MySQL添加/删除主键、外键、唯一键、索引、自增
建表是添加外键create table tableName1(id int primary key,name varchar(128) default null,tableName2_id int not null,foreign key(tableName2_id) references tableName2(id));单独添加外键alter table tableName1 add c
索引的介绍
什么是索引
MySQL官方对索引的定义为:索引( Index)是帮助 MySQL高效获取数据的数据结构。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
可以简单理解为“排好序的快速查找数据结构”。数据库索引和书籍字典的索引目的完全相同,都是为了提升查询效率。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引。当然,除了B+树这种类型的索引之外,还有哈希索引。
在mysql中索引index和键key是同义词。
索引快速查找数据的示意图
二叉树索引示例:
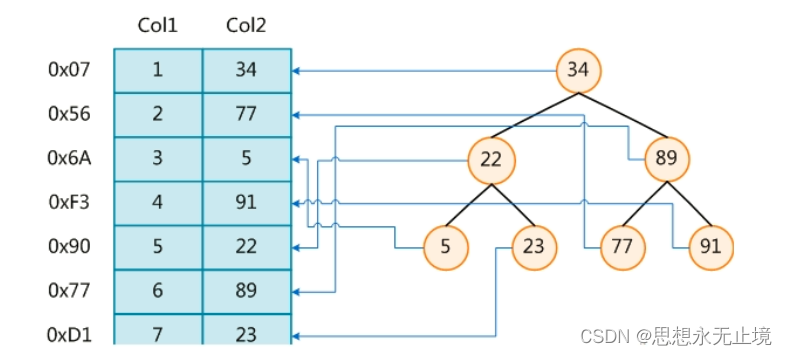
按照上图,如果现在要查找Col2=89的数据,只需要索引里找Col2=89对应的索引点在哪,先比较34,89比34大,那么再去比较89,发现89=89,那么取出89索引点存储的真实数据位置0x77,然后再去真实数据文件中取出0x77的数据。
如果没有这个索引,就需要将表的所有行遍历一遍去匹配Col2为89的,也就是全表扫描,如果有几十万上百万的数据,全表扫描的效率是及其低下的。
上图中的二叉树只是举个例子,并不是真实的索引数据结构,真实的索引数据结构比这个复杂。
索引类型
索引按存储方式(硬件层面)分为聚集索引(相邻索引的数据在物理层面存放在一起)和非聚集索引。
聚集索引:一个表有且仅有一个聚集(clustered)索引,聚集索引在innodb中是主键的同义词,除主键之外的其他索引都是非聚集索引,非聚集索引在innodb中是二级索引的同义词。二级索引保存的不是行数据的物理位置,而是是行的主键,所以二级索引实际上会查询两次,先查询对应的主键,再根据主键从聚集索引中查出物理地址(不过innodb对此有优化,对于经常使用到的索引,会建立自适应哈希索引减少这样的重复工作)。
按存储结构(软件层面)分为btree索引(数据根据btree算法进行分配和查询)、hash索引(数据根据hash算法进行分配和查询)、full-text索引(全文索引)、rtree索引等等。
按索引指向的列的个数可分为,单列索引、复合索引。
按所以是否唯一可分为,唯一索引,主键索引(唯一索引的一种),可重复索引。
索引的优缺点
优点
提高数据检索的效率,降低数据库的IO成本
降低数据排序的成本,降低了CPU的消耗
缺点
1.实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。
2.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、 UPDATE和 DELETE。
因为更新表时, MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
3.索引只是提高效率的一个因素,如果你的 MySQL有大数据量的表,就需要花时间研究建立优秀的索引优化查询。
索引一般都是根据实际查询需求不断删除重建进行迭代优化的,优化索引需要不小时间和精力,这就是缺点。
一般而言,一张表的索引个数最好不要建超过5个,因为SQL查询是最终只会选择一个索引来查询。
索引与键的增删改
主键
主键会自动添加唯一索引,所以主键列不需要添加索引
建表时设置主键
create table tableName(
id int primary key
);
或:
create table tableName(
id int,
primary key (id)
);
单独设置主键
alter table tableName add primary key(id)
删除主键
alter table tableName drop primary key;
外键
建表时添加外键
create table tableName1(
tableName2_id int not null,
foreign key(tableName2_id) references tableName2(id)
);
单独添加外键
alter table tableName1 add constraint tableName1_ref_tableName2(foreignKeyName) foreign key(tableName2_id) references tableName2(id);
删除外键
alter table tableName1 drop foreign key foreignKeyName;
唯一键
唯一键会自动添加唯一索引,所以唯一键列不需要添加索引
建表时添加唯一键
create table tableName(
columnName int unique
);
或:
create table tableName(
columnName int,
unique key(columnName)
);
单独添加唯一键
alter table tableName add unique key(columnName)
删除唯一键
alter table tableName drop index columnName;
索引
绝大部分情况下,mysql中的索引index和键key是同义词。
fulltext全文索引,只有MyISAM引擎支持,博主没有使用过不太清楚,想了解的可以自行百度。
建表时添加索引
语法规则:
create table tableName(
columnName int,
[unique/fulltext/spatial] index/key indexName (columnName[(len)] [asc/desc])[using btree/hash]
);
示例:
create table tableName(
