es查询时MatchPhraseQueryBuilder和MatchQueryBuilder时的一些分词查询问题
es查询时MatchPhraseQueryBuilder和MatchQueryBuilder时的一些分词查询问题当你的es库没有设置查询时分词和存储时分词时一、采用默认设置建立的索引1、使用**MatchQueryBuilder**查询es时2、使用**MatchQueryBuilder**查询es时二、采用设置了查询时分词和存储字段时分词的配置后建立的索引当你的es库没有设置查询时分词和存储时分
es查询时MatchPhraseQueryBuilder和MatchQueryBuilder时的一些分词查询问题
当es库没有设置查询时分词和存储时分词时
一、采用默认设置建立的索引
图片:
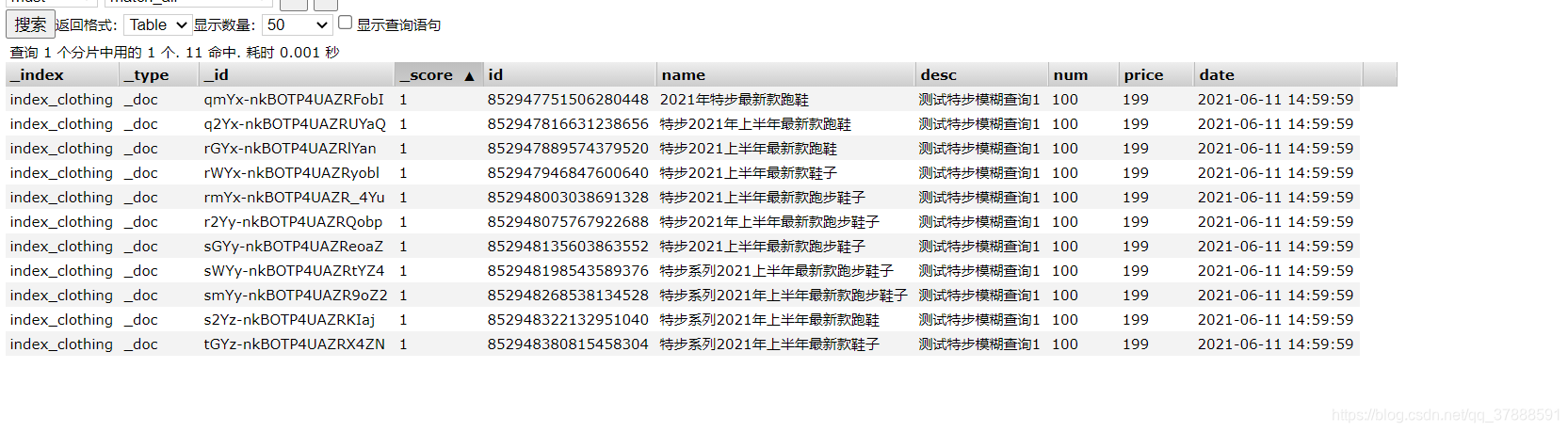
1、使用MatchQueryBuilder查询es时
@Test
public void searchTest() throws IOException{
// SearchResponse response = service.search("name", "shoes-0-num", 0, 30, "idx_clouthing");//特步2021最新款跑鞋
// SearchResponse response = service.search("name", "特步2021最新款跑鞋", 0, 100, "index_cloth");
SearchResponse response = service.search("name", "特步2021上半年最新款跑鞋", 0, 30, "index_clothing");
SimpleDateFormat sim = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Arrays.asList(response.getHits().getHits())
.forEach(e -> {
Object object = e.getSourceAsMap().get("date");
String time = (String) object;
Date date;
if (StringUtils.isNotBlank(time)){
try {
date = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").parse(time);
time = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").format(date);
} catch (ParseException ex) {
ex.printStackTrace();
}
}
// DateTime dateTime = new DateTime(object);
// long millis = dateTime.getMillis();
// Date date = new Date(millis);
// String format = sim.format(date);
log.info("文档:{},date:{}",e.getSourceAsString(),time);
});
}
- 采用standard默认分词器进行查询
结果是:
