常用Hive命令合集
1. 建表(1)直接建表创建表的结构create table user_click_info(user_id string comment "用户id",click_time string comment "点击时间",item_id string comment "物品id")ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LINES TERMINAT
0. Hive的语句执行顺序
from -> on -> join -> where -> group by -> having -> select -> distinct -> order -> limit
Hive函数大致可以分为三类:UDF(用户自定义函数)、UDAF(用户自定义聚合函数)、UDTF(用户自定义表生成函数)。
- UDF(user-defined function):一进一出,即 一行数据输入,一行数据输出,如:substring()
- UDAF(user-defined aggregate function): 多进一出,多行数据输入,只有一个结果输出,如:sum()、count()等聚合函数
- UDTF(user-defined table-generating function):一进多出,如现在explode(),可以将一行数据输出为多行结果
1. 建表
内部表和外部表
hive表的数据存在hdfs
Hive的内部表和外部表:
- 内部表: 内部表的数据由Hive所管理,如果删除了内部表,相关的HDFS数据也会删除。删除内部表会直接删除元数据(metadata)及存储数据,对内部表的修改会将修改直接同步给元数据。
内部表:create table [表名] (默认内部表)
内部表数据存储的位置是hive在hdfs中存在默认的存储路径,即default数据库(默认:/user/hive/warehouse)。所以在该路径 下的表为内部表。 - 外部表: 外部标的数据由HDFS所管理,如果删除了外部表,外部表相关的HDFS数据不会删除。 删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name)。
外部表:create external table [表名] location ‘hdfs_path ’ (hdfs_path必须是文件夹,否则会报错 ) 或者用load data装载方式上传数据。
外部表数据存储的位置由自己指定,可以指定除/user/hive/warehouse以外的路径。
说明:hive的数据分为两种,一种为普通数据,一种为元数据。
元数据存储着表的基本信息,增删改查记录,类似于Hadoop架构中的namespace。普通数据就是表中的详细数据。
hive的元数据默认存储在derby中,但大多数情况下存储在MySQL中。普通数据如架构图所示存储在hdfs中。
内部表和外部表的转换:
内 —> 外
alter table tblName set tblproperties('EXTERNAL'='TRUE');
外 —> 内
alter table tblName set tblproperties('EXTERNAL'='FALSE');
(1)直接建表
创建表的结构
create table user_click_info
(user_id string comment "用户id",
click_time string comment "点击时间",
item_id string comment "物品id")
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
其中comment、STORED、ROW FORMAT根据情况可不加、可不加。
格式:
create table 表名
(列名1 数据类型 comment 标注,
列名2 数据类型 comment 标注)
ROW FORMAT DELIMITED FIELDS TERMINATED BY 字符间分割方式
LINES TERMINATED BY 行间分割方式
STORED AS 存储类型;
(2)查询建表
通过已有表建立新表的结构并插入数据,通常在存放中间结果的场景下使用较多。
create table tmp_article_table as
select
explode(split(sent, " ")) as words
from
article_table limit 10;
其中limit可根据情况可加、可不加。
格式:
create table 新表名 as
select
选择旧表中的列 as 作为新表中的列名
from
旧表 limit 前几行
拓展
(1)split分割
select split("l love you", " ");
相当于MapReduce中的split,按指定字符进行分割。
(2)explode一行转多行
select explode(split("l love you", " "));
相当于是Reduce阶段迭代器遍历输出,用于将map列表中的字符串按行输出。
(3)count()统计数量
select
t.word, count(*)
from
(select explode(split("l love you l love you l love l love you", " ")) as word)t
group by t.word
相当于是WordCount中Reduce阶段的数量求和,使用group by来指定以哪一列作为聚合对象。
count()具有三种参数:*、1、列名。
1)包括了所有的列,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。当要统计的对象是确定表中的主键时,使用count(列名)效果更好。
2)包括了忽略所有列,用1代表代码行,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。当要统计的表中只有一个列时,使用count(*)效果更好。
3)只包含指定列名的一列,在统计结果的时候,不会忽略列值为NULL。当要统计的表中既不是只有一个列,也不是对主键进行统计时,使用count(1)效果更好。
(4)group by分组
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。同时,group by 在分组时会实现去重效果
select col1 [,col2] ,count(1),sel_expr(聚合操作)from table
where condition -->Map端执行
group by col1 [,col2] -->Reduce端执行
[having] -->Reduce端执行
注意:select后面的非聚合列必须出现在group by中(如上面的col1和col2)。select后面除了普通列就是一些聚合操作 group by后面也可以跟表达式,比如substr(col)。
