样就能修正 regular join 因为没有剔除数据策略带来 join 结果的误差以及需要大量的资源。但是使用interval join,需要定义好时间属性字段,可以是计算发生的 Processing Time,也可以是根据数据本身提取的 Event Time;如果是定义的是 Processing Time,则Flink 框架本身根据系统划分的时间窗口定时清理数据;如果定义的是 Event Time,Flink 框架分配 Event Time 窗口并根据设置的 watermark 来清理数据。而在前面的数据准备中,我们根据点击流和曝光流提取实践时间属性字段,并且设置了允许 5 分钟乱序的 watermark。目前 Interval join 已经支持 inner ,left outer, right outer , full outer 等类型的 join。因此,interval join 只需要缓存时间边界内的数据,存储空间占用小,计算更为准确的实时 join 结果。
使用语法
--写法1
SELECT columns
FROM t1 [AS <alias1>]
[LEFT/INNER/FULL OUTER] JOIN t2
ON t1.column1 = t2.key-name1 AND t1.timestamp BETWEEN t2.timestamp AND BETWEEN t2.timestamp + + INTERVAL '10' MINUTE;
--写法2
SELECT columns
FROM t1 [AS <alias1>]
[LEFT/INNER/FULL OUTER] JOIN t2
ON t1.column1 = t2.key-name1 AND t2.timestamp <= t1.timestamp and t1.timestamp <= t2.timestamp + + INTERVAL ’10' MINUTE ;
如何设置边界条件
right.timestamp ∈ [left.timestamp + lowerBound, left.timestamp + upperBound]
使用场景:双流join场景
根据小节1中的数据,我们来做一个inertval join(用between and 的方式),将click流和曝光流根据impressionId进行interval join, 边界条件是点击流介于曝光流发生到曝光流发生后的10分钟,输出广告位和impressionId,具体SQL语句如下所示:
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId,
adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId as click_impressionId,
adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId as show_impressionId
from adsdw_dwd_max_click_mobileapp
inner join adsdw_dwd_max_show_mobileapp
on adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId = adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId and
adsdw_dwd_max_click_mobileapp.ets between adsdw_dwd_max_show_mobileapp.ets and adsdw_dwd_max_show_mobileapp.ets + INTERVAL '10' MINUTE;
Interval join 有多种写法来实现 interval join,根据小节1中的数据我们用 <= 的方式来实现,还是做同样的逻辑,将 click 流和曝光流根据 impressionId 进行 interval join, 边界条件是点击流介于曝光流发生到曝光流发生后的 10 分钟,输出广告位和 impressionId,具体 SQL 语句如下所示:
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId,
adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId as click_impressionId,
adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId as show_impressionId
from adsdw_dwd_max_click_mobileapp
inner join adsdw_dwd_max_show_mobileapp
on adsdw_dwd_max_click_mobileapp.audience_behavior_click_creative_impressionId = adsdw_dwd_max_show_mobileapp.audience_behavior_watch_creative_impressionId and
adsdw_dwd_max_show_mobileapp.ets <= adsdw_dwd_max_click_mobileapp.ets and adsdw_dwd_max_click_mobileapp.ets <= adsdw_dwd_max_show_mobileapp.ets + INTERVAL '10' MINUTE;
04 Flink SQL join 之 temproal table join
上节中 interval Join 提供了剔除数据的策略,解决资源问题以及计算更加准确,这是有个前提:join 的两个流需要时间属性,需要明确时间的下界,来方便剔除数据;显然,这种场景不适合维度表的 join,因为维度表没有时间界限,对于这种场景,Flink 提供了 temproal table join 来覆盖此类场景。
在 regular join和interval join中,join 两侧的表是平等的,任意的一个表的更新,都会去和另外的历史纪录进行匹配,temproal table 的更新对另一表在该时间节点以前的记录是不可见的。而在temproal table join 中,比较明显的使用场景之一就是点击流去 join 广告位的维度表,引入广告位的中文名称。
使用语法
SELECT columns
FROM t1 [AS <alias1>]
[LEFT] JOIN t2 FOR SYSTEM_TIME AS OF t1.proctime [AS <alias2>]
ON t1.column1 = t2.key-name1
使用场景:维度表 join 场景
根据小节1中的数据,我们来做一个 temproal table join,将 click 流和广告位维度表根据广告位 Id 进行 temproal rable join,输出广告位和广告位中文名字,具体 SQL 语句如下所示:
select adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId as publisher_adspace_adspaceId,
mysql_dim_table.name as publisher_adspace_name
from adsdw_dwd_max_click_mobileapp
join mysql_dim_table FOR SYSTEM_TIME AS OF adsdw_dwd_max_click_mobileapp.procTime
on adsdw_dwd_max_click_mobileapp.publisher_adspace_adspaceId = mysql_dim_table.ID;
05 总结
上面简单介绍 Flink SQL 三种 join 方式的使用,一般对于流式 join 来说,对于双流join 的场景,推荐使用 interval join,对于流和维度表 join 的场景推荐使用 temproal table join。
18、hive分区表和分桶表的区别?