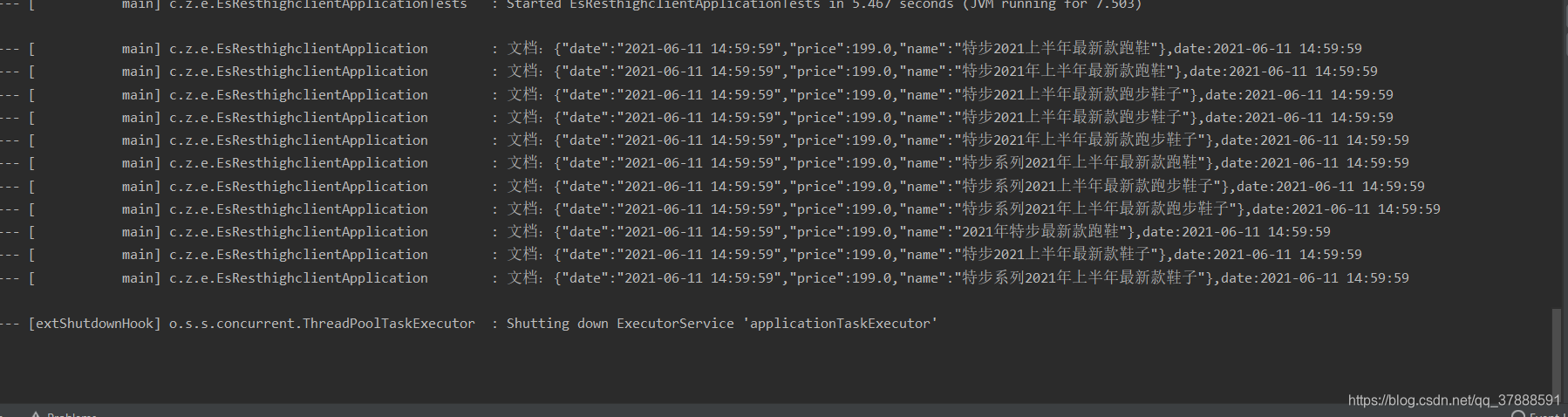
从这里可以看到,全部查询回来了,再查询一下要查询的条件在默认分词下分词的结果
@Test
public void getAnalyzerWordsTest() throws IOException {
String indexName = "index_clothing";
// String analyzer = "ik_smart";
String analyzer = "standard";
String phrase = "特步2021上半年最新款跑鞋";
//全局分词
// List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getAnalyzeWordsGlobal(analyzer, phrase);
//某索引下采用默认分词器对短语的分词结果
// List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getAnalyzeWordsWithFiled(indexName,phrase,"name");
//某索引下采用某种分词器后的短语分词结果
List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getAnalyzeWordsWithIndex(indexName,phrase,analyzer);
//需要自定义设置keyword的属性normalizer,是对 keyword生成的单一 Term再做进一步的处理,比如 lowercase,即做小写变换
// List<AnalyzeResponse.AnalyzeToken> analyzeWordsGlobal = service.getNormalizerWords(indexName,analyzer,phrase);
analyzeWordsGlobal.forEach(data ->{
log.info("分词结果:{}",data.getTerm());
});
}
查询条件的分词代码
/**
* 返回某索引内某个短语在某种分词器下的结果
* @param indexName 索引名
* @param phrase 要分词的短语
* @param analyzer 分词器类型
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getAnalyzeWordsWithIndex(String indexName, String phrase, String analyzer) throws IOException {
AnalyzeRequest request = AnalyzeRequest.withIndexAnalyzer(indexName,analyzer,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
/**
* 返回某索引内某个短语在某个字段下的分词结果
* @param indexName 索引名
* @param phrase 要分词的短语
* @param field 分词字段
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getAnalyzeWordsWithFiled(String indexName, String phrase, String field) throws IOException {
