

区别
Redis 是一个服务,独立的进程,用户的程序需要与它建立连接才能向它发请求,读写数据。
RocksDB 和LevelDB 是一个库,嵌入在用户的程序中,用户程序直接调用接口读写数据。
Redis 是一个远程内存数据存储(类似于 memcached)。它是一个服务器。单个 Redis 实例非常高效,但完全不可扩展(就 CPU 而言)。 Redis 集群是可扩展的(就 CPU 而言)。
RocksDB 是一个嵌入式键/值存储(类似于 BerkeleyDB 或更确切地说是 LevelDB)。它是一个库,支持多线程和基于日志结构合并树的持久性。
总的来说,Redis 比 RocksDB 具有更多的功能。它可以原生地理解复杂数据结构的语义,例如列表和数组。
相比之下,RocksDB 将存储的值视为一团数据。如果您想进行任何进一步的处理,您需要将数据带到您的程序中并在那里进行处理(换句话说,您不能将处理委托给数据库引擎(又名 RocksDB))。
RocksDB 仅在单个服务器上运行。 Redis 有一个集群版本(虽然它不是免费的)
Redis 是为内存计算而构建的,虽然它也支持将数据备份到持久存储,但主要用例是内存用例。相比之下,RocksDB 通常用于持久化数据,并且在大多数情况下将数据存储在持久性介质上。
RocksDB 有更好的多线程支持(特别是对于读——写仍然受到并发访问的影响)。
https://stackoverflow.com/questions/31831706/redis-vs-rocksdb
相关联
Google 开源NOSQL存储引擎库LevelDB ,在它的基础之上,Facebook 开发出了另一个 NOSQL 存储引擎库 RocksDB。沿用了 LevelDB 的先进技术架构的同时还解决了 LevelDB 的一些短板。
Redis 缓存有什么问题?
当我们将 Redis 拿来做缓存用时,背后肯定还有一个持久层数据库记录了全量的冷热数据。Redis 和持久层数据库之间的数据一致性是由应用程序自己来控制的。应用程序会优先去缓存中获取数据,当缓存中没有数据时,应用程序需要从持久层加载数据,然后再放进缓存中。当数据更新发生时,需要将缓存置为失效。
function getUser(String userId) User {
User user = redis.get(userId);
if user == null {
user = db.get(userId);
if user != null {
redis.set(userId, user);
}
}
return user;
}
function updateUser(String userId, User user) {
db.update(userId, user);
redis.expire(userId);
}
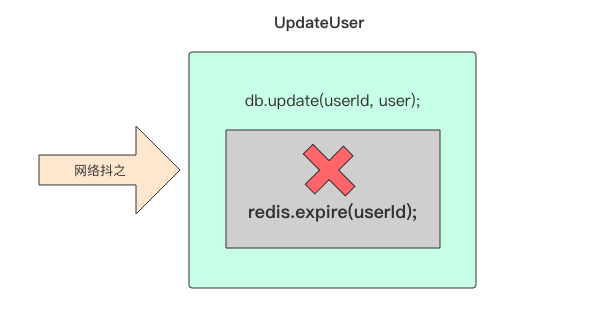
严格来说我们还需要仔细考虑缓存一致性问题,比如在 updateUser 方法中,数据库正确执行了更新,但是缓存 redis 因为网络抖动等原因置为失效没有成功,那么缓存中的数据就成了过期数据。如果你将设置缓存和更新持久存的先后顺序反过来,也还是会有其它问题,这个读者可以自行思考一下。
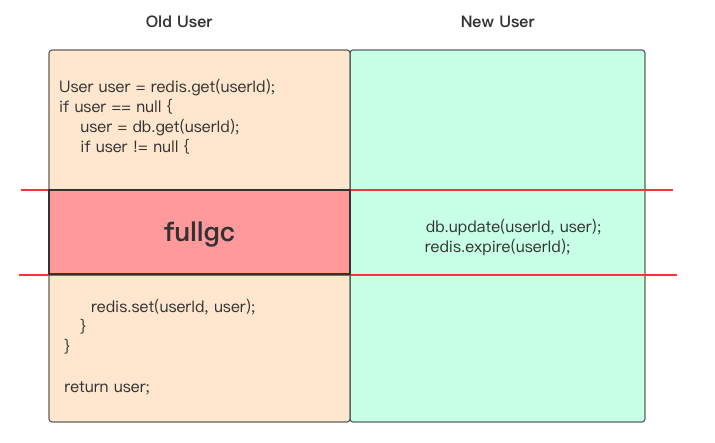
在多进程高并发场合也会导致缓存不一致,比如一个进程对某个 userId 调用 getUser() 方法,因为缓存里没有,它需要从数据库里加载。结果刚刚加载出来,正准备要设置缓存,这时候发生了内存 fullgc 代码暂停了一会,而正在此时另一个进程调用了 updateUser 方法更新了数据库,将缓存置为失效(其实缓存里本来就没有数据)。然后前面那个进程终于 fullgc 结束要开始设置缓存了,这时候进缓存的就是过期的数据。
LevelDB 是如何解决的?