columnName int key//这里只能用key不能用index
);
或:
create table tableName(
columnName int,
key/index (columnName)
);
或:
create table tableName(
columnName int,
key/index indexName(columnName)
);
多列索引:
create table tableName(
columnName1 int,
columnName2 int,
key/index indexName(columnName1,columnName2)
);
单独添加索引
语法规则:
alter table tableName add [unique/fulltext/spatial] index/key indexName (columnName[(len)] [asc/desc])[using btree/hash]
或者:
create [unique/fulltext/spatial] index indexName on tableName(columnName[(len)] [asc/desc])[using btree/hash]//此处只能用index不能用key
示例:
alter table tableName add key/index indexName(columnName)//单列索引
alter table tableName add key/index indexName(columnName1,columnName2,columnName3)//多列索引
alter table tableName add key/index indexName(columnName(len))//截取指定长度内容作为索引
alter table tableName add key/index indexName(columnName desc)//指定索引排序方式
alter table tableName add key/index indexName(columnName) using btree/hash //指定索引类型
或者:
create index indexName on tableName(columnName)//此处只能用index不能用key
删除索引
alter table tableName drop key/index columnName;
或
drop index indexName on tableName;//此处只能用index不能用key
查询索引
show index from tableName;//此处只能用index不能用key
自增
auto_increment必须要求该列是主键(或别的键,详细请看文章:http://blog.csdn.net/u012643122/article/details/52643888)
建表时添加自增
create table tableName(
columnName int unique auto_increment
);
或:
create table tableName(
columnName int primary key auto_increment
);
单独添加自增
alter table tableName change columnName columnName int unique auto_increment;
或:
alter table tableName change columnName columnName int primary key auto_increment;
已是唯一键或主键时:
alter table tableName change columnName columnName int auto_increment;
删除自增
alter table tableName change columnName columnName int;
设置自增初始值
create table tableName(
columnName int primary key auto_increment
)auto_increment=1;
或:
alter table tableName auto_increment=1;
索引的优化
什么是选择性数值
假如一个表有10万行记录,有一个字段valid只有0和1两种值,且每个值的分布概率大约为50%,那么对这种表valid字段建索引不会提高数据库的查询速度。
索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。
一个索引的选择性越接近于1,这个索引的效率就越高。
如何使索引高效的工作
不推荐一开始建表时就添加索引(除非能是unique或能确定其选择性接近1),不推荐添加单列索引(除非能是unique或能确定其选择性接近1),而是根据特定查询创建索引。
主键自带主键索引,主键索引是最高效的索引,其次是唯一索引unique key,因为它们都是选择性为1的索引。
我们在建立索引时,首先需要考虑的就是选择性大小,选择性大小可以通过查看执行计划里的rows,也可以执行select count进行查询。
建立多列索引时,选择性大的索引放最前面。
多列索引中mysql索引遵循最左匹配原则(比如index(a,b),order by b,则索引失效,order by a,索引生效)。
三星索引
三星索引用于评价一个索引是否适合某个查询(three-star system):
一星索引:索引将相关记录放在一起,即index(a,b,c)使用where a=? and b=? and c=?。
二星索引:在一星索引的基础上,索引中的数据顺序和查找的排列顺序一致,即index(a,b,c)使用order by a,b,c,index(c desc,b asc,a desc)使用order by c desc,b asc,a desc
三星索引:在二星索引的基础上,索引中的列包含了查询中所需的全部列,即index(a,b,c)使用select a,b,c,也就是覆盖索引。
如果需要查询的列过多,而没有任何索引能覆盖这么多查询的列时,想实现三星索引变得不可能,不过有个巧妙解决办法:延时查询!