AnalyzeRequest request = AnalyzeRequest.withField(indexName,field,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
/**
* 返回某个短语在所有索引下某分词器类型下的分词结果
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getAnalyzeWordsGlobal(String analyzer, String ... phrase) throws IOException {
AnalyzeRequest request = AnalyzeRequest.withGlobalAnalyzer(analyzer,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
/**
* 返回某个短语在某索引下某Normalizer类型下的分词结果
* @param indexName 索引名
* @param analyzer 分词器类型
* @param phrase 要分词的短语
* @return
* @throws IOException
*/
public List<AnalyzeResponse.AnalyzeToken> getNormalizerWords(String indexName, String analyzer,String ... phrase) throws IOException {
//normalizer是 keyword的一个属性,可以对 keyword生成的单一 Term再做进一步的处理,比如 lowercase,即做小写变换。使用方法和自定义分词器有些类似,需要自定义
AnalyzeRequest request = AnalyzeRequest.withNormalizer(indexName,analyzer,phrase);
List<AnalyzeResponse.AnalyzeToken> tokens = client.indices().analyze(request, RequestOptions.DEFAULT).getTokens();
return tokens;
}
这里面大概主要用的是前两种,
下面就是默认分词器下的结果:
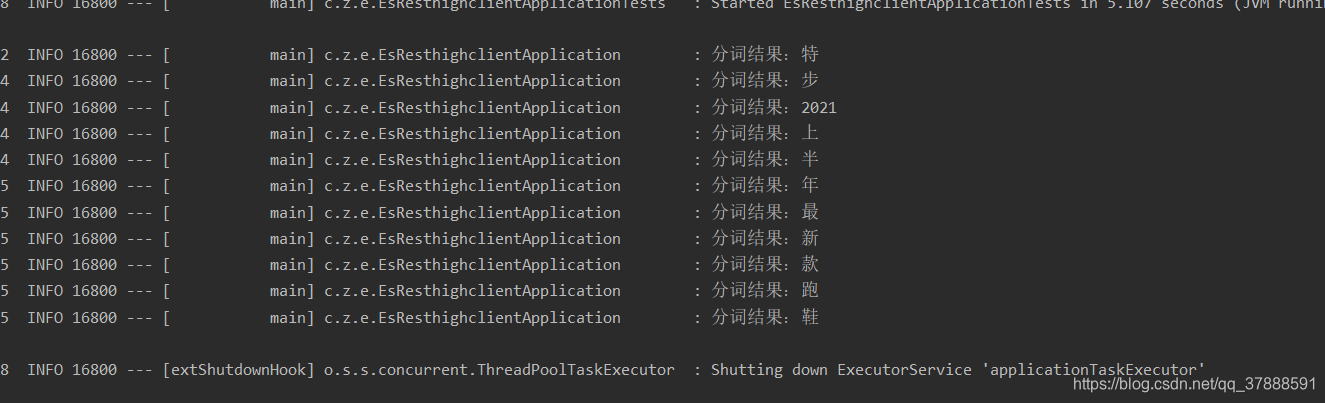
可以看出来基本上是按中文的个数分出来的,并且短语中的中文的顺序好像对结果没有啥影响

这里也可以用kibana来查询关键词的分词效果
kibana语句:
POST /index_clothing/_analyze
{
"field": "name",
"text": "2021特步上半年最新款跑鞋"
}
字段说明:
filed:对标test索引中哪个字段,默认使用与该字段相同的分词器
text:需要分词的关键词内容
也可以自定义 该字段使用哪个分词器 “analyzer”: “ik_smart”
分词结果:
{
"tokens" : [
{
