Alluxio简介
Alluxio简介Alluxio概览 - Alluxio v2.6.1 (stable) Documentation1.介绍Alluxio 是世界上第一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建了桥梁, 将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio内存至
Alluxio简介
1.介绍
Alluxio 是世界上第一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建了桥梁, 将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。
在大数据生态系统中,Alluxio 位于数据驱动框架或应用(如 Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache Flink)和各种持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack Swift、HDFS、GlusterFS、IBM Cleversafe、EMC ECS、Ceph、NFS 、Minio和 Alibaba OSS)之间。 Alluxio 统一了存储在这些不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。
2.优势
通过简化应用程序访问其数据的方式(无论数据是什么格式或位置),Alluxio 能够帮助克服从数据中提取信息所面临的困难。Alluxio 的优势包括:
-
内存速度 I/O:Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
-
简化云存储和对象存储接入:与传统文件系统相比,云存储系统和对象存储系统使用不同的语义,这些语义对性能的影响也不同于传统文件系统。在云存储和对象存储系统上进行常见的文件系统操作(如列出目录和重命名)通常会导致显著的性能开销。当访问云存储中的数据时,应用程序没有节点级数据本地性或跨应用程序缓存。将 Alluxio 与云存储或对象存储一起部署可以缓解这些问题,因为这样将从 Alluxio 中检索读取数据,而不是从底层云存储或对象存储中检索读取。
-
简化数据管理:Alluxio 提供对多数据源的单点访问。除了连接不同类型的数据源之外,Alluxio 还允许用户同时连接同一存储系统的不同版本,如多个版本的 HDFS,并且无需复杂的系统配置和管理。
-
应用程序部署简易:Alluxio 管理应用程序和文件或对象存储之间的通信,将应用程序的数据访问请求转换为底层存储接口的请求。Alluxio 与 Hadoop 生态系统兼容,现有的数据分析应用程序,如 Spark 和 MapReduce 程序,无需更改任何代码就能在 Alluxio 上运行。
-
技术创新
Alluxio 将三个关键领域的创新结合在一起,提供了一套独特的功能。
-
全局命名空间:Alluxio 能够对多个独立存储系统提供单点访问,无论这些存储系统的物理位置在何处。这提供了所有数据源的统一视图和应用程序的标准接口。有关详细信息,请参阅统一命名空间文档。
-
智能多层级缓存:Alluxio 集群能够充当底层存储系统中数据的读写缓存。可配置自动优化数据放置策略,以实现跨内存和磁盘(SSD/HDD)的性能和可靠性。缓存对用户是透明的,使用缓冲来保持与持久存储的一致性。有关详细信息,请参阅 缓存功能文档。
-
服务器端 API 翻译转换:Alluxio支持工业界场景的API接口,例如HDFS API, S3 API, FUSE API, REST API。它能够透明地从标准客户端接口转换到任何存储接口。Alluxio 负责管理应用程序和文件或对象存储之间的通信,从而消除了对复杂系统进行配置和管理的需求。文件数据可以看起来像对象数据,反之亦然。
-
Alluxio 采用了经典型的单master 多worker架构。当使用集群独立模式部署时,为了解决master的单点问题,Alluxio使用多master实现,通过Zookeeper来保证全局唯一性。类似Hadoop的HA功能。 工作方式如下图
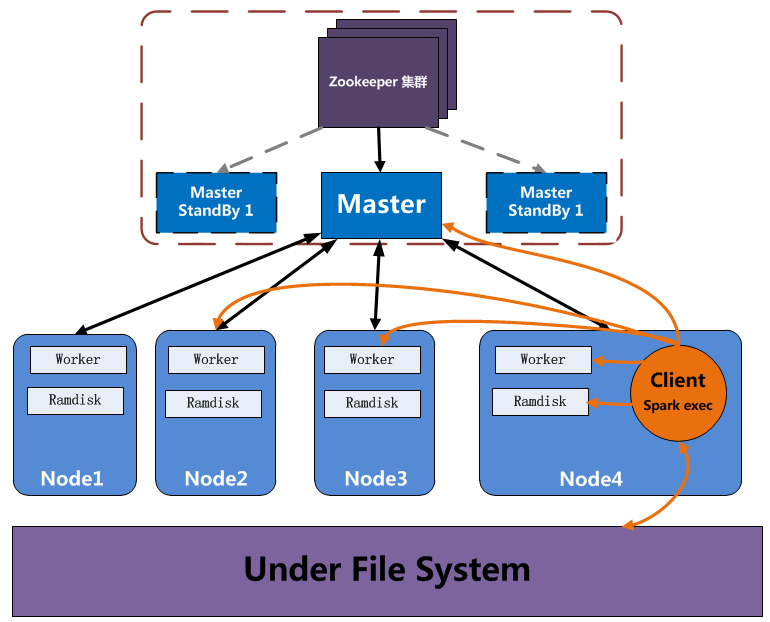
Master: 主要负责处理与存储系统元数据,元数据通过树形结构来管理,树形结构的每一个叶子节点代表文件或者空目录。对外(客户端或其他程序)提供元数据信息的访问与修改。对内(所有的Worker)负责统计收集每个Worker 周期心跳发送来的数据块信息与每个Worker的运行状态。Master不会主动与其他组件通讯,只以请求应答的方式与其他组件通讯。
Worker: 负责管理本地资源,如本地内存、SSD、磁盘等。提供Client读写数据请求服务,客户端或其他程序发来的数据将会以block的方式进行管理(一个文件的多个block会分散存储在多个Worker节点上)。每个Worker缓存数据时使用的是Ramfs,它是Linux下的一种基于RAM做存储的文件系统,上层可以象使用普通硬盘一样操作它。同时提供了象访问内存一样的速度。
Client: 使用数据的程序,可以是Spark executor 也可以是 MapReduce的task 或是其他程序。 Alluxio 允许Client通过与Master通讯来执行元数据操作,与Worker通讯来读写数据。同时客户端还可以直接绕过Alluxio访问底层存储系统。
Zookeeper: 实现容错和Leader选举,保证对外提供服务的leader(master)的唯一性。
Under File System: 真实的存储系统,可以是 S3、 HDFS、 GlusterFS等存储系统。
http://blog.iwantfind.com/archives/76
Alluxio:架构及数据流 - 简书 (jianshu.com)
3.内存、外存
Alluxio的层次化存储充分利用了每个Tachyon Worker上的本地存储资源,将Alluxio中的数据块按不同热度存放在了不同的存储层中。目前Alluxio所使用的本地存储资源包括MEM(Memory,内存)、SSD(Solid State Drives,固态硬盘)和HDD(Hard Disk Drives,磁盘)。在Tachyon Worker中,每一类存储资源被视作一层(Storage Tier),每一层又可以由多个目录(Storage Directory)组成,并且用户可以设置每个存储目录的容量。
分层存储种类:
- 1、MEM (内存)
- 2、SSD (固态硬盘)
- 3、HDD (硬盘驱动器)
计算机存储器按照用途可分为主存储器和辅助存储器,主存储器又称内存储器(简称主存或内存),辅助存储器又称外存储器(简称外存)。
外存通常是磁性介质或光盘,像硬盘,软盘,磁带,CD等,能长期保存信息,并且不依赖于电来保存信息,但是由机械部件带动,速度与CPU相比就显得慢的多。
PC机常见的外存储器有 软盘存储器 、 硬盘存储器 、 光盘存储器 。
硬盘的种类可分为:
- 固态硬盘(SSD),采用闪存颗粒来储存;优点是速度快,日常的读写比机械硬盘快几十倍上百倍,此外还拥有低功耗、防震抗摔性好、发热低等优势。缺点是单位成本高,不适合做大容量存储。
- 机械硬盘(HDD),采用磁性碟片来储存;优点是单位成本低,适合做大容量存储,但速度远不如SSD。
- 混合硬盘(HHD),是把磁性硬盘和闪存集成到一起的一种硬盘。
**内存(主存)**指的就是主板上的存储部件,是CPU直接与之沟通,并用其存储数据的部件,存放当前正在使用的数据和程序,它的物理实质就是一组或多组具备数据输入输出和数据存储功能的集成电路,内存只用于暂时存放程序和数据,一旦关闭电源或发生断电,其中的程序和数据就会丢失。
内存储器有很多类型。**随机存取存储器( RAM)**在计算期间被用作高速暂存记忆区。数据可以在RAM中存储、读取和用新的数据代替。当计算机在运行时RAM是可得到的。它包含了放置在计算机此刻所处理的问题处的信息。大多数RAM是“不稳定的”,这意味着当关闭计算机时信息将会丢失。只读存储器(ROM)是稳定的。它被用于存储计算机在必要时需要的指令集。存储在ROM内的信息是硬接线的”(即,它是电子元件的一个物理组成部分),且不能被计算机改变(因此称为“只读”)。可变的ROM,称为可编程只读存储器(PROM),可以将其暴露在一个外部电器设备或光学器件(如激光)中来改变。
随机存储器
随机存储器是一种可以随机读∕写数据的存储器,也称为读∕写存储器。RAM有以下两个特点:一是可以读出,也可以写入。读出时并不损坏原来存储的内容,只有写入时才修改原来所存储的内容。二是RAM只能用于暂时存放信息,一旦断电,存储内容立即消失,即具有易失性。RAM通常由MOS型半导体存储器组成,根据其保存数据的机理又可分为动态(DynamicRAM)和静态(StaticRAM)两大类。DRAM的特点是集成度高,主要用于大容量内存储器;SRAM的特点是存取速度快,主要用于高速缓冲存储器。
只读存储器
ROM是只读存储器,顾名思义,它的特点是只能读出原有的内容,不能由用户再写入新内容。原来存储的内容是采用掩膜技术由厂家一次性写入的,并永久保存下来。它一般用来存放专用的固定的程序和数据。只读存储器是一种非易失性存储器,一旦写入信息后,无需外加电源来保存信息,不会因断电而丢失。
