kafka 消费机制
一、本文介绍了kafka的基础概念:topic、partition、broker、consumer、consumer group和producer。Topic一个Topic代表了一类资源,一种事件。比如用户上传的数据可以是一个topic,系统产生的事件也可以是一个topicBroker一个broker代表一个kafka实例,通常建议一台物理机配置一个kafka实例,因为配置多个磁盘的IO限制也注定
一、本文介绍了kafka的基础概念:topic、partition、broker、consumer、consumer group和producer。
-
Topic
一个Topic代表了一类资源,一种事件。比如用户上传的数据可以是一个topic,系统产生的事件也可以是一个topic -
Broker
一个broker代表一个kafka实例,通常建议一台物理机配置一个kafka实例,因为配置多个磁盘的IO限制也注定了性能不会提升太多 -
Partition
一个Topic可以创建多个Partition,一个partition就是一个存储kafka数据的文件(称为log),每个partition内部,消息是顺序排列的。
由于Partition是顺序写磁盘,不需要关心锁的问题,保证了Kafka的高吞吐量;每个partition内的数据是有序的。多个partition可以解决磁盘IO的性能限制,同时,也可以通过指定数据发送给kafka时的key,key被用来决定数据放到哪个partition,这样就消费数据时,某个partition的数据就是按照某个规则有序的了。
Partition和broker没有必然联系(可以参考Partition分配到broker的策略),但是一个partition只能位于一个broker上。
-
Consumer
消费者,消费Kafka中存储的数据,一个consumer可以消费多个partition(同topic/不同topic) -
Consumer Group
消费者组。一个消费者组可以有多个消费者,当使用高级消费者时,只需要指定订阅(subscribe)的topic;使用低级消费时,则需要指定consumer分配(assign)的topic和partition,,指定哪个partition就消费哪个,没有限制。
一个partition只能被同一个消费者组的一个订阅的consumer(高级)消费,但是可以被不同消费者组的多个consumer消费(订阅/分配均可),或者被同一个组的一个订阅的consumer和任意个分配的consumer(低级)消费;这个限制是由client端实现的,详情参见本系列第二篇文章。 -
Offset
offset记录了某个consumer group在一个partition中消费数据的位置。由partition和group唯一确定。 -
Producer
生产者,生产数据到Kafka
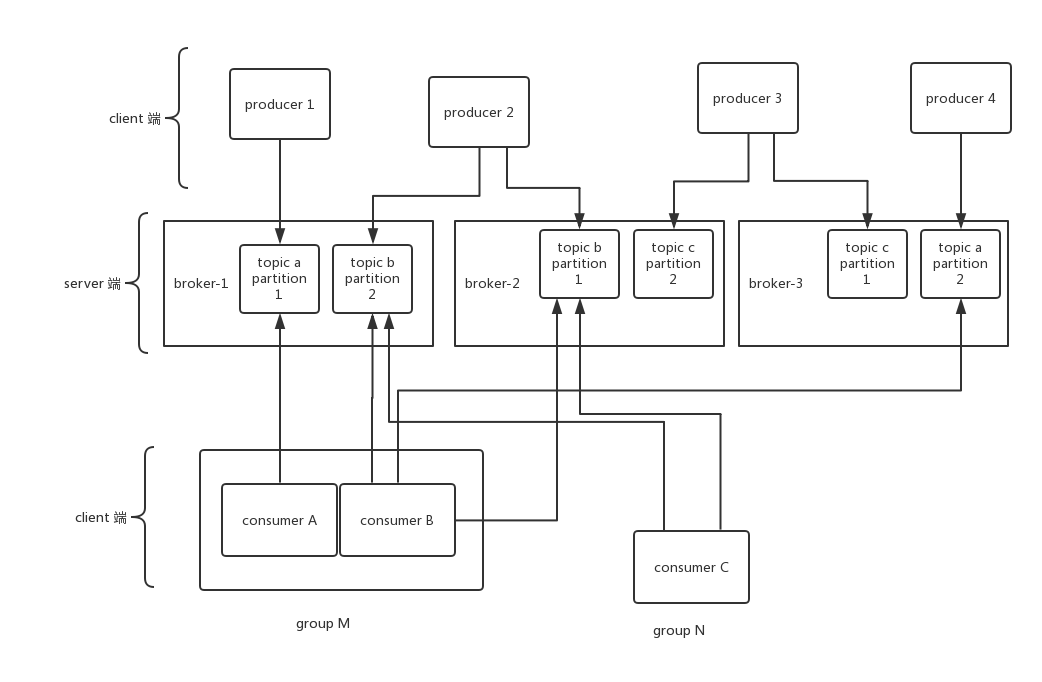
示意图如下:
topic a:
p1 被groupMconsumerA 消费
p2 被groupMconsumerB 消费
实现了一个topic被两个同group独立的consumer消费,提升消费速度。
topic b:
p1 被groupMconsumerB和groupNconsumerC同时消费
p2 被groupMconsumerB和groupNconsumerC同时消费
实现了多播的效果,所有到topicb的数据,consumerB和C同时接收到
【参考链接】
Kafka背景及架构介绍