"token" : "2021",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "特",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "步",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "上",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "半",
"start_offset" : 7,
"end_offset" : 8,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "年",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "最",
"start_offset" : 9,
"end_offset" : 10,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "新",
"start_offset" : 10,
"end_offset" : 11,
"type" : "<IDEOGRAPHIC>",
"position" : 7
},
{
"token" : "款",
"start_offset" : 11,
"end_offset" : 12,
"type" : "<IDEOGRAPHIC>",
"position" : 8
},
{
"token" : "跑",
"start_offset" : 12,
"end_offset" : 13,
"type" : "<IDEOGRAPHIC>",
"position" : 9
},
{
"token" : "鞋",
"start_offset" : 13,
"end_offset" : 14,
"type" : "<IDEOGRAPHIC>",
"position" : 10
}
]
}
这里注意:分词结果里面有position,这应该就是分词后的词的位置,start_offset和end_offset就是起始位置差,后面的slop参数的大小应该跟这个有关,但是在standard下面无法起作用。
综合来看,默认分词方式下,查询关键词的顺序跟结果没有什么关系,只要待查询的字段里面分词后含有该关键词分词后的某一个词,就能查询出来,
所以这种方法好像有点不符合实际的需求!
-
采用ik_max_word分词器进行查询,
它会按中文的最细粒度进行分词,结果如下
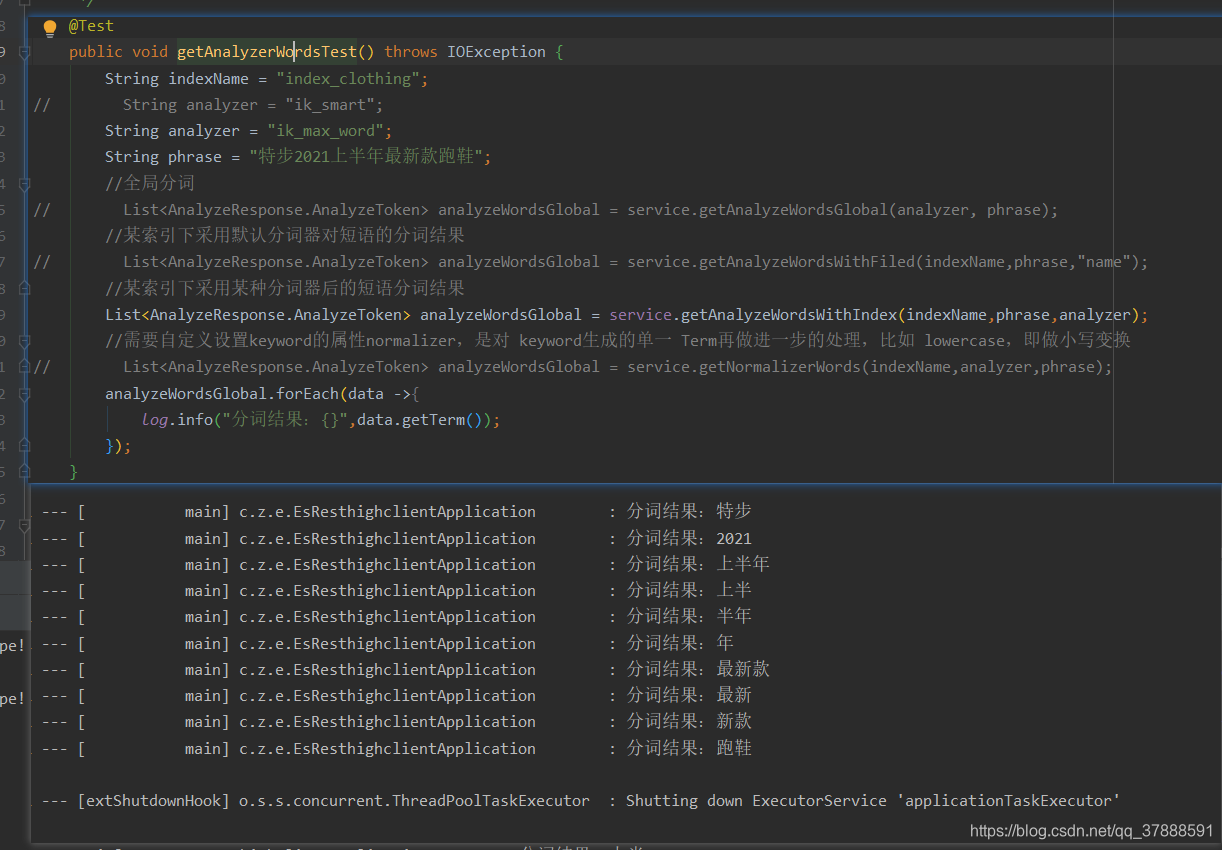
查询条件及结果:
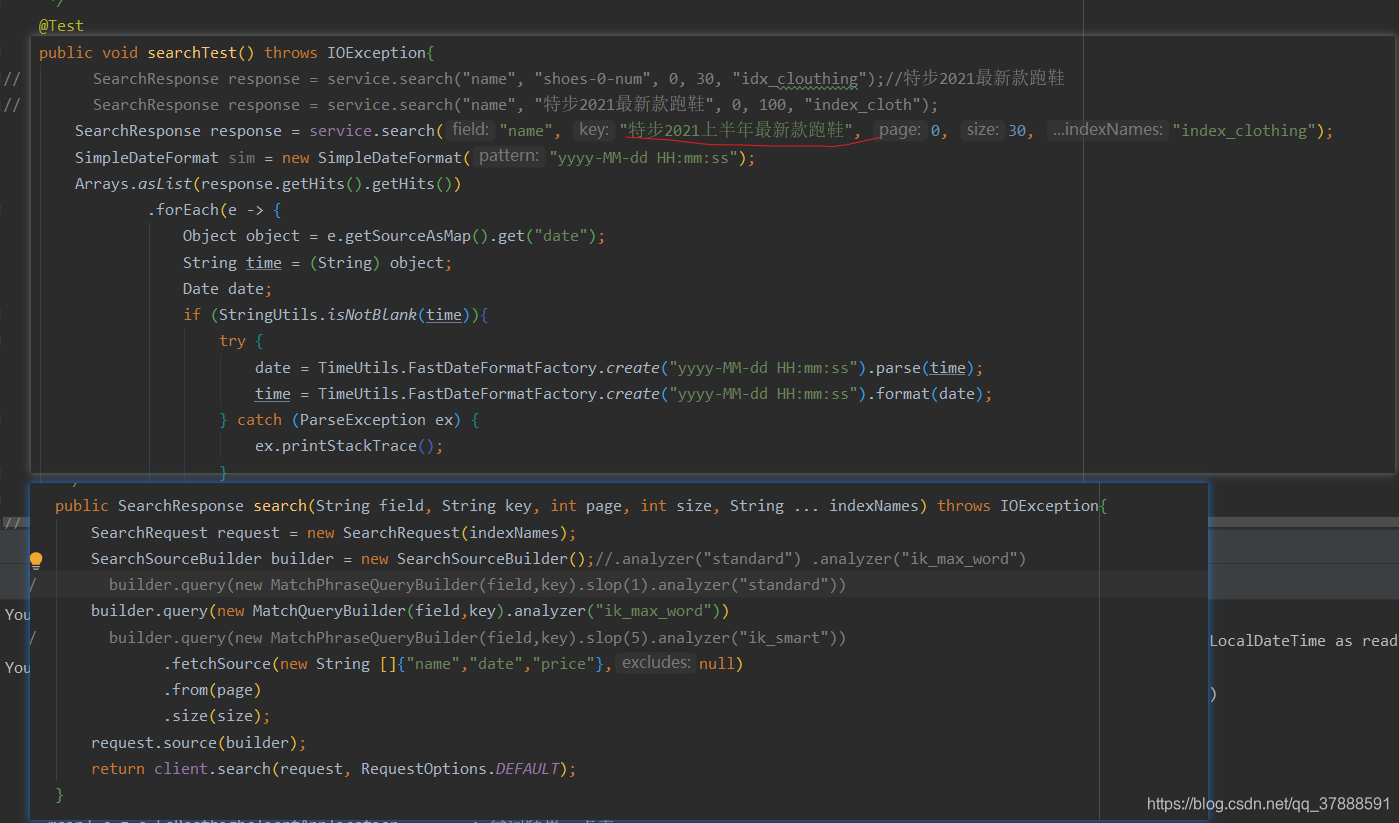
结果:
结果跟第一种没有区别,
调换短语顺序后结果没有区别 -
采用ik_smart分词器进行查询,
它会按照常见的短语组合词进行分词,并且可以在ik插件中自定义短语词,例如‘666’,‘老铁’ 这种非传统的中文词组,ik分词器需要的可以自己去安装配置。
查询短语分词结果:

里面的test.dic文件是我自定义的词典
查询结果:
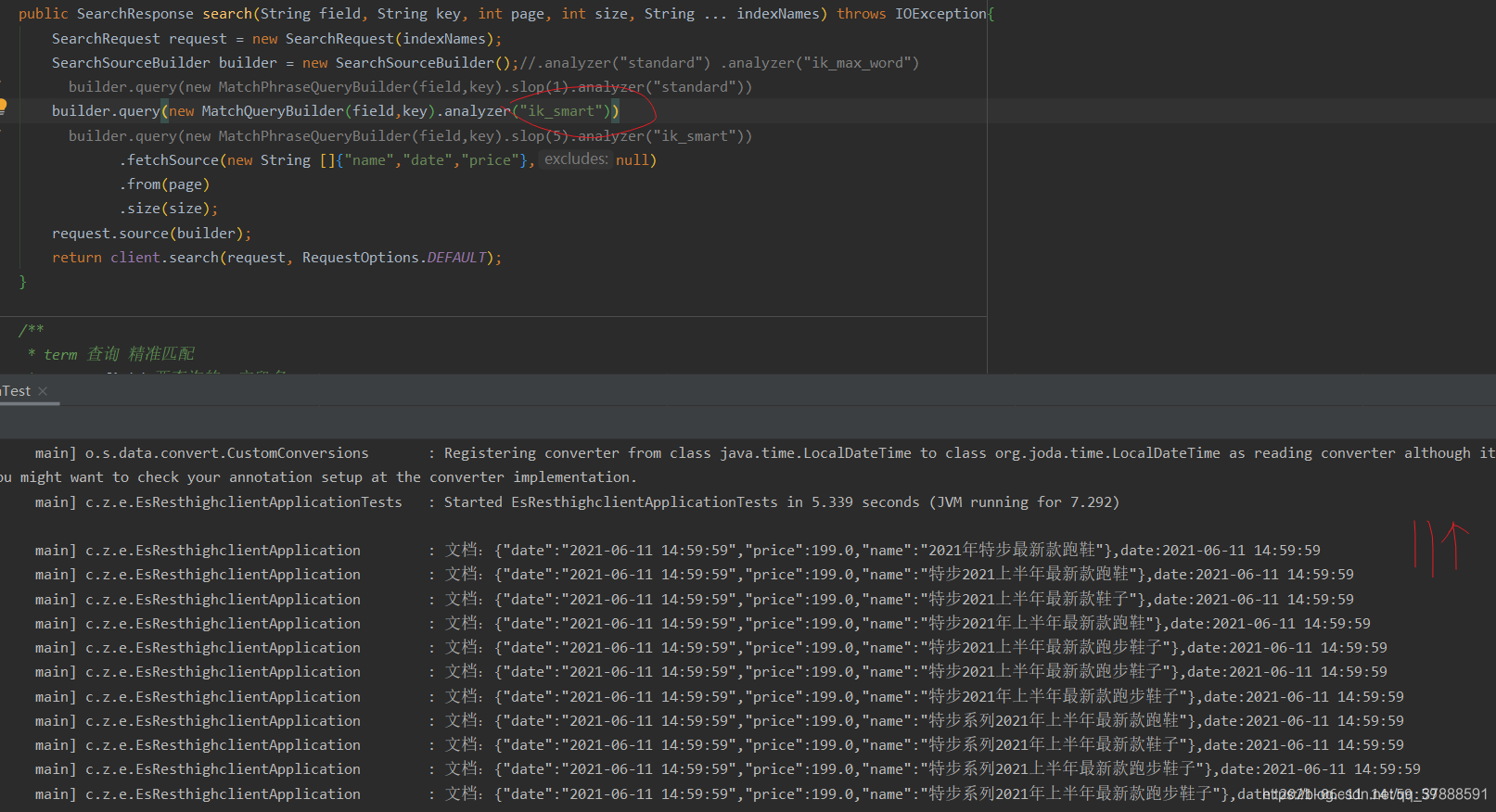
好像结果都是一样的。
从这里可以看出MatchQueryBuilder下三种分词结果差不多
2、使用MatchPhraseQueryBuilder查询es时
-
采用standard 查询es
这里短语分词是一样的,就不在贴图了,直接贴查询结果。

调换短语顺序后查询,比如 “步特2021上半年最新款跑鞋”,发现没有结果
