手写数学公式识别: 基于注意力聚合和双向交互学习的算法ABM(AAAI 2022 Oral)
关注公众号,发现CV技术之美本文转自CSIG文档图像分析与识别专委会本文简要介绍发表在AAAI 2022上的Oral论文《Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning》。该论文针对现有数学公式识别方...
关注公众号,发现CV技术之美
本文转自CSIG文档图像分析与识别专委会

本文简要介绍发表在AAAI 2022上的Oral论文《Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning》。
该论文针对现有数学公式识别方法中Coverage机制仅注意到历史信息而没有充分利用“未来”信息的问题,提出了一种从左向右和从右向左两个方向的解码同时解码并进行交互学习的方法。另外,为了对齐历史注意信息,同时兼顾不同大小符号的特征尺度学习,文章还提出了一个注意力聚合模块来更好地整合多尺度的Coverage注意力。相关代码已开源在https://github.com/XH-B/ABM
一、研究背景
手写数学公式识别是将包含数学表达式的图像转换为结构表达式,例如LaTeX数学表达式或符号布局树的过程,在智能办公和智能教育中有着广泛的应用。而对比于传统的文本符号识别(Optical Character Recognition, OCR),公式识别具有更大的挑战性。
首先,公式识别不仅需要从图像中识别所有符号,还需要捕捉符号之间的二维空间位置关系;其次,同一个公式中的符号尺度变化较大,而不同的大小可能具有不同的含义;第三,手写体公式符号书写的多样性和复杂性进一步加大了识别的难度。
随着深度学习的快速发展,在过去的几年中,许多基于编码器-解码器框架的方法在数学公式识别中取得了优异的性能。基于Seq2Seq架构[1]的手写数学公式识别模型WAP[2],利用RNN解码器将视觉特征解码成LaTeX字符串。
RNN解码器中的Coverage注意机制[3],通过考虑过去的对齐概率很好地克服注意力机制带来的解析不足或过度解析的问题。除了RNN之外,BTTR[4]首次在公式识别中引入了双向Transformer Decoder解码器,并且在解码的时候利用双向解码信息。
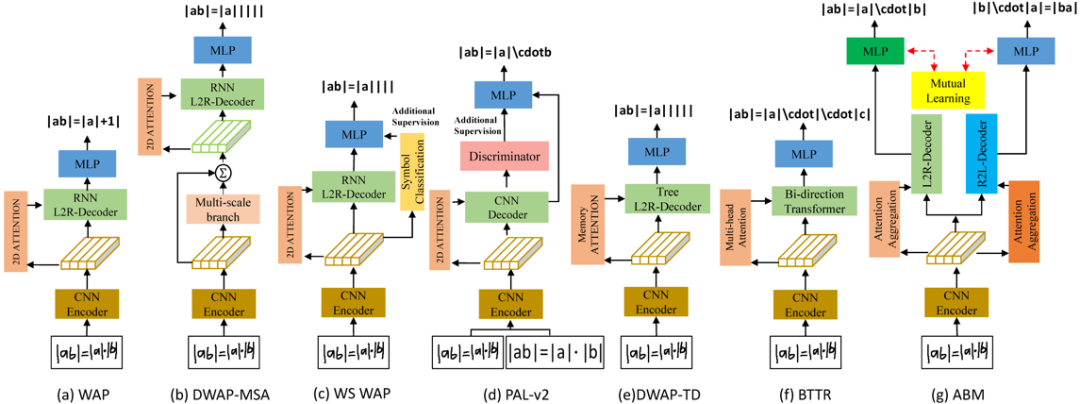
图1 手写数学公式识别的经典架构与本文提出的模型
然而,上述方法都存在两点不足:第一,基于WAP的方法都没有充分的利用“未来”信息,而仅计算了历史注意力。尽管BTTR对双向信息利用做了初步尝试,但在训练时一个方向的解码器时并没有显式地利用到另一个方向的信息。第二,没有充分融合公式符号的多尺度特征。
二、方法原理简述
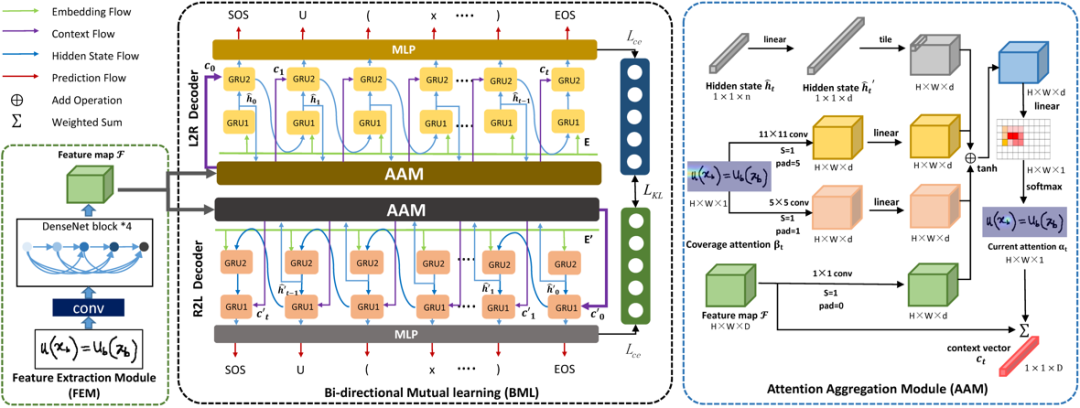
图2 网络整体框架图
基于上述方法存在不足,文章提出了一种称为ABM的端到端公式识别框架,如下图所示。主要由三个模块组成:
1)特征提取模块(FEM):采用CNN从数学表达式图片中提取特征信息;
2)注意力聚合模块(AAM):集成了Multi-Coverage注意力机制,主要对齐历史注意信息,同时兼顾不同大小符号的特征尺度学习;
3)双向相互学习模块(BML):由从左到右和从右到左(L2R和R2L)两个具有相反方向解码器构成,在训练阶段每个解码器不仅学习自身LaTeX序列,同时也通过自蒸馏的方法学习另一分支信息,从而提高解码能力;
特征提取模块(FEM)