KafkaPartition与Broker的映射关系
二、本文主要介绍Kafka中的topic、partition、offset的概念,和kafka java使用consumer时,高级消费和低级消费不同场景下的区别,通过本文,大致能够了解kafka是怎么保证至少消费一次,以及什么情况下会出现重复消费和丢失数据。
Offset
kafka高吞吐量的保证是Partition是顺序写磁盘,同样消费也是顺序的,offset维护了一个group的消费者在当前partition消费的数据位置。
当一个consumer启动后,会查询服务端的offset作为本地offset;
运行中poll数据使用的是本地offset,不再查询server;
每poll完一批数据,自动更新本地offset
server端也会维护一个offset,新版kafka offset是维护在一个topic中,旧版维护在zookeeper
提交offset是指:使用本地的offset/指定的offset 去更新server端的offset,但是本地offset不会改变
自动提交
自动提交策略下,是每隔指定时间,由kafka-clients自动提交本地维护的offset,默认本地offset=poll的数量+1。(本地offset可以通过seek方法修改)
但是会出现数据丢失的情况,比如poll了一批数据没有处理完,但是到时间了已经提交了offset,然后程序终止了,下次启动会从新的offset’启动,没有处理的数据丢失了
手动提交
- 不指定offset:同上,也是提交本地维护的offset,默认本地offset=poll的数量+1。
这种模式下,数据处理完毕(保存/丢弃)后再手动提交,解决了自动模式下的数据丢失问题,但是可能存在消费完的数据,offset没有提交成功,重复消费数据的问题(可以通过数据库事务解决) - 指定offset:更新server端offset为指定值,但是本地offset不会更新,所以在consumer没有重启的情况下,是不会消费到重复数据。
Consumer消费数据
一个大致的流程如下
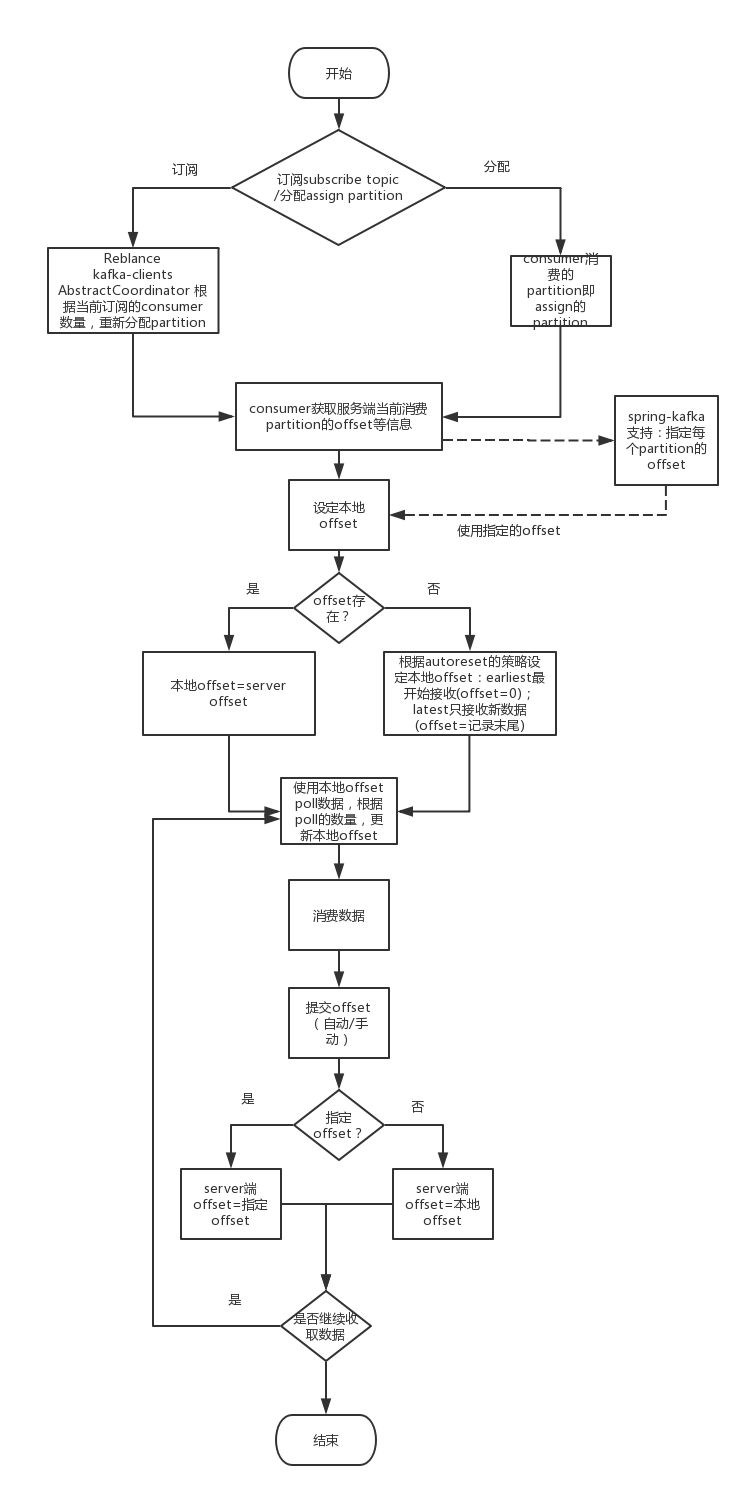
消费有两种指定topic的方式:subscribe和assign,两种方式主要区别在于partition的分配,前者是由kafka-clients分配的(高级消费),而后者是我们手动指定的(低级消费)。
注意:Consumer线程不安全,不能多线程共用
高级消费
API
对应于KafkaConsumer.subscribe()方法。可以接受的参数为
| 1 | subscribe(java.util.Collection<java.lang.String> topics) |
|---|---|
| 2 | subscribe(java.util.Collection<java.lang.String> topics,ConsumerRebalanceListener listener) |
| 3 | subscribe(java.util.regex.Pattern pattern) |
| 4 | subscribe(java.util.regex.Pattern pattern,ConsumerRebalanceListener listener) |
所以,其只接受订阅某个topic,而不能具体指定partition。
介绍
