insert into/overwrite table xxx partition(dt=xxx) select xxx from tmp;语句执行成功,但插入失败
报错信息在hive 中执行insert into/overwrite table dwd_xxx partition(dt=xxx) select xxx from tmp语句,发现插入失败,其中dwd_xxx存储格式为parquet,tmp存储格式为textfile。问题排查思路查日志,一般查两个日志第一个为hive.log => 缺省情况下 /tmp/root/hive.log (hiv
报错信息
在hive 中执行insert into/overwrite table dwd_xxx partition(dt=xxx) select xxx from tmp语句,发现插入失败,其中dwd_xxx存储格式为parquet,tmp存储格式为textfile。
问题排查思路
-
查日志,一般查两个日志第一个为hive.log => 缺省情况下 /tmp/root/hive.log (hive-site.conf),第二个为MR的日志 => 启动historyserver、日志聚合 + SQL运行在集群模式。
-
排查jobhistory日志未发现报错信息,排查hive.log未发现报错信息。
-
关闭hive的local模式,重新运行,查看jobhistory报错信息发现报错java.lang.reflect.InvocationTargetException/java.lang.NullPointException错误。

-
上述报错信息无明显定位,实际作用不大。将hive的执行引擎由mr替换为tez,set hive.execution.engine=tez;执行语句时报错Exception in thread main java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfiguration,在~/.bashrc中加入
for jar in `ls $TEZ_HOME |grep jar`; do
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$TEZ_HOME/lib/$jar
done
然后source ~/.bashrc;
5.重新执行insert into … select…语句报错xxx is running beyond virtual memory limits. Current usage:201.9MB of 1GB physical memory used; 2.6GB of 2.1 GB virtual memory used. Killing container.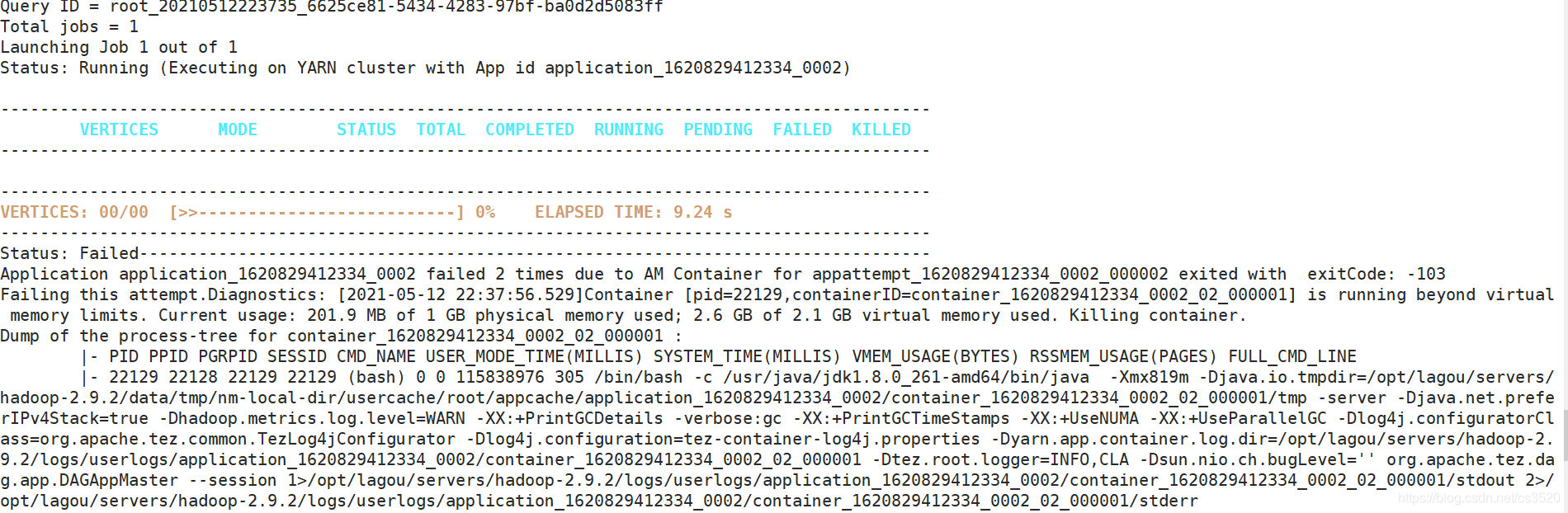
6.经查yarn虚拟内存不足,cd $HADOOP_HOME/conf/hadoop,修改yarn-site.xml,加个配置
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
</property>
7.再次运行即可,上面扩展5倍后有可能还是执行不成功,这时候试试改写sql语句,先做select,将结果插入临时表,再将临时表的内容插入dwd。
改写前
insert overwrite table dwd_xxx
partition(dt='$do_date')
select * from ods_xxx where ...
改写后
create table tmp.tmp_xxx as
( select *from ods_xxx where...);
insert overwrite table dwd_xxx
partition(dt='$do_date')
select * from tmp_xxx;
相当于中间数据落盘,减少内存消耗。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)