spring boot 数据库连接池满问题解决
方式1:HikariCP项目pom依赖pom.xml<!--数据库连接驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.23</version></d
·
方式1:HikariCP
项目pom依赖
pom.xml
<!--数据库连接驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
<!--HikariCP数据源-->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
</dependency>
<!--mybatis-plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
application.yml
datasource:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.1:3306/db?serverTimezone=UTC&&useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
hikari:
# 池中最小空闲连接数量,默认值10
minimum-idle: 5
# 空闲时间
idle-timeout: 600000
# 池中最大连接数(包括空闲和正在使用的连接)
maximum-pool-size: 10
# 是否自动提交池中返回的连接
auto-commit: true
# 连接池的名字
pool-name: MyHikariCP
# 连接池中连接的最大生命周期
max-lifetime: 1800000
# 连接超时时间。默认值为30s
connection-timeout: 30000
# 测试连接
connection-test-query: SELECT 1
参数解释:
- minimum-idle
- 池中最小空闲连接数量。默认值10,小于池中最大连接数,一般根据系统大部分情况下的数据库连接情况取一个平均值。Hikari会尽可能、尽快地将空闲连接数维持在这个数量上。如果为了获得最佳性能和对峰值需求的响应能力,我们也不妨让他和最大连接数保持一致,使得HikariCP成为一个固定大小的数据库连接池。
- idle-timeout
- 空闲时间。仅在minimum-idle小于maximum-poop-size的时候才会起作用。默认值10分钟。根据应用实际情况做调整,对于一些间歇性流量达到峰值的应用,一般需要考虑设置的比间歇时间更大,防止创建数据库连接拖慢了应用速度。
- maximum-pool-size
- 池中最大连接数(包括空闲和正在使用的连接)。默认值是10,这个一般预估应用的最大连接数,后期根据监测得到一个最大值的一个平均值。要知道,最大连接并不是越多越好,一个connection会占用系统的带宽和存储。但是 当连接池没有空闲连接并且已经到达最大值,新来的连接池请求(HikariPool#getConnection)会被阻塞直到connectionTimeout(毫秒),超时后便抛出SQLException。
- auto-commit
- 是否自动提交池中返回的连接。默认值为true。一般是有必要自动提交上一个连接中的事物的。如果为false,那么就需要应用层手动提交事物。
- pool-name
- 连接池的名字。一般会出现在日志和JMX控制台中。默认值:auto-genenrated。建议取一个合适的名字,便于监控。
- max-lifetime
- 连接池中连接的最大生命周期。当连接一致处于闲置状态时,数据库可能会主动断开连接。为了防止大量的同一时间处于空闲连接因为数据库方的闲置超时策略断开连接(可以理解为连接雪崩),一般将这个值设置的比数据库的“闲置超时时间”小几秒,以便这些连接断开后,HikariCP能迅速的创建新一轮的连接。
- connection-timeout
- 连接超时时间。默认值为30s,可以接收的最小超时时间为250ms。但是连接池请求也可以自定义超时时间(com.zaxxer.hikari.pool.HikariPool#getConnection(long))。
方式2:druid
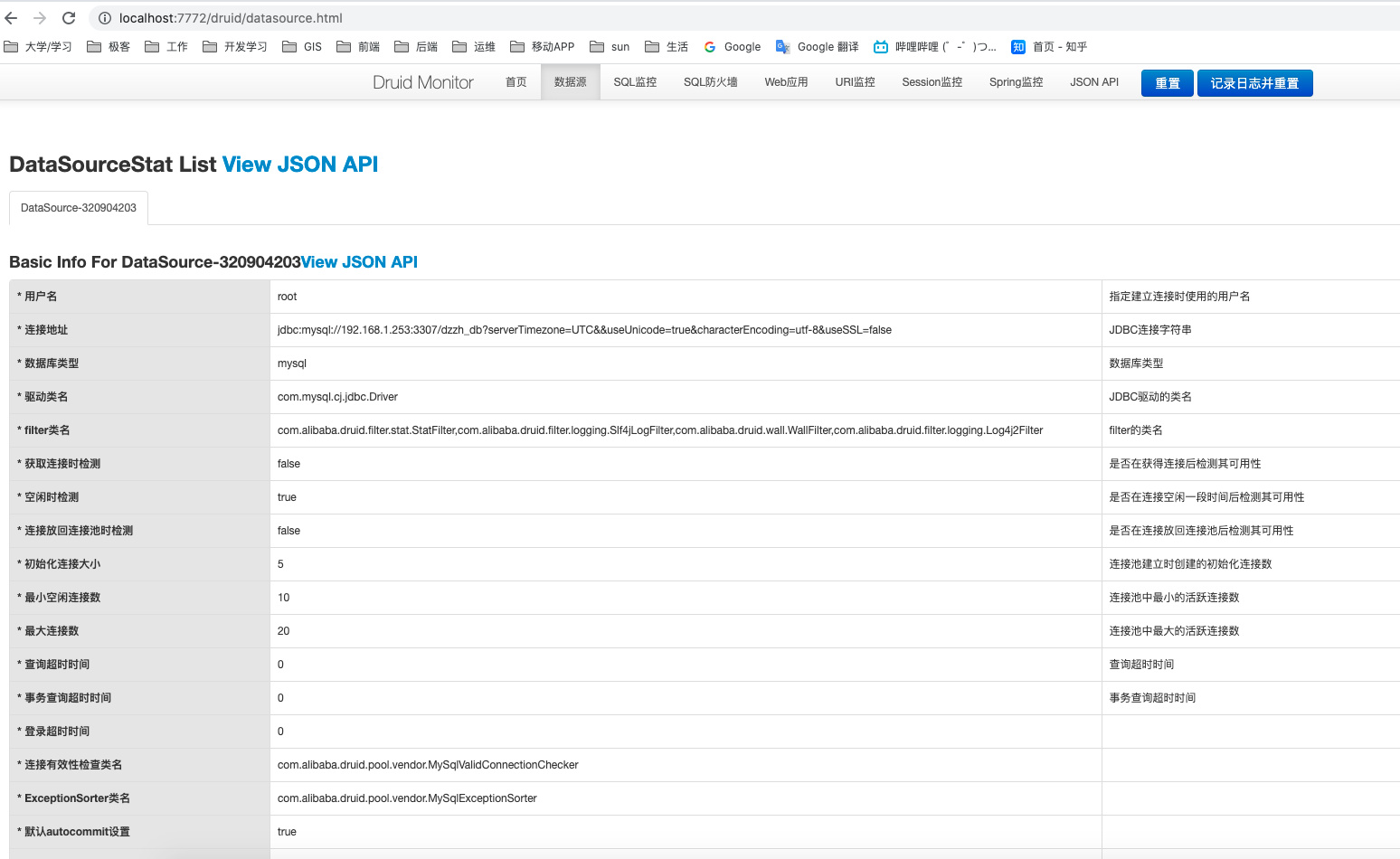
- Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
- stat:Druid内置提供一个StatFilter,用于统计监控信息。
- wall:Druid防御SQL注入攻击的WallFilter就是通过Druid的SQL Parser分析。Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。
- log4j2:这个就是日志记录的功能,可以把sql语句打印到log4j2 供排查问题。
pom.xml
<!-- druid数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>
<!-- mysql 驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
<!--使用 log4j2 记录日志-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<!-- mybatis plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
<exclusions>
<!-- 排除默认的 HikariCP 数据源 -->
<exclusion>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
</exclusion>
</exclusions>
</dependency>
application.yml
datasource:
type: com.alibaba.druid.pool.DruidDataSource
platform: mysql
