Hive面试题汇总大全
1 什么是hive?Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL 查询功能。本质是:将HQL 转化成MapReduce 程序1)Hive 处理的数据存储在HDFS2)Hive 分析数据底层的实现是MapReduce3)执行程序运行在Yarn 上2 Hive的优缺点优点:1 操作接口采用类SQL 语法,提供快速开发的能力(简单、容易上手)。2
1 什么是hive?
Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL 查询功能。
本质是:将HQL 转化成MapReduce 程序
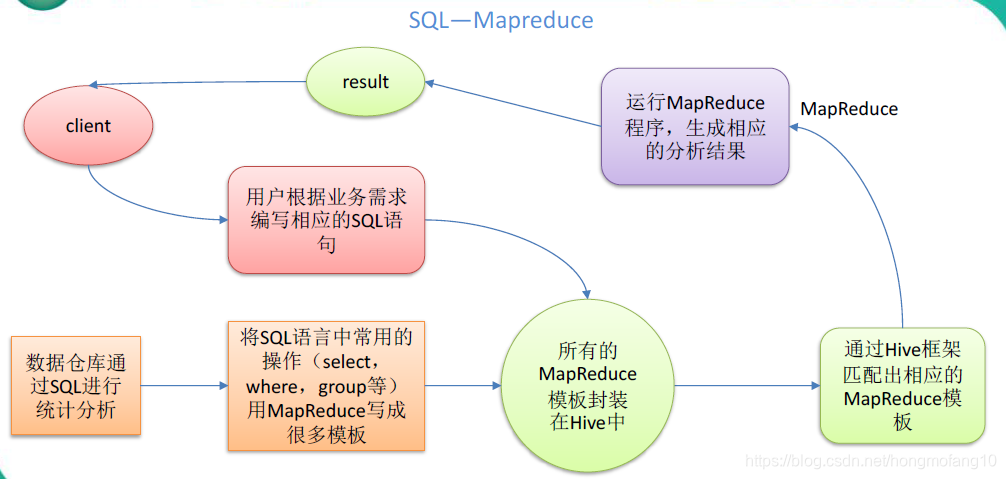
- 1)Hive 处理的数据存储在HDFS
- 2)Hive 分析数据底层的实现是MapReduce
- 3)执行程序运行在Yarn 上
2 Hive的优缺点
优点:
- 1 操作接口采用类SQL 语法,提供快速开发的能力(简单、容易上手)。
- 2 避免了去写MapReduce,减少开发人员的学习成本。
- 3 Hive 的执行延迟比较高,因此Hive 常用于数据分析,对实时性要求不高的场合。
- 4 Hive 优势在于处理大数据,对于处理小数据没有优势,因为Hive 的执行延迟比较高。
- 5 Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
- 1 Hive 的HQL 表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长 - 2 Hive 的效率比较低
(1)Hive 自动生成的MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗
Hive 架构原理
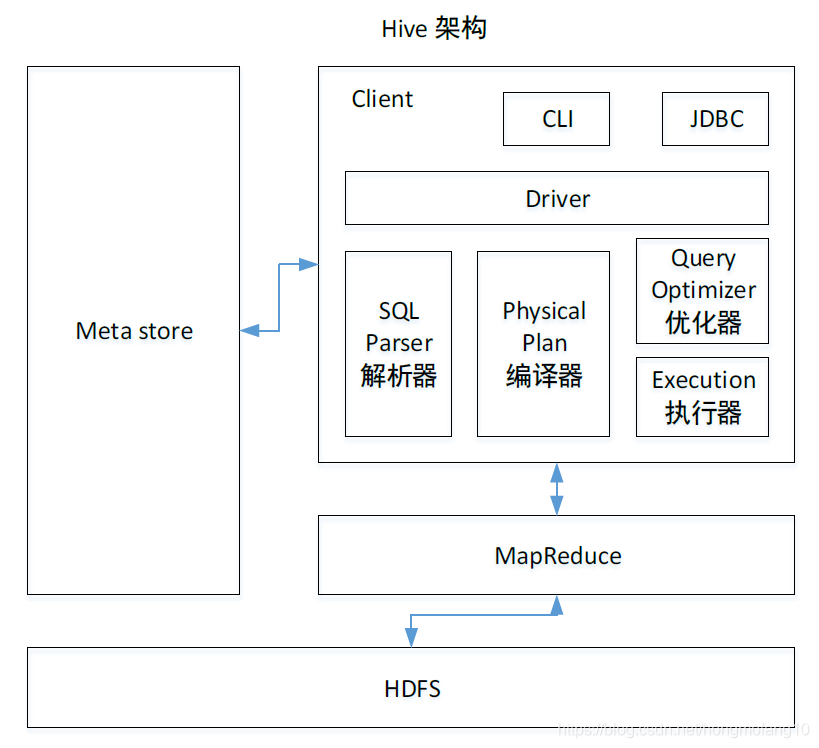
- 1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java 访问hive)、WEBUI(浏览器访问hive) - 2.元数据:Metastore元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby 数据库中,推荐使用MySQL 存储Metastore - 3.Hadoop
使用HDFS 进行存储,使用MapReduce 进行计算。 - 4.驱动器:Driver
(1)解析器(SQL Parser):将SQL 字符串转换成抽象语法树AST,这一步一般都用
第三方工具库完成,比如antlr;对AST 进行语法分析,比如表是否存在、字段是否存
在、SQL 语义是否有误。
(2)编译器(Physical Plan):将AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive 来说,就是MR/Spark。