select 你要查询的列(不需要满足索引的列) from tableName t1 where t1.id in(select t0.id from tableName t0 where 满足索引的查询条件 ) order by 满足索引的排序
覆盖索引
覆盖索引(Covering Index),覆盖索引是指select的数据列只用从索引(物理磁盘索引文件)中就能够取得,不必读取真实数据行(物理磁盘数据文件)。
select的数据列可以少于索引列,但不能多余索引列。
select的数据列的顺序,对覆盖索引没有任何影响。
如果你要查询的列确实很多,不可以强行为了使用覆盖索引而给很多的列建一个索引,那样会造成索引文件过大,查询性能下降。
查询时,指定索引
强制使用(其实mysql仍然会根据查询优化器来计算是否使用该索引,也就是说,强制使用也并非一定会使用)
select * from tableName force index(indexName) where ...
建议使用
select * from tableName use index(indexName) where ...
判断表是否适合添加索引:
适合添加索引的表
1万行以上,建议建立索引,100万以上的数据一定要建索引。
经常查询的表,需要建立索引。
不适合添加索引的表
1万行以下数据的表不建议建立索引。
频繁增删改的表,或者增删改频率大于查询频率的表,不建议添加索引,如果一定要添加,最多添加一个两个索引。
需要经常增删的并且几乎不查询的备份表不适合添加索引。
项目一启动就被加载到缓存中的配置类的表不适合添加索引。
索引不是越多越好,索引也不是添加了就一定会增加查询效率,查询索引是否被使用,及使用概率,可以查看sql语句的执行计划(主要看select_type、type、key、rows),及时剔除没有使用到的、使用率低的索引。
但是,准确的说,是否添加索引是针对查询,而不是针对表的,是否添加索引还得看查询需求
判断字段是否适合添加索引:
适合添加索引的字段
经常被order by的字段适合使用索引(这条最重要);
经常被where的字段适合使用索引(这条很重要);
经常被group by的字段适合使用索引(这条也重要);
foreign key的字段适合使用索引;
经常被join on的字段适合使用索引;
不适合添加索引的字段
重复性特别多的字段,如sex、valid等不适合使用索引(这条最重要);
没在where中用到的字段不适合使用索引;
二进制类型的字段不适合使用索引;
长文本类型的字段不适合使用索引(非全文索引);
多列索引和单列索引的选择
单列索引只有在选择性为1或接近1的情况下,才建立单列索引,正常情况应该都是多列索引。
多字段排序的查询都需要建立对应的多列索引(而不是建立多个单列索引),索引顺序和order by的顺序保持一致。
查询条件为单列并且排序字段为单列的时候,可以建立单列索引,也可以建立多列索引但将此列放置在最左侧。
哪些情况会使索引失效
范围条件
查询条件where 索引列>、>=、<、<=会导致索引失效,如果是多列索引,则索引虽然被使用,但该索引列失效,会导致文件排序。
详细解释为什么范围查询会导致索引失效:
create table `news`(...);
create index idx_ccv on `news`(channel_id,comments,views);
explain select id,author_id from 'news' where `channel_id`=1 and comments >1 order by views desc limit 1;
explain select id,author_id from 'news' where `channel_id`=1 and comments =3 order by views desc limit 1
现象,第一个查询使用了文件排序,第二个查询没有使用文件排序。
explain type变成了 range,这是可以忍受的。但是explain extra里使用Using filesort仍是无法接受的。
但是我们已经建立了索引,为啥没用呢?