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.1:3306/db?serverTimezone=UTC&&useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
druid:
# 配置初始化大小、最小、最大
initial-size: 5
minIdle: 10
max-active: 20
# 配置获取连接等待超时的时间(单位:毫秒)
max-wait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 2000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 600000
max-evictable-idle-time-millis: 900000
# 用来测试连接是否可用的SQL语句,默认值每种数据库都不相同,这是mysql
validationQuery: select 1
# 应用向连接池申请连接,并且testOnBorrow为false时,连接池将会判断连接是否处于空闲状态,如果是,则验证这条连接是否可用
testWhileIdle: true
# 如果为true,默认是false,应用向连接池申请连接时,连接池会判断这条连接是否是可用的
testOnBorrow: false
# 如果为true(默认false),当应用使用完连接,连接池回收连接的时候会判断该连接是否还可用
testOnReturn: false
# 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle
poolPreparedStatements: true
# 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true,
# 在Druid中,不会存在Oracle下PSCache占用内存过多的问题,
# 可以把这个数值配置大一些,比如说100
maxOpenPreparedStatements: 20
# 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作
keepAlive: true
# Spring 监控,利用aop 对指定接口的执行时间,jdbc数进行记录
aop-patterns: "com.dzzh.big_screen.mapper.*"
########### 启用内置过滤器(第一个 stat必须,否则监控不到SQL)##########
filters: stat,wall,log4j2
# 自己配置监控统计拦截的filter
filter:
# 开启druidDatasource的状态监控
stat:
enabled: true
db-type: mysql
# 开启慢sql监控,超过2s 就认为是慢sql,记录到日志中
log-slow-sql: true
slow-sql-millis: 2000
# 日志监控,使用slf4j 进行日志输出
slf4j:
enabled: true
statement-log-error-enabled: true
statement-create-after-log-enabled: false
statement-close-after-log-enabled: false
result-set-open-after-log-enabled: false
result-set-close-after-log-enabled: false
########## 配置WebStatFilter,用于采集web关联监控的数据 ##########
web-stat-filter:
enabled: true # 启动 StatFilter
url-pattern: /* # 过滤所有url
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" # 排除一些不必要的url
session-stat-enable: true # 开启session统计功能
session-stat-max-count: 1000 # session的最大个数,默认100
########## 配置StatViewServlet(监控页面),用于展示Druid的统计信息 ##########
stat-view-servlet:
enabled: true # 启用StatViewServlet
url-pattern: /druid/* # 访问内置监控页面的路径,内置监控页面的首页是/druid/index.html
reset-enable: false # 不允许清空统计数据,重新计算
login-username: root # 配置监控页面访问密码
login-password: 123456
allow: 127.0.0.1 # 允许访问的地址,如果allow没有配置或者为空,则允许所有访问
deny: # 拒绝访问的地址,deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝
- 配置Druid数据源(连接池):如同以前 c3p0、dbcp 数据源可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等一样,Druid 数据源同理可以进行设置;
- 配置 Druid web 监控 filter(WebStatFilter):这个过滤器的作用就是统计 web 应用请求中所有的数据库信息,比如 发出的 sql 语句,sql 执行的时间、请求次数、请求的 url 地址、以及seesion 监控、数据库表的访问次数 等等。
- 配置 Druid 后台管理 Servlet(StatViewServlet):Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装 路由器 时,人家也提供了一个默认的 web 页面;需要设置 Druid 的后台管理页面的属性,比如 登录账号、密码 等;
监控页面
启动项目后,访问 /druid/login.html 来到登录页面,输入用户名密码登录

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)