- group的特性:
(1) 使用了reduce操作,受限于reduce数量,通过参数mapred.reduce.tasks设置reduce个数。
(2) 输出文件个数与reduce数量相同,文件大小与reduce处理的数量有关。
(3) like建表
使用旧表中的结构建立表,但不含旧表中的数据
create table tmp_article_table_like like tmp_article_table;
格式:
create table 新表名 like 旧表名;
2. 加载数据
将本地数据导入
load data local inpath '/mnt/hgfs/ShareOffice/hadoop_test/word_count/acticle.txt' into table article_table
local表示从本地主机上读取,如果表示从HDFS上读取。
格式:
load data local inpath 本地数据路径 into table 表名
3. 查询数据库/表
查询所有的表
show tables;
查询表的结构
desc 表名;
查询数据库
show databases;
如果在第一次建表时候为规定数据库名字,会给它一个默认名字default。
4. 按某列的升序/ 降序输出
排序函数有三个rank()、row_number()和dense_rank()
select *, rank() over(order by create_time) as user_rank,
row_number() over(order by create_time) as user_row_number,
dense_rank() over(order by create_time) as user_dense_rank
from user_match_temp
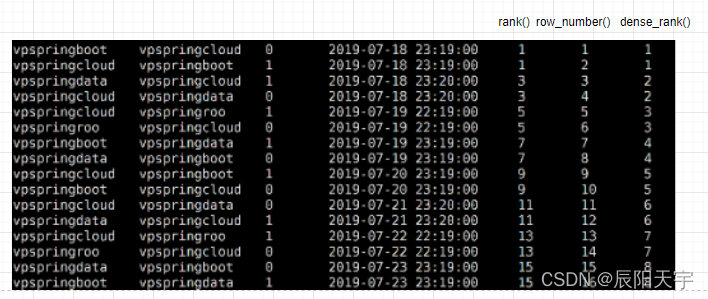
rank():如果两个元素相等, 则序号相同, 并且跳过下一个序号。
row_number():生成连续的序号(相同的元素序号不同)
dense_rank():如果两个元素相等,则序号相同,不会跳过下一个序号
其中窗口函数 over() 中可指定升序或者降序、按哪一列进行聚合分区
over(partition by col1 order by col2 asc/desc)
(1)partition by col1 指定按col1这一列进行分组,如果不指定,则默认全局排序。如果指定了列,则按照指定列进行分组,然后进行排序。
(2)order by 按col2这一列进行排序。
(3)asc升序,desc降序,默认时升序。(ascend、descend)
格式:
select
rank() over(order by 按某列进行排序) as 排序结果列别名,
row_number() over(order by 按某列进行排序) as 排序结果列别名,
dense_rank() over(order by 按某列进行排序) as 排序结果列别名
from 数据表
* 四大排序语句的区别
(1)局部排序 sort by
局部排序,相当于是shuffle阶段的排序,在每个reducer内部进行排序,在进入 reducer 前完成排序。
1.设置 reduce 个数
hive (default)> set mapreduce.job.reduces=3;
2.查看设置 reduce 个数
hive (default)> set mapreduce.job.reduces;
3.按照部门编号降序排序)
hive (default)> select * from emp sort by deptno desc;
(2)全局排序 order by
全局排序,尽在一个reduce中完成对数据的全局排序。
ASC(ascend): 升序(默认)
DESC(descend): 降序
举例
(1)查询员工信息按工资升序排列
hive (default)> select * from emp order by sal;
(2)查询员工信息按工资降序排列
hive (default)> select * from emp order by sal desc;
(3)多个列排序,按照部门和工资升序排序
hive (default)> select ename, deptno, sal from emp order by deptno, sal ;
(3)分区排序 distribute by(结合sort by)
类似 MR 中 partition 进行分区,需要结合 sort by 使用。distribute by按照指定的字段对数据进行分区,输出到不同的reduce中。distribute by是控制将map的输出结果划分到不同的reducer中。hive会根据distribute by后面的列对应reduce的个数进行分发。默认是采用hash算法。
注意,Hive 要求 DISTRIBUTE BY 语句要写在 SORT BY 语句之前。
对于 distribute by 进行测试,一定要分配多 reduce 进行处理,否则无法看到 distribute by的效果。
举例
(1)先按照部门编号分区,再按照员工编号降序排序。
hive (default)> set mapreduce.job.reduces=3;
hive (default)> select * from emp distribute by deptno sort by empno desc;
分区指定字段分区 排序在分区内按指定字段排序
(4)cluster by
cluster by的功能就是distribute by和sort by相结合。
控制某个特定行分到指定的reduce中,除了具有distribute by的功能,还具有了sort by的功能。当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式,但排序只能是倒序排序,不能指定排序规则为 ASC 或者 DESC。
举例
以下两种写法等价
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
参考资料:
Hive之查询JOIN、排序(order by、sort by、distribute by、cluster by)、分桶&分桶抽样查询、窗口函数及案例
5. 列变行collect_list()、collect_set()
按用户进行分组,将同一用户的iid数据转成数组或集合形式的一行数据,相当于Reduce阶段的多行value转一行列表形式的value。
select
uid, collect_list(iid) as iid_list
from
user_tables
group by uid
collect_list():将列转成行变成数组形式,对里面的数据不做去重。
