ClickHouse高级学习(四)Clickhouse数据查询(待更新)
文章目录数据查询WITH子句SAMPLE子句ARRAY JOIN子句JOIN 子句LIMIT BY 子句LIMIT查看SQL执行计划数据查询注意事项:在clickhouse里面不要使用select * 这样的语句,这种语句对于列式存储来说很容易消耗内存WITH子句Clickhouse 支持CTE 也就是公共表达式,用于增强查询语句的表达,表现如下:With子句的第一种用法:定义变量,这些变量可以在
·
数据查询
- 注意事项:
- 在clickhouse里面不要使用select * 这样的语句,这种语句对于列式存储来说很容易消耗内存
WITH子句
-
Clickhouse 支持CTE 也就是公共表达式,用于增强查询语句的表达,表现如下:

-
With子句的第一种用法:定义变量,这些变量可以在后续的查询子句中被直接访问

-
With子句的第二种用法:调用函数,可以访问SELECT子句中的列字段,并调用函数做进一步的加工处理。

-
With子句的第三种用法:定义子查询
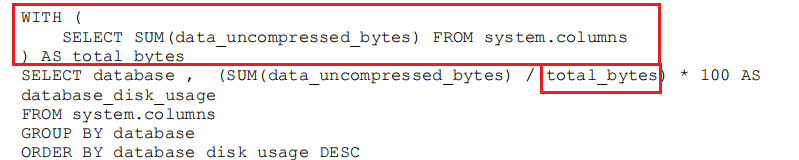
-
With子句的第四种用法:在子查询中重复使用WITH
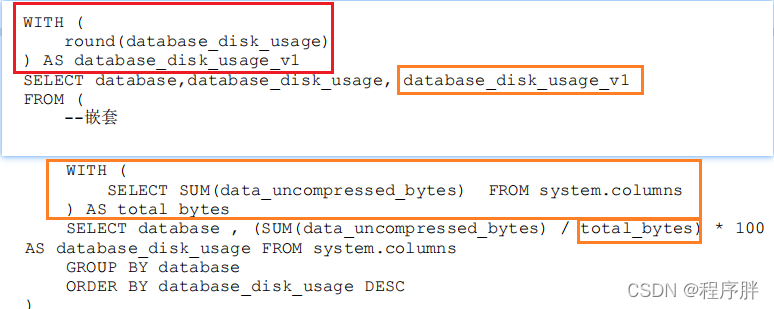
SAMPLE子句
- 作用:实现数据采样的功能,使查询仅返回采样数据而不是全部数据,从而有效减少查询负载。
- 使用场景:适合在可以接受近似查询结果得场合使用
- 引擎:只适用于MegreTree系列引擎的数据表
- 声明:

- 注意:
- SAMPLE BY所声明的表达式必须同时包含在主键的声明内
- Sample Key必须是Int类型,如若不是,ClickHouse在进行CREATE TABLE操作时也不会报错,但在数据查询时会得到如下类似异常
- 使用:
ARRAY JOIN子句
-
作用:允许在数据表内部,与数组或嵌套得字段进行JOIN操作,从而将一行数组展开为多行。首先先创建一个带数组的数据表


-
注意事项:
- 在一条select语句中,只能存在一个Array Join
- 目前只支持INNER和LEFT两种JOIN策略
-
INNER ARRAY JOIN :数据基于value数组被展开成了多行,并且排除掉了空数组。
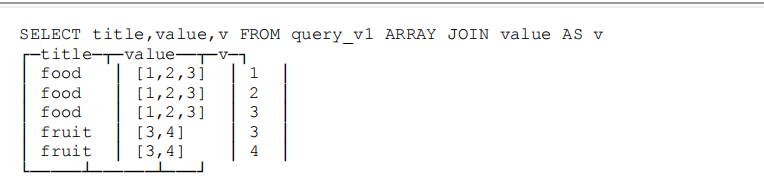
-
LEFT ARRAY JOIN :当同时对多个数组字段进行ARRAY JOIN操作时,查询的计算逻辑是按行合并而不是产生笛卡儿积