分区、分桶的作用:
我们知道在传统的DBMs系统中,一般都具有表分区的功能,通过表分区能够在特定的区域检索数据,减少扫描成本,在一定程度上提高了查询效率,当然我们还可以通过进一步在分区上建立索引,进一步提高查询效率。
在Hive中的数据仓库中,也有分区分桶的概念,在逻辑上,分区表与未分区表没有区别,在物理上分区表会将数据按照分区间的列值存储在表目录的子目录中,目录名=“分区键=键值”。其中需要注意的是分区键的列值存储在表目录的子目录中,目录名=“分区键=键值”。其中需要注意的是分区键的值不一定要基于表的某一列(字段),它可以指定任意值,只要查询的时候指定相应的分区键来查询即可。我们可以对分区进行添加、删除、重命名、清空等操作。
分桶则是指定分桶表的某一列,让该列数据按照哈希取模的方式随机、均匀的分发到各个桶文件中。因为分桶操作需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段)。分桶改变了数据的存储方式,它会把哈希取模相同或者在某一个区间的数据行放在同一个桶文件中。如此一来便可以提高查询效率。如果我们需要对两张在同一个列上进行了分桶操作的表进行JOIN操作的时候,只需要对保存相同列值的通进行JOIN操作即可。
还有一点需要点一下:在hive中的数据是存储在hdfs中的,我们知道hdfs中的数据是不允许修改只能追加的,那么在hive中执行数据修改的命令时,就只能先找到对应的文件,读取后执行修改操作,然后重新写一份文件。如果文件比较大,就需要大量的IO读写。在hive中采用了分桶的策略,只需要找到文件存放对应的桶,然后读取再修改写入即可。
分区:
hive中分区分为 : 单值分区、范围分区。
单值分区: 静态分区 动态分区
如下所示,现在有一张persionrank表,记录每个人的评级,有id、name、score字段。我们可以创建分区rank(rank不是表中的列,我们可以把它当做虚拟列),并将相应的数据导入指定分区(将数据插入指定目录)。
单值分区:
单值静态分区:导入数据时需要手动指定分区
单值动态分区:导入数据时,系统可以动态判断目标分区
1.静态分区创建:
直接在PARTITI1ONED BY后面跟上分区键、类型即可(指定的分区键不能出现在定义列名中)
CREATE [EXTERNAL] TABLE <table_name>
(<col_name> <data_type> [, <col_name> <data_type> …])
– 指定分区键和数据类型
PARTITIONED BY (<partition_key> <data_type>, …)
[CLUSTERED BY …]
[ROW FORMAT <row_format>]
[STORED AS TEXTFILE|ORC|CSVFILE]
[LOCATION ‘<file_path>’]
[TBLPROPERTIES (‘<property_name>’=‘<property_value>’, …)];
2.静态分区写入:
– 覆盖写入
INSERT OVERWRITE TABLE <table_name>
PARTITION (<partition_key>=<partition_value>[, <partition_key>=<partition_value>, …])
SELECT <select_statement>;
– 追加写入
INSERT INTO TABLE <table_name>
PARTITION (<partition_key>=<partition_value>[, <partition_key>=<partition_value>, …])
SELECT <select_statement>;
3.添加分区:
//只能添加分区列的值,不能添加分区列,如果是多个分区列,不能单独添加其中一个
alter table tablename add partition(col=value)
4.删除分区:
//可以删除一个分区列,但是会把表中所有包含当前分区列的数据全部删除
alter table tablename drop partition(col=value)
5.修复分区:
//手动向hdfs中创建分区目录,添加数据,创建好hive的外表之后,无法加载数据,
//元数据中没有相应的记录
msck repair table tablename
6.动态分区创建:
创建方式与静态分区表完全一样,一张表可同时被静态分区和动态分区键分区,只是动态分区键需要放在静态分区键的后面(HDFS上的动态分区目录下不能包含静态分区的子目录),如下spk即static partition key(静态分区键),dpk为dynamic partition key(动态分区键)