,但是当设置了slop参数之后,可以查询到8条数据,如图:
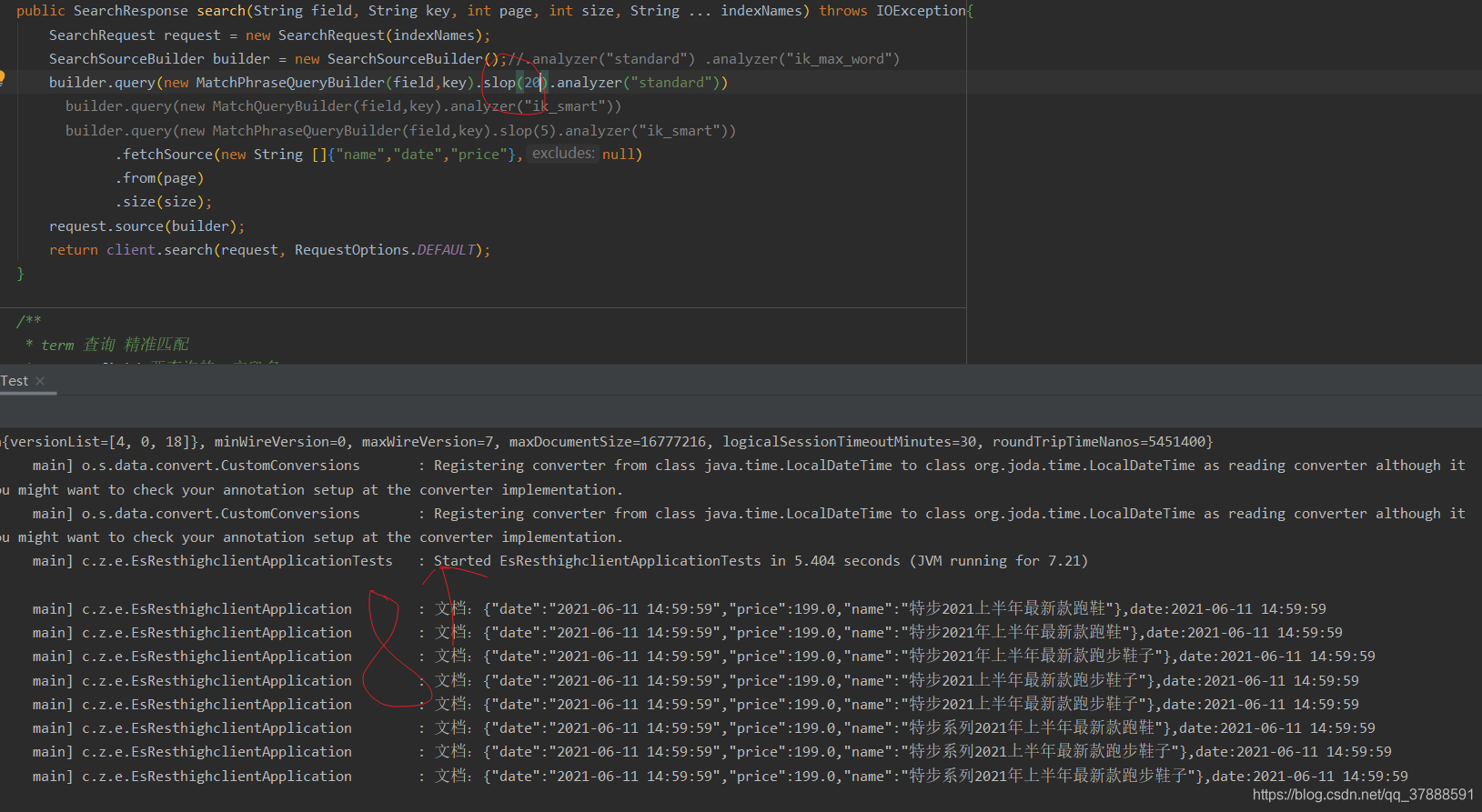
作用:
match_phrase 的作用,匹配到的文档中必须
包含"特步2021上半年最新款跑鞋"而且顺序间隔必须跟输入的内容保持一致.
那如果我想文档中只要包含"特步2021上半年最新款跑鞋",但是他们之间能隔着一些单词呢?比如"特步2021年上半年最新款跑鞋",这个时候就需要靠参数来控制了,这个参数就是 slop,slop 的数值意味着
你输入的短语中每个词项(term)之间允许隔着几个词项(term)。
大概作用就是2021和上半年 这两个词不用挨在一起了,如果上半年分词后的位置比2021分词后的位置在20个单位之内,还是可以正常查询出来(当然这个里面的参数数字可以自己定义,根据自己合适的大小去用,想了解更多的可以去google),standard分词器的情况下,调换两个词的顺序是没有问题的,结果是一样的
-
采用ik_max_word 查询es
查询结果:
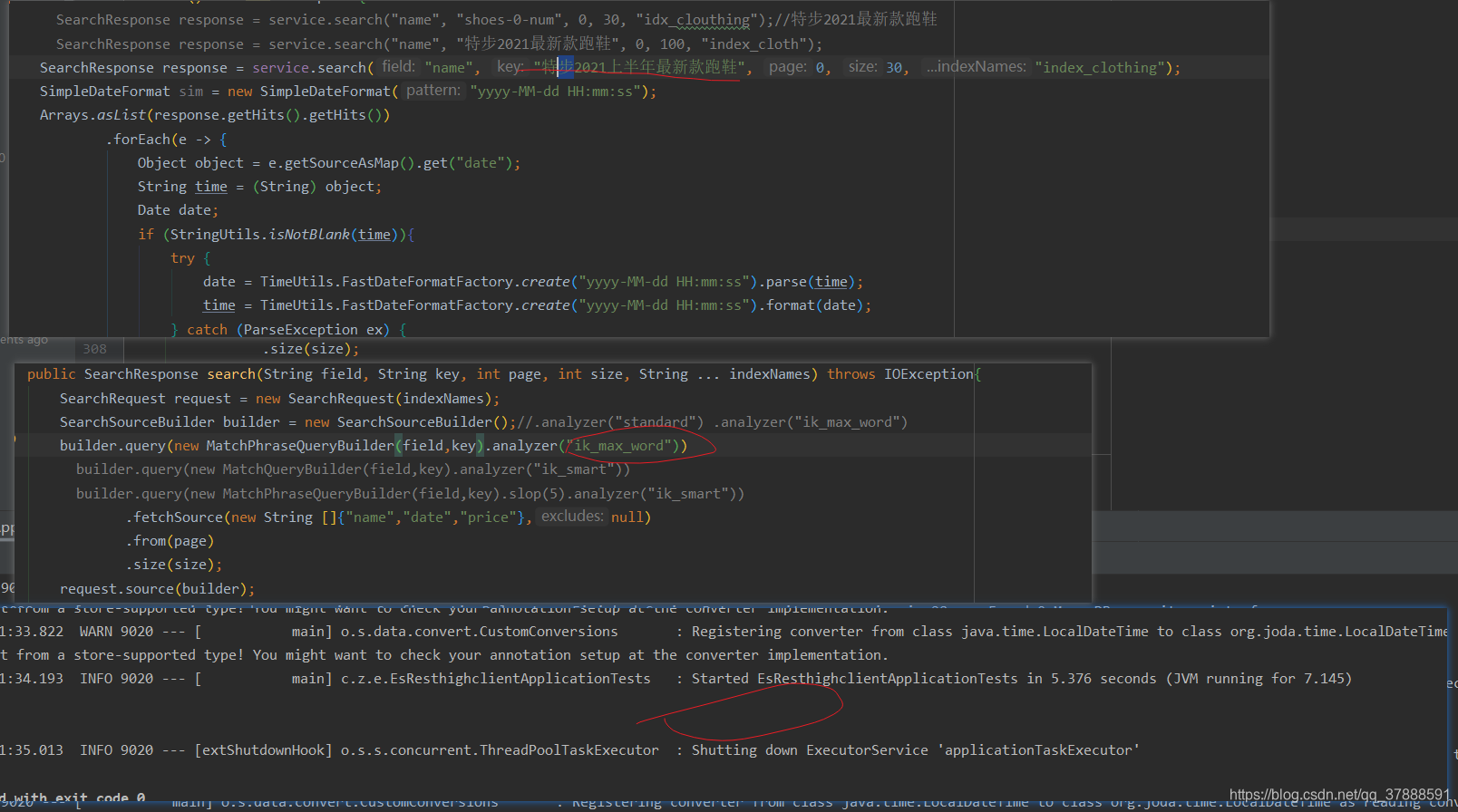
加入slop参数后,还是没有查询到结果,调换查询短语的顺序还是查询不到 -
采用ik_smart 查询es
查询结果:为空
加入slop参数后,为空
没有设置查询分词索引和存储时的分词配置的es库,查询时,从以上测试结果来看,
standard分词方式下加slop参数后能查到数据,但ik_max_word和ik_smart两种方式为啥加了slop方式却没有查 询到数据,个人感觉是因为索引是按照standard默认方式分词的,但因为我配置了ik分词器和中文自定义词典,导致查询时的关键词分词后没有索引自己分词后的结果词,
设置了默认分词的字段本身索引和查询关键词的分词对比图如下:

所以用默认分词方式加上slop参数能够查询到 ,因为他们的分词结果是一样的,而后两种分词方式,字段分词后是找不到某些分词结果,而 MatchPhraseQueryBuilder 查询时,查询短语分词结果必须按照在字段中本身的先后顺序,
所以 按照一般实际情况,采用MatchPhraseQueryBuilder 加上 默认的分词器就好了
采用设置了查询时分词和存储字段时分词的配置后建立的索引库
一、当es库对某些字段采用搜索时关键词进行ik分词索引和字段存储在es中时索引配置后设置建立的索引
我建立索引时的kibana命令:
PUT /index_cloth
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 1,
"max_result_window" : 100000000
},
"analysis": {
"analyzer": {
"default": {
"type": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "keyword",
"ignore_above" : 32
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"price": {
"type": "float"
},
"num": {
"type": "integer"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
建立后的索引信息:

索引信息代码:
{