JOIN 子句
- JOIN 的作用是将表与表之间连接,他的语法包含了连接精度和连接类型两部分,他的组合规则如下:
- 连接精度:ALL ANY ASOF
- 连接类型:LEFT RIGHT INNER CROSS
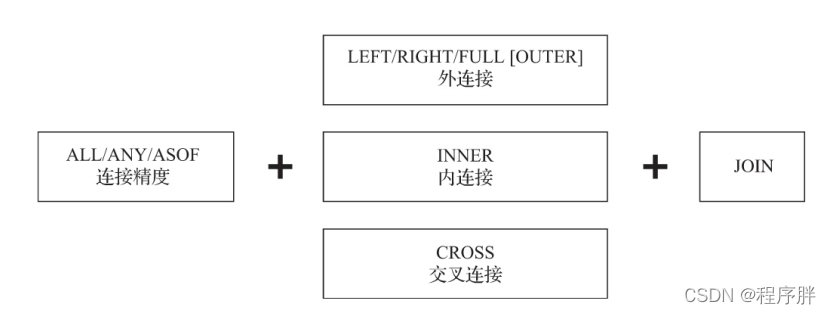
- 连接精度:决定了JOIN查询在连接数据时所使用的策略,如果不主动声明,则默认是ALL。
- ALL 连接精度:如果左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表中全部连接的数据。而判断连接匹配的依据是左表与右表内的数据,基于连接键(JOIN KEY)的取值完全相等(equal),等同于left.key=right.key。
- ANY连接精度:如果左表内的一行数据,在右表中有多行数据与之连接匹配,则仅返回右表中第一行连接的数据。ANY与ALL判断连接匹配的依据相同。
- ASOF连接精度:ASOF是一种模糊连接,它允许在连接键之后追加定义一个模糊连接的匹配条件asof_column。

