MySQL:一个表里的索引是不是越多越好?
MySQL的B+树的索引原理:首先,正常我们在一个表里插入数据的时候,都会基于主键自动建立聚簇索引。随着我们不停的在表里面插入数据,它就会不停的在数据页里插入数据,然后一个数据页放满了就会分裂成多个数据页,这个时候就需要索引页去指向各个数据页。如果数据页太多了,那么索引页里的数据页指针也会太多了,索引页也必然会被放满,此时索引页也会分裂成多个,再形成更上层的索引页。这么逐步简化下来。形成的聚簇索引
MySQL的B+树的索引原理:
- 首先,正常我们在一个表里插入数据的时候,都会基于主键自动建立聚簇索引。
- 随着我们不停的在表里面插入数据,它就会不停的在数据页里插入数据,然后一个数据页放满了就会分裂成多个数据页,这个时候就需要索引页去指向各个数据页。
- 如果数据页太多了,那么索引页里的数据页指针也会太多了,索引页也必然会被放满,此时索引页也会分裂成多个,再形成更上层的索引页。
这么逐步简化下来。形成的聚簇索引如下图:
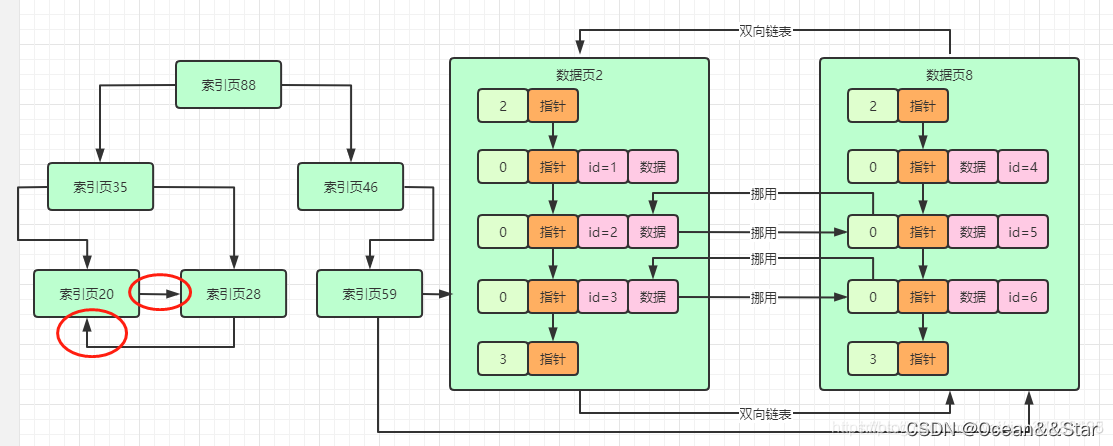
默认情况下,MySQL给我们建立的聚簇索引都是基于主键的值来组织索引的,聚簇索引的叶子节点都是数据页,里面放的就是我们插入的一行一行的完整的数据了
在一个索引B+树中,它有一些特性:
- 数据页/索引页里面的记录都是组成一个单向链表的,而且是按照数据大小有序排序的
- 数据页/索引页互相之间都是组成双向链表的,而且也都是按照数据大小有序排列的
所以其实B+树索引是一个完全有序的数据结构,无论是页内还是页之间。
正因为这个有序的B+树的索引结构,才能让我们查找数据的时候,直接从根节点开始按照数据值大小一层一层往下找,这个效率是非常高的。
然后如果是针对主键之外的字段建立索引的话,实际上本质就是为那个字段的值重新建立另外一棵B+树索引。
- 这个索引B+树的叶子节点,存放的都是数据页,里面放的都是你字段的值和主键值,然后每一层索引页里存放的都是下层也的引用,包括页内的排序规则、也之间的排序规则,B+树索引的搜索规则,都是一样的。
- 但是要注意的是:假设我们要根据其他字段的索引来搜索,那么只能基于其他字段的索引B+树快速找到到哪个值所对应的主键。接着再次做回表查询,基于主键在聚簇索引的B+树里,重新从根节点开始查找那个主键值,找到主键值对应的完整数据。
在MySQL的表里建立一些字段对应的索引,好处是什么?缺点是什么。
好处是你可以直接根据某个字段的索引B+树来查找数据,不需要全表扫描,性能提升是很高的。
坏处主要有两个,一个是空间上的,一个是时间上的:
- 空间上而言,你要是给很多字段创建很多的索引,那么就必然会有很多棵索引B+树,每一棵B+树都要占用很多磁盘空间。所以要是索引太多了,是很耗费磁盘空间的。
- 其次,你要是搞了很多索引,那么你在增删查改的时候,每次都需要维护各个索引的数据有序性,因为每个索引B+树都要求页内是按照值大小排序的,页之间也是有序的,下一个也的所有值必须大于上一个页的所有值。
- 所以你不停的增删改查,必然会导致各个数据页之间的值大小可能会没有顺序,如果下一个数据页里插入了一个比较小的值,居然比上一个数据页的值要小!此时就只能进行数据页的挪动,维护页之间的顺序
- 或者是你不停的插入数据,各个索引的数据页就要不停的分裂,不停的增加新的索引页
- 这些过程都是耗费时间的
所以要是一个表里建立的索引太多了,很可能导致你增删改的速度变得比较差,也许查询的速度确实可以提高,但是增删改就会受到影响。因此通常来说,我们不建议一个表里的索引太多。
那么怎样才能尽量用少的索引满足最多的查询请求,还不至于让索引占据太多的磁盘空间,影响增删改的性能呢?这就需要我们深入理解索引的使用规则,我们的SQL语句怎么写,才能用上索引B+树来查询

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)