大数据的处理流程
大数据的处理流程
·
大数据处理流程一般分为四步骤:数据采集、数据导入和清洗预处理、数据统计分析和挖掘、结果可视化。
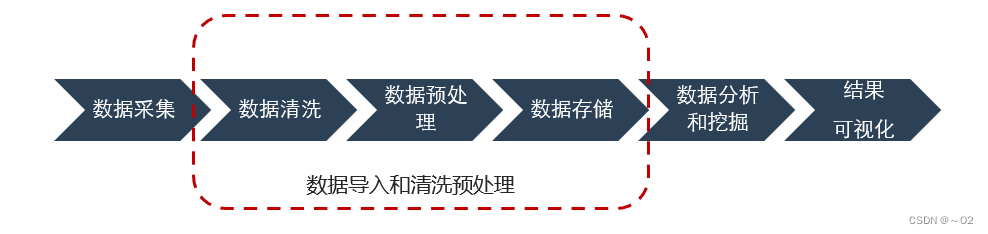
1、数据采集
大数据的采集一般采用ETL( Extract-Transform-Load )工具负责将分布的、异构数据源中的数据如关系数据、平面数据以及其他非结构化数据等抽取到临时文件或数据库中。
2、数据清洗和预处理
采集好数据,肯定不少是重复或是无用的数据,此时需要对数据进行简单的清洗和预处理,使得不同来源的数据整合成一致的,适合数据分析算法和工具读取的数据,如数据去重、异常处理和数据归一化等,然后将这些数据存到大型分布式数据库或者分布式存储集群中。
3、数据统计分析和挖掘
统计分析需要用到工具来处理,比如SPSS工具、一些结构算法模型,进行分类汇总以满足各种数据分析需求。
与统计分析过程不同的是,数据挖掘一般没有什么预先设定好的主题,主要是在现有数据上面进行基于各种算法的计算,起到预测效果,实现一些高级别数据分析的需求。比较典型算法有用于聚类的K-means、用于统计学习的SVM和用于分类的NaïveBayes,主要使用的工具有Hadoop的Mahout等。
4、结果可视化
大数据分析的使用者有大数据分析专家,同时还有普通用户,但是他们二者对于大数据分析最基本的要求就是可视化分析,因为可视化分析能够直观的呈现大数据特点,同时能够非常容易被读者所接受,就如同看图说话一样简单明了。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)