LevelDB 将 Redis 缓存和持久层合二为一,一次性帮你搞定缓存和持久层。有了 LevelDB,你的代码可以简化成下面这样
function getUser(String userId) User {
return leveldb.get(userId);
}
function updateUser(String userId, User user) {
leveldb.set(userId, user);
}
LevelDB 具体是什么?
前面我们说道它是一个 NOSQL 存储引擎,它和 Redis 不是一个概念。Redis 是一个完备的数据库,而 LevelDB 它只是一个引擎。如果将数据库必须成一辆高级跑车,那么存储引擎就是它的发动机,是核心是心脏。有了这个发动机,我们再给它包装上一系列的配件和装饰,就可以成为数据库。不过也不要小瞧了配件和装饰,做到极致那也是非常困难,将 LevelDB 包装成一个简单易用的数据库需要加上太多太多精致的配件。LevelDB 和 RocksDB 出来这么多年,能够在它的基础上做出非常一个完备的生产级数据库寥寥无几。
在使用 LevelDB 时,我们还可以将它看成一个 Key/Value 内存数据库。它提供了基础的 Get/Set API,我们在代码里可以通过这个 API 来读写数据。你还可以将它看成一个无限大小的高级 HashMap,我们可以往里面塞入无限条 Key/Value 数据,只要磁盘可以装下。
正是因为它只能算作一个内存数据库,它里面装的数据无法跨进程跨机器共享。在分布式领域,LevelDB 要如何大显身手呢?
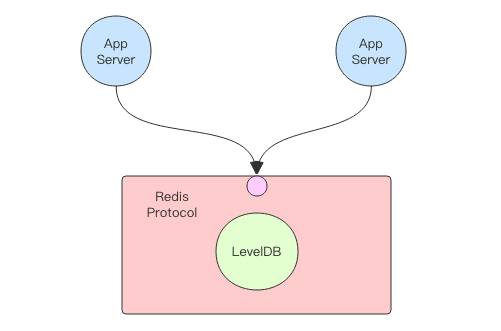
