Postgresql学习
2.数据类型PostgrSql为我们提供了许多数据类型,用户可以使用CREATE TYPE命令在数据库中创建新的数据类型,PostgreSQL的数据类型有很多种,下面我们具体介绍。数值类型由2字节、4字节或8字节的整数以及4字节或者8字节的浮点数和可选京都的十进制数组成money类型存储带有固定小数精度的货币金额。numeric、int和bigint类型的值可以转换为money,不建议使用浮点数来
文章目录
- 1.java连接postgre
- 2.数据类型
- 3.进入和退出数据库
- 4.创建数据库
- 5.删除数据库
- 6.创建表格
- 7.删除表格
- 8.PostgreSQL模式(SCHEMA)
- 9.INSERT INTO 语句
- 10.SELECT语句
- 11.运算符
- 12.表达式
- 13.WHERE 子句(模糊查询,子查询)
- 14.UPDATE语句(更新语句)
- 15.DELETE语句
- 16.LIMIT 语句
- 17.ORDER BY语句
- 18.GROUP BY语句
- 19.WITH子句
- 20.HAVING子句
- 21去重关键字(DISTINCT)
- 22.约束
- 23.连接(JOIN)
- 24.UNION 操作符
- 25.IS NULL和IN NOT NULL操作符
- 26.别名
- 27.触发器
- 28.索引
- 29.表结构修改命令(ALTER TABLE命令)
- 30.删除表中的数据(TRUNCATE TABLE)
- 31.视图(View)
- 32.事务
- 32.1事务的特性:
- 32.2事务控制命令
- 33.锁
- 34.自动增长(AUTO_INCREMENT)
- 35.常用函数
- 36.序列: [参考网站](https://n3xtchen.github.io/n3xtchen/postgresql/2015/04/10/postgresql-sequence)
- 37.常用符号
- 38.postgresql中的类if-else语句
- 39常用操作
1.java连接postgre
1.安装postgre数据库
2.引入依赖
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.2</version>
</dependency>
3.修改数据库连接配置
pring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: org.postgresql.Driver
druid:
# 主库数据源
master:
url: jdbc:postgresql://dockeros:15432/gulimall_admin?useSSL=false&stringtype=unspecified
username: postgres
password: 123456
2.数据类型
PostgrSql为我们提供了许多数据类型,用户可以使用CREATE TYPE命令在数据库中创建新的数据类型,PostgreSQL的数据类型有很多种,下面我们具体介绍。
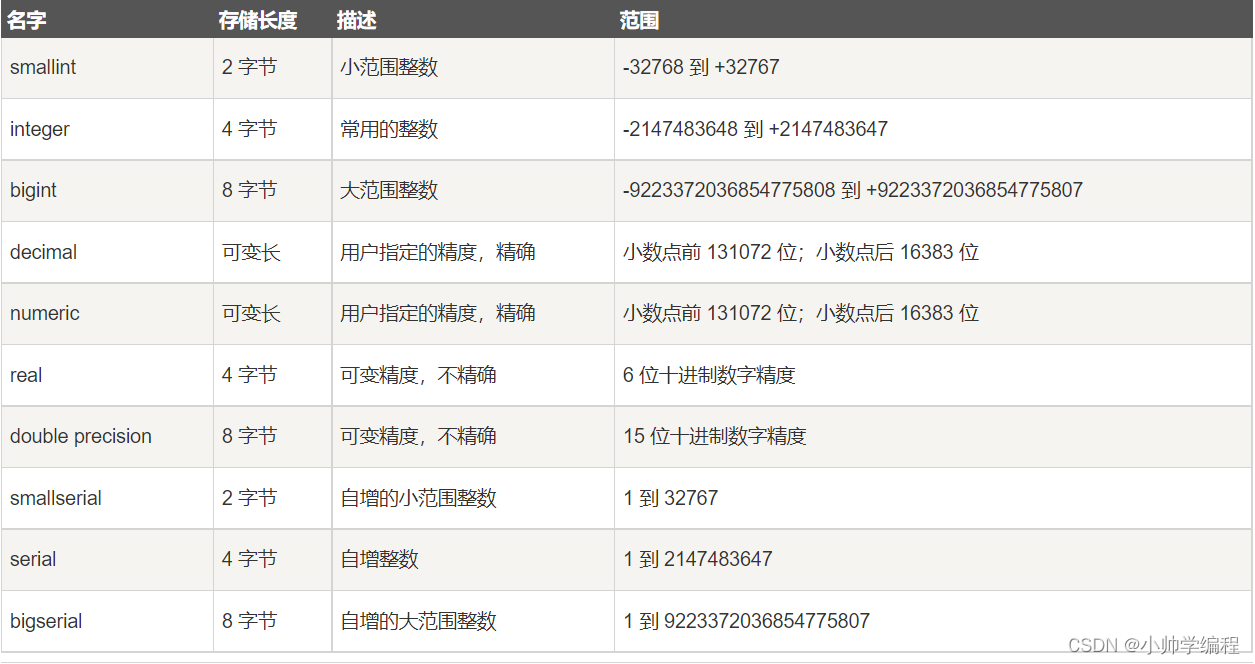
2.1数值类型
数值类型由2字节、4字节或8字节的整数以及4字节或者8字节的浮点数和可选京都的十进制数组成
2.2货币类型
money类型存储带有固定小数精度的货币金额。numeric、int和bigint类型的值可以转换为money,不建议使用浮点数来处理货币类型,因为存在摄入错误的可能性。

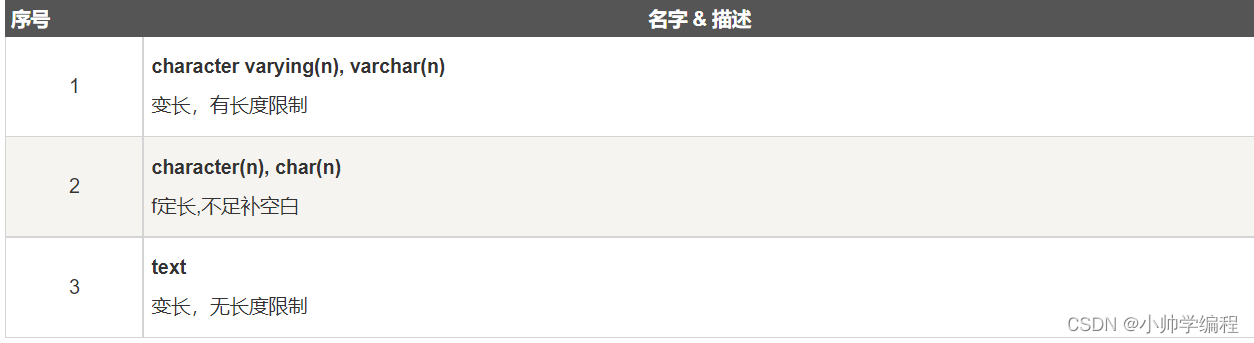
2.3字符类型