内存和外存的区别:
CPU、缓存、内存和本地磁盘的关系:
CPU
CPU是中央处理器的简称,它可以从内存和缓存中读取指令,放入指令寄存器,并能够发出控制指令来完成一条指令的执行。但是CPU并不能直接从硬盘中读取程序或数据。
内存
内存作为与CPU直接进行沟通的部件,所有的程序都是在内存中运行的。其作用是暂时存放CPU的运算数据,以及与硬盘交换的数据。也是相当于CPU与硬盘沟通的桥梁。只要计算机在运行,CPU就会把需要运算的数据调到内存中进行运算,运算完成后CPU再将结果传出来。
缓存
缓存是CPU的一部分,存在于CPU里。由于CPU的存取速度很快,而内存的速度很慢,为了不让CPU每次都在运行相对缓慢的内存中操作,缓存就作为一个中间者出现了。有些常用的数据或是地址,就直接存在缓存中,这样,下一次调用的时候就不需要再去内存中去找了。因此,CPU每次回先到自己的缓存中寻找想要的东西(一般80%的东西都可以找到),找不到的时候再去内存中获取。最初的缓存生产成本很高,价格昂贵,所以为了存储更多的数据,又不希望成本过高,就出现了二级缓存的概念,他们采用的并不是一级缓存的SRAM(静态RAM),而是采用了性能比SRAM稍差一些,但是比内存更快的DRAM(动态RAM)
硬盘
我们都知道内存是掉电之后数据就消失的部件,所以,长期的数据存储更多的还是依靠硬盘这种本地磁盘作为存储工具。
简单的概括:
-
CPU运行时首先会去自身的缓存中寻找,如果没有再去内存中找。
-
硬盘中的数据会先写入内存才能被CPU使用。
-
缓存会记录一些常用的数据等信息,以免每次都要到内存中,节省了时间,提高了效率。
-
内存+缓存 -> 内存储空间
-
硬盘 -> 外存储空间
4.常见问题
-
如果向集群添加新节点,为了平衡节点之间的内存空间利用率,Alluxio是否会进行重新平衡(即将缓存的块移动到新节点)?
否,当前还未实现对数据块的重新平衡。
-
Alluxio master节点是否具备容错能力?
是的。请参考以集群模式运行Alluxio文档。
-
什么是底层存储系统?Alluxio支持多少种底层存储系统?
Alluxio 使用底层存储系统作为其持久化存储系统,当前支持 Amazon S3, Swift, GCS, HDFS以及很多其他存储系统。
-
如果数据集不适合存储在内存中该怎么办?
这取决于系统设置。Alluxio 会使用本地SSD和HDD进行存储,热数据(被频繁访问的数据)被保存在Alluxio中而冷数据(不经常访问的数据)被保存在底层存储系统中。 可以在缓存功能文档阅读有关Alluxio存储设置的更多信息。
-
Alluxio必须在HDFS上运行吗?
不是的,Alluxio可以运行在不同的底层存储系统上,如HDFS,Amazon S3,Swift和GlusterFS等。
-
Alluxio可以和其他框架一起工作吗?
5.核心功能
一、缓存
- Alluxio存储概述
- 配置Alluxio存储
- Alluxio中数据生命周期管理
- 从Alluxio存储中释放数据
- 将数据加载到Alluxio存储中
- 在Alluxio中持久化保留数据
- 设置生存时间(TTL)
- 在Alluxio中管理数据复制
- 检查Alluxio缓存容量和使用情况
Alluxio存储概述
本文档的目的是向用户介绍Alluxio存储和 在Alluxio存储空间中可以执行的操作背后的概念。 与元数据相关的操作 例如同步和名称空间,请参阅 [有关命名空间管理的页面] (…/…/en/core-services/Unified-Namespace.html)
Alluxio在帮助统一跨各种平台用户数据的同时还有助于为用户提升总体I / O吞吐量。 Alluxio是通过把存储分为两个不同的类别来实现这一目标的。
- UFS(底层文件存储,也称为底层存储) -该存储空间代表不受Alluxio管理的空间。 UFS存储可能来自外部文件系统,包括如HDFS或S3。 Alluxio可能连接到一个或多个UFS并在一个命名空间中统一呈现这类底层存储。 -通常,UFS存储旨在相当长一段时间持久存储大量数据。
- Alluxio存储
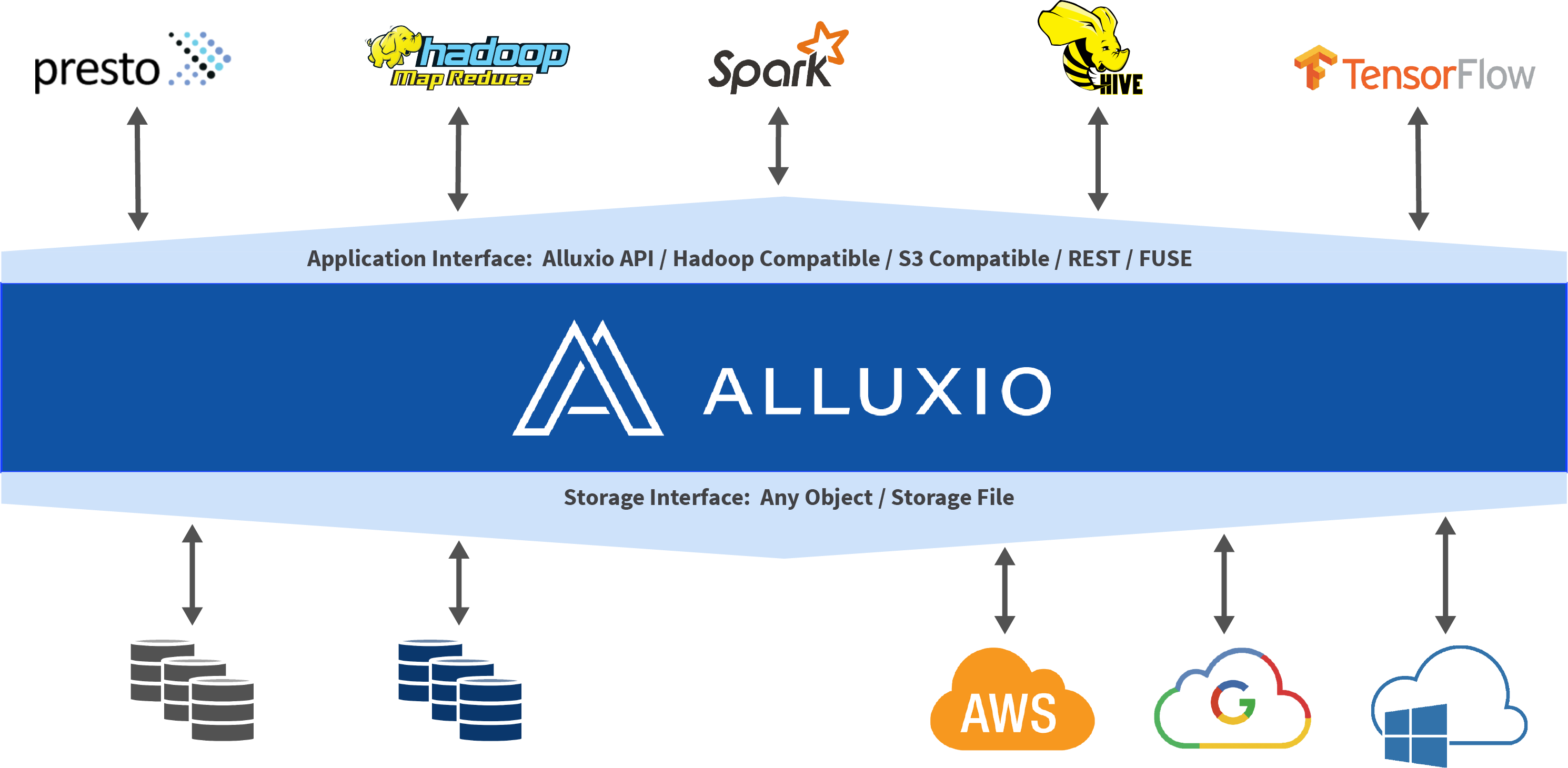
Alluxio存储通过将数据存储在计算节点内存中来提高性能。 Alluxio存储中的数据可以被复制来形成“热”数据,更易于I/O并行操作和使用。
Alluxio中的数据副本独立于UFS中可能已存在的副本。 Alluxio存储中的数据副本数是由集群活动动态决定的。 由于Alluxio依赖底层文件存储来存储大部分数据, Alluxio不需要保存未使用的数据副本。
Alluxio还支持让系统存储软件可感知的分层存储,使类似L1/L2 CPU缓存一样的数据存储优化成为可能。
配置Alluxio存储
单层存储
配置Alluxio存储的最简单方法是使用默认的单层模式。
请注意,此部分是讲本地存储,诸如
mount之类的术语指在本地存储文件系统上挂载,不要与Alluxio的外部底层存储的mount概念混淆。要分清Alluxio本身的存储 与 底部挂载的多个存储
1)单一存储介质
在启动时,Alluxio将在每个worker节点上发放一个ramdisk并占用一定比例的系统的总内存。 此ramdisk将用作分配给每个Alluxio worker的唯一存储介质。
RamDisk实际上是从内存中划出一部分作为一个分区使用,换句话说,就是把内存一部分当做硬盘使用,你可以向里边存文件。
RamDisk并非一个实际的文件系统,而是一种将实际的文件系统装入内存的机制,并且可以作为根文件系统。实际上它使用的文件系统是ext2。
那么为什么要用RamDisk呢?a) 假设有几个文件要频繁的使用,你如果将它们加到内存当中,程序运行速度会大副提高,因为内存的读写速度远高于硬盘。况且内存价格低廉,一台PC有4G或8G已不是什么新鲜事。划出部分内存提高整体性能不亚于更换新的CPU。b) ramdisk是基于内存的文件系统,具有断电不保存的特性,假设你对文件系统做了什么破坏导致系统崩溃,只要重新上电即可恢复。
通过Alluxio配置中的alluxio-site.properties来配置Alluxio存储。 详细信息见configuration settings。
对默认值的常见修改是明确设置ramdisk的大小。 例如,设置每个worker的ramdisk大小为16GB:
alluxio.worker.ramdisk.size=16GB
2)多个存储介质
另一个常见更改是指定多个存储介质,例如ramdisk和SSD。 需要 更新alluxio.worker.tieredstore.level0.dirs.path以指定想用的每个存储介质 为一个相应的存储目录。 例如,要使用ramdisk(挂载在/mnt/ramdisk上)和两个 SSD(挂载在/mnt/ssd1和/mnt/ssd2):
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk,/mnt/ssd1,/mnt/ssd2
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM,SSD,SSD
请注意,介质类型的顺序必须与路径的顺序相符。 MEM和SSD是Alluxio中的两种预配置存储类型。 alluxio.master.tieredstore.global.mediumtype是包含所有可用的介质类型的配置参数,默认情况下设置为MEM,SSD,HDD。 如果用户有额外存储介质类型可以通过修改这个配置来增加。
提供的路径应指向挂载适当存储介质的本地文件系统中的路径。 为了实现短路操作,对于这些路径,应允许客户端用户在这些路径上进行读取,写入和执行。 例如,对于与启动Alluxio服务的用户组同组用户应给予770权限。
更新存储介质后,需要指出每个存储目录分配了多少存储空间。 例如,如果要在ramdisk上使用16 GB,在每个SSD上使用100 GB:
alluxio.worker.tieredstore.level0.dirs.quota=16GB,100GB,100GB
注意存储空间配置的顺序一定与存储目录的配置相符。
Alluxio在通过Mount或SudoMount选项启动时,配置并挂载ramdisk。(指定Alluxio存储的存储介质,挂载内存) 这个ramdisk大小是由alluxio.worker.ramdisk.size确定的。 默认情况下,tier 0设置为MEM并且管理整个ramdisk。 此时alluxio.worker.tieredstore.level0.dirs.quota的值同alluxio.worker.ramdisk.size一样。 如果tier0要使用除默认的ramdisk以外的设备,应该显式地设置alluxio.worker.tieredstore.level0.dirs.quota选项。
多层存储
通常建议异构存储介质也使用单个存储层。 在特定环境中,工作负载将受益于基于I/O速度存储介质明确排序。 Alluxio假定根据按I/O性能从高到低来对多层存储进行排序。 例如,用户经常指定以下层:
写数据
用户写新的数据块时,默认情况下会将其写入顶层存储。如果顶层没有足够的可用空间, 则会尝试下一层存储。如果在所有层上均未找到存储空间,因Alluxio的设计是易失性存储,Alluxio会释放空间来存储新写入的数据块。 根据块注释策略,空间释放操作会从work中释放数据块。 块注释政策。 如果空间释放操作无法释放新空间,则写数据将失败。