CREATE TABLE <table_name>
PARTITIONED BY ([ <data_type>, … ,] <data_type>, [
<data_type>,…]);
7.动态分区写入:
根据表中的某一个列值来确定hdfs存储的目录:
优点:
动态可变,不需要人为控制。假如设定的是日期,那么每一天的数据会单独存储在一个文件夹中
缺点:
需要依靠MR完成,执行比较慢
静态分区键要用 = 指定分区值;动态分区只需要给出分出分区键名称 。
– 开启动态分区支持,并设置最大分区数
set hive.exec.dynamic.partition=true;
//set hive.exec.dynamic.partition.mode=nostrict;
set hive.exec.max.dynamic.partitions=2000;
insert into table1 select 普通字段 分区字段 from table2
范围分区:
单值分区每个分区对应于分区键的一个取值,而每个范围分区则对应分区键的一个区间,只要落在指定区间内的记录都被存储在对应的分区下。分区范围需要手动指定,分区的范围为前闭后开区间 [最小值, 最大值)。最后出现的分区可以使用 MAXVALUE 作为上限,MAXVALUE 代表该分区键的数据类型所允许的最大值。
CREATE [EXTERNAL] TABLE <table_name>
(<col_name> <data_type>, <col_name> <data_type>, …)
PARTITIONED BY RANGE (<partition_key> <data_type>, …)
(PARTITION [<partition_name>] VALUES LESS THAN (),
[PARTITION [<partition_name>] VALUES LESS THAN (),
…
]
PARTITION [<partition_name>] VALUES LESS THAN (|MAXVALUE)
)
[ROW FORMAT <row_format>] [STORED AS TEXTFILE|ORC|CSVFILE]
[LOCATION ‘<file_path>’]
[TBLPROPERTIES (‘<property_name>’=‘<property_value>’, …)];
多个范围分区键的情况:
DROP TABLE IF EXISTS test_demo;
CREATE TABLE test_demo (value INT)
PARTITIONED BY RANGE (id1 INT, id2 INT, id3 INT)
(
– id1在(–∞,5]之间,id2在(-∞,105]之间,id3在(-∞,205]之间
PARTITION p5_105_205 VALUES LESS THAN (5, 105, 205),
– id1在(–∞,5]之间,id2在(-∞,105]之间,id3在(205,215]之间
PARTITION p5_105_215 VALUES LESS THAN (5, 105, 215),
PARTITION p5_115_max VALUES LESS THAN (5, 115, MAXVALUE),
PARTITION p10_115_205 VALUES LESS THAN (10, 115, 205),
PARTITION p10_115_215 VALUES LESS THAN (10, 115, 215),
PARTITION pall_max values less than (MAXVALUE, MAXVALUE, MAXVALUE)
);
分桶:
对Hive(Inceptor)表分桶可以将表中记录按分桶键的哈希值分散进多个文件中,这些小文件称为桶。
1.创建分桶表:
分桶表的建表有三种方式:直接建表,CREATE TABLE LIKE 和 CREATE TABLE AS SELECT ,单值分区表不能用 CREATE TABLE AS SELECT 建表。这里以直接建表为例:
CREATE [EXTERNAL] TABLE <table_name>
(<col_name> <data_type> [, <col_name> <data_type> …])]
[PARTITIONED BY …]
CLUSTERED BY (<col_name>)
