大数据开发,聊聊离线数仓和实时数仓 ETL
Kappa架构的设计理念是,全部都进行流式计算。流式计算的数据来源是消息队列,把所有需要计算的数据放在消息队列里,然后让流计算引擎计算所有数据。因为所有数据都存在Kafka,上面接Flink批流一体数据处理引擎将kafka的数据计算好存在服务层的table n中。如果需求有变化了,就讲kafka的offset调整一下,Flink则重启一个任务重新计算,存在table N+1中,当N+1的数据进度赶
数据仓库的概念,最早是在1991年被提出,而直到最近几年的大数据趋势下,实时数据处理快速发展,使得数据仓库技术架构不断向前,出现了实时数仓,而实时数仓又分为批数据+流数据、批流一体两种架构。
1、离线数仓
离线数仓,其实简单点来说,就是原来的传统数仓,数据以T+1的形式计算好放在那里,给前台的各种分析应用提供算好的数据。到了大数据时代,这种模式被称为“大数据的批处理”。
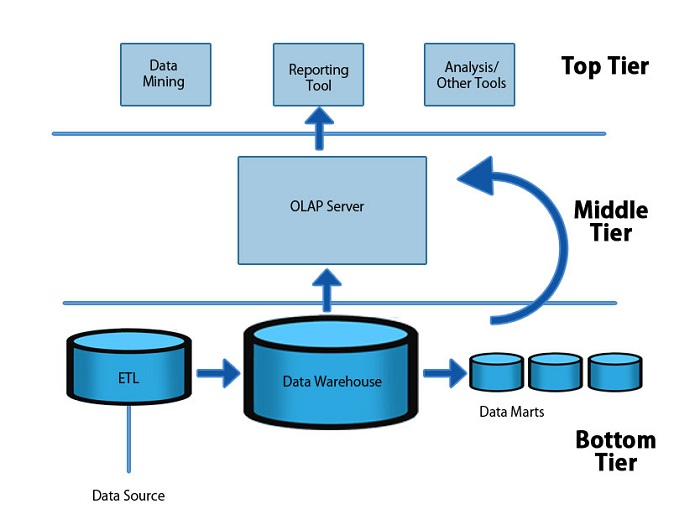
只不过原本的单体环境工具(Oracle、Informatica等)基本都被替换成了大数据体系内(Hadoop、Hive、Sqoop、Oozie等)的工具而已。
数据采集:flume/logstash+kafka,替代传统数仓的FTP;
批量数据同步:Sqoop、Kettle,跟传统数仓一样用Kettle,部分商用ETL工具也开始支持大数据集群;
大数据存储:Hadoop HDFS/Hive、TiDB、GP等MPP,替代传统数仓的Oracle、MySQL、MS SQL、DB2等;
大数据计算引擎:MapReduce、Spark、Tez,替代传统数仓的数据库执行引擎;
OLAP引擎:Kylin/druid,(Molap,需预计算)、Presto/Impala,(Rolap,无需预计算),替代BO、Brio、MSTR等各种BI工具。
2、实时数仓
实时数仓最开始是在日志数据分析业务中被广泛使用,后来在各种实时战报大屏的推动,实时数仓开始应用。
与离线计算相比,实时计算减少了数据落地,替换了数据计算引擎,目前纯流式数据处理基本上就只有Spark Streaming了,而Flink是批流一体的。实时数据计算好结果后,可以落地到各种数据库中,也可以直接对接到大屏进行展示。

3、大数据环境下的两种数仓架构
Lambda 架构
Lambda架构核心就三个:批数据处理层、流数据处理层和服务层。批数据处理层应对历史长时间数据计算,流数据处理层应对短时间实时数据计算。如果一个需求要历史到当前所有数据的累加结果,那就在服务层将两部分数据进行累加。
Kappa 架构
Kappa架构的设计理念是,全部都进行流式计算。流式计算的数据来源是消息队列,把所有需要计算的数据放在消息队列里,然后让流计算引擎计算所有数据。
因为所有数据都存在Kafka,上面接Flink批流一体数据处理引擎将kafka的数据计算好存在服务层的table n中。如果需求有变化了,就讲kafka的offset调整一下,Flink则重启一个任务重新计算,存在table N+1中,当N+1的数据进度赶上table n了,就停掉table n的任务。
数据时代的数据仓库,总体来说是根据当前的业务需求去进行架构设计的,所以需要更多结合业务去考量。
推荐阅读1:实时数仓和离线数仓的概念 (360doc.com)![]() http://www.360doc.com/content/22/0319/19/22355405_1022272961.shtml
http://www.360doc.com/content/22/0319/19/22355405_1022272961.shtml
推荐阅读2:
大数据开发,聊聊离线数仓和实时数仓_加米谷大数据张老师的博客-CSDN博客_离线数仓![]() https://blog.csdn.net/shuimuzh123/article/details/117749980
https://blog.csdn.net/shuimuzh123/article/details/117749980

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)