**注意:**新的释放空间模型是同步模式并会代表要求为其要写入的数据块释放新空白存储空间的客户端来执行释放空间操作。 在块注释策略的帮助下,同步模式释放空间不会引起性能下降,因为总有已排序的数据块列表可用。 然而,可以将alluxio.worker.tieredstore.free.ahead.bytes(默认值:0)配置为每次释放超过释放空间请求所需字节数来保证有多余的已释放空间满足写数据需求。
用户还可以通过configuration settings来指定写入数据层。
读取数据
如果数据已经存在于Alluxio中,则客户端将简单地从已存储的数据块读取数据。 如果将Alluxio配置为多层,则不一定是从顶层读取数据块, 因为数据可能已经透明地挪到更低的存储层。
用ReadType.CACHE_PROMOTE读取数据将在从worker读取数据前尝试首先将数据块挪到 顶层存储。也可以将其用作为一种数据管理策略 明确地将热数据移动到更高层存储读取。
配置分层存储
可以使用以下方式在Alluxio中启用分层存储 配置参数。 为Alluxio指定额外存储层,使用以下配置参数:
alluxio.worker.tieredstore.levels
alluxio.worker.tieredstore.level{x}.alias
alluxio.worker.tieredstore.level{x}.dirs.quota
alluxio.worker.tieredstore.level{x}.dirs.path
alluxio.worker.tieredstore.level{x}.dirs.mediumtype
例如,如果计划将Alluxio配置为具有两层存储,内存和硬盘存储, 可以使用类似于以下的配置:
# configure 2 tiers in Alluxio
alluxio.worker.tieredstore.levels=2
# the first (top) tier to be a memory tier
alluxio.worker.tieredstore.level0.alias=MEM
# defined `/mnt/ramdisk` to be the file path to the first tier
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
# defined MEM to be the medium type of the ramdisk directory
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM
# set the quota for the ramdisk to be `100GB`
alluxio.worker.tieredstore.level0.dirs.quota=100GB
# configure the second tier to be a hard disk tier
alluxio.worker.tieredstore.level1.alias=HDD
# configured 3 separate file paths for the second tier
alluxio.worker.tieredstore.level1.dirs.path=/mnt/hdd1,/mnt/hdd2,/mnt/hdd3
# defined HDD to be the medium type of the second tier
alluxio.worker.tieredstore.level1.dirs.mediumtype=HDD,HDD,HDD
# define the quota for each of the 3 file paths of the second tier
alluxio.worker.tieredstore.level1.dirs.quota=2TB,5TB,500GB
可配置层数没有限制 但是每个层都必须使用唯一的别名进行标识。 典型的配置将具有三层,分别是内存,SSD和HDD。 要在HDD层中使用多个硬盘存储,需要在配置alluxio.worker.tieredstore.level{x}.dirs.path时指定多个路径。
块注释策略
Alluxio从v2.3开始使用块注释策略来维护存储中数据块的严格顺序。 注释策略定义了跨层块的顺序,并在以下操作过程中进行用来参考: -释放空间 -动态块放置。
与写操作同步发生的释放空间操作将尝试根据块注释策略强制顺序删除块并释放其空间给写操作。注释顺序的最后一个块是第一个释放空间候选对象,无论它位于哪个层上。
开箱即用的注释策略实施包括:
- LRUAnnotator:根据最近最少使用的顺序对块进行注释和释放。 这是Alluxio的默认注释策略。
- LRFUAnnotator:根据配置权重的最近最少使用和最不频繁使用的顺序对块进行注释。
- 如果权重完全偏设为最近最少使用,则行为将 与LRUAnnotator相同。
- 适用的配置属性包括
alluxio.worker.block.annotator.lrfu.step.factoralluxio.worker.block.annotator.lrfu.attenuation.factor。
workers选择使用的注释策略由Alluxio属性 alluxio.worker.block.annotator.class决定。 该属性应在配置中指定完全验证的策略名称。当前可用的选项有:
alluxio.worker.block.annotator.LRUAnnotatoralluxio.worker.block.annotator.LRFUAnnotator
释放空间模拟
旧的释放空间策略和Alluxio提供的实施现在已去掉了,并用适当的注释策略替换。 配置旧的Alluxio释放空间策略将导致worker启动失败,并报错java.lang.ClassNotFoundException。 同样,旧的基于水位标记配置已失效。因此,以下配置选项是无效的:
-alluxio.worker.tieredstore.levelX.watermark.low.ratio -alluxio.worker.tieredstore.levelX.watermark.high.ratio
然而,Alluxio支持基于自定义释放空间实施算法数据块注释的仿真模式。该仿真模式假定已配置的释放空间策略创建一个基于某种顺序释放空间的计划,并通过定期提取这种自定义顺序来支持块注释活动。
旧的释放空间配置应进行如下更改。 (由于旧的释放空间实施已删除,如未能更改基于旧实施的以下配置就会导致class加载错误。)
-LRUEvictor-> LRUAnnotator -GreedyEvictor-> LRUAnnotator -PartialLRUEvictor-> LRUAnnotator -LRFUEvictor-> LRFUAnnotator
分层存储管理
因为块分配/释放不再强制新的写入必须写到特定存储层,新数据块可能最终被写到任何已配置的存储层中。这样允许写入超过Alluxio存储容量的数据。但是,这就需要Alluxio动态管理块放置。 为了确保层配置为从最快到最慢的假设,Alluxio会基于块注释策略在各层存储之间移动数据块。
每个单独层管理任务都遵循以下配置:
alluxio.worker.management.task.thread.count:管理任务所用线程数。 (默认值:CPU核数)alluxio.worker.management.block.transfer.concurrency.limit:可以同时执行多少个块传输。 (默认:CPU核数/2)
块对齐(动态块放置)
Alluxio将动态地跨层移动数据块,以使块组成与配置的块注释策略一致。
为辅助块对齐,Alluxio会监视I/O模式并会跨层重组数据块,以确保 较高层的最低块比下面层的最高块具有更高的次序。
这是通过“对齐”这个管理任务来实现的。此管理任务在检测到层之间 顺序已乱时,会通过在层之间交换块位置来有效地将各层与已配置的注释策略对齐以消除乱序。 有关如何控制这些新的后台任务对用户I/O的影响,参见管理任务推后部分。
用于控制层对齐:
alluxio.worker.management.tier.align.enabled:是否启用层对齐任务。 (默认:true)alluxio.worker.management.tier.align.range:单个任务运行中对齐多少个块。 (默认值:100)alluxio.worker.management.tier.align.reserved.bytes:配置多层时,默认情况下在所有目录上保留的空间大小。 (默认:1GB) 用于内部块移动。alluxio.worker.management.tier.swap.restore.enabled:控制一个特殊任务,该任务用于在内部保留空间用尽时unblock层对齐。 (默认:true) 由于Alluxio支持可变的块大小,因此保留空间可能会用尽,因此,当块大小不匹配时在块对齐期间在层之间块交换会导致一个目录保留空间的减少。
块升级
当较高层具有可用空间时,低层的块将向上层移动,以便更好地利用较快的磁盘介质,因为假定较高的层配置了较快的磁盘介质。
用于控制动态层升级:
alluxio.worker.management.tier.promote.enabled:是否启用层升级任务。 (默认:true)alluxio.worker.management.tier.promote.range:单个任务运行中升级块数。 (默认值:100)alluxio.worker.management.tier.promote.quota.percent:每一层可以用于升级最大百分比。 一旦其已用空间超过此值,向此层升级将停止。 (0表示永不升级,100表示总是升级。)
管理任务推后
层管理任务(对齐/升级)会考虑用户I/O并在worker/disk重载情况下推后运行。 这是为了确保内部管理任务不会对用户I/O性能产生负面影响。
可以在alluxio.worker.management.backoff.strategy属性中设置两种可用的推后类型,分别是Any和DIRECTORY。
-ANY; 当有任何用户I/O时,worker管理任务将推后。 此模式将确保较低管理任务开销,以便提高即时用户I/O性能。 但是,管理任务要取得进展就需要在worker上花更长的时间。
-DIRECTORY; 管理任务将从有持续用户I/O的目录中推后。 此模式下管理任务更易取得进展。 但是,由于管理任务活动的增加,可能会降低即时用户I/O吞吐量。
影响这两种推后策略的另一个属性是alluxio.worker.management.load.detection.cool.down.time,控制多长时间的用户I/O计为在目标directory/worker上的一个负载。
Alluxio中数据生命周期管理
用户需要理解以下概念,以正确利用可用资源:
- free:释放数据是指从Alluxio缓存中删除数据,而不是从底层UFS中删除数据。 释放操作后,数据仍然可供用户使用,但对Alluxio释放文件后尝试访问该文件 的客户端来讲性能可能会降低。
- load:加载数据意味着将其从UFS复制到Alluxio缓存中。如果Alluxio使用 基于内存的存储,加载后用户可能会看到I/O性能的提高。
- persist:持久数据是指将Alluxio存储中可能被修改过或未被修改过的数据写回UFS。 通过将数据写回到UFS,可以保证如果Alluxio节点发生故障数据还是可恢复的。
- TTL(Time to Live):TTL属性设置文件和目录的生存时间,以 在数据超过其生存时间时将它们从Alluxio空间中删除。还可以配置 TTL来删除存储在UFS中的相应数据。
从Alluxio存储中释放数据free
为了在Alluxio中手动释放数据,可以使用./bin/alluxio文件系统命令 行界面。
$ ./bin/alluxio fs free ${PATH_TO_UNUSED_DATA}
这将从Alluxio存储中删除位于给定路径的数据。如果数据是持久存储到UFS的则仍然可以访问该数据。有关更多信息,参考 命令行界面文档
注意,用户通常不需要手动从Alluxio释放数据,因为 配置的注释策略将负责删除未使用或旧数据。
将数据加载到Alluxio存储中load
如果数据已经在UFS中,使用 alluxio fs load
$ ./bin/alluxio fs load ${PATH_TO_FILE}
要从本地文件系统加载数据,使用命令 alluxio fs copyFromLocal。 这只会将文件加载到Alluxio存储中,而不会将数据持久保存到UFS中。 将写入类型设置为MUST_CACHE写入类型将不会将数据持久保存到UFS, 而设置为CACHE和CACHE_THROUGH将会持久化保存。不建议手动加载数据,因为,当首次使用文件时Alluxio会自动将数据加载到Alluxio缓存中。
在Alluxio中持久化保留数据persist
命令alluxio fs persist 允许用户将数据从Alluxio缓存推送到UFS。
$ ./bin/alluxio fs persist ${PATH_TO_FILE}
如果您加载到Alluxio的数据不是来自已配置的UFS,则上述命令很有用。 在大多数情况下,用户不必担心手动来持久化保留数据。
设置生存时间(TTL)
Alluxio支持命名空间中每个文件和目录的”生存时间(TTL)”设置。此 功能可用于有效地管理Alluxio缓存,尤其是在严格 保证数据访问模式的环境中。例如,如果对上一周提取数据进行分析, 则TTL功能可用于明确刷新旧数据,从而为新文件释放缓存空间。
Alluxio具有与每个文件或目录关联的TTL属性。这些属性将保存为 日志的一部分,所以集群重新后也能持久保持。活跃master节点负责 当Alluxio提供服务时将元数据保存在内存中。在内部,master运行一个后台 线程,该线程定期检查文件是否已达到其TTL到期时间。
注意,后台线程按配置的间隔运行,默认设置为一个小时。 在检查后立即达到其TTL期限的数据不会马上删除, 而是等到一个小时后下一个检查间隔才会被删除。
如将间隔设置为10分钟,在alluxio-site.properties添加以下配置:
alluxio.master.ttl.checker.interval=10m
请参考配置页 CN以获取有关设置Alluxio配置的更多详细信息。
API
有两种设置路径的TTL属性的方法。
- 通过Alluxio shell命令行
- 每个元数据加载或文件创建被动设置
TTL API如下:
SetTTL(path,duration,action)
`path` Alluxio命名空间中的路径
`duration` TTL动作生效前的毫秒数,这会覆盖任何先前的设置
`action` 生存时间过去后要执行的`action`。 `FREE`将导致文件
从Alluxio存储中删除释放,无论其目前的状态如何。 `DELETE`将导致
文件从Alluxio命名空间和底层存储中删除。
注意:`DELETE`是某些命令的默认设置,它将导致文件被
永久删除。
命令行用法
了解如何使用setTtl命令在Alluxio shell中修改TTL属性参阅详细的 命令行文档。
Alluxio中文件上的被动TTL设置
Alluxio客户端可以配置为只要在Alluxio命名空间添加新文件时就添加TTL属性。 当预期用户是临时使用文件情况下,被动TTL很有用 ,但它不灵活,因为来自同一客户端的所有请求将继承 相同的TTL属性。
被动TTL通过以下选项配置:
alluxio.user.file.create.ttl-在Alluxio中文件上设置的TTL持续时间。 默认情况下,未设置TTL持续时间。alluxio.user.file.create.ttl.action-对文件设置的TTL到期后的操作 在Alluxio中。注意:默认情况下,此操作为“DELETE”,它将导致文件永久被删除。
TTL默认情况下处于不使用状态,仅当客户有严格数据访问模式才启用。
例如,要3分钟后删除由runTests创建的文件:
$ ./bin/alluxio runTests -Dalluxio.user.file.create.ttl=3m \
-Dalluxio.user.file.create.ttl.action=DELETE
对于这个例子,确保alluxio.master.ttl.checker.interval被设定为短 间隔,例如一分钟,以便master能快速识别过期文件。
在Alluxio中管理数据复制
被动复制
与许多分布式文件系统一样,Alluxio中的每个文件都包含一个或多个分布在集群中存储的存储块。默认情况下,Alluxio可以根据工作负载和存储容量自动调整不同块的复制级别。例如,当更多的客户以类型CACHE或CACHE_PROMOTE请求来读取此块时Alluxio可能会创建此特定块更多副本。当较少使用现有副本时,Alluxio可能会删除一些不常用现有副本 来为经常访问的数据征回空间(块注释策略)。 在同一文件中不同的块可能根据访问频率不同而具有不同数量副本。
默认情况下,此复制或征回决定以及相应的数据传输 对访问存储在Alluxio中数据的用户和应用程序完全透明。
主动复制
除了动态复制调整之外,Alluxio还提供API和命令行 界面供用户明确设置文件的复制级别目标范围。 尤其是,用户可以在Alluxio中为文件配置以下两个属性:
alluxio.user.file.replication.min是此文件的最小副本数。 默认值为0,即在默认情况下,Alluxio可能会在文件变冷后从Alluxio管理空间完全删除该文件。 通过将此属性设置为正整数,Alluxio 将定期检查此文件中所有块的复制级别。当某些块 的复制数不足时,Alluxio不会删除这些块中的任何一个,而是主动创建更多 副本以恢复其复制级别。alluxio.user.file.replication.max是最大副本数。一旦文件该属性 设置为正整数,Alluxio将检查复制级别并删除多余的 副本。将此属性设置为-1为不设上限(默认情况),设置为0以防止 在Alluxio中存储此文件的任何数据。注意,alluxio.user.file.replication.max的值 必须不少于alluxio.user.file.replication.min。
例如,用户可以最初使用至少两个副本将本地文件/path/to/file复制到Alluxio:
$ ./bin/alluxio fs -Dalluxio.user.file.replication.min=2 \