[SORTED BY (<col_name> [ASC|DESC] [, <col_name> [ASC|DESC]…])]
INTO <num_buckets> BUCKETS
[ROW FORMAT <row_format>]
[STORED AS TEXTFILE|ORC|CSVFILE]
[LOCATION '<file_path>']
[TBLPROPERTIES ('<property_name>'='<property_value>', ...)];
分桶键只能有一个即<col_name>。表可以同时分区和分桶,当表分区时,每个分区下都会有<num_buckets> 个桶。我们也可以选择使用 SORTED BY … 在桶内排序,排序键和分桶键无需相同。ASC 为升序选项,DESC 为降序选项,默认排序方式是升序。<num_buckets> 指定分桶个数,也就是表目录下小文件的个数。
2.向分桶表中写数据:
因为分桶表在创建的时候只会定义Scheme,且写入数据的时候不会自动进行分桶、排序,需要人工先进行分桶、排序后再写入数据。确保目标表中的数据和它定义的分布一致。
目前有两种方式往分桶表中插入数据:
方法一:打开enforce bucketing开关。
SET hive.enforce.bucketing=true;
INSERT (INTO|OVERWRITE) TABLE <bucketed_table> SELECT <select_statement>
[SORT BY <sort_key> [ASC|DESC], [<sort_key> [ASC|DESC], …]];
方法二:将reducer个数设置为目标表的桶数,并在 SELECT 语句中用 DISTRIBUTE BY <bucket_key>对查询结果按目标表的分桶键分进reducer中。
SET mapred.reduce.tasks = <num_buckets>;
INSERT (INTO|OVERWRITE) TABLE <bucketed_table>
SELECT <select_statement>
DISTRIBUTE BY <bucket_key>, [<bucket_key>, …]
[SORT BY <sort_key> [ASC|DESC], [<sort_key> [ASC|DESC], …]];
如果分桶表创建时定义了排序键,那么数据不仅要分桶,还要排序
如果分桶键和排序键不同,且按降序排列,使用Distribute by … Sort by分桶排序
如果分桶键和排序键相同,且按升序排列(默认),使用 Cluster by 分桶排序,即如下:
SET mapred.reduce.tasks = <num_buckets>;
INSERT (INTO|OVERWRITE) TABLE <bucketed_table>
SELECT <select_statement>
CLUSTER BY <bucket_sort_key>, [<bucket_sort_key>, …];
抽样语句 :tablesample(bucket x out of y)
tablesample是抽样语句,语法:tablesample(bucket x out of y),y必须是table总共bucket数的倍数或者因子。Hive根据y的大小,决定抽样的比例。例如:table总共分了64份,当y=32时,抽取2(64/32)个bucket的数据,当y=128时,抽取1/2(64/128)个bucket的数据。x表示从哪个bucket开始抽取。例如:table总共bucket数为32,tablesample(bucket 3 out of 16)表示总共抽取2(32/16)个bucket的数据,分别为第三个bucket和第19(3+16)个bucket的数据。
19、如何对十亿数据进行去重统计?
一.思考问题
10亿数据,以每条数据按150个字符算,一共需要139g的内存,所以只能采用分而治之的思想;
如果在读取数据库过程中因为某种原因程序中断,难道需要再从头开始处理吗?
二.大致方案
采用流式读取,分批次进行处理,比如每次读取大约3个g内存的数据(每一次将这一批处理完的最后一个数据id进行保存到本地,以便程序中断后,从当前数据开始处理)
将某一个字段进行哈希映射(得到哈希值对500取余即可),映射到500个文件中,每个文件大概300m,将数据ID和对应数据去重字段的MD5值保存到对应文件中.
依次处理每个小文件(相互重复的数据一定在一个文件中),利用Map进行去重.将重复数据进行删除.