对于图像特征的提取,本文使用DenseNet作为编码器。相较于ResNet,DenseNet在不同尺度特征图上的密集连接能够更好地反映出不同大小字符的尺度特征,有利于后续解码不同位置大小字符的含义。通过特征提取模块,网络将输入的图片编码为H×W×D的特征图,其中H、W和D分别表示特征图高、宽和通道数。
注意力聚合模块(AAM)
注意力机制能够帮助解码器关注其感兴趣区域。特别是基于Coverage的注意力机制能更好地对齐特征信息并指导网络对未关注区域分配更高的注意力概率。受 Inception模块的启发,本文提出了的注意力聚合模块 (AAM)。
与传统注意力相比,其具有两个不同卷积核大小的Coverage分支,不仅关注精细的局部特征,还关注更大感受野上的全局信息。从而帮助模型捕捉更准确的空间关系。如图2所示,AAM的计算过程分别使用隐藏状态 、视觉特征图F、Coverage注意力
、视觉特征图F、Coverage注意力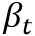 ,来计算当前注意力权重
,来计算当前注意力权重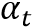 并最终得到上下文向量
并最终得到上下文向量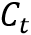 :
:
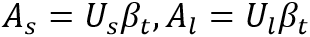
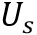 和
和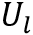 分别表示小核和大核卷积参数。其中
分别表示小核和大核卷积参数。其中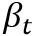 表示了所有过去注意力概率和,其计算过程如下:
表示了所有过去注意力概率和,其计算过程如下:
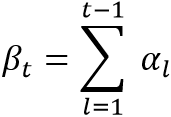
其中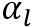 表示时间步l的注意力分数。其计算过程如下:
表示时间步l的注意力分数。其计算过程如下:
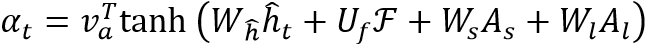
其中, 是可训练权重矩阵,
是可训练权重矩阵,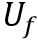 是 1×1的卷积运算,
是 1×1的卷积运算,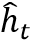 表示GRU的隐藏状态。
表示GRU的隐藏状态。
最终,根据注意力分数对内容向量加权求和就可以得到上下文向量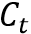 :
:
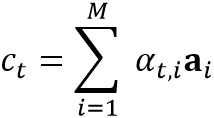
双向交互学习模块(BML)
双向交互学习模块包含了从左到右和从右到左两个方向的解码器。对于双向训练,添加<sos>和<eos>作为LaTeX序列起始和终止符。对于长度为 T的LaTeX序列 ,其从左到右 (L2R) 序列表示为
,其从左到右 (L2R) 序列表示为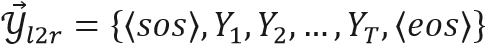 ,从右到左 (R2L) 序列表示为
,从右到左 (R2L) 序列表示为 。对于时间步t,L2R和R2L分支输出概率值的过程如下:
。对于时间步t,L2R和R2L分支输出概率值的过程如下:

其中隐藏层状态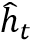 计算过程如下:
计算过程如下:
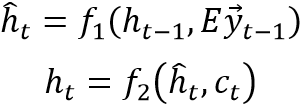
其中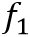 和
和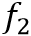 分别代表单向的GRU单元。
分别代表单向的GRU单元。
对于两个分支输出的概率分布,作者引入自蒸馏思想,将两解码分支通过Kullback-Leibler (KL) 损失函数在每个时间步上对预测的软概率作为标签进行交互学习。对于k个字符类别,L2R的软概率分布定义为:
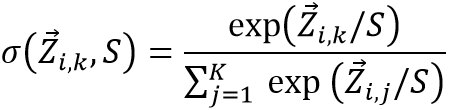
其中S是生成概率标签的温度参数。
由此可以得到L2R和R2L分支的KL距离为:

最终整体网络的目标为最小化两个分支的交叉熵损失与交互学习的KL损失之和:
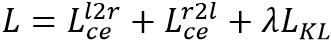
三、主要实验结果及可视化结果
表1 与先前工作在CROHME数据集上的效果的比较
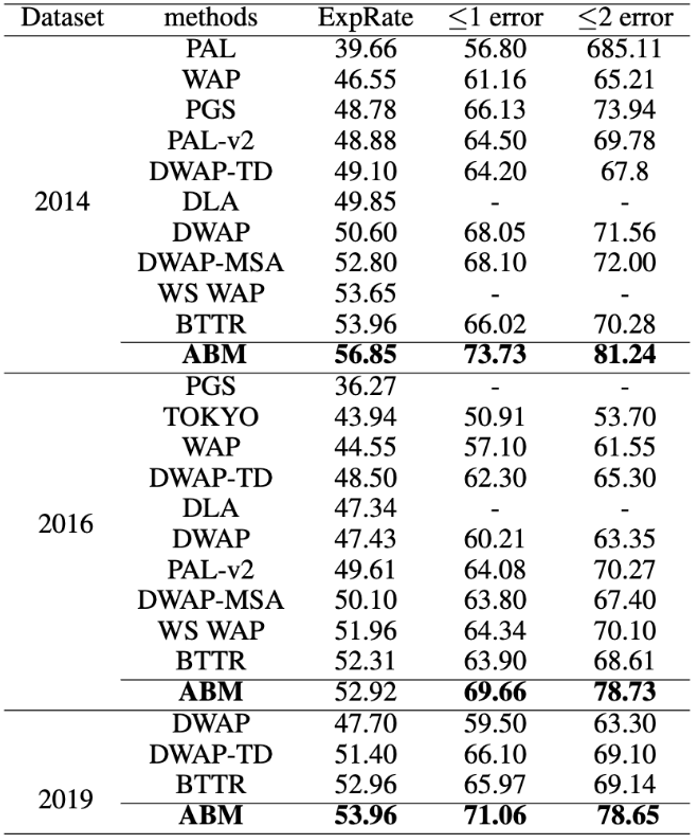
从表1中可以看出,本文提出的模型ABM在三个测试数据集上的识别准确率分别较基准(DWAP)提升了6.25%、5.49和6.26%。这说明了BML和AAM很有效地增强了解码器的预测能力。BTTR使用了传统的Transformer作为解码器。这在长序列上一定程度减少了识别错误,但是≤1 Error和≤2 Error的结果表明Transformer不能有效地降低字符错误率。在CROHME 2014的数据集上,本文提出的模型在整体识别准确率、≤1 Error和≤2 Error上相较BTTR分别有2.89%、7.71%和10.96%的提升。
表2 各模块消融实验
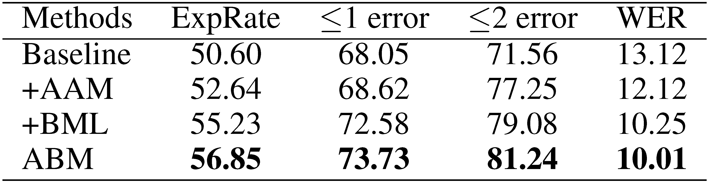
消融实验的结果表明,本文提出的两个模块都可以有效地提升识别的准确率,并且两个模块的对整体识别率的提升可以叠加。最终的结果相较于基准方法在识别率上有6.25%的较大提升。由此证明了提出的两个模块的有效性。
表3 不同编码方向带来的影响
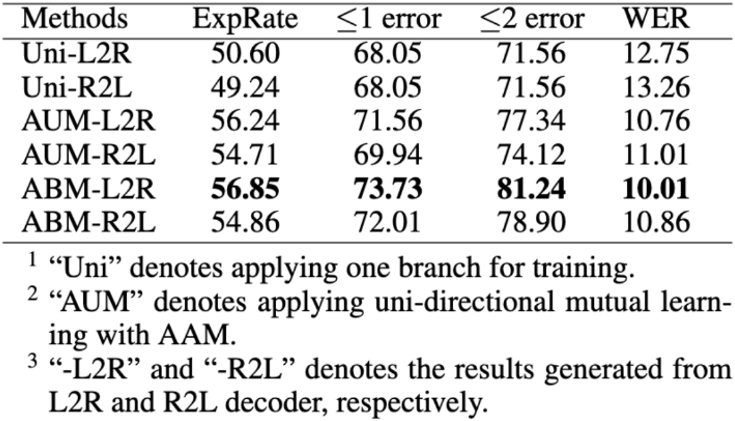
除了与传统的单向训练的模型做对比之外,作者还在具有AAM和BML模块的同向解码器模型上进行了实验。从表3中可以看出,本文提出的双向模型使得识别的准确率提升了6.25%。这说明,对比于两个同向解码器的交互学习,在两个相反的解码器上进行交互学习更加有效。
表4 提出的模块在不同编/解码器上的效果
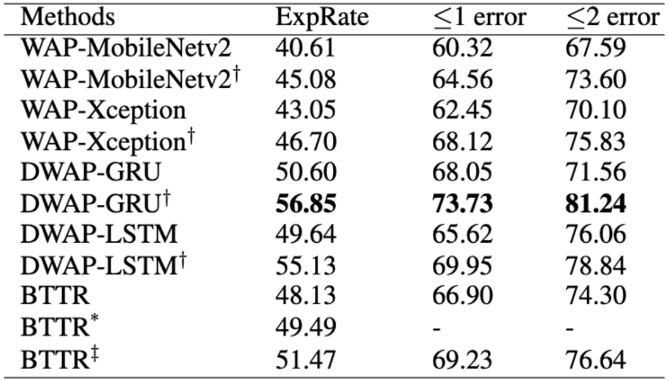
作者在不同的编码器和解码器上验证了ABM的通用性。为了公平起见,所有实验都使用相同的设置。如表4所示,对于不同的编码器,作者将 DenseNet 替换为 MobileNetV2 和 Xception,它们的识别准确率相较原始模型分别被提高了 4.47% 和 3.65%。对于不同的解码器,GRU、LSTM 和 Transformer 分别提高了 6.25%、5.49% 和 3.34%。