copyFromLocal /path/to/file /file
接下来,设置/file的复制级别区间为3到5。需要注意的是,在后台进程中完成新的复制级别范围设定后此命令将马上返回,实现复制目标是异步完成的。
$ ./bin/alluxio fs setReplication --min 3 --max 5 /file
设置alluxio.user.file.replication.max为无上限。
$ ./bin/alluxio fs setReplication --max -1 /file
重复递归复制目录/dir下所有文件复制级别(包括其子目录)使用-R:
$ ./bin/alluxio fs setReplication --min 3 --max -5 -R /dir
要检查的文件的目标复制水平,运行
$ ./bin/alluxio fs stat /foo
并在输出中查找replicationMin和replicationMax字段。
检查Alluxio缓存容量和使用情况
Alluxio shell命令fsadmin report提供可用空间的简短摘要 以及其他有用的信息。输出示例如下:
$ ./bin/alluxio fsadmin report
Alluxio cluster summary:
Master Address: localhost/127.0.0.1:19998
Web Port: 19999
Rpc Port: 19998
Started: 09-28-2018 12:52:09:486
Uptime: 0 day(s), 0 hour(s), 0 minute(s), and 26 second(s)
Version: 2.0.0
Safe Mode: true
Zookeeper Enabled: false
Live Workers: 1
Lost Workers: 0
Total Capacity: 10.67GB
Tier: MEM Size: 10.67GB
Used Capacity: 0B
Tier: MEM Size: 0B
Free Capacity: 10.67GB
Alluxio shell还允许用户检查Alluxio缓存中多少空间可用和在用。
获得Alluxio缓存总使用字节数运行:
$ ./bin/alluxio fs getUsedBytes
获得Alluxio缓存以字节为单位的总容量
$ ./bin/alluxio fs getCapacityBytes
Alluxio master web界面为用户提供了集群的可视化总览包括已用多少存储空间。可以在http:/{MASTER_IP}:${alluxio.master.web.port}/中找到。 有关Alluxio Web界面的更多详细信息可以在 相关文档 中找到。
二、统一命名空间
本页总结了如何在Alluxio文件系统名称空间中管理不同的底层存储系统。
介绍
Alluxio通过使用透明的命名机制和挂载API来实现有效的跨不同底层存储系统的数据管理。
统一命名空间
Alluxio提供的主要好处之一是为应用程序提供统一命名空间。 通过统一命名空间的抽象,应用程序可以通过统一命名空间和接口来访问多个独立的存储系统。 与其与每个独立的存储系统进行通信,应用程序可以只连接到Alluxio并委托Alluxio来与不同的底层存储通信。

master配置属性alluxio.master.mount.table.root.ufs指定的目录挂载到Alluxio命名空间根目录,该目录代表Alluxio 的”primary storage”。在此基础上,用户可以通过挂载API添加和删除数据源。
void mount(AlluxioURI alluxioPath, AlluxioURI ufsPath);
void mount(AlluxioURI alluxioPath, AlluxioURI ufsPath, MountOptions options);
void unmount(AlluxioURI path);
void unmount(AlluxioURI path, UnmountOptions options);
例如,可以通过以下方式将一个新的S3存储桶挂载到Data目录中
mount(new AlluxioURI("alluxio://host:port/Data"), new AlluxioURI("s3://bucket/directory"));
UFS命名空间
除了Alluxio提供的统一命名空间之外,每个已挂载的基础文件系统 在Alluxio命名空间中有自己的命名空间; 称为UFS命名空间。 如果在没有通过Alluxio的情况下更改了UFS名称空间中的文件, UFS命名空间和Alluxio命名空间可能不同步的情况。 发生这种情况时,需要执行UFS元数据同步操作才能重新使两个名称空间同步。
透明命名机制
透明命名机制保证了Alluxio和底层存储系统命名空间身份一致性。
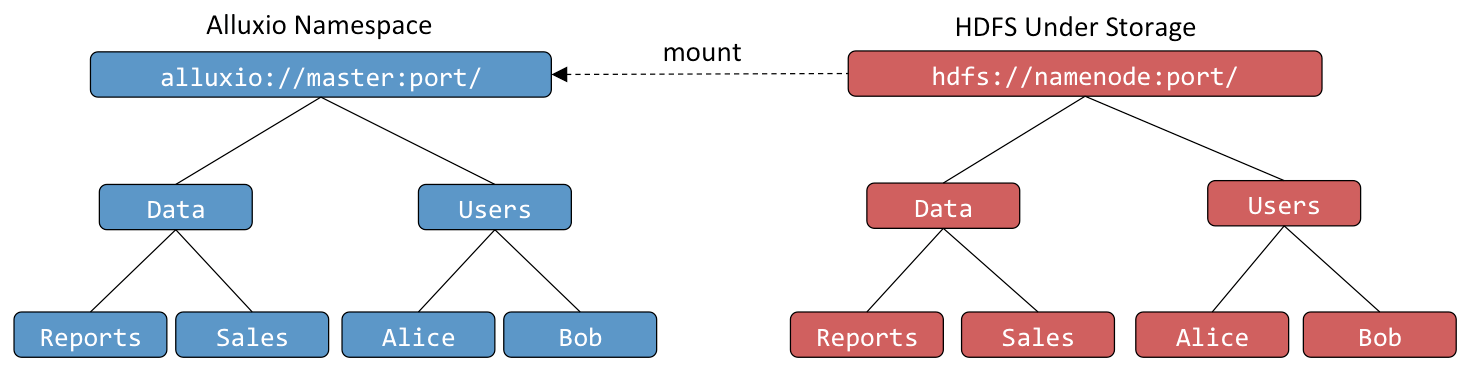
当用户在Alluxio命名空间创建对象时,可以选择这些对象是否要在底层存储系统中持久化。对于需要持久化的对象, Alluxio会保存底层存储系统存储这些对象的路径。例如,一个用户在根目录下创建了一个Users目录及Alice和Bob两个子目录,底层存储系统也会保存相同的目录结构和命名。类似地,当用户在 Alluxio命名空间中对一个持久化的对象进行重命名或者删除操作时,底层存储系统中也会对其执行相同的重命名或删除操作。
Alluxio能够透明发现底层存储系统中并非通过Alluxio创建的内容。例如,底层存储系统中包含一个Data文件夹, 其中包含Reports和Sales文件,都不是通过Alluxio创建的,当它们第一次被访问时,如用户请求打开文 件,Alluxio会自动加载这些对象的元数据。然而在该过程中Alluxio不会加载文件内容数据,若要将其内容加载到Alluxio, 可以用FileInStream来读数据,或者通过Alluxio Shell中的load命令。
挂载底层存储系统
定义Alluxio命名空间和UFS命名空间之间的关联是通过将底层存储系统挂载到Alluxio文件系统命名空间的机制完成的。 在Alluxio中挂载底层存储与在Linux文件系统中挂载一个卷类似。 mount命令将UFS挂载到Alluxio命名空间中文件系统树。
根挂载点
Alluxio命名空间的根挂载点是在masters上’conf/alluxio-site.properties’中配置的。 下一行是一个配置样例,一个HDFS路径挂载到 Alluxio命名空间根目录。
alluxio.master.mount.table.root.ufs=hdfs://HDFS_HOSTNAME:8020
使用配置前缀来配置根挂载点的挂载选项:
alluxio.master.mount.table.root.option.<some alluxio property>
例如,以下配置为根挂载点添加AWS凭证。
alluxio.master.mount.table.root.option.aws.accessKeyId=<AWS_ACCESS_KEY_ID>
alluxio.master.mount.table.root.option.aws.secretKey=<AWS_SECRET_ACCESS_KEY>
以下配置显示了如何为根挂载点设置其他参数。
alluxio.master.mount.table.root.option.alluxio.security.underfs.hdfs.kerberos.client.principal=client
alluxio.master.mount.table.root.option.alluxio.security.underfs.hdfs.kerberos.client.keytab.file=keytab
alluxio.master.mount.table.root.option.alluxio.security.underfs.hdfs.impersonation.enabled=true
alluxio.master.mount.table.root.option.alluxio.underfs.version=2.7
嵌套挂载点
除了根挂载点之外,其他底层文件系统也可以挂载到Alluxio命名空间中。 这些额外的挂载点可以通过mount命令在运行时添加到Alluxio。 --option选项允许用户传递挂载操作的附加参数,如凭证。
# the following command mounts an hdfs path to the Alluxio path `/mnt/hdfs`
$ ./bin/alluxio fs mount /mnt/hdfs hdfs://host1:9000/data/
# the following command mounts an s3 path to the Alluxio path `/mnt/s3` with additional options specifying the credentials
$ ./bin/alluxio fs mount \
--option aws.accessKeyId=<accessKeyId> --option aws.secretKey=<secretKey> \
/mnt/s3 s3://data-bucket/