"state": "open",
"settings": {
"index": {
"number_of_shards": "5",
"provided_name": "index_cloth",
"max_result_window": "100000000",
"creation_date": "1623210850009",
"analysis": {
"analyzer": {
"default": {
"type": "ik_smart"
}
}
},
"number_of_replicas": "1",
"uuid": "POi7MdwZR-eq4-i7rglWUQ",
"version": {
"created": "7060199"
}
}
},
"mappings": {
"_doc": {
"properties": {
"date": {
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis",
"type": "date"
},
"price": {
"type": "float"
},
"num": {
"type": "integer"
},
"name": {
"search_analyzer": "ik_smart",
"analyzer": "ik_max_word",
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"id": {
"ignore_above": 32,
"type": "keyword"
},
"desc": {
"search_analyzer": "ik_smart",
"analyzer": "ik_max_word",
"type": "text"
}
}
}
},
"aliases": [ ],
"primary_terms": {
"0": 6,
"1": 6,
"2": 6,
"3": 6,
"4": 6
},
"in_sync_allocations": {
"0": [
"XPGwry8cRDCxaMXY8fY68w"
],
"1": [
"NdRuwJVzSlWI8xOyRgSO8A"
],
"2": [
"jYgFnX7NRR2fy0QWxwCe8g"
],
"3": [
"zJGltD4YRBe5-bzq48-_SQ"
],
"4": [
"cINi0SkqQhGhhNFnL7aMIA"
]
}
}
图片:

总共12条数据
1、使用MatchQueryBuilder查询es时
@Test
public void searchTest() throws IOException{
// SearchResponse response = service.search("name", "shoes-0-num", 0, 30, "idx_clouthing");//特步2021最新款跑鞋
// SearchResponse response = service.search("name", "特步2021最新款跑鞋", 0, 100, "index_cloth");
SearchResponse response = service.search("name", "特步2021上半年最新款跑鞋", 0, 30, "index_cloth");
