查询和删除mysql表中某个字段重复数据的几种方式
关于删除mysql表中某个字段重复数据问题重复一次首先查出重复的数据删除sql几个关键点解释下:重复多次(不确定几次)首先查出重复的数据删除sql几个关键点解释下:写在最后重复一次首先查出重复的数据SELECT*FROMtbl_employee e,( SELECT max(id) id &nb
·
关于删除mysql表中某个字段重复数据问题
方式一 (重复一次)
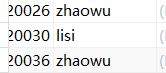
首先查出重复的数据
SELECT
*
FROM
tbl_employee e,(
SELECT max(id) id
FROM tbl_employee d
GROUP BY d.last_name
HAVING COUNT(1)>1
) re_id_table
WHERE e.id = re_id_table.id

删除
DELETE
e
FROM
tbl_employee e,(
SELECT max(id) id
FROM tbl_employee d
GROUP BY d.last_name
HAVING COUNT(1)>1
) re_id_table
WHERE e.id = re_id_table.id
sql几个关键点解释下:
- 由于mysql的SELECT中只能写GROUP BY中的有的字段(不包括聚合函数,可以设置sqlmode取消),所以可以通过聚合函数的形式(MAX(id)/MIN(id))查出非分组字段也就是id。多条记录要删除id最大的就用MAX(),id最小的就用MIN()
- DELETE时的语法,如果表用了别名,要在DELETE后面加上表的别名。
当然也可以使用重复一次的语句删除多次的重复纪录,就是执行多次
方式二(重复多次(不确定几次))
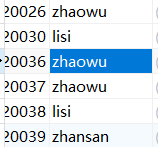
首先查出重复的数据
SELECT
*
FROM
tbl_employee e
WHERE e.id NOT IN (
SELECT IFNULL(MIN(id),e.id)
FROM (
SELECT min(id) id,d.last_name
FROM tbl_employee d
GROUP BY d.last_name
HAVING COUNT(1)>1
) as b
WHERE e.last_name = b.last_name
)

删除
DELETE
e
FROM
tbl_employee e
WHERE e.id NOT IN (
SELECT IFNULL(MIN(id),e.id)
FROM (
SELECT min(id) id,d.last_name
FROM tbl_employee d
GROUP BY d.last_name
HAVING COUNT(1)>1
) as b
WHERE e.last_name = b.last_name
)
sql几个关键点解释下:
- WHERE e.last_name = b.last_name 使用相关子查询将外表的数据代入内表。
- 为什么这么写IFNULL(MIN(id),e.id) :由于查不到数据返回N/A(Not Applicable,不适用的意思),需要使用聚合函数将其转换为null来判断。e.id就是外表的id。不重复的数据就返回自身id,(这是不删除不重复数据的关键)这样就不会删除不重复的数据了。
方式三 利用窗口函数删除多条重复纪录(mysql8.0以上版本支持窗口函数)
查询重复的数据
SELECT *
FROM (
SELECT ROW_NUMBER() OVER w AS row_num,last_name,id
FROM tbl_employee
WINDOW w AS (PARTITION BY last_name ORDER BY id)
)t
WHERE row_num >1
删除重复数据
DELETE
FROM tbl_employee
WHERE id in (
SELECT id
FROM(
SELECT *
FROM (
SELECT ROW_NUMBER() OVER w AS row_num,last_name,id
FROM tbl_employee
WINDOW w AS (PARTITION BY last_name ORDER BY id)
)t
WHERE row_num >1
)e
)
写在最后
当然,不建议直接删除数据,可以逻辑删除,改成相应的update语句

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)