注意,挂载点也允许嵌套。 例如,如果将UFS挂载到 alluxio:///path1,可以在alluxio:///path1/path2处挂载另一个UFS。
使用特定版本挂载UFS
Alluxio支持挂载特定不同版本HDFS。 因此,用户可以将不同版本的HDFS挂载到同一个Alluxio命名空间中。 有关更多详细信息,请参考HDFS底层存储。
Alluxio和UFS命名空间之间的关系
Alluxio提供了一个统一的命名空间,充当一个或多个底层文件存储系统的数据缓存层。 本节讨论Alluxio如何与底层文件系统交互来发现和通过Alluxio呈现这些文件。
通过Alluxio访问UFS文件的与直接通过UFS访问文件的相同。 如果UFS根目录是s3://bucket/data,则列出alluxio:///下内容应该与列出s3://bucket/data相同。 在alluxio:///file上运行cat的结果应与在s3://bucket/data/file上运行cat的结果相同。
Alluxio按需从UFS加载元数据。 在上面的示例中,Alluxio在启动时并没有有关s3://bucket/data/file的信息。 直到当用户试图列出alluxio:///或尝试使用cat alluxio:///file时,才发现该文件。 这样好处是可以防止在安装新的UFS时进行不必要的文件发现工作。
默认情况下,* Alluxio预期所有对底层文件系统修改都是通过Alluxio 来进行的*。 这样Alluxio只需扫描每个UFS目录一次,从而在UFS元数据操作很慢情况下显著提高性能。 当出现在Alluxio之外对UFS进行更改的情况下, 就需要用元数据同步功能用于同步两个命名空间。
UFS元数据同步
UFS元数据同步功能新增自版本
1.7.0。
当Alluxio扫描UFS目录并加载其子目录元数据时, 它将创建元数据的副本,以便将来无需再从UFS加载。 元数据的缓存副本将根据 alluxio.user.file.metadata.sync.interval客户端属性配置的间隔段刷新。 此属性适用于客户端操作。 例如,如果客户执行一个命令基于间隔设置为一分钟的配置, 如果最后一次刷新是在一分钟之前,则相关元数据将据UFS刷新。 设值为0表示针对每个操作都会进行实时元数据同步, 而默认值-1表示在初始加载后不会再重新同步元数据。
低间隔值使Alluxio客户端可以快速发现对UFS的外部修改, 但由于导致调用UFS的次数增加,因此是以降低性能为代价的。
元数据同步会保留每个UFS文件的指纹记录,以便Alluxio可以在文件更改时做出相应更新。 指纹记录包括诸如文件大小和上次修改时间之类的信息。 如果在UFS中修改了文件,Alluxio将通过指纹检测到该修改,释放现有文件 元数据,然后重新加载更新文件的元数据。 如果在UFS中添加或删除了文件,Alluxio还将更新对其命名空间中的元数据做出相应刷新。
用于管理UFS同步的方法
定期元数据同步
如果UFS按计划的间隔更新,可以在更新后手动触发sync命令。 运行以下命令将同步间隔设置为0:
$ ./bin/alluxio fs ls -R -Dalluxio.user.file.metadata.sync.interval=0 /path/to/sync
集中配置
对于使用来自频繁更新的UFS数据的集群作业, 每个客户端指定一个同步间隔很不方便。 如果在master配置中设置了同步间隔,所有请求都将以默认的同步间隔来处理。
在master点上的alluxio-site.properties中设置:
alluxio.user.file.metadata.sync.interval=1m
注意,需要
1)同步配置到所有节点 alluxio copyDir conf/
2)重新启动master节点以便启用新配置。
### 其他加载新UFS文件的方法
建议使用前面讨论的UFS同步的方法来同步UFS中的更改。 这是是其他一些加载文件的方法:
*alluxio.user.file.metadata.load.type:此客户端属性可以设置为 ALWAYS,ONCE或NEVER。此属性类似alluxio.user.file.metadata.sync.interval, 但有注意事项: 1.它只会发现新文件,不会重新加载修改或删除的文件。 1.它仅适用于exists,list和getStatus RPC。
`ALWAYS`配置意味者总会检查UFS中是否有新文件,`ONCE`将使用默认值 仅扫描每个目录一次,而`NEVER`配置下Alluxio根本不会 扫描新文件。
*alluxio fs ls -f /path:ls的-f选项相当于设置 alluxio.user.file.metadata.load.type为ALWAYS。它将发现新文件,但 不检测修改或删除的UFS文件。 要检测修改或删除的UFS文件的唯一方法是通过传递 -Dalluxio.user.file.metadata.sync.interval=0选项给ls。
示例
以下示例假设Alluxio源代码在${ALLUXIO_HOME}文件夹下,并且有一个本地运行的Alluxio进程。
透明命名
先在本地文件系统中创建一个将作为底层存储挂载的临时目录:
$ cd /tmp
$ mkdir alluxio-demo
$ touch alluxio-demo/hello
将创建的目录挂载到Alluxio命名空间中,并确认挂载后的目录在Alluxio中存在:
$ cd ${ALLUXIO_HOME}
$ ./bin/alluxio fs mount /demo file:///tmp/alluxio-demo
Mounted file:///tmp/alluxio-demo at /demo
$ ./bin/alluxio fs ls -R /
... # note that the output should show /demo but not /demo/hello
验证对于不是通过Alluxio创建的内容,当第一次被访问时,其元数据被加载进入了Alluxio中:
$ ./bin/alluxio fs ls /demo/hello
... # should contain /demo/hello
在挂载目录下创建一个文件,并确认在底层文件系统中该文件也被以同样名字创建了:
$ ./bin/alluxio fs touch /demo/hello2
/demo/hello2 has been created
$ ls /tmp/alluxio-demo
hello hello2
在Alluxio中重命名一个文件,并验证在底层文件系统中该文件也被重命名了:
$ ./bin/alluxio fs mv /demo/hello2 /demo/world
Renamed /demo/hello2 to /demo/world
$ ls /tmp/alluxio-demo
hello world
在Alluxio中删除一个文件,然后确认该文件是否在底层文件系统中也被删除了:
$ ./bin/alluxio fs rm /demo/world
/demo/world has been removed
$ ls /tmp/alluxio-demo
hello
卸载该挂载目录,并确认该目录已经在Alluxio命名空间中被删除,但该目录依然保存在底层文件系统中。
$ ./bin/alluxio fs unmount /demo
Unmounted /demo
$ ./bin/alluxio fs ls -R /
... # should not contain /demo
$ ls /tmp/alluxio-demo
hello
HDFS元数据主动同步
在2.0版中,引入了一项新功能,用于在UFS为HDFS时保持Alluxio空间与UFS之间的同步。 该功能称为主动同步,可监听HDFS事件并以master上后台任务方式定期在UFS和Alluxio命名空间之间同步元数据。 由于主动同步功能取决于HDFS事件,因此仅当UFS HDFS版本高于2.6.1时,此功能才可用。 你可能需要在配置文件中更改alluxio.underfs.version的值。 有关所支持的Hdfs版本的列表,请参考HDFS底层存储。
要在一个目录上启用主动同步,运行以下Alluxio命令。
$ ./bin/alluxio fs startSync /syncdir
可以通过更改alluxio.master.ufs.active.sync.interval选项来控制主动同步间隔,默认值为30秒。
要在一个目录上停止使用主动同步,运行以下Alluxio命令。
$ ./bin/alluxio fs stopSync /syncdir
注意:发布
startSync时,就预定了对同步点进行完整扫描。 如果以Alluxio超级用户身份运行,stopSync将中断所有尚未结束的完整扫描。 如果以其他用户身份运行,stopSync将等待完整扫描完成后再执行。
可以使用以下命令检查哪些目录当前处于主动同步状态。
$ ./bin/alluxio fs getSyncPathList
主动同步的静默期
主动同步会尝试避免在目标目录被频繁使用时进行同步。 它会试图在UFS活动期寻找一个静默期,再开始UFS和Alluxio空间之间同步,以避免UFS繁忙时使其过载。 有两个配置选项来控制此特性。
