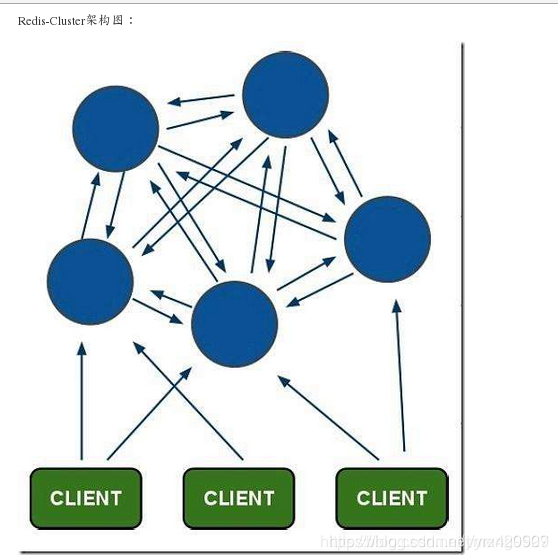
Redis-Cluster集群
Redis-Cluster集群Redis-Cluster集群简介一、Redis-Cluster集群介绍1、redis cluster集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。2、Redis cluster集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点。3、高达 1000 个节点的高性能和线性
Redis-Cluster集群
Redis-Cluster集群简介
一、Redis-Cluster集群介绍
1、redis cluster集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。
2、Redis cluster集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点。
3、高达 1000 个节点的高性能和线性可扩展性。没有代理,使用异步复制,并且不对值执行合并操作。
二、为何使用Redis-Cluster集群
Redis集群演变过程
1.单机版
核心技术:持久化 持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
2.主从复制
复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷是故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
3.哨兵
在复制的基础上,哨兵实现了自动化的故障恢复。缺陷是写操作无法负载均衡;存储能力受到单机的限制。
4.集群
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案
三、Redis-Cluster集群设计
Redis-Cluster采用无中心结构,其结构特点: 1、每个节点都和其它节点通过互ping保持连接,每个节点保存整个集群的状态信息,可以通过连接任意节点读取或者写入数据(甚至是没有数据的空节点)。 2、节点的fail是通过集群中超过半数的节点检测失效时才生效。 3、Redis集群预分好16384个槽,当需要在 Redis 集群中放置一个 key-value 时,根据公式HASH_SLOT=CRC16(key) mod 16384的值,决定将一个key放到哪个槽中。
四、Redis-Cluster集群缺点
-
数据通过异步复制,不保证数据的强一致性。
-
Redis Cluster 不支持像 Redis 的独立版本那样支持多个数据库。只有数据库 0 并且不允许使用SELECT命令。
-
Key 批量操作限制,如使用 mset、mget 目前只支持具有相同 slot 值的 Key 执行批量操作。对于映射为不同 slot 值的 Key 由于 Keys 不支持跨 slot 查询,所以执行 mset、mget、sunion 等操作支持不友好。
-
Key 事务操作支持有限,只支持多 key 在同一节点上的事务操作,当多个 Key 分布于不同的节点上时无法使用事务功能。
Redis-Cluster集群搭建
一、Cluster集群搭建
[详情参考博客] https://www.cnblogs.com/mafly/p/redis_cluster.html
1、创建目录
#创建集群目录
mkdir /usr/local/redis-cluster
#创建实例目录
mkdir -p 900{1,2,3,4,5,6}/data
2、拷贝redis实例
cp /usr/local/redis/redis.conf /usr/local/redis-cluster/9001
3、修改实例配置文件
port 9001(每个节点的端口号) daemonize yes dir /usr/local/redis-cluster/9001/data/(数据文件存放位置) pidfile /var/run/redis_9001.pid(pid 9001和port要对应) cluster-enabled yes(启动集群模式) cluster-config-file nodes9001.conf(9001和port要对应) cluster-node-timeout 15000 appendonly yes
4、再复制出五个新 Redis 实例
\cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9002 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9003 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9004 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9005 \cp -rf /usr/local/redis-cluster/9001/* /usr/local/redis-cluster/9006
5、修改配置文件
vim redis.conf #批量替换 :%s/9001/9002
6、启动redis实例
/usr/local/bin/redis-server /usr/local/redis-cluster/9001/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9002/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9003/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9004/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9005/redis.conf /usr/local/bin/redis-server /usr/local/redis-cluster/9006/redis.conf
7、创建集群
#使用redis-cli --cluster命令创建集群 redis-cli --cluster create 120.78.204.98:9001 120.78.204.98:9002 120.78.204.98:9003 120.78.204.98:9004 120.78.204.98:9005 120.78.204.98:9006 --cluster-replicas 1
上图则代表集群搭建成功啦!!!