图3 本文提出的Coverage注意力在解码时的可视化效果
作者可视化了本文所提出的Coverage注意力机制在不同时间进行双向历史状态对齐的效果。由图3可以看出Coverage注意力能够很好地关注到当前预测的字符位置。

图4 基准方法DWAP与本文方法的t-SNE可视化效果图
作者进一步地使用t-SNE[6]可视化了CROHME 2014测试数据集上10个字符的特征分布。作者输入了所有之前的正确符号来解码当前的符号,并将分类器第一个全连接层之前的特征进行了可视化。图4展示了基准方法DWAP与本文方法的t-SNE可视化效果,可以看到本文提出的方法的分类特征聚类更加明显。
四、总结及讨论
本文提出了一种新颖的手写数学公式识别方法ABM。使用了双分支的解码器在相反的解码方向上进行了交互学习。实验结果证明了ABM相较于其他SOTA方法具有一定的优势。除此之外,将双向交互学习应用在其他的解码器如GRU、LSTM、Transformer上,都可以在推理时不增加额外参数的前提下,很有效的提高它们的性能。
五、相关资源
五、
Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning:
论文地址: https://arxiv.org/pdf/2112.03603.pdf;
码地址:https://github.com/XH-B/ABM
Watch, Attend and Parse: An End-to-end Neural Network Based Approach to Handwritten Mathematical Expression Recognition论文地址:
http://home.ustc.edu.cn/~xysszjs/paper/PR2017.pdf
Multi-scale Attention with Dense Encoder for Handwritten Mathematical Expression Recognition论文地址:
https://arxiv.org/pdf/1801.03530.pdf
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer论文地址:
https://arxiv.org/pdf/2105.02412.pdf
参考文献
[1] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems 27 (2014).
[2] Zhang, Jianshu, et al. "Watch, attend and parse: An end-to-end neural network based approach to handwritten mathematical expression recognition." Pattern Recognition 71 (2017): 196-206.
[3] See, Abigail, Peter J. Liu, and Christopher D. Manning. "Get to the point: Summarization with pointer-generator networks." arXiv preprint arXiv:1704.04368 (2017).
[4] Zhao, Wenqi, et al. "Handwritten mathematical expression recognition with bidirectionally trained transformer." International Conference on Document Analysis and Recognition. Springer, Cham, 2021.
[5] Zhang, Jianshu, Jun Du, and Lirong Dai. "Multi-scale attention with dense encoder for handwritten mathematical expression recognition." 2018 24th International Conference on Pattern Recognition (ICPR). IEEE, 2018.
[6] Van der Maaten, Laurens, and Geoffrey Hinton. "Visualizing data using t-SNE." Journal of Machine Learning Research 9.11 (2008).
原文作者:Xiaohang Bian, Bo Qin, Xiaozhe Xin, Jianwu Li, Xuefeng Su, Yanfeng Wang
撰稿:杨文韬
编排:高 学
审校:殷 飞
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。

END
欢迎加入「OCR」交流群👇备注:OCR


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)