collect_set():将列转成行变成集合形式,对里面的数据去重。
格式:
select
列名, collect_list(列名) as 别名
from
表名
group by 按指定的列进行分组
6. case when条件判断
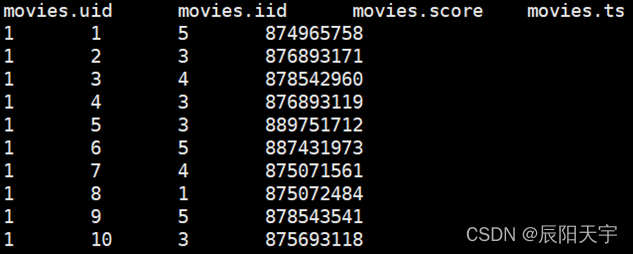

将评分数据转换成one-hot数据分布形式
select
uid, iid, ts,
case when score = 1 then 1 else 0 end as score_1,
case when score = 2 then 1 else 0 end as score_2,
case when score = 3 then 1 else 0 end as score_3,
case when score = 4 then 1 else 0 end as score_4,
case when score = 5 then 1 else 0 end as score_5
from
movies
limit 100
用于条件判断,如果case when中的条件成立,则执行then中的内容,否则执行else中的内容,用end结尾,用as其列别名。
格式:
select
列名1,
case when 条件 then 条件通过时执行结果 else 条件未通过时执行结果 end as 列别名
from 数据表
7. join多表拼接
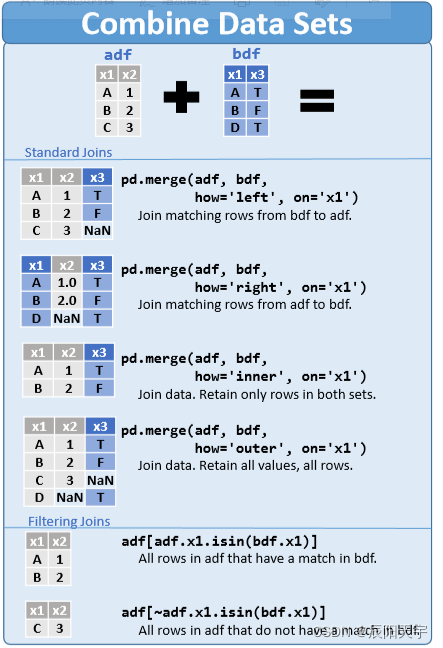
主要由下面几个拼接方式,拼接后的效果如上图所示。
测试表
hive> select * from rdb_a;
OK
1 lucy
2 jack
3 tony
hive> select * from rdb_b;
OK
1 12
2 22
4 32
(1)内关联([inner] join)
只返回关联上的结果
select
a.id,a.name,b.age
from rdb_a a
inner join rdb_b b on a.id=b.id;
Total MapReduce CPU Time Spent: 2 seconds 560 msec
OK
1 lucy 12
2 jack 22
Time taken: 47.419 seconds, Fetched: 2 row(s)
(2)左关联(left [outer] join)
以左表为主
select
a.id,a.name,b.age
from rdb_a a
left join rdb_b b on a.id=b.id;
Total MapReduce CPU Time Spent: 1 seconds 240 msec
OK
1 lucy 12
2 jack 22
3 tony NULL
Time taken: 33.42 seconds, Fetched: 3 row(s)
(3)右关联(right [outer] join)
以右表为主
select
a.id,a.name,b.age
from rdb_a a
right join rdb_b b on a.id=b.id;
Total MapReduce CPU Time Spent: 2 seconds 130 msec
OK
1 lucy 12
2 jack 22
NULL NULL 32
Time taken: 32.7 seconds, Fetched: 3 row(s)
(4)全关联(full [outer] join)
以两个表的记录为基准,返回两个表的记录去重之和,关联不上的字段为NULL。
select
a.id,a.name,b.age
from rdb_a a
full join rdb_b b on a.id=b.id;
Total MapReduce CPU Time Spent: 5 seconds 540 msec
OK
1 lucy 12
2 jack 22
3 tony NULL
NULL NULL 32
Time taken: 42.938 seconds, Fetched: 4 row(s)
8. 窗口函数 over()函数
(1)窗口函数的作用:
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
over() 可以为 聚合函数,窗口函数和分析函数进行开窗操作,用于指定分析函数工作的数据窗口大。开窗之后,每一行的数据都会对应一个数据窗口,这个数据窗口中的数据可能会随着行的变化而变化小。
over() 开窗开出来的数据是整个查询结果排除开窗操作,都执行完之后的数据。也可以说是开窗操作是在整个select查询结束后才执行的,因此开窗出来的数据也是在当前select的查询结果上进行划分的。
(2) 窗口函数的使用格式:
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
over()函数中包括三个函数:
(1)分区partition by 列名:按指定的列进行分区,可理解为group by 分组。over(partition by 列名)搭配分析函数时,分析函数按照每一组每一组的数据进行计算的。
(2)排序order by 列名:对分区内指定列名进行排序,可设为升序asc(默认值)或降序desc。它是一个默认的开窗函数。
(3)指定窗口范围rows between 开始位置 and 结束位置:指定窗口范围,比如第一行到当前行。而这个范围是随着数据变化的。
窗口范围说明:
我们常使用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行),常用该窗口来计算累加。
PRECEDING: 往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
我们在使用over()窗口函数时,over()函数中的这三个函数可组合使用也可以不使用。over()函数中如果不使用这三个函数,窗口大小是针对查询产生的所有数据,如果指定了分区,窗口大小是针对每个分区的数据。
-
注:
特殊的窗口函数如rank(),rownumber(),dense()等,即使后面over()里面没有条件,默认的开窗类似order by效果,即第一行窗口大小为1,第二行窗口大小为2,以此类推,但是数据只不过没有什统计意义,所以一般还是会在over()里加入partiton by和order by(分组,排序)等,为其赋予意义 如排名等。over(partition by ) 和 普通的group by的区别,为什么不同group by,因为有group by,只能select group by 后面的字段,和一些聚合函数 sum(),avg(),max(),min()等,而用了over(partition by),还能select 别的非partition by 字段 或者能直接“select *”,而且对于join 等有更好的支持。