这就需要靠包装技术了,在 LevelDB 内存数据库的基础上包装一层网络 API。当不同机器上不同的进程要来访问它时,都统一走网络 API 接口。这样就形成了一个简易的数据库。如果在网络层我们使用 Redis 协议来包装,那么使用 Redis 的客户端就可以读写这个数据库了。
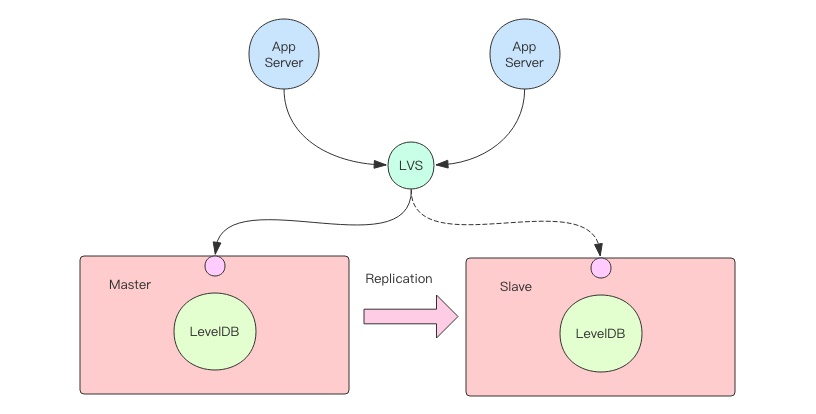
如果要考虑数据库的高可用性,我们在上面这个单机数据库的基础上再加上主从复制功能就可以变身成为一个主从结构的分布式 NOSQL 数据库。在主从数据库前面加一层转发代理(负载均衡器如 LVS、F5 等),就可以实现主从的实时切换。
如果你需要的数据容量特别大以至于单个机器的硬盘都容不下,这时候就需要数据分片机制将整个数据库的数据分散到多台机器上,每台机器只负责一部分数据的读写工作。数据分片的方案非常多,可以像 Codis 那样通过转发代理来分片,也可以像 Redis-Cluster 那样使用客户端转发机制来分片,还可以使用 TiDB 的 Raft 分布式一致性算法来分组管理分片。最简单最易于理解的还是要数 Codis 的转发代理分片。
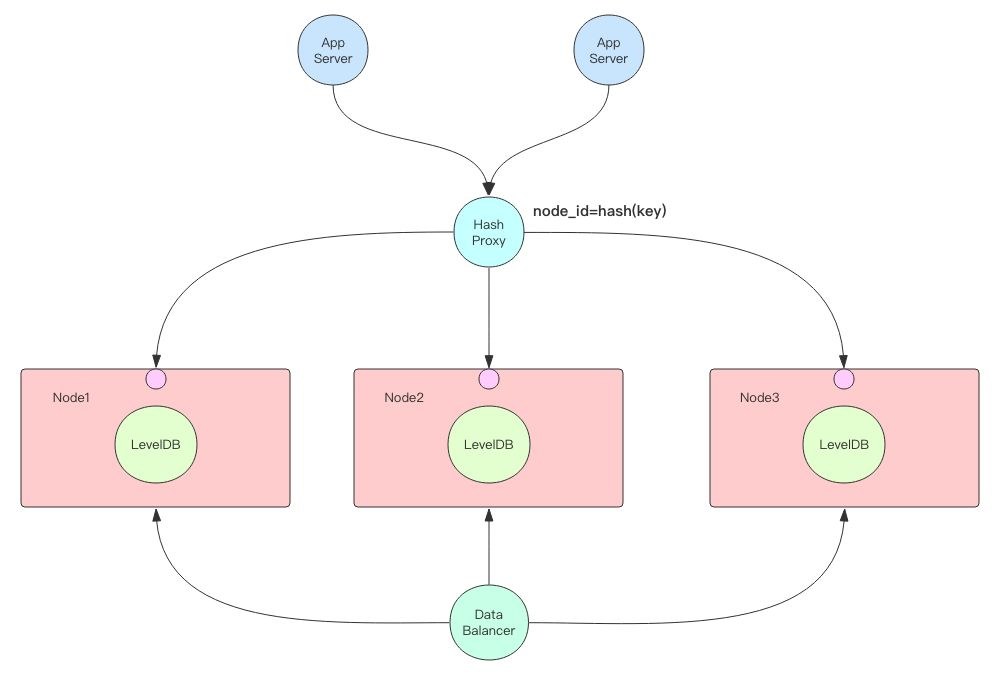
当数据量继续增长需要新增节点时,就必须将老节点上的数据部分迁移到新节点上,管理数据的均衡和迁移的又是一个新的高级配件 —— 数据均衡器。
看到这里读者应该可以从整体上理解了分布式数据库中 LevelDB 所处的地位。下一节我们开始全面了解一下 LevelDB 的内存数据库特性。

原文链接:https://blog.csdn.net/shellquery/article/details/100892922







 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)