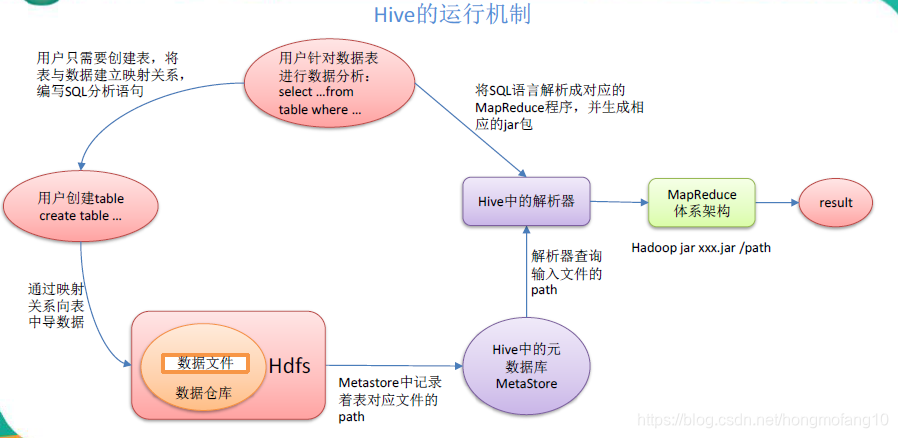
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
Hive和数据库比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
- 1 查询语言
由于SQL 被广泛的应用在数据仓库中,因此,专门针对Hive 的特性设计了类SQL 的查询语言 HQL 。熟悉 SQL 开发 的开发者可以很方便的使用 Hive 进行开发。 - 2 数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则
可以将数据保存在块设备或者本地文件系统中。 - 3 数据更新
由于 Hive 是针对数据仓库应用设计的,而 数据仓库的内容是读多写少的。 因此, Hive中不 建议 对数据的改写,所有的数据都是在加载的时候确定好的。 而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO VALUES 添加数据,使用 UPDATE SET 修改数据。 - 4 索引
Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此 也没有对数据中的某些 Key 建立索引。 Hive 要访问数据中满足条件的特定值时,需要 暴力扫描整个数据 ,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于 大数据 量的访问, Hive 仍然可以体现出优势。 数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。 - 5 执行
Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。 - 6 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于MapReduce 本身具有较 高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候, Hive 的并行计算显然能体现出优势。 - 7 可扩展性
由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是。一致的(世界上最大的 Hadoop 集群在 Yahoo! 2009 年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数 据库 Oracle 在理论上的扩展能力也只有 100 台左右。 - 8 数据规模
由于Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