窗口函数仅仅只会将结果附加到当前的结果上,它不会对已有的行或列做任何修改。而 Group By 的做法完全不同:对于各个 Group 它仅仅会保留一行聚合结果。
(3)搭配分析函数
[1] 聚合类(Aggregate)
avt()、 count()、min()、max()、sum()
sum(col) over() : 分组对col累计求和
count(col) over() : 分组对col累计计数
min(col) over() : 分组对col求最小
max(col) over() : 分组求col的最大值
avg(col) over() : 分组求col列的平均值
[2] 取值类(Value)
first_value()、last_value()、lead()、lag()
first_value(col) over() : 某分区排序后的第一个col值
last_value(col) over() : 某分区排序后的最后一个col值
lag(col,n,DEFAULT) : 统计往前n行的col值,n可选,默认为1,DEFAULT当往上第n行为NULL时候,取默认值,如不指定,则为NULL
lead(col,n,DEFAULT) : 统计往后n行的col值,n可选,默认为1,DEFAULT当往下第n行为NULL时候,取默认值,如不指定,则为NULL
[3] 排序类(Ranking)
rank()、dense_rank()、row_number()、ntile()
ntile(n) : 用于将分组数据按照顺序切分成n片,返回当前切片值。注意:n必须为int类型。
row_number() over() : 排名函数,不会重复,适合于生成主键或者不并列排名
rank() over() : 排名函数,有并列名次,名次不连续。如:1,1,3
dense_rank() over() : 排名函数,有并列名次,名次连续。如:1,1,2
参考资料:
[4] 练习
数据格式

uid string, opponent string, result string, create_time timestamp
表中展示的是比赛数据,第一列是选手,第二列是对手,第三列是输赢结果(赢为1输为0),第四列是时间戳
(1)统计每个用户按时间排序的失败次数
select
*, sum(if(result=0, 1, 0)) over(partition by user_name order by create_time) as result_sum
from user_match_temp;
对user_match_temp中的数据按user_name进行分区,按create_time进行升序排序,使用sum()对每个窗口中的数据进行求和,默认情况下每行代表一个窗口,每个窗口的范围是从当前行到起始行。
使用if()进行判断,格式if(条件表达式, 条件成立输出结果, 条件不成立输出结果)。如果为0,代表本场失败,输出1。然后对时间窗口内该列数据求和。
9. UDTF函数
UDTF(User-Defined Table-Generating Functions) 用来解决一行输入多行输出(On-to-many maping) 的需求。
数据格式

arear string, good_id string, sale_info string

(1)split()拆解
select
split(area, ',')
from explode_test
相当于是Map阶段按,进行split分割后,以数组形式输出。

格式:
select
split(列名, 按指定字符进行分割)
from 数据表
(2)explode()一行转多行
select
explode(split(area, ','))
from explode_test
将输出的一行数组转换成多行,相当于是Map阶段生成一个个<key, value>

格式:
select
explode(split(列名, 按指定字符进行分割) )
from 数据表
(3)使用索引获取值
select
split(t.col, ':')[0] as id,
split(t.col, ':')[1] as area
from
(select explode(split(area, ',')) as col from explode_test)t
获取(2)中切分后的数据构建新的列,将第一个字符作为第一列,将第二个字符作为第二列

10. UDF函数
针对数据的每一行或者某个字段,封装一个函数,m行进m行出。
数据格式
arear string, good_id string, sale_info string
(1)regexp_replace()函数
注:Hive中的用两个\代表转义字符
拆解sale_info字段内的数据
select
REGEXP_REPLACE(sale_info, '\\[\\{|\\}\\]', '')
from explode_test
使用regexp_replace函数,将sale_info字段,按照正则化匹配的方式用''替换指定字符。

格式:
regrexp_replace(列, 指定正则化的分割符, 指定正则化的替换符号)
留有},{还没有进行替换的目的是用这个当作分隔符,便于后续操作。
使用split拆分
select
split(REGEXP_REPLACE(sale_info, '\\[\\{|\\}\\]', ''), '\\},\\{')
from explode_test

然后,按使用正则化的方式,将数据以},{分割,存储在数组当中。
使用explode一行转多行
select
explode(split(regexp_replace(sale_info, '\\[\\{|\\}\\]', ''), '\\},\\{')) as infos
from explode_test
将split切分后一行数组,转为多行输出
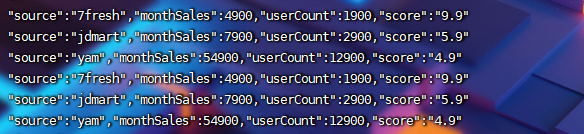
(2)concat字符串拼接
select
concat('{', t.infos, '}') as res
from
(select explode(split(regexp_replace(sale_info, '\\[\\{|\\}\\]', ''), '\\},\\{')) as infos
from explode_test)t
将每行数据加上{},变成标准的josin字符串形式
格式:
concat(拼接字符,列名)
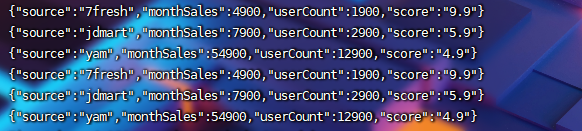
(3)get_json_object()获取元素
select
get_json_object(concat('{', t.infos, '}'), '$.source') as source,
get_json_object(concat('{', t.infos, '}'), '$.monthSales') as monthSales,