SimpleDateFormat sim = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Arrays.asList(response.getHits().getHits())
.forEach(e -> {
Object object = e.getSourceAsMap().get("date");
String time = (String) object;
Date date;
if (StringUtils.isNotBlank(time)){
try {
date = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").parse(time);
time = TimeUtils.FastDateFormatFactory.create("yyyy-MM-dd HH:mm:ss").format(date);
} catch (ParseException ex) {
ex.printStackTrace();
}
}
// DateTime dateTime = new DateTime(object);
// long millis = dateTime.getMillis();
// Date date = new Date(millis);
// String format = sim.format(date);
log.info("文档:{},date:{}",e.getSourceAsString(),time);
});
log.info("总个数:{}",response.getHits().getTotalHits().value);
}
- 采用standard默认分词器进行查询
结果是:
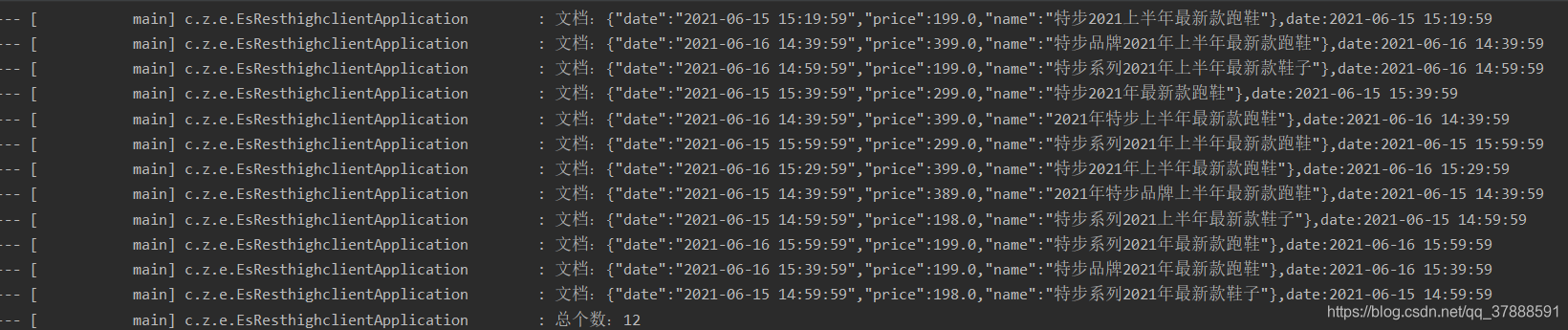
从这里可以看到,全部查询回来了,再查询一下要查询的条件在默认分词下分词的结果,发现
这里的关键词分词结果跟没有设置索引配置的库是一样的。
standard查询条件的结果 —》结论:
跟默认配置的索引库查询结果一致,并且短语中的中文的顺序好像对结果没有啥影响,并且只要查询关键词含有字段文本中的某一个词,就能查询到,这样范围查询太广,
所以这种方法也不符合实际的需求!
-
采用ik_max_word分词器进行查询,
它会按中文的最细粒度进行分词,结果如下
分词结果跟没有配置存储时设置分词方式的结果是一样的,没有变化
查询结果:
跟上面standard一样,调换短语顺序和少几个词对结果也没有影响。 -
采用ik_smart分词器进行查询,
它会按照常见的短语组合词进行分词,并且可以在ik插件中自定义短语词,例如‘666’,‘老铁’ 这种非传统的中文词组,ik分词器需要的可以自己去安装配置。
查询短语分词结果和查询结果一致,
从这里可以看出MatchQueryBuilder下三种分词结果差不多,与没有设置查询分词方式的索引库查询结果类似
2、使用MatchPhraseQueryBuilder查询es时
- 采用standard 查询es
查询语句:
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();//.analyzer("standard") .analyzer("ik_max_word")
builder.query(new MatchPhraseQueryBuilder(field,key))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