使用高级消费时,假定,1-N个consumer,属于同一个group。根据订阅的consumer的个数,由kafka-clinets根据指定的分配策略分配每个consumer消费的partition。注意:必须使用合理的分配策略,否则可能出现一些consumer没有分配partition的情况。
若N>partition num(所有topic的partition总和), 则一些consumer不会被分配partition
若N< partition num,则某些consumer会消费多个partition
当消费多个partition时,消费每个分区内的消息是有序的,但消费多个分区之间的消息是无序的(可以在消费记录中获得当前记录的partition)
partition分配策略
-
range: 得到topic-partitions关系,得到topic-consumers关系,然后,按照topic进行分配,即topic的所有partition按顺序分配到其所有的consumer上,举例:topicA-3partition, topicB-1partition, 4 consumers, 过程是,A的3个partition分配到consumer1-3,B的1个partition分配到consumer1,consumer4空闲,所以使用的最大线程数=max(topic*partition)
-
roundrobin:topics和patition组合,上述例子,就是ta-0,ta-1,ta-2,tb-0,然后四个取hashcode得到顺序,然后挨个分配到consumer上(要求:每一个consumer消费的topics有相同的streams&&这个消费组中每个consumer消费的topics必须完全相同)
上面的文字可能有描述不准确或不清楚的地方,这里列出了官方对着两种策略的解释:
RoundRobin: The round-robin partition assignor lays out all the available partitions and all the available consumer threads. It then proceeds to do a round-robin assignment from partition to consumer thread. If the subscriptions of all consumer instances are identical, then the partitions will be uniformly distributed. (i.e., the partition ownership counts will be within a delta of exactly one across all consumer threads.) (For simplicity of implementation) the assignor is allowed to assign a given topic-partition to any consumer instance and thread-id within that instance. Therefore, round-robin assignment is allowed only if: a) Every topic has the same number of streams within a consumer instance b) The set of subscribed topics is identical for every consumer instance within the group.