get_json_object(concat('{', t.infos, '}'), '$.userCount') as userCount,
get_json_object(concat('{', t.infos, '}'), '$.score') as score
from
(select explode(split(regexp_replace(sale_info, '\\[\\{|\\}\\]', ''), '\\},\\{')) as infos
from explode_test)t
使用get_json_object指定key获取对应的value数据。

格式:
get_json_object(json数据, '$josn变量') as score
第一个参数填写json对象变量,第二个参数使用$表示json变量标识,然后用 . 或 [] 读取对象或数组;如果输入的json字符串无效,那么返回NULL。每次只能返回一个数据项。
(4)lateral_view
lateral view侧视图是Hive中提供给UDTF的结合,用于UDTF(user-defined table generating functions)中将行转成列,它可以解决UDTF不能添加额外的select列的问题(例如:select 列, exlode()...),单独使用UDTF只支持select输出一个字段。
lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。这个虚拟表会和输入行进行join来达到连接UDTF外的select字段的目的。
在使用lateral view的时候需要指定视图别名和生成的新列别名
select
area,
get_json_object(concat('{', gid, '}'), '$.source') as source
from explode_test
lateral view explode(split(regexp_replace(sale_info, '\\[\\{|\\}\\]', ''), '\\},\\{'))g as gid

格式:
SELECT
列名
FROM
数据表
LATERAL VIEW explode(列名1) 视图别名1 AS 新列别名1,
LATERAL VIEW explode(列名2) 视图别名2 AS 新列别名2
可以加入多个later view
拓展资料:
Lateral View 语法
11. UDAF函数
聚合函数,m行进入,一行输出 collect_list
12. 取整函数
(1)向下取整:floor()
语法: floor(double a)
返回值: BIGINT
说明: 返回等于或者小于该double变量的最大的整数
hive> select floor(3.1415926) from lxw_dual;
3
hive> select floor(25) from lxw_dual;
25
(2)向上取整:ceiling()
语法: ceiling(double a)
返回值: BIGINT
说明: 返回等于或者大于该double变量的最小的整数
hive> select ceiling(3.1415926) from lxw_dual;
4
hive> select ceiling(46) from lxw_dual;
46
ceil()
语法: ceil(double a)
返回值: BIGINT
说明: 与ceil功能相同
hive> select ceil(3.1415926) from lxw_dual;
4
hive> select ceil(46) from lxw_dual;
46
(3)四舍五入:round()
语法: round(double a)
返回值: BIGINT
说明: 返回double类型的整数值部分 (遵循四舍五入)
hive> select round(3.1415926) from lxw_dual;
3
hive> select round(3.5) from lxw_dual;
4
hive> create table lxw_dual as select round(9542.158) from lxw_dual;
hive> describe lxw_dual;
_c0 bigint
指定精度取整函数round(a,b)
语法: round(double a, int d)
返回值: DOUBLE
说明: 返回指定精度d的double类型
hive> select round(3.1415926,4) from lxw_dual;
3.1416
拓展资料:数值计算
13. 空值补数函数nvl()
nvl(expr1,expr2)
如果expr1为空值,nvl返回值为expr2的值,否则返回expr1的值。 该函数的目的是把一个空值(null)转换成一个实际的值。其表达式的值可以是数字型、字符型和日期型。但是expr1和expr2的数据类型必须为同一个类型。
14. strict模式
hive提供了一个严格模式,可以防止用户执行那些可能产生意想不到的不好的效果的查询。即某些查询在严格模式下无法执行。通过设置hive.mapred.mode的值为stric。
切换严格模式
查看当前的模式:
hive> set hive.mapred.mode;
hive.mapred.mode is undefined
未定义即为false,即no-strict模式。
开启严格模式:
set hive.mapred.mode=strict;
关闭严格模式:
set hive.mapred.mode=undefined;
(1)分区partition限制where
要partition的表查询需要加上where子句,筛选部分数据实现分区裁剪,即不允许全表分区扫描,防止数据过大。
如果在一个分区表执行hive,除非where语句中包含分区字段过滤条件来显示数据范围,否则不允许执行。换句话说,就是用户不允许扫描所有的分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。
如果没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表:
hive> SELECT DISTINCT(planner_id) FROM fracture_ins WHERE planner_id=5;
FAILED: Error in semantic analysis: No Partition Predicate Found for Alias "fracture_ins" Table "fracture_ins
如下这个语句在where语句中增加了一个分区过滤条件(也就是限制了表分区):
hive> SELECT DISTINCT(planner_id) FROM fracture_ins
> WHERE planner_id=5 AND hit_date=20120101;
... normal results ...