// builder.query(new MatchQueryBuilder(field,key).analyzer("ik_smart"))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
.fetchSource(new String []{"name","date","price"},null)
.from(page)
.size(size);
request.source(builder);
return client.search(request, RequestOptions.DEFAULT);
这里短语分词是一样的,就不在贴图了,直接贴查询结果。

结论: 没有发现结果,调换短语顺序后查询,比如 “步特2021上半年最新款跑鞋”,发现没有结果
,当设置了slop参数之后,依旧查询不到,从这里可以应证到设置了字段分词方式为"ik_max_word"方式后,用standard方式查询分词查不到数据
- 采用ik_max_word 查询es
查询语句:
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();//.analyzer("standard") .analyzer("ik_max_word")
builder.query(new MatchPhraseQueryBuilder(field,key).analyzer("ik_max_word"))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
// builder.query(new MatchQueryBuilder(field,key).analyzer("ik_smart"))
// builder.query(new MatchPhraseQueryBuilder(field,key).slop(20).analyzer("ik_smart"))
.fetchSource(new String []{"name","date","price"},null)
.from(page)
.size(size);
request.source(builder);
return client.search(request, RequestOptions.DEFAULT);
查询结果:

加入slop参数后,结果:

调换查询语句关键词的顺序:
SearchResponse response = service.search("name", "2021特步上半年最新款跑鞋", 0, 30, "index_cloth");
结果为0个。
加slop参数后,结果:
与上面一种结果一致
- 采用ik_smart 查询es
SearchResponse response = service.search("name", "特步2021上半年最新款跑鞋", 0, 30, "index_cloth");
查询结果:
查询到0条,调换查询语句关键词的顺序: 结果和采用ik_max_word方式一致,没有查询到,
加了slop参数结果是,6条数据,调换查询语句关键词的顺序, 加了slop参数结果也是一致的,6条数据
结果图片都是下面的:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)