(注意这里有个小问题,如果真的是程序中断进行二次处理,则同一个数据可能被再次处理,即在一个文件中存储两次,因为我们之前只保存了了每一批数据的最后一个数据id,所以在判断去重字段的MD5值一样后还需要判断数据id是否一致)
20、大数据架构设计都考虑哪些方面?
21、公司所用组件版本?
22、Flink 如何实现 Exactly-once 语义?
Flink依靠checkpoint机制来实现exactly-once语义,如果要实现端到端的exactly-once,还需要外部source和sink满足一定的条件。状态的存储通过状态后端来管理,Flink中可以配置不同的状态后端。
从两方面回答:
一,Flink应用程序内部的exactly-once
二,端到端一致性
当在分布式系统中引入状态时,自然也引入了一致性问题。一致性实际上是"正确性级别"的另一种说法,也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少?如果有偏差,是有漏掉的计数还是重复计数?所以根据实际情况就可以对一致性设定不同的级别
一致性级别
在流处理中,一致性可以分为3个级别:
at-most-once: 这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可 能丢失。同样的还有udp。
at-least-once: 这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说, 计数程序在发生故障后可能多算,但是绝不会少算。
exactly-once: 这指的是系统保证在发生故障后得到的计数结果与正确值一致。
曾经,at-least-once非常流行。第一代流处理器(如Storm和Samza)刚问世时只保证at-least-once,原因有二。
保证exactly-once的系统实现起来更复杂。这在基础架构层(决定什么代表正确,以 及exactly-once的范围是什么)和实现层都很有挑战性。
流处理系统的早期用户愿意接受框架的局限性,并在应用层想办法弥补(例如使应 用程序具有幂等性,或者用批量计算层再做一遍计算)。
最先保证exactly-once的系统(Storm Trident和Spark Streaming)在性能和表现力这两个方面付出了很大的代价。为了保证exactly-once,这些系统无法单独地对每条记录运用应用逻辑,而是同时处理多条(一批)记录,保证对每一批的处理要么全部成功,要么全部失败。这就导致在得到结果前,必须等待一批记录处理结束。因此,用户经常不得不使用两个流处理框架(一个用来保证exactly-once,另一个用来对每个元素做低延迟处理),结果使基础设施更加复杂。曾经,用户不得不在保证exactly-once与获得低延迟和效率之间权衡利弊。Flink避免了这种权衡。
Flink的一个重大价值在于,它既保证了exactly-once,也具有低延迟和高吞吐的处理能力。
从根本上说,Flink通过使自身满足所有需求来避免权衡,它是业界的一次意义重大的技术飞跃。尽管这在外行看来很神奇,但是一旦了解,就会恍然大悟。
端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。
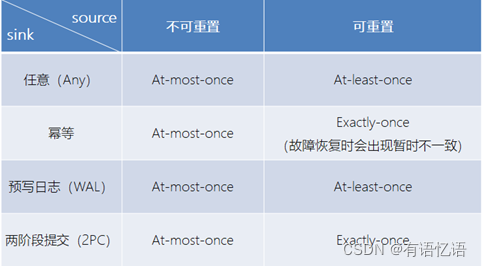
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。 具体可以划分如下:
source端 —— 需要外部源可重设数据的读取位置
flink内部 —— 依赖checkpoint
sink端 —— 需要保证从故障恢复时,数据不会重复写入外部系统
而对于sink端,又有两种具体的实现方式:幂等(Idempotent)写入和事务性(Transactional)写入。
幂等写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
事务写入
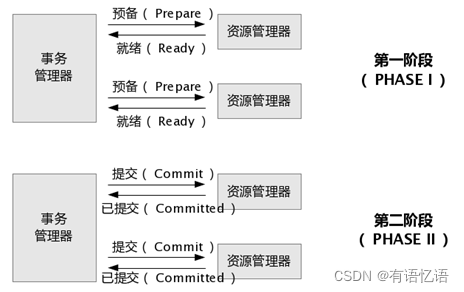
需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)。
DataStream API 提供了GenericWriteAheadSink模板类和TwoPhaseCommitSinkFunction 接口,可以方便地实现这两种方式的事务性写入。
不同 Source 和 Sink 的一致性保证可以用下表说明:
Flink具体如何保证exactly-once呢? 它使用一种被称为"检查点"(checkpoint)的特性,在出现故障时将系统重置回正确状态。
Flink的检查点算法