(2)排序order by限制limit
order by执行时只产生一个reduce,必须加上limit限制输出条数,防止数据量过大造成一个reduce超负荷,如果不加会报错。
因为orderby为了执行排序过程会讲所有的结果分发到同一个reducer中进行处理,强烈要求用户增加这个limit语句可以防止reducer额外执行很长一段时间:
hive> SELECT * FROM fracture_ins WHERE hit_date>2012 ORDER BY planner_id;
FAILED: Error in semantic analysis: line 1:56 In strict mode,
limit must be specified if ORDER BY is present planner_id
只需要增加limit语句就可以解决这个问题:
hive> SELECT * FROM fracture_ins WHERE hit_date>2012 ORDER BY planner_id
> LIMIT 100000;
... normal results ...
(3)笛卡尔积join限制on
join时,如果只有一个reduce,则不支持笛卡尔积查询,也就是说必须要有on语句的条件关联。
对关系型数据库非常了解的用户可能期望在执行join查询的时候不使用on语句而是使用where语句,这样关系数据库的执行优化器就可以高效的将where语句转换成那个on语句。不幸的是,hive不会执行这种优化,因此,如果表足够大,那么这个查询就会
出现不可控的情况:
hive> SELECT * FROM fracture_act JOIN fracture_ads
> WHERE fracture_act.planner_id = fracture_ads.planner_id;
FAILED: Error in semantic analysis: In strict mode, cartesian product
is not allowed. If you really want to perform the operation,
+set hive.mapred.mode=nonstrict+
下面这个才是正确的使用join和on语句的查询:
hive> SELECT * FROM fracture_act JOIN fracture_ads
> ON (fracture_act.planner_id = fracture_ads.planner_id);
... normal results ...
(4)group by和 order by 同时使用时不会按组进行排序。
where、group by、having、order by同时使用时,执行顺序为:
① where过滤数据
② 对筛选结果集group by分组,group by执行顺序是在select之前。因此group by中不能使用select后面字段的别名
③ 对每个分组进行select查询,提取对应的列,有几组就分几组
④ 再进行having筛选每组数据
⑤ 最后整体进行order by排序
15. Hive分区
1. 为什么出现分区?
随着MR的任务越来越多,表的数据量会越来越大,而Hive Select查询数据的时候通常会全表扫描,。有时候只需要扫描表中关心的一部分数据,全表扫描将会导致大量不必要的数据进行扫描,从而查询效率会大大的降低。因此Hive引进了分区技术,使用分区技术:避免Hive全表扫描,提升查询效率。
2. 分区是什么?
