Elasticsearch:数据建模的方法与规范
当前文档以实战问题为基础,规范Elasticsearch数据建模流程,重点分析基于业务角度、数据量级角度、setting、mapping、复杂索引关联这五个层面中涉及到的问题。
写在前面:
我在做Elasticsearch相关的数据同步时,查阅了比较多的文章,再结合自己踩过的坑,发现了一些实战中比较经典的问题,下面选取几个常见且典型的问题分析下:
-
订单表、司机车辆表父子文档可以实现类似SQL的左连接吗?通过canal同步到ES中,能否实现类似左连接的效果?具体应该如何建模?
-
一个人管理1000家门店,如何更高效的查询自己管辖的商品类目?一个人维护1000个司机,如何快速查询自己管辖的司机信息?
-
随着业务的增长,一个索引的字段数据不断膨胀(业务场景变化,一直在索引内加字段),有什么解决办法?
-
一个索引字段个数设置为1500个,超出这个限制会不会消耗CPU资源和造成写入堆积?
-
日志诊断用于机器学习基线,需要将message分离出来,怎么在写入之前搞定?
如果对上述实战问题进行归类,都可以将其归类为Elasticsearch数据建模问题。
当前文档以实战问题为基础,规范Elasticsearch数据建模流程,重点分析基于业务角度、数据量级角度、setting、mapping、复杂索引关联这五个层面中涉及到的问题。
一、为什么要做数据建模?
以MySQL为例,做数据存储前需要考虑的问题如下:
-
数据库是否做读写分离?
-
分几张表存储?
-
每张表是按照业务划分吗?
-
业务扩展时是新增表还是在原有表新增字段?
-
单表数据量增加如何处理?
-
每个表需要哪些字段?每个字段选择什么数据类型?如何设计合理的字段类型才能节省存储提高效率?
-
哪些字段需要建索引?选择什么索引更好?
-
哪些字段需要设置外键?
-
表之间要不要建立关联?如何实现关联查询?关联键是否需要建索引?
-
多表之间的关联查询可能会很慢?如何设计阶段优化建模才能提高响应速度?
以上这些疑问均属于数据建模问题。在MySQL中我们往往认为建模十分必要,但是反观Elasticsearch,很多时候往往忽略了数据建模的重要性。
接下来,基于MySQL做数据存储需要考虑的问题,重新审视数据建模的定义,内容如下。
-
数据模型是对描述数据、数据联系、数据语义和一致性约束进行标准化的抽象模型;
-
数据建模是为存储在数据库中的资源创建和分析数据模型的过程;
-
数据建模的主要目的是表示系统内的数据类型、对象之间的关系及其属性;
-
数据模型有助于了解需要哪些数据以及应如何组织数据。
下面具体分析一下为什么要数据建模?
相比于MySQL,Elasticsearch有非常快捷的优势:
Elasticsearch支持动态类型检查和匹配。也就是说,当我们往索引中写入数据的时候,可以不提前指定数据类型,直接插入数据。Elasticsearch会为插入的字段赋予默认的数据类型。相比于MySQL,这样的确会节省很多时间。但随着后续数据量的增加,会存在以下弊端:
-
浪费存储空间,所有字符串类型的数据都会存储为text+keyword这样的组合类型,这对很多业务字段都是非必须的;
-
字符串类型默认分词standard,无法满足中文精细化分词检索的需求。
二 、Elasticsearch如何数据建模?