alluxio.master.ufs.active.sync.max.activities是UFS目录中的最大活动数。 活动数的计算是基于目录中事件数的指数移动平均值的启发式方法。 例如,如果目录在过去三个时间间隔中有100、10、1个事件。 它的活动为100/10 * 10 + 10/10 + 1 = 3 alluxio.master.ufs.active.sync.max.age是在同步UFS和Alluxio空间之前将等待的最大间隔数。
系统保证如果目录“静默”或长时间未同步(超过最大期限),我们将开始同步该目录。
例如,以下设置
alluxio.master.ufs.active.sync.interval=30sec
alluxio.master.ufs.active.sync.max.activities=100
alluxio.master.ufs.active.sync.max.age=5
表示系统每隔30秒就会计算一次此目录的事件数, 并计算其活动。 如果活动数少于100,则将其视为一个静默期,并开始同步 该目录。 如果活动数大于100,并且在最近5个时间间隔内未同步,或者 5 * 30 = 150秒,它将开始同步目录。 如果活动数大于100并且至少已在最近5个间隔中同步过一次,将不会执行主动同步。
统一命名空间
此示例将安装多个不同类型的底层存储,以展示统一文件系统命名空间的抽象作用。 本示例将使用属于不同AWS账户和一个HDSF服务的两个S3存储桶。
使用相对应凭证<accessKeyId1>和<secretKey1>将第一个S3存储桶挂载到Alluxio中:
$ ./bin/alluxio fs mkdir /mnt
$ ./bin/alluxio fs mount \
--option aws.accessKeyId=<accessKeyId1> \
--option aws.secretKey=<secretKey1> \
/mnt/s3bucket1 s3://data-bucket1/
使用相对应凭证’’和’ ’将第二个S3存储桶挂载到Alluxio:
$ ./bin/alluxio fs mount \
--option aws.accessKeyId=<accessKeyId2> \
--option aws.secretKey=<secretKey2> \
/mnt/s3bucket2 s3://data-bucket2/
将HDFS存储挂载到Alluxio:
$ ./bin/alluxio fs mount /mnt/hdfs hdfs://<NAMENODE>:<PORT>/
所有这三个目录都包含在Alluxio的一个命名空间中:
$ ./bin/alluxio fs ls -R /
... # should contain /mnt/s3bucket1, /mnt/s3bucket2, /mnt/hdfs
资源
- 一篇博客文章,解释了统一命名空间
- 关于[优化以加快元数据操作速度]的博客文章(https://www.alluxio.io/blog/how-to-speed-up-alluxio-metadata-operations-up-to-100x/)
三、Catalog
概述
Alluxio 2.1.0引入了一项Alluxio目录服务的新Alluxio服务。 Alluxio目录是用于管理对结构化数据访问的服务, 所提供服务类似于Apache Hive Metastore
SQL Presto,SparkSQL和Hive等引擎利用这些类似于元数据存储的服务来确定执行查询时要读取哪些数据以及读取多少数据。Catalog中存储有关不同数据库目录,表,存储格式,数据位置等及更多信息。 Alluxio目录服务旨在使为Presto查询引擎提供结构化表元数据检索和服务变得更简单和直接,例如PrestoSQL, PrestoDB和Starburst Presto。
系统架构
Alluxio目录服务的设计与普通的Alluxio文件系统非常相似。 服务本身并不负责保有所有数据,而是作为一个源自另一个位置(如MySQL,Hive)的 元数据缓存服务。 这些被称为UDB(Under DataBase)。 UDB负责元数据的管理和存储。 当前,Hive是唯一支持的UDB。 Alluxio目录服务通过Alluxio文件系统命名空间来缓存和使元数据全局可用。
Query Engine Metadata service Under meta service
+--------+ +--------------------------+ +----------------+
| Presto | <---> | Alluxio Catalog Service | <---> | Hive Metastore |
+--------+ +--------------------------+ +----------------+
当用户表跨多个存储服务(即AWS S3,HDFS,GCS)时, 为了做查询和读取等请求,通常用户需要配置其SQL引擎分别逐一连接到每个存储服务, 使用了Alluxio目录服务之后,用户只需配置一个Alluxio客户端,通过Alluxio就可以读取和查询任何支持的底层存储系统及数据。
使用Alluxio目录服务
以下是Alluxio目录服务的基本配置参数以及与Alluxio目录服务交互的方式。更多详细信息 可以在[命令行界面文档]中找到(…/…/en/operation/User-CLI.html#table-operations)。
Alluxio服务器配置
默认情况下,目录服务是启用的。要明确停止目录服务,添加以下配置行到 alluxio-site.properties
alluxio.table.enabled=false
默认情况下,挂载的数据库和表将在Alluxio/catalog目录下。 可以通过以下配置为目录服务配置非默认根目录,
alluxio.table.catalog.path=</desired/alluxio/path>
附加数据库
为了让Alluxio能提供有关结构化表数据信息服务,必须告知Alluxio 有关数据库的位置。 使用Table CLI来执行任何与从Alluxio附加,浏览或分离数据库相关操作。
$ ${ALLUXIO_HOME}/bin/alluxio tableUsage: alluxio table [generic options] [attachdb [-o|--option <key=value>] [--db <alluxio db name>] [--ignore-sync-errors] <udb type> <udb connection uri> <udb db name>] [detachdb <db name>] [ls [<db name> [<table name>]]] [sync <db name>] [transform <db name> <table name>] [transformStatus [<job ID>]]
要附加数据库,使用attachdb命令。目前,hive和glue是支持的 <udb type>。 有关更多详细信息参见attachdb命令文档。 以下命令从位于Thrift://metastore_host:9083的元数据存储将hive数据库default映射到Alluxio中名为alluxio_db的数据库
$ ${ALLUXIO_HOME}/bin/alluxio table attachdb --db alluxio_db hive \ thrift://metastore_host:9083 default
**注意:**附加数据库后,所有表都从已配置的UDB同步过了。 如果数据库或表发生带外更新,并且用户希望查询结果反映这些 更新,则必须同步数据库。有关更多信息参见同步数据库。
探索附加的数据库
数据库一旦附加,通过alluxio table ls检查已挂载数据库
$ ${ALLUXIO_HOME}/bin/alluxio table lsalluxio_db
通过alluxio tables ls <db_name>列出数据库下所有表。 相应hive数据库中存在的所有表都会通过此命令列出
$ ${ALLUXIO_HOME}/bin/alluxio table ls alluxio_dbtest
在上述情况下,alluxio_db有一个表test。要获取数据库中表的更多信息,运行
$ alluxio table ls <db_name> <table_name>
此命令会将表的信息通过控制台输出。输出示例如下:
$ ${ALLUXIO_HOME}/bin/alluxio table ls alluxio_db testdb_name: "alluxio_db"table_name: "test"owner: "alluxio"schema { cols { name: "c1" type: "int" comment: "" }}layout { layoutType: "hive" layoutSpec { spec: "test" } layoutData: "\022\004test\032\004test\"\004test*\345\001\n\232\001\n2org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe\022(org.apache.hadoop.mapred.TextInputFormat\032:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat\0227alluxio://localhost:19998/catalog/test/tables/test/hive\032\v\020\377\377\377\377\377\377\377\377\377\001 \0002\v\022\002c1\032\003int*\000"}parameters { key: "totalSize" value: "6"}parameters { key: "numRows" value: "3"}parameters { key: "rawDataSize" value: "3"}parameters { key: "COLUMN_STATS_ACCURATE" value: "{\"BASIC_STATS\":\"true\"}"}parameters { key: "numFiles" value: "3"}parameters { key: "transient_lastDdlTime" value: "1571191595"}
分离数据库
如果需要分离数据库,可以从Alluxio命名空间用以下命令
$ alluxio table detach <database name>
针对前面的例子,分离数据库可以运行:
$ ${ALLUXIO_HOME}/bin/alluxio table detachdb alluxio_db
运行上述命令之后再运行alluxio table ls将不会再显示已分离的数据库。
同步数据库
当原始底层数据库和表更新后,用户可以调用sync命令 来刷新存储在Alluxio目录元数据中的相应信息。 有关更多详细信息参见sync命令文档。
$ alluxio table sync <database name>
针对前面的例子,可以运行以下命令来sync数据
$ ${ALLUXIO_HOME}/bin/alluxio table sync alluxio_db
上述sync命令将根据UDB表的更新,删除,和添加等来刷新Alluxio相应目录元数据。
通过Presto使用Alluxio结构化数据
PrestoSQL版本332或更高版本以及PrestoDB版本0.232或更高版本在其hive-hadoop2连接器中内置了对Alluxio目录服务的支持。 有关使用PrestoSQL或PrestoDB相应版本设置Alluxio目录服务的说明, 请参阅PrestoSQL文档documentation 或PrestoDB文档documentation。
如果使用的是PrestoSQL或PrestoDB的早期版本,则可以使用alluxio发行版中包含的hive-alluxio连接器。 最新的Alluxio发行版包含一个presto连接器jar文件,可以通过将其放入 $ {PRESTO_HOME}/plugins目录中激活经由Presto到目录服务的连接。
在Presto中启用Alluxio目录服务
假设已经分别在本地计算机上的
‘
`
‘{ALLUXIO_HOME}和${PRESTO_HOME}` 上安装了Alluxio和Presto ,要启用Alluxio目录服务需要在所有Presto节点上将Alluxio连接器文件作为一个新的插件复制到 Presto安装中。
对于PrestoSQL安装,运行以下命令。
$ cp -R ${ALLUXIO_HOME}/client/presto/plugins/presto-hive-alluxio-319/ ${PRESTO_HOME}/plugin/hive-alluxio/
对于PrestoDB安装,运行以下命令。
$ cp -R ${ALLUXIO_HOME}/client/presto/plugins/prestodb-hive-alluxio-227/ ${PRESTO_HOME}/plugin/hive-alluxio/
另外,你还需要创建一个新的目录来使用Alluxio连接器和 Alluxio目录服务
/etc/catalog/catalog_alluxio.propertiesconnector.name=hive-alluxiohive.metastore=alluxiohive.metastore.alluxio.master.address=HOSTNAME:PORT
创建catalog_alluxio.properties文件,意味着一个名为catalog_alluxio新的目录 添加到Presto。 设置connector.name=hive-alluxio会将连接器类型设置为Presto新Alluxio连接器名称,即hive-alluxio。 如果使用的是PrestoSQL版本332或更高版本以及PrestoDB版本0.232或更高版本,hive-hadoop2连接器中内置了对Alluxio Catalog Service的支持,因此应设置connector.name=hive-hadoop2。 hive.metastore=alluxio表示Hive元数据存储连接将使用alluxio类型与Alluxio目录服务进行通信。 设置hive.metastore.alluxio.master.address=HOSTNAME:PORT定义了 Alluxio目录服务的主机和端口,与Alluxio master主机和端口相同。 一旦在每个节点上配置后,重新启动所有presto coordinators和workers。
###在Presto中使用Alluxio目录服务
为了使用Alluxio Presto插件,使用以下命令启动presto CLI(假设 /etc/catalog/catalog_alluxio.properties文件已创建)
$ presto --catalog catalog_alluxio
默认情况下,presto执行的任何查询都会通过Alluxio的目录服务来获取数据库和表信息。
通过运行以下一些查询来确认配置正确:
- 列出附加的数据库:
SHOW SCHEMAS;
- 列出一种数据库模式下的表:
SHOW TABLES FROM <schema name>;
- 运行一个简单的查询,该查询将从元数据存储中读取数据并从表中加载数据:
DESCRIBE <schema name>.<table name>;SELECT count(*) FROM <schema name>.<table name>;
四、数据转换
数据转换
通过作业服务和目录服务,Alluxio可以将一个表转换为新表。如果表未分区,则转换是在表级运行的。如果表已分区,则转换将在分区级运行。原始表的数据是不会被修改的,新表的数据将在Alluxio管理的新存储位置永久保留。一旦转换完成后,Presto用户可以透明地查询新数据。
目前有两种支持的转换类型:
1.合并文件,以便每个文件都至少达到一定的大小,并且最多不超过一定数量的文件。 2.将CSV文件转换为Parquet文件
在Alluxio版本2.3.0中,转换后的数据将总写为Parquet格式。
在运行转换之前,首先要attach一个数据库。以下命令将Hive中的“默认”数据库attach到Alluxio。
$ ${ALLUXIO_HOME}/bin/alluxio table attachdb hive thrift://localhost:9083 default
转换是通过命令行界面调用的。以下命令将表test的每个分区下的文件合并为最多100个文件。 可在command line interface documentation找到有关transform命令的其他详细信息。
$ ${ALLUXIO_HOME}/bin/alluxio table transform default test
运行上面的命令后,你会看到如下输出
Started transformation job with job ID 1572296710137, you can monitor the status of the job with './bin/alluxio table transformStatus 1572296710137'.
现在,按输出中的指令来监控数据变换的状态
$ ${ALLUXIO_HOME}/bin/alluxio table transformStatus 1572296710137
上述命令将显示转换作业的状态
database: defaulttable: testtransformation: write(hive).option(hive.file.count.max, 100).option(hive.file.size.min, 2147483648)job ID: 1572296710137job status: COMPLETED
因转换成功完成,现在可以直接在转换后的表上透明地运行Presto查询。
可以使用以下Presto查询找到转换后的数据的位置:
presto:default> select "$path" from test;
应看到类似如下输出:
alluxio://localhost:19998/catalog/default/tables/test/_internal_/part=0/20191024-213102-905-R29w

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)