hive分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集,(子目录就是分区名,将列别名作为子目录名来存放数据,就是一个分区)。这样where中给出列值时,只需根据列值直接扫描对应目录下的数据,不扫面其他不关心的分区,快速定位,查询节省大量时间 。
即表中的一个分区对应于表下的一个目录,所有的分区的数据都存储在对应的目录中。
3. 分区种类
Hive分为静态分区 SP(static partition)和动态分区 DP(dynamic partition)两种。静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。详细来说,静态分区的列是在编译时期,通过用户传递来决定的;动态分区只有在 SQL 执行时才能决定。
4. 创建分区
如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by(分区名 数据类型),当然也可以建立多分区。
注:
分区的列最好不要与建表的列相同。
hive的分区使用的是外表字段,并且是一个伪列,可以用于查询过滤条件,但不会存储实际的值。
hive的分区名不准使用中文。
(1)静态分区
1)创建分区表
单分区
create table pt_orders
(order_id string, eval_set string, order_number string)
partitioned by(user_id_pt string)
row format delimited fields terminated by ','
lines terminated by '\n'
hive中对应存储路径 /user/hive/warehouse/mutli_pt_orders
增加的语句有两种
insert into是增加数据
insert overwrite是删除原有数据然后在新增数据,如果有分区那么只会删除指定分区数据,其他分区数据不受影响
多级分区
create table multi_pt_orders
(order_id string, eval_set string, order_number string)
partitioned by(user_id_pt string, order_dow_pt string)
row format delimited fields terminated by ','
lines terminated by '\n'
user_id为一级分区,order_dow为二级分区
HDFS中对应存储路径/user/hive/warehouse/pt_orders
2)导入数据
insert导入(常用)
% 单级
insert overwrite table pt_orders partition(user_id_pt=1)
select order_id, eval_set, order_number
from orders where user_id=1
在HDFS上的路径/user/hive/warehouse/pt_orders/user_id=1
% 多级
insert overwrite table multi_pt_orders partition(user_id_pt=1,order_dow_pt=1)
select order_id, eval_set, order_number
from orders where user_id=1 and order_dow=1
在HDFS上的路径/user/hive/warehouse/mutli_pt_orders/user_id=1/order_dow=1
load加载
load data local inpath "/home/admin/badou_project_data/project1/orders.csv"
into table multi_pt_orders partition(user_id_pt=2,order_dow_pt=1);
3)查看表中分区种类
show partitions pt_orders;
4)添加分区
% 单级
alter table pt_orders
add if not exists partition(user_id_pt=100)
partition(user_id_pt=200)
% 多级
alter table multi_pt_orders
add if not exists partition(user_id_pt=100,order_dow_pt=1)
partition(user_id_pt=200,order_dow_pt=1)
partition(user_id_pt=200,order_dow_pt=2)
partition(user_id_pt=2000,order_dow_pt=2)
5)删除分区
% 单级
alter table pt_orders
drop if exists partition(user_id_pt=1000),
partition(user_id_pt=100000)
% 多级
alter table multi_pt_orders
drop if exists partition(user_id_pt=200,order_dow_pt=1),
partition(user_id_pt=2000,order_dow_pt=2)
注意删除需要用,相隔,添加不需要
6)修复分区
修复分区就是重新同步hdfs上的分区信息。
msck repair table pt_orders;
(2)动态分区
上述分区都是静态分区,插入的时候知道分区类型,而且每个分区写一个load data,很繁琐。使用动态分区可解决以上问题,其可以根据查询得到的数据动态分配到分区里。其实动态分区与静态分区区别就是不指定分区目录,由系统自己选择。
静态分区在插入数据的时候需要指明分区类型,如果有很多个分区的话,需要每一个都写出来,较为繁琐,动态分区就是为了解决这个问题而出现的。动态分区可以根据select查询得到的数据自动的分配各个对应分区里,而不需要在插入时写出每个需要对应的分区。
动态分区与静态分区的操作区别是:(1)需要开启动态配置;(2)插入数据时后不需要指定分区值,相同字段会自动分为一个分区
注:动态分区可以允许所有的分区列都是动态分区列,但不允许主分区采用动态列而副分区采用静态列(一个未指定分区值,一个指定分区值),这样将导致所有的主分区都要创建副分区静态列所定义的分区。
1)创建分区表
create table pt_movies
(iid string,
score string,
ts string)
partitioned by(pt_uid string)
row format delimited fields terminated by '\t'