- ASOF支持使用USING的简写形式,USING后声明的最后一个字段会被自动转换成asof_colum模糊连接条件。

- asof_colum必须是整型、浮点型和日期型这类有序序列的数据类型;asof_colum不能是数据表内的唯一字段,换言之,连接键(JOIN KEY)和asof_colum不能是同一个字段。
- ASOF支持使用USING的简写形式,USING后声明的最后一个字段会被自动转换成asof_colum模糊连接条件。
- INNER 连接类型:表示内连接,在查询时会以左表为基础逐行遍历数据,然后从右表中找出与左边连接的行,就只会返回左表和右表两个数据集合中交集的部分。
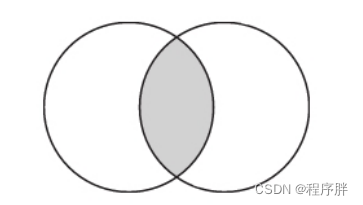
- OUTER 连接类型:OUTER JOIN表示外连接,它可以进一步细分为左外连接(LEFT)、右外连接(RIGHT)和全外连接(FULL)三种形式。根据连接形式的不同,其返回数据集合的逻辑也不尽相同。
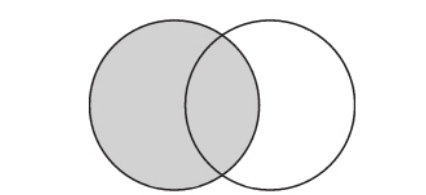
- LEFT :在进行左外连接查询时,会以左表为基础逐行遍历数据,然后从右表中找出与左边连接的行以补齐属性。如果在右表中没有找到连接的行,则采用相应字段数据类型的默认值填充。换言之,对于左连接查询而言,左表的数据总是能够全部返回。
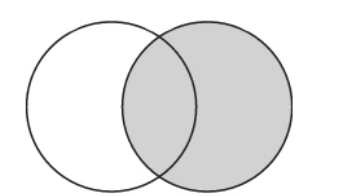
- RIGHT:右外连接查询的效果与左连接恰好相反,右表的数据总是能够全部返回,而左表不能连接的数据则使用默认值补全
- 在内部进行类似INNER JOIN的内连接查询,在计算交集部分的同时,顺带记录右表中那些未能被连接的数据行。
- 将那些未能被连接的数据行追加到交集的尾部。
- 将追加数据中那些属于左表的列字段用默认值补全
- FULL :全外连接查询会返回左表与右表两个数据集合的并集
- 会在内部进行类似LEFT JOIN的查询,在左外连接的过程中,顺带记录右表中已经被连接的数据行。
- 通过在右表中记录已被连接的数据行,得到未被连接的数据行。
- 将右表中未被连接的数据追加至结果集,并将那些属于左表
中的列字段以默认值补全。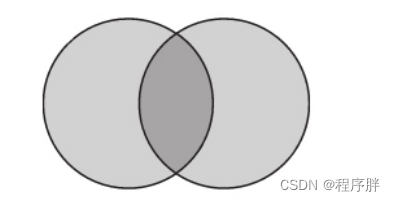
- LEFT :在进行左外连接查询时,会以左表为基础逐行遍历数据,然后从右表中找出与左边连接的行以补齐属性。如果在右表中没有找到连接的行,则采用相应字段数据类型的默认值填充。换言之,对于左连接查询而言,左表的数据总是能够全部返回。
- CROSS连接类型:CROSS JOIN表示交叉连接,它会返回左表与右表两个数据集合的笛卡儿积。也正因为如此,CROSS JOIN不需要声明JOIN KEY,因为结果会包含它们的所有组合
- 注意事项:
- 关于性能:
- 应该遵循左大右小的原则
- join查询没有缓存的支持,每次join查询都会执行相同的sql,所以建议将经常使用的join转换成其他有助于join引擎来改善性能
- 关于空值策略与简写形式:
- 关于性能:
LIMIT BY 子句
- 它运行于ORDER BY之后和LIMIT之前,能够按照指定分组,最多返回前n行数据,常用于TOP N的查询场景。
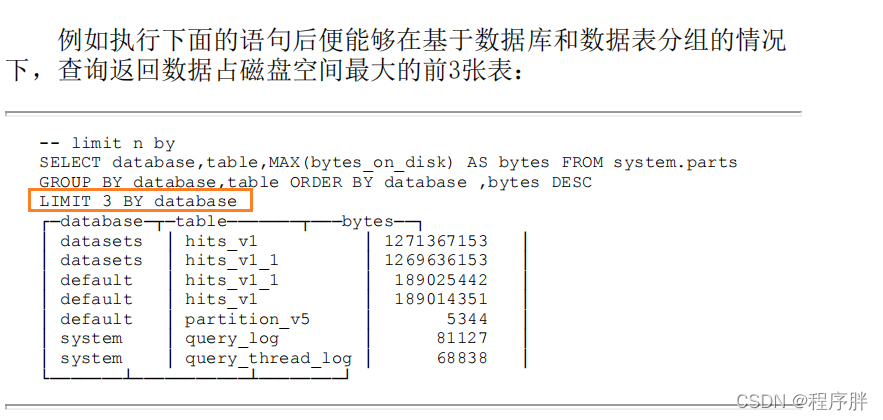
LIMIT
- LIMIT子句用于返回指定的前n行数据,常用于分页场景,它的三种语法形式

查看SQL执行计划
- 总结:
- 通过将ClickHouse服务日志设置到DEBUG或者TRACE级别,可以变相实现EXPLAIN查询,以分析SQL的执行日志。
- 需要真正执行了SQL查询,CH才能打印计划日志,所以如果表的数据量很大,最好借助LIMIT子句以减小查询返回的数据量。
- 在日志中,分区过滤信息部分如下所示:Selected xxx parts by date,其中by date是固定的,无论我们的分区键是什么字段,这里都不会变。这是由于在早期版本中,MergeTree分区键只支持日期字段。
- 不要使用SELECT * 全字段查询。
- 尽可能利用各种索引(分区索引、一级索引、二级索引),这样可避免全表扫描。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)