什么是物化视图
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,而普通视图只是一层简单的查询代理普通视图不会存储任何数据,它只是一层单纯的SELECT查询映射,起着简化查询、明晰语义的作用,对查询性能不会有任何增强。物化视图物化视图支持表引擎,数据保存形式由它的表引擎决定,创建物化视图的完整语法如下所示create materialized view mv_log engine=Log p
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,而普通视图只是一层简单的查询代理
普通视图不会存储任何数据,它只是一层单纯的SELECT查询映射,起着简化查询、明晰语义的作用,对查询性能不会有任何增强。
物化视图
物化视图支持表引擎,数据保存形式由它的表引擎决定,创建物化视图的完整语法如下所示
create materialized view mv_log engine=Log populate as select * from log ;
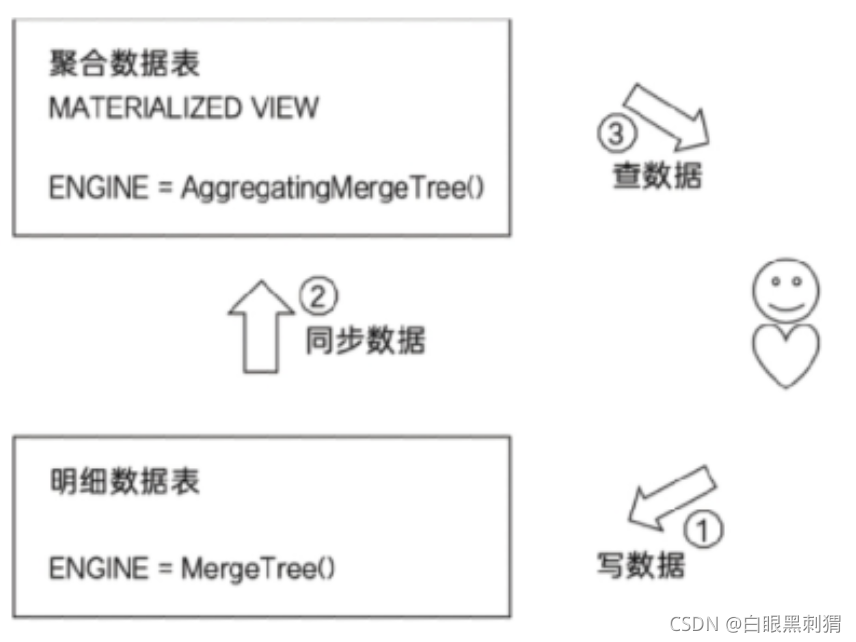
物化视图创建好之后,如果源表被写入新数据,那么物化视图也会同步更新。POPULATE修饰符决定了物化视图的初始化策略:如果使用了POPULATE修饰符,那么在创建视图的过程中,会连带将源表中已存在的数据一并导入,如同执行了INTO SELECT 一般;反之,如果不使用POPULATE修饰符,那么物化视图在创建之后是没有数据的,它只会同步在此之后被写入源表的数据。物化视图目前并不支持同步删除,如果在源表中删除了数据,物化视图的数据仍会保留。
create materialized view test3_view engine = Log populate as select * from tb_test3 ;
-- 建表的时候同步数据 , 当数据更新以后 物化视图中的数据会同步更新 , 但是当删除数据以后,物化视图中的数据不会被删除
SELECT *
FROM test3_view ;
┌─id─┬─name───┬─role─┐
│ 1 │ HANGGE │ VIP │
│ 2 │ BENGE │ VIP │
│ 3 │ PINGGE │ VIP │
└────┴────────┴──────┘
-- 向源表中擦混入数据
SELECT *
FROM test3_view
┌─id─┬─name──┬─role─┐
│ 4 │ TAOGE │ VIP │
└────┴───────┴──────┘
┌─id─┬─name───┬─role─┐
│ 1 │ HANGGE │ VIP │
│ 2 │ BENGE │ VIP │
│ 3 │ PINGGE │ VIP │
└────┴────────┴──────┘
-- 删除源表中的数据 , 物化视图中的数据 不会变化 ****
注意: 数据删除语法只适用于MergeTree引擎的表 基本语法如下
ALTER TABLE db_name.table_name DROP PARTITION '20210601'
ALTER TABLE db_name.table_name DELETE WHERE day = '20210618'
ALTER TABLE <table_name> UPDATE col1 = expr1, ... WHERE <filter>Show tables ; 其实物化视图就是一种特殊的表
物化视图在本地表的存储目录中有一份真实的数据存储 !