Range: Range partitioning works on a per-topic basis. For each topic, we lay out the available partitions in numeric order and the consumer threads in lexicographic order. We then divide the number of partitions by the total number of consumer streams (threads) to determine the number of partitions to assign to each consumer. If it does not evenly divide, then the first few consumers will have one extra partition. For example, suppose there are two consumers C1 and C2 with two streams each, and there are five available partitions (p0,p1, p2, p3, p4). So each consumer thread will get at least one partition and the first consumer thread will get one extra partition. So the assignment will be: p0 -> C1-0, p1 -> C1-0, p2 -> C1-1, p3 ->C2-0, p4 -> C2-1
reblance
订阅模式下,每加入或者离开一个consumer,都会触发consumer reblance,重新为每个消费者分配partition。
reblance的过程发生了什么?查看kafka-clients源码可以发现:
AbstractCoordinator 有详细说明调用subscribe方法发生了以下的事请
consumer注册到到服务端
coordinator(server端维护的一个服务)查找所有的该组consumer,选取leader
如果auto commit为true,所有的consumer提交本地offset到服务端;为false则不提交
leader通过coordinator获取服务端所有的partition和offset,并使用策略重新分配partition,结果返回给coordinator,coordinator下发分配结果到所有consumer(即join和leave的reblance)。
所以高级消费者集群时,新加入的consumer,如果是auto-commit则会提交offset,若未处理完可能会丢失数据;否则不提交,会重复消费数据。离开consumer,若未提交offset离开,则会重复消费数据;若自动提交了但是未消费,则会丢失数据。
低级消费
API
对应于KafkaConsumer.assign()方法,指定TopicPartition的集合
| 1 | assign(java.util.Collection partitions) |
|---|
介绍
使用低级消费时,直接指定consumer消费某个topic的某个partition,不再由kafka-clients分配,这种情况下,第一篇文章中已经提到,是可以多个同组消费者消费同一个partition的。
所以当同一个消费组指定重复的partition时,会消费到重复的数据(完全重复的数据,因为poll的offset是本地维护的),但是server端只有一个offset!server的offset被两个consumer更新,会出现冲突和错乱,这种模式下,需要开发者自己保证同一个消费组的消费着具有不重复的partition。
高级or低级?
如何抉择,主要取决于复杂性和数据一致性的取舍,即reblance带来的影响和手动分配带来的复杂的取舍。
数据丢失/重复消费
高级消费partition的分配是由kafka-clients完成的,但是会查询server端的信息,所以集群环境下,当没有指定partition时,每加入/离开一个消费者,kafka-clients都会重新平衡partition的分配,这个时候,如果有消费完成但是没有提交的offset,reblance时则会造成数据的重复消费或者数据丢失(具体是哪种情况,要看offset的提交策略)。低级消费则不会发生reblance!
注意:Spring-kafka多线程消费的配置下,指定topic和partition时,也是低级消费,其线程和partition的分配策略见后续spring-kafka的教程。
reblance影响性能
每次reblance都要重新分配,如果partition比较多的情况下,重新分配将会消耗大量的时间。
低级消费时的高可用
如果使用低级消费,当一个consumer退出时,其partition不会再分配给其他消费者,数据将会堆积在kafka中!所以务必要保证退出的消费者能重新运行。
【参考链接】
1.Kafka-偏移量提交
2.更详细的reblance过程
本文主要介绍kafka原生api的使用,关于kafka apache官方的文档页面只有简单的说明,不过所有的使用说明都在apache kafka java doc文档页面,每个类的文档都有详细的使用说明,源码中也有详细的注释。
原生api的使用比较简单,直接创建Consumer或者Producer对象即可,注意:由于Consumer线程不安全,不得多线程公用,且最好使用final变量
更多参考api docs
自动提交
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
手动提交
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
多线程
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(10000));
// Handle new records
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
低级消费
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)