这是因为按照BTree索引的工作原理,先排序 channel_id,如果遇到相同的 channel_id则再排序 comments,如果遇到相同的 comments则再排序views。当comments字段在联合素引里处于中间位置时,因 comments>1条件是一个范围值(所谓 range),MySQL无法利用索引再对后面的 views部分进行检索,即 range类型查询字段后面的素引无效。
本质上这一问题的根本原因其实是btree数据结构限制导致的。
解决办法:有范围查询的字段,不要加入索引。
联接查询
from L left join R on L.a=R.a ,用于确定如何从右表R搜索行,左边的所有行一定都有,所以右表R是我们的关键点,一定需要在R.a建立索引。在L.a上建索引等于没建。
right join和left join类似。
使用表联接查询时,尽可能减少join语句中的NestedLoop的循环总次数;“永远用小结果集驱动大的结果集”,即left join时要保证左表的结果集小于右表,然后我们在右表上做索引,左表就让它全表扫描(反正也无法避免)。
多个联接查询时也一样,如from L left join R1 on L.a=R1.a left join R2 on L.a=R2.a ,这样的三表联查,只需要在R1.a和R2.a做索引即可。
优先优化 NestedLoopl的内层循环;
保证Join语句中被驱动表上Join条件字段已经被索引;
当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜 JoinBuffer的设置;
多列索引
使用多列索引时,如index(a,b,c),应该保证a一定会出现在where条件中,不然where b=x,c=y就会导致索引失效,因为mysql在使用多列索引时,使用的是最佳左前缀法则(本质上其实是btree数据结构限制导致的),order by、group by和where一样都遵循这一法则。
函数计算
不要在索引列上做任何操作(计算、函数),否则会导致索引失效。
where left(索引列,2)#索引失效
类型转换
不要在索引列上做任何操作类型转换(自动or手动),否则会导致索引失效。
#假设id_card_no为字符串类型
where id_card_no=19225784894;#索引失效,因为输入的int会被mysql自动转型为varchar。
不等于条件
mysql在使用不等于(!=或者<>)的时候会导致索引失效。
null条件
is null, is not null会导致索引失效。
like
like以通配符开头('%abc.)会导致索引失效。
解决办法:使用覆盖索引即可解决。
create index(name,age);
select id,name from t1 where t1.name like'%xxx%';#覆盖索引(id是主键不影响覆盖),like时索引有效
select id,name,age from t1 where t1.name like'%xxx%';#覆盖索引(id是主键不影响覆盖),like时索引有效
select name,age from t1 where t1.name like'%xxx%';#覆盖索引(id是主键不影响覆盖),like时索引有效
select name,age,email from t1 where t1.name like'%xxx%';#非覆盖索引,like时索引失效
单引号
字符串不加单引号索引失效。
or
where中使用or 索引列时会导致索引失效。
总结
索引的法则就是,按索引列定义的顺序逐个查找排序、查找排序、查找排序…。
假设 index(a,b,c)
| Wherei语句 | 索引是否被使用 |
|---|---|
| where a=3 | Y,使用到a |
| where a= 3 and b=5 | Y,使用到a,b |
| where a= 3 and b= 5 and c=4 | Y,使用到a,b,c |
| where b=3或者 where b=3andc=4或者 where c=4 | N |
| where a 3 and c=5 | 使用到a,但是c不可以,b中间断了 |
| where a= 3 and b> 4 and c=5 | 使用到a和b,c不能用在范围之后,b断了 |
| where a 3 and b like ‘kk%’ and c=4 | a能用,b能用,c不能用 |
order by
MySql有两种排序方式:文件排序或扫描有序索引排序。
MySql能为排序与查询使用相同的索引。
order by遵循where使用索引的规则,并且比where更严格,因为where的条件顺序会被mysql优化器调整顺序,所以有时候where列的顺序即使不按照index列的顺序来也可以使用索引,而order by的顺序是不能被调整的。
假设 index(a, b. c)
order by能使用素引最左前:
ORDER BY a
ORDER BY a,b
ORDER BY a, b,c
ORDER BY a DESC, b DESC, c DESC
如果 WHERE使用索素引的最左前缀定义为常量,则 order byi能使用素引:
WHERE a const ORDER BY b, c
WHERE a const AND b const ORDER BY c
WHERE a const ORDER BY b. c
WHERE a const AND b const ORDER BY b. c
不能使用索引进行排序:
ORDER BY a ASC, b DESC, c DESC /*排序不一致*/
WHERE g= const ORDER BY b,c /*丢失a索引I*/
WHERE a= const ORDER BY c /*丢失b索引I*/
WHERE a= const ORDER BY a,d /*d不是素引的一部分*/
WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/
group by
group by在分组之前一定会排序,group by和order by在排序法则和where、order by索引优化原则是一致的。
Query Optimizer
1 MySQL中有专门负责优化SELECT语句的优化器模块Query Optimizer,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的 Query提供它认为最优的执行计划(它认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)
2 当客户端向MySQL请求一条Query,命令解析器模块完成请求分类,区别出是SELECT并转发给MySQL Query Optimizer时, MySQL Query Optimizer首先会对整条Query进行优化,处理掉一些常量表达式的预算,直接换算成常量值。并对Quey中的查询条件进行简化和转换,如去掉一些无用或显而易见的条件、结构调整等。然后分析 Query中的Hint信息(如果有),看显示Hint信息是否可以完全确定该 Query的执行计划。如果没有Hint或Hint信息还不足以完全确定执行计划,则会读取所涉及对象的统计信息,根据 Query进行写相应的计算分析,然后再得出最后的执行计划。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 29
29 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)