lines terminated by '\n'
2)开启动态配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
如果出现org.apache.hadoop.hive.ql.metadata.HiveException:Hive Runtime Errore processing row...错误,可调整分区大小、创建文件大小
SET hive.exec.max.dynamic.partitions=100000;(如果自动分区数大于这个参数,将会报错)
SET hive.exec.max.dynamic.partitions.pernode=100000;
set hive.exec.max.created.files=100000;
3)插入数据
insert into pt_movies partition(pt_uid)
select
iid,
score,
ts,
uid as pt_uid
from movies;
注意: 分区名要放到列的最后一个才能对应起来
(3)静态分区和动态分区的区别
静态分区
① 静态分区是在编译期间指定的指定分区名
② 支持load和insert两种插入方式
load方式
会将分区字段的值全部修改为指定的内容,一般是确定该分区内容是一致的时候才会使用。
insert方式
必须先将数据放在一个没有设置分区的普通表中,该方式可以在一个分区内存储一个范围的内容,从普通表中选出的字段不能包含分区字段。
③ 适用于分区数少,分区名可以明确的数据
动态分区
①根据分区字段的实际值,动态进行分区
② 在sql执行的时候进行分区
③ 需要先将动态分区设置打开
④ 只能用insert方式
⑤ 通过普通表选出的字段包含分区字段,分区字段放置在最后,多个分区字段按照分区顺序放置
(4)静态分区和动态分区的应用场景
静态分区: 适合已经确认分区的文件,分区相对较少的,适合增量导入的应用场景。
动态分区: 适合根据时间线做分区,分区比较多的,适合全量导入的场景。
拓展资料
hive分区操作partition——静态分区和动态分区语法、区别及使用场景
16. 数据分桶
分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式,(不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况)
分桶是将数据集分解为更容易管理的若干部分的另一种技术是比表或分区更为细粒度的数据范围划分。按照用户创建表时指定的分桶字段进行hash散列多个文件。
1、原理
跟MR中的HashPartitioner的原理一模一样
1、MR中:按照key的hash值去模除以reductTask的个数
2、Hive中:按照分桶字段的hash值去模除以分桶的个数
2、作用
1、方便抽样
2、提高join查询效率
3、分桶和分区的区别
1、个数
(1)分桶表的个数:由用户的HQL语句所设置的reduceTask的个数决定。
(2)表的分区的个数:也能由用户自定义指定。也能由程序自动生成, 分区是可以动态增长的。
2、更改
(1)分桶表是一经决定,就不能更改,所以如果要改变桶数,要重新插入分桶数据。
(2)分区数是可以动态增长的。
3、key值
(1)分桶表中的每个分桶中的数据可以有多个key值。
(2)分区表中的每个分区只有一个 key值。
注:分桶和分区两者不干扰,可以把分区表进一步分桶;分区针对的是数据的存储路径;分桶针对的是数据文件。
4、分桶的操作
首先创建一个分桶的空表,然后创建个临时表,往临时表导入数据,然后在从临时表中分桶查询出来的数据insert到分桶的空表里。
(1)建表
通过 clustered by(字段名) into bucket_num buckets 分桶,意思是根据字段名分成bucket_num个桶
CREATE TABLE movies_bucket (
uid string,
iid string,
score string,
ts string
)
clustered by(uid,iid) into 6 buckets
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
开启强制分桶
hive> set hive.enforce.bucketing=true;
若没有使用hive.enforce.bucketing属性,则需要设置和分桶个数相匹配的reducer个数。
因为桶的概念就是MapReduce的分区的概念,两者是完全一样的,物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同。
所以若只有一个分区且没有开启强制分桶模式时,不会实现分桶。(hive分桶本质上就是mapreduce的分区)
(2)导入数据
分桶表导入数据需要通过中间表来实现,首先建立一个中间表,用load将数据导入中间表中,再通过insert将数据插入到分桶表。
1)创建中间表
CREATE TABLE `movies`(
`uid` string,
`iid` string,
`score` string,
`ts` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
2)加载数据到中间表
load data local inpath '/home/admin/hive_test_data/Hivedata/movies.txt' into table test;
3)通过insert插入数据
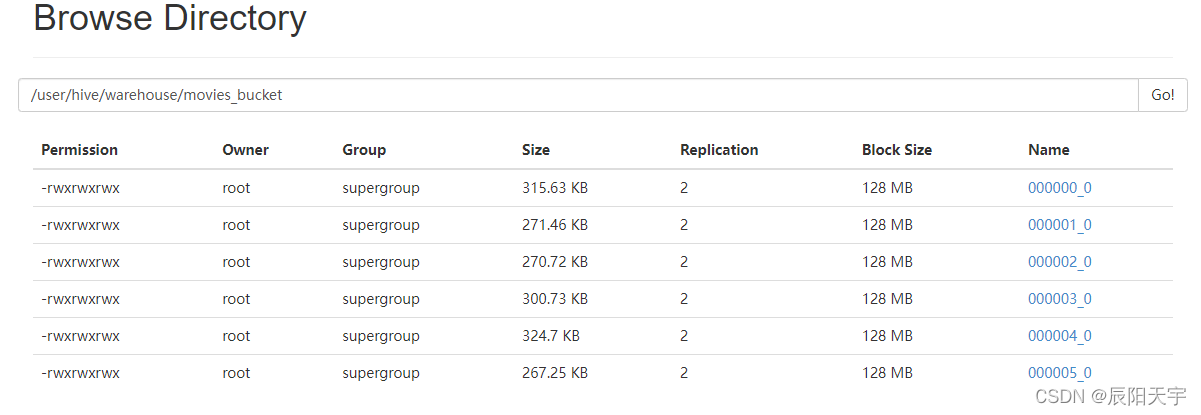
INSERT INTO movies_bucket
SELECT
*
FROM movies;
查看目录,发现正确分出六个桶
(3)分层抽样
对表分桶一般有两个目的,提高数据查询效率、抽样调查。通过前面的实战,我们已经可以对分桶表进行正常的创建并导入数据了。一般在实际生产中,对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。这个时候Hive就可以通过对表进行抽样来满足这个需求。
select * from movies_bucket tablesample(bucket 1 out of 3 on uid);
语法解析:
bucket x out of y on uid
x:表示从第x个桶开始抽取,
y:控制抽取比例,例如若总共有6个桶,则抽取6/3=2个桶的数据,若y=8,则抽取6/8=3/4个桶的数据。
(4)删除数据
truncate table movies_bucket;
参考文章:
一文彻底学会hive分桶表(实战详解)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)