Flink检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。记住这一基本点之后,Flink为用户提供了用来定义状态的工具。
val dataDS: DataStream[String] = env.readTextFile("input/data.txt")
val mapDS: DataStream[(String, String, String)] = dataDS.map(data => {
val datas = data.split(",")
(datas(0), datas(1), datas(2))
})
val keyDS: KeyedStream[(String, String, String), Tuple] = mapDS.keyBy(0)
keyDS.mapWithState{
case ( t, buffer ) => {
(t, buffer)
}
}
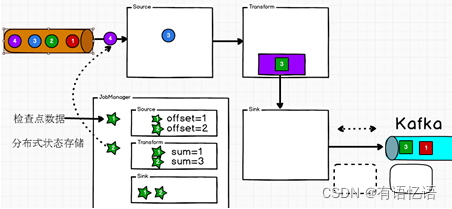
我们用一个图形来看检查点是如何运行的:
Flink检查点算法的正式名称是异步分界线快照(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport分布式快照算法。检查点是Flink最有价值的创新之一,因为它使Flink可以保证exactly-once,并且不需要牺牲性能。
Flink+Kafka如何实现端到端的Exactly-Once语义
我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于Flink + Kafka的数据管道系统(Kafka进、Kafka出)而言,各组件怎样保证exactly-once语义呢?
内部 —— 利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
source —— kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
sink —— kafka producer作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
内部的checkpoint机制我们已经有了了解,那source和sink具体又是怎样运行的呢?接下来我们逐步做一个分析。
我们知道Flink由JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。
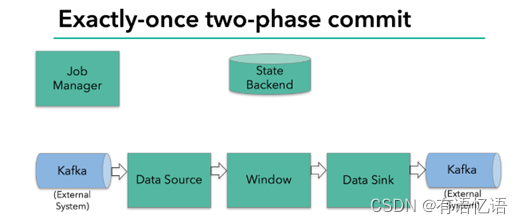
当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流;barrier会在算子间传递下去。
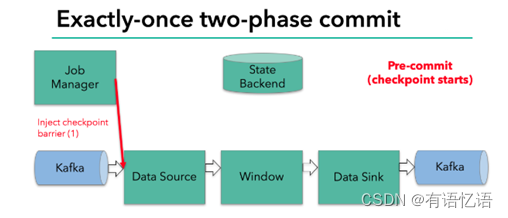
每个算子会对当前的状态做个快照,保存到状态后端。对于source任务而言,就会把当前的offset作为状态保存起来。下次从checkpoint恢复时,source任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。

每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里。
sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务(还不能被消费);当遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务。
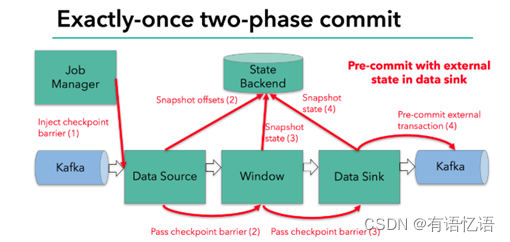
当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成。
当sink 任务收到确认通知,就会正式提交之前的事务,kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了。
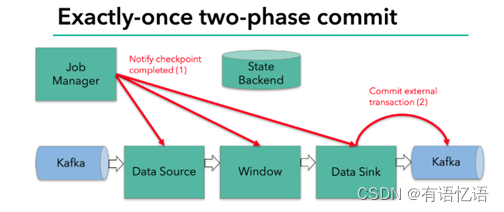
所以我们看到,执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
具体的两阶段提交步骤总结如下:
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
- jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了。
23、Flink 时间类型的分类和各自的实现原理?
24、Flink 如何处理数据乱序和延迟?

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)