可以使用物化视图同步普通表中的数据 , 还可以将源表中的数据提前聚合 !
-- 建立明细表
drop table orders ;
CREATE TABLE orders
(
uid UInt64,
money UInt64,
ctime Date,
Sign Int8
)
ENGINE = MergeTree()
ORDER BY uid;
--插入数据
insert into orders values(1,100,toDate(now()),1) ;
insert into orders values(1,100,toDate(now()),1) ;
insert into orders values(1,100,toDate(now()),1) ;
insert into orders values(2,200,toDate(now()),1) ;
insert into orders values(2,200,toDate(now()),1) ;
insert into orders values(2,200,toDate(now()),1) ;
insert into orders values(2,100,toDate(now()),1) ;
-- 将聚合逻辑创建成物化视图
CREATE MATERIALIZED VIEW orders_agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY toDate(ctime)
ORDER BY uid
populate
as select
uid ,
ctime ,
sumState(money) as mm -- 注意别名
from
orders
group by uid , ctime;
-- 查询物化视图数据
select uid,ctime,sumMerge(mm) from orders_agg_view group by uid, ctime ;
-- 更新明细数据, 物化视图中的数据实时计算更新
insert into orders values(1,100,toDate(now()),1);
┌─uid─┬──────ctime─┬─sumMerge(mm)─┐
│ 2 │ 2021-05-19 │ 400 │
│ 1 │ 2021-05-19 │ 200 │
└─────┴────────────┴──────────────┘
┌─uid─┬──────ctime─┬─sumMerge(mm)─┐
│ 2 │ 2021-05-19 │ 400 │
│ 1 │ 2021-05-19 │ 300 │
└─────┴────────────┴──────────────┘
┌─uid─┬──────ctime─┬─sumMerge(mm)─┐
│ 2 │ 2021-05-19 │ 400 │
│ 1 │ 2021-05-19 │ 400 │
└─────┴────────────┴──────────────┘总结 :
(1)用ORBER BY排序键作为聚合数据的条件Key。
(2)使用AggregateFunction字段类型定义聚合函数的类型以及聚合的字 段。
(3)只有在合并分区的时候才会触发聚合计算的逻辑。
(4)以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合 Key相同的数据会被合并计算,而不同分区之间的数据则不会被计算。
(5)在进行数据计算时,因为分区内的数据已经基于ORBER BY排序,所以 能够找到那些相邻且拥有相同聚合Key的数据。
(6)在聚合数据时,同一分区内,相同聚合Key的多行数据会合并成一 行。对于那些非主键、非AggregateFunction类型字段,则会使用第一行数据的 取值。
(7)AggregateFunction类型的字段使用二进制存储,在写入数据时,需 要调用State函数;而在查询数据时,则需要调用相应的Merge函数。其中,* 表示定义时使用的聚合函数。
(8)AggregatingMergeTree通常作为物化视图的表引擎,与普通 MergeTree搭配使用。
该查询尝试使用[MergeTree]系列中的表引擎初始化表的未计划的数据部分合并。[MaterializedView和[Buffer]引擎OPTMIZE也支持。不支持其他表引擎。
当OPTIMIZE与使用[ReplicatedMergeTree]表引擎,ClickHouse创造了合并,并等待所有节点上执行(如果该任务replication_alter_partitions_sync已启用设置)。
· 如果OPTIMIZE由于任何原因未执行合并,则不会通知客户端。要启用通知,请使用[optimize_throw_if_noop]设置。
· 如果指定PARTITION,则仅优化指定的分区。[如何设置分区表达式]。
· 如果指定FINAL,即使所有数据已经在一个部分中,也会执行优化。
· 如果指定DEDUPLICATE,则将对完全相同的行进行重复数据删除(比较所有列),这仅对MergeTree引擎有意义。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)