ES--存储原理及读写过程
存储原理及读写过程1、ES节点架构2、插入、更新或者删除流程3、查询4、写实现5、删除和更新实现1、ES节点架构分布式主从架构Master Node:主节点负责所有管理类的操作所有索引库的创建、删除、修改、分片的分配维护和 更新整个ES集群的状态也负责存储数据Data Node:从节点负责存储数据,保存分片中的数据,可以横向扩展Master会将索引库的分片相对均衡的分布在每台机器上Coordina
·
1、ES节点架构
- 分布式
主从架构 Master Node:主节点- 负责所有管理类的操作
所有索引库的创建、删除、修改、分片的分配维护和 更新整个ES集群的状态也负责存储数据
Data Node:从节点- 负责
存储数据,保存分片中的数据,可以横向扩展 - Master会将索引库的分片相对均衡的分布在每台机器上
- 负责
Coordinator Node:中心调度节点- 谁接受客户端的读写请求,这台节点就作为中心调度节点,
负责这次读写的实现 - 类似于Impala中的中心调度节点
- 处理客户端请求,负责将请求通过路由计算转发到正确的分区所在的节点上
判断是否需要修改索引库:创建、删除如果有,会将请求先转发给Master- 然后Master处理完再转发给分区所在的节点
- 如果不需要,直接转发给分区所在的ES的节点
- 谁接受客户端的读写请求,这台节点就作为中心调度节点,
2、插入、更新或者删除流程
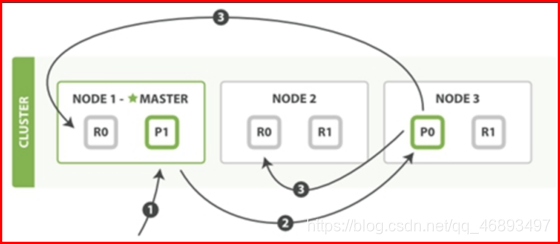
更新也是一种插入- 插入、更新、删除请求的流程是一模一样
- index:有两个分片,每个分片有两个副本
- p0:node3
- r0:node1
- r0:node2
- p1:node1
- r1:node2
- r1:node3
- p:primary shard
- 主分区
- r:replicas shard
- 副本分区
- p0:node3
- step1:客户端在node1发起请求,这个时候node1成为了
中心调度节点 - step2:
读取元数据,判断要操作的索引库是否存在,是否需要修改索引库- 如果需要:将请求转发给Master,Master修改索引信息
- 如果不需要:直接转发给这条数据的写或者删除粗请求对应的分区节点的primary shard上
- step3:node1将请求转发给node3
- step4:
primary shard判断这个请求是否合法,如果合法 ,会执行这个写入请求,将这个请求同步给所有replicas shard - step5:所有的 replicas shard将请求执行完成曾,
返回结果给primary shard,primary shard将最终结果返回给coordinator node - step6:
中心调度节点将结果返回给客户端
3、查询
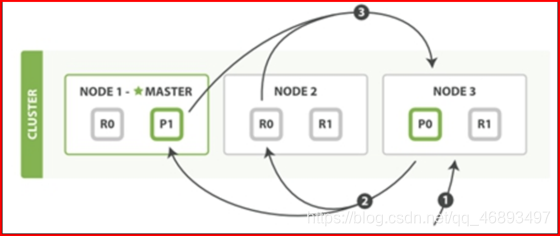
- 根据documentid查询单条document的数据
- 请求会提交到某一台es的节点,这个节点作为中心调度节点
- coordinator根据路由规则,找到这个数据所在的分片的位置
- 0分区
- p0:node3
- r0:node1
- r0:node2
- 0分区
- 默认规则 :根据
轮询 算法将请求转发给对应的分区【不区分primay shard 和 replicas shard】- Kafka的读写都只对主分区来做
- 对应的shard接受请求,检索数据并返回
- 问题:
- 数据写的时候,是写入primary shard,primary shard会同步给所有的replicas shards
- 只要
同步超过半数,就表示同步成功,这条数据就写入成功
- 只要
- 如果这次轮询读取到某一个replicas的shard,它的数据与primary shard还没有同步完整怎么办?
- 如果你要解决这个问题,你可以修改配置,让ES只读primary shard
- 数据写的时候,是写入primary shard,primary shard会同步给所有的replicas shards
- 本身设计
4、写实现
- 先进入buffer:
ES自己分配的一个内存区域,临时存储写入的数据,类似于Hbase的memstore - refresh:刷新
- es每隔1s会将buffer中的数据写入一个segment【系统的缓存OS Cache】
- 如果buffer为空,是不会刷新的
整个buffer清空,这时候数据集在os cache,数据可以被读取到- 延迟时间:1s,这个属性可以调整,最小值可以调整为200ms
- 这个
数据索引也是在这一步构建
- es每隔1s会将buffer中的数据写入一个segment【系统的缓存OS Cache】
- flush:刷写
- 将os cache中的数据写入磁盘,变成segement文件
默认每隔30分钟flush一次,清空translogsegement文件编号最大的就是最新的数据
- 数据安全
- 如果buffer或者os cache中的数据丢失,可以通过translog
不是绝对安全的,因为translog的数据也在os cache
5、删除和更新实现
- delete
- 当执行删除粗操作时,做了一个
标记,数据在flush会将被标记的数据写入另外一个文件 当搜索数据时,会过滤这个文件
- 当执行删除粗操作时,做了一个
- update
- 将被更新数据标记为被更新,添加一个delete状态
- merge:合并,类似于Hbase中的compact
- 将所有segement文件进行合并为1个文件
- 删除被标记的数据文件

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)