数据库SQL语句中 where,group by,having,order by的执行顺序
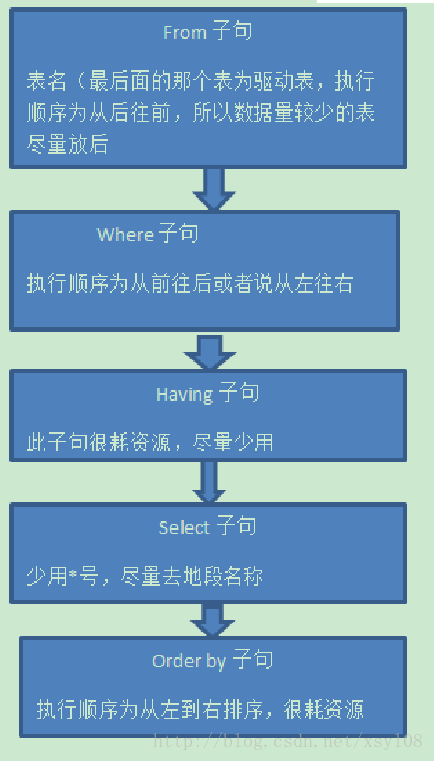
一、SQL查询1.查询中用到的关键词主要包含六个,并且他们的顺序依次为:select>from>where>group by>having>order by其中select和from是必须的,其他关键词是可选的,这六个关键词的执行顺序与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行:from>where>group by>having&g
一、SQL查询
1.查询中用到的关键词主要包含六个,并且他们的顺序依次为:
select>from>where>group by>having>order by
其中select和from是必须的,其他关键词是可选的,这六个关键词的执行顺序与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行:
from>where>group by>having>select>order by
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by:按照什么样的顺序来查看返回的数据
2.from后面的表关联,是自右向左解析的;而where条件的解析顺序是自下而上的。
也就是说,在写SQL语句的时候,尽量把数据量小的表放在最右边来进行关联(用小表去匹配大表),而把能筛选出小量数据的条件放在where语句的最左边 (用小表去匹配大表)。
使用count(列名)当某列出现null值的时候,count(*)仍然会计算,但是count(列名)不会。
二、数据分组(group by):
select 列a,聚合函数(聚合函数规范) from 表名 where 过滤条件 group by 列a
group by子句也和where条件语句结合在一起使用。当结合在一起时,where在前,group by 在后。即先对select xx from xx的记录集合用where进行筛选,然后再使用group by对筛选后的结果进行分组。
三、使用having字句对分组后的结果进行筛选,语法和where差不多:having 条件表达式
需要注意having和where的用法区别:
1.having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
2.where肯定在group by 之前,即也在having之前。
3.where后的条件表达式里不允许使用聚合函数,而having可以。
四、当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是:
1.执行where xx对全表数据做筛选,返回第1个结果集。
2.针对第1个结果集使用group by分组,返回第2个结果集。
3.针对第2个结集执行having xx进行筛选,返回第3个结果集。
4.针对第3个结果集中的每1组数据执行select xx,有几组就执行几次,返回第4个结果集。
5.针对第4个结果集排序。
例子:
完成一个复杂的查询语句,需求如下:
按由高到低的顺序显示个人平均分在70分以上的学生姓名和平均分,为了尽可能地提高平均分,在计算平均分前不包括分数在60分以下的成绩,并且也不计算贱人(jr)的成绩。 分析:
1.要求显示学生姓名和平均分
因此确定第1步select s_name,avg(score) from student
2.计算平均分前不包括分数在60分以下的成绩,并且也不计算贱人(jr)的成绩
因此确定第2步 where score>=60 and s_name!=’jr’
3.显示个人平均分
相同名字的学生(同一个学生)考了多门科目 因此按姓名分组 确定第3步 group by s_name 4.显示个人平均分在70分以上
因此确定第4步 having avg(s_score)>=70 5.按由高到低的顺序
因此确定第5步 order by avg(s_score) desc
五、索引
1.索引是单独的数据库对象,索引也需要被维护。
2.索引可以提高查询速度,但会降增删改的速度。
3.通过一定的查询触发,并不是越多越好。什么时候不适合用索引?
1).当增删改的操作大于查询的操作时。
2).查询的语句大于所有语句的三分之一时。
创建索引语法:create index 索引名 on 表名 (列名)
删除索引语法:drop index 索引名
更多信息请关注公众号:「软件老王」,关注不迷路,软件老王和他的IT朋友们,分享一些他们的技术见解和生活故事。


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)