在做数据建模之前,需要进行架构设计。架构环节设计到技术选型,版本选型集群划分,节点角色划分。
① 基于业务角度建模
Elasticsearch使用范围广泛,很多行业都使用其作为搜索服务或复合查询的数据存储。涉及索引层面的设计和业务紧密贴合。尤其要注意两点:
1.业务细分:分成哪几类数据,每类数据归结为一个索引还是多个索引。
2.跨索引检索:跨索引检索的痛点是字段不统一,需要写非常复杂的dsl语句实现查询。为了避免这种情况,最好的方式就是在数据建模的阶段将所有可能用到的查询条件以及后续可能会新增的字段做好设计与预留。为每一类业务数据相同或者相似的字段进行统一建模。尽可能的“求同存异”。
求同:相同或者相近含义字段,统一字段名和字段类型;
存异:特定业务数据特有字段类型,可以独立设计字段名称和类型。
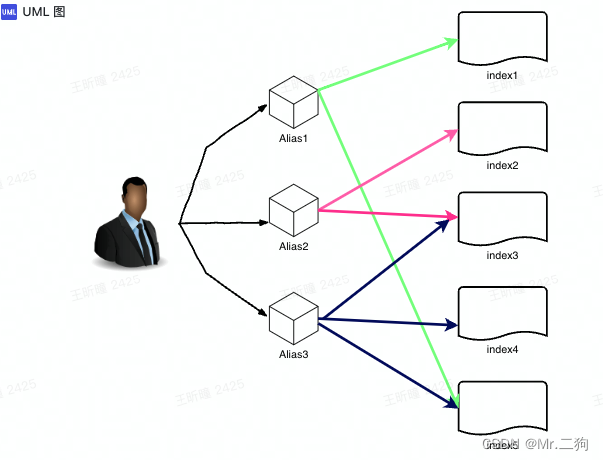
多索引管理一般优先考虑使用模板(template)和别名(alias)结合的方式。
模板:相同前缀名的索引可以归为一大类,一次创建,N多索引共享,非常方便;
别名:多个索引可以映射到一个别名,方便多索引以相同的名称统一对外提供服务。
②基于数据量角度建模
如果在Elasticsearch内存储的数据为某种时序性数据,建议基于时间来切分索引。根据当前使用的Elasticsearch版本(6.7.0/7.1.0),推荐使用ILM索引生命周期管理方案。
时序管理数据的优先:
-
灵活:基于时间切分索引在分区上有着天然的优势,因为时间是不会倒流的;
-
快速:特定业务数据配合冷热集群架构,确保高配机器对应热数据,提升检索效率和用户体验。
③基于setting层面建模
Setting层面又分为静态Setting和动态Setting两种。
静态Settings,一旦设置后,后续不可修改。如number_of_shards索引分片数量。
动态Settings,索引创建后,后续随时可以更新,如number_of_replicas索引副本数量,max_result_window查询返回数据最大数量,refresh_interval刷新频率。
当前阶段的核心问题:
-
问题1:索引设置多少分片?多少副本?
主分片设计需要考量总体数据量、集群节点规模,这点在集群规划层面需要做好预估。一般主分片数要考虑集群未来动态扩展,通常设置为节点数量的1~3之间的值。如3个节点的集群,索引主分片的数量可以设置为3/6/9.
-
问题2:refresh_interval设置多大?
默认值为1s,这意味着在写入阶段,每秒都会生成一个分段。
目的是:数据由index buffer的堆内存缓存区刷新到堆外内存区域,形成segment,使得搜索可见。
在实际的业务场景里,如果写入的数据不需要近实时搜索可见,可以适当在模板索引层面调大这个值,当然也可以动态的调整。
-
问题3:max_result_window是否需要修改?
对于深度翻页的from+size实现,越往后面翻返回速度越慢。
默认值为10000,如果每页显示10条,可以翻1000页,基本够用。不建议调大该值。
如果需要翻页查询,建议使用search_after的方式;如果需要全量遍历或者导出,推荐使用scroll查询的方式。参考文档:Elasticsearch深入理解(九)——三种分页方式选取
-
问题4:管道预处理如何使用?
参考文档:Elasticsearch深入理解(十三)——Index更换字段类型的三种方式 中方案三
④基于mapping层面建模
mapping层面核心是字段名称、字段类型、分词器选型、多字段multi_fields选型,以及字段细节的敲定。
-
字段命名:索引名称不允许用大写,字段名称官方没有限制,但是可以参考java编码规范。
-
字段类型:要结合业务类型选择适合的字段类型。比如integer可以搞定的,就不要用long。需要注意的是,字符串类型在5.x版本之后分为keyword和text两种类型。参考文档:Elasticsearch深入理解(十) ——keyword与text的区别
3.分词器:结合业务选择合适的分词器,分词器一旦设置是不可以修改的,除非reindex。
4.multi_fields:同一个字段根据需要可以设置多种数据类型,其实就是进行了多种类型的存储。
⑤基于复杂索引关联建模
对于多表关联的问题,Elasticsearch能提供的核心解决方案如下:
1.宽表方案
2.nested方案
3.join父子文档方案
4.业务层面实现关联
三、总结
Elasticsearch数据建模的核心考量因素:
-
尽量去用时间换空间
-
尽量前期数据预处理
-
能指定路由的提前执行路由,写入时指定路由
-
尽量将问题前置,在设计阶段预留足够的业务扩展空间

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)