二、集群扩容
[详情参考博客] https://www.cnblogs.com/PatrickLiu/p/8473135.html
1、新增Master主节点
redis-cli --cluster add-node 120.78.204.98:9007 120.78.204.98:9001
2、为新节点分配槽位
redis-cli --cluster reshard 120.78.204.98:9007
3、新增Slave从节点
#将9008端口redis实例添加为cluster集群中9007端口redis实例的从节点 redis-cli --cluster add-node 120.78.204.98:9008 120.78.204.98:9007 --cluster-slave
三、Cluster集群删除操作
删除的顺序是先删除Slave从节点,然后在删除Master主节点
1、动态删除Slave从服务器节点
redis-cli --cluster del-node 192.168.127.130:7007 991ed242102aaa08873eb9404a18e0618a4e37bd
2、动态删除Master主服务器节点
要想删除Master主节点,可能要繁琐一些。因为在Master主节点上有数据槽(slots),为了保证数据的不丢失,必须把这些数据槽迁移到其他Master主节点上,然后在删除主节点。
2.1、重新分片
把要删除的Master主节点的数据槽移动到其他Master主节点上,以免数据丢失。
redis-cli --cluster reshard 192.168.127.130:7006
将此节点的槽重新分配给其他节点后再删除
redis-cli --cluster del-node 192.168.127.130:7006 71ecd970838e9b400a2a6a15cd30a94ab96203bf
Redis-Cluster集群核心概念
一、什么是哈希槽
Redis集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为16384个槽( slot ),数据库中的每个键都属于这16384个槽的其中的一个,集群中的每个节点可以处理0个或最多16384个槽。当数据库中的16384个槽都有节点在处理时,集群处于上线状态( ok);相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态( fail )。
当你往Redis Cluster中加入一个Key时,会根据crc16(key) mod 16384计算这个key应该分布到哪个hash slot中,一个hash slot中会有很多key和value。你可以理解成表的分区,使用单节点时的redis时只有一个表,所有的key都放在这个表里;改用Redis Cluster以后会自动为你生成16384个分区表,你insert数据时会根据上面的简单算法来决定你的key应该存在哪个分区关系:cluster>node>slot>key。
二、集群节点间如何通讯
[参考博客] https://www.cnblogs.com/leeSmall/p/8414687.html
1、所有集群节点都使用 TCP 总线和二进制协议连接,称为Redis 集群总线。每个节点都使用集群总线连接到集群中的每个其他节点。
2、节点之间采用Gossip协议进行通信,Gossip协议就是指节点彼此之间不断通信交换信息
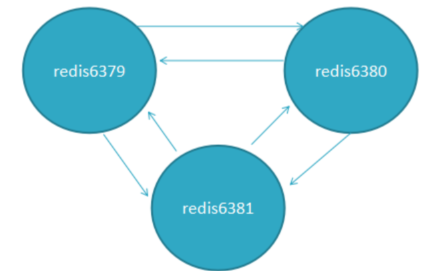
当主从角色变化或新增节点,彼此通过ping/pong进行通信知道全部节点的最新状态并达到集群同步
3、Gossip协议
Gossip协议的主要职责就是信息交换,信息交换的载体就是节点之间彼此发送的Gossip消息,常用的Gossip消息有ping消息、pong消息、meet消息、fail消息

meet消息:用于通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信完后,接收节点会加入到集群中,并进行周期性ping pong交换
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向其它节点发ping消息,用于检测节点是在在线和状态信息,ping消息发送封装自身节点和其他节点的状态数据;
pong消息,当接收到ping meet消息时,作为响应消息返回给发送方,用来确认正常通信,pong消息也封闭了自身状态数据;
fail消息:当节点判定集群内的另一节点下线时,会向集群内广播一个fail消息,
Gossip 的特点
1)扩展性
网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
2)容错
网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 协议具有天然的分布式系统容错特性。
3)去中心化
Gossip 协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。
4)一致性收敛
Gossip 协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN。
下图为gossip的传播示意图。
三、故障检测
官网:Redis Cluster 故障检测用于识别何时大多数节点不再可以访问主节点或副本节点,然后通过将副本提升为主节点来做出响应。当无法进行副本提升时,集群将处于错误状态以停止接收来自客户端的查询。
1、集群中的每个节点都会定期地向集群中的其他节点发送 PING 消意,以此来检测对方是否在线,如果接收PING 消息的节点没有在规定的时间内,向发送 BING 消息的节点返回 PONG 消息,那么发送PING 消息的节点就会将接收 PING 消息的节点标记为疑似下线( probable fail, PFAIL)
2、如果在一个集群里面,半数以上负责处理槽的主节点都将某个主节点x报告为疑似下线,那么这个主节点× 将被标记为已下线(FAIL)。将主节点x标记为已下线的节点会向集群广播一条关于主节点x 的FAII 消息,所有收到这条 FAIL 消息的节点都会立即将主节点×标记为己下线。
四、故障转移
当一个从节点发现自己正在复制的主节点进入了已下线状态时,从节点将开始对下线主节点进行故障转移,以下是故障转移的步骤:
1)复制下线主节点的所有从节点里面,会有一个从节点被选中。
2)被选中的从节点会执行 SLAVEOF no one命令,成为新的主节点。
3)新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
4)新的主节点向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点,并且这个主节点已经接管了原本由已下线节点负责处理的槽。
5)新的节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
五、选举新的主节点
当满足以下条件时,副本开始选举:
-
副本的主节点处于
FAIL状态。 -
主服务器正在服务非零数量的插槽。
-
副本复制链接与主节点断开连接的时间不超过给定的时间
副本通过
FAILOVER_AUTH_REQUEST向集群的每个主节点广播数据包来请求投票。然后它等待最多两倍NODE_TIMEOUT于回复到达的时间(但总是至少 2 秒)。一旦 master 为给定的副本投票,并以 肯定答复
FAILOVER_AUTH_ACK,一段时间NODE_TIMEOUT * 2就不能再为同一 master 的另一个副本投票。在此期间,它将无法回复同一主站的其他授权请求。
六、集群节点宕机
1、集群是如何判断是否有某个节点挂掉
首先要说的是,每一个节点都存有这个集群所有主节点以及从节点的信息。它们之间通过互相的ping-pong判断是否节点可以连接上。如果有一半以上的节点去ping一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的备用节点。
2、集群进入fail状态的必要条件
当数据库中的16384个槽都有节点在处理时,集群处于在线状态(ok),相反的,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)。
例如:
A、某个主节点和所有从节点全部挂掉,我们集群就进入faill状态。
B、如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态。
C、如果集群任意master挂掉,且当前master没有slave.集群进入fail状态。
Redis-Cluster集群测试与分析
一、如何访问正确的节点
1、先看一个操作
2、Client如何实现重定向
MOVED错误,当节点发现键所在的槽并非由自己负责处理的时候,节点就会向客户端返回一个 MOVED错误,指引客户端转向至正在负责槽的节点。
二、为一些key指定到固定的槽
如果键中的 {} 括号之间有一个子字符串,则只有字符串内的内容会被哈希,因此例如this{foo}key和another{foo}key 保证在同一个哈希槽中, 并且可以在具有多个键作为参数的命令中一起使用。
SpringBoot整合Redis-Cluster
一、Pom文件新增依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> </dependency>
二、新增配置
#集群节点 spring.redis.cluster.nodes=120.78.204.98:9001,120.78.204.98:9002,120.78.204.98:9003,120.78.204.98:9004,120.78.204.98:9005,120.78.204.98:9006 #最大重定向数 spring.redis.cluster.max-redirects=6 # 连接池最大连接数(使用负值表示没有限制) 默认为8 spring.redis.jedis.pool.max-active=8 # 连接池最大阻塞等待时间(使用负值表示没有限制) 默认为-1 spring.redis.jedis.pool.max-wait=-1ms # 连接池中的最大空闲连接 默认为8 spring.redis.jedis.pool.max-idle=8 # 连接池中的最小空闲连接 默认为 0 spring.redis.jedis.pool.min-idle=0
三、自定义RedisTemplate
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<Object, Object>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setConnectionFactory(redisConnectionFactory);
return redisTemplate;
}
}
四、测试
@Resource
private RedisTemplate<String, Object> redisTemplate;
@RequestMapping("/testA")
public void testA(@RequestBody String a, HttpServletRequest request) {
User user = new User(18, "jack");
redisTemplate.opsForValue().set("jack", "user" + a);
redisTemplate.opsForValue().set("jack1", "user1" + a);
redisTemplate.opsForValue().set("jack2", "user1" + a);
redisTemplate.opsForValue().set("jack3", "user1" + a);
redisTemplate.opsForValue().set("jack4", "user1" + a);
System.out.println(redisTemplate.opsForValue().get("jack1"));
System.out.println(redisTemplate.opsForValue().get("jack2"));
System.out.println(redisTemplate.opsForValue().get("jack3"));
System.out.println(redisTemplate.opsForValue().get("jack4"));
}
扩展讨论
一、哈希算法
二、Redis连接池

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)