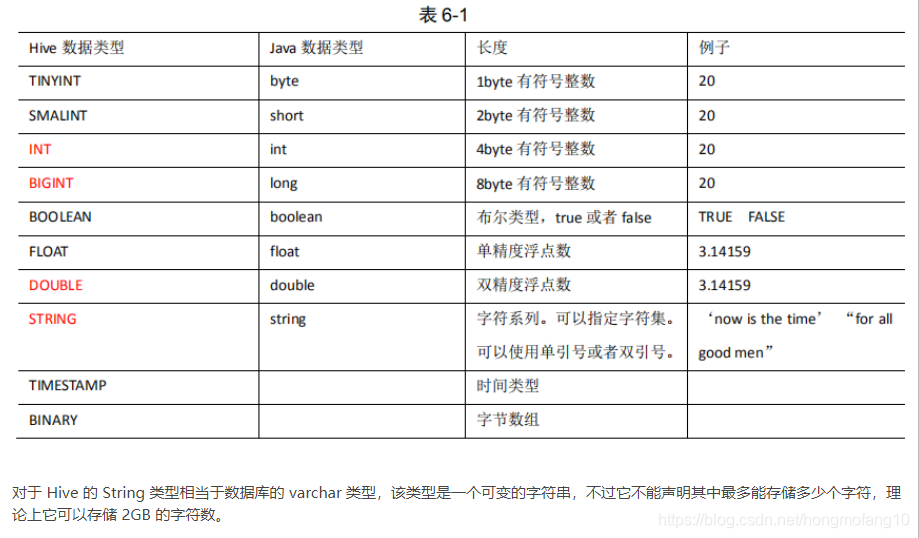
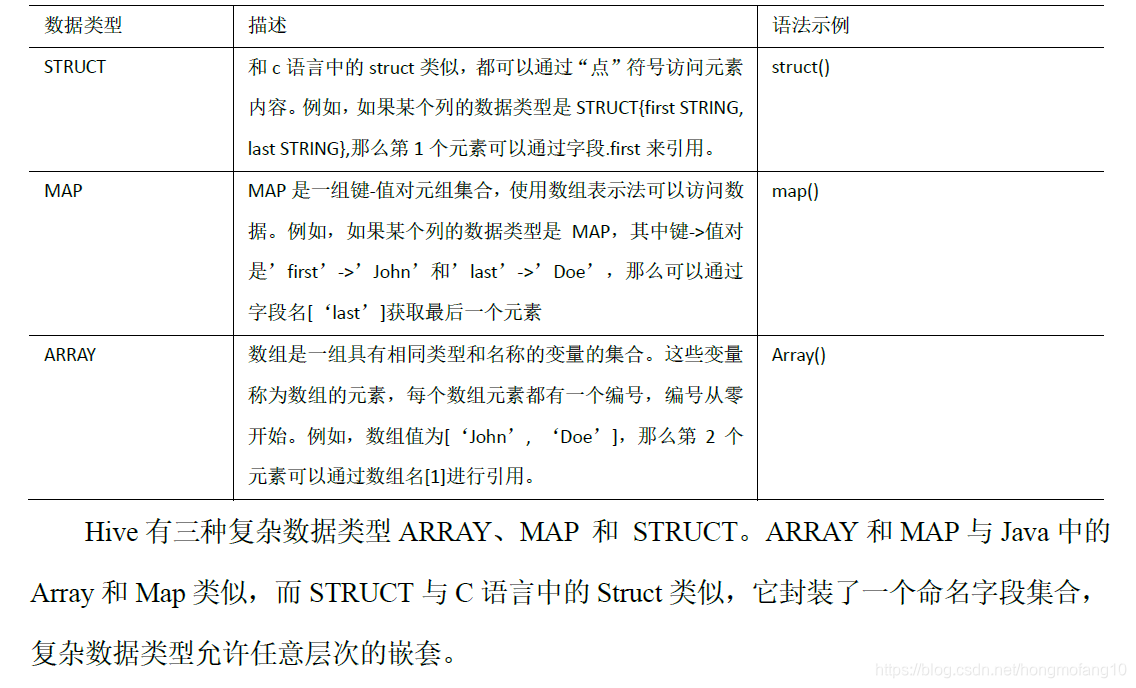
Hive数据类型
- 基本数据类型
-
Hive 管理表和外部表
- 管理表
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,
Hive 会(或多或少地) 控制着数据的生命周期。 Hive 默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir( 例如, ,/user/hive/ 所定义的目录的子目录下。 当我们删除一个管理表时,Hive 也会删除这个表中数据。管理表不适合和其他工具共享数据。 - 外部表
Hive 并非认为其完全拥有这份数据。删除该表并不会删除掉这
份数据,不过描述表的元数据信息会被删除掉。
Hive分区表
分区表实际上就是对应一个HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。 Hive 中的分区就是分目录 ,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
Hive排序
- 全局排序(Order by)
Order By:全局排序,一个Reducer
ASC: 升序(默认)
DESC: 降序 - 内部排序(Sort by)
每个 Reducer 内部进行排序,对全局结果集来说不是排序。 - 分区排序 (Distribute By)
类似 MR 中 partition ,进行分区,结合 sort by 使用。
注意: Hive 要求 DISTRIBUTE BY 语句要写在 SORT BY 语句之前。
对于 distribute by 进行测试,一定要分配多 reduce 进行处理,否则无法看到 distribute by的效果。 - Cluster by
当distribute by 和sorts by 字段相同时,可以使用cluster by 方式。
cluster by 除了具有distribute by 的功能外还兼具sort by 的功能。但是排序只能是升序排序,不能指定排序规则为ASC 或者DESC。
以下两种写法等价:
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
注意:按照部门编号分区,不一定就是固定死的数值,可以是20 号和30 号部门分到一个分区里面去。
Hive分桶
分区针对的是数据的存储路径;分桶针对的是数据文件。
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是之前所提到过的要确定合适的划分大小这个疑虑。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分桶抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。 Hive 可以通过对表进行抽样来满足这个需求。查询表stu_buck 中的数据。
hive (default)> select * from stu_buck tablesample(buck et 1 out of 4 on id);
注:tablesample 是抽样语句,语法: TABLESAMPLE(BUCKET x OUT OF y) 。
y必须是 table 总 bucket 数的倍数或者因子。 hive 根据 y 的大小,决定抽样的比例。例如, table 总共分了 4 份,当 y=2 时,抽取 (4/2=)2 个 bucket 的数据,当 y=8 时,抽取 (4/8=)1/2个 bucket 的数据。
x表示从哪个 bucket 开始抽取 ,如果需要取多个分区,以后的分区号为当前分区号加上y 。例如, table 总 bucket 数为 4 ta blesample(bucket 1 out of 2 )),表示总共抽取 4/ 2 2 个bucket 的数据,抽取第 1 x) 个和第 3 (x +y 个 bucket 的数据。
注意:
x 的值必须小于等于 y 的值,否则FAILED: SemanticException [Error 10061]: Numerator should not be bigger than
denominator in sample clause for table stu_buck
Hive调优
- Fetch抓取
Fetch抓取是指, Hive 中对某些情况的查询可以不必使用 MapReduce 计算 。例如:SELECT * FROM employees; 在这种情况下, Hive 可以简单地读取 employee 对应的存储目录下的文件,然后输出查询结果到控制台。
在hive default.xml.template 文件中 hive.fetch.task.conversion 默认是 more ,老版本 hive默认是 minimal ,该属性修改为 more 以后,在全局查找、字段查找、 limit 查找等都不走mapreduce 。 - 本地模式
大多数的Hadoop Job 是需要 Hadoop 提供的完整的可扩展性来处理大数据集的。不过,有时 Hive 的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际 job 的执行时间要多的多。对于大多数这种情况, Hive 可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。用户可以通过设置hive.exec.mode.local.auto 的值为 true ,来让 Hive 在适当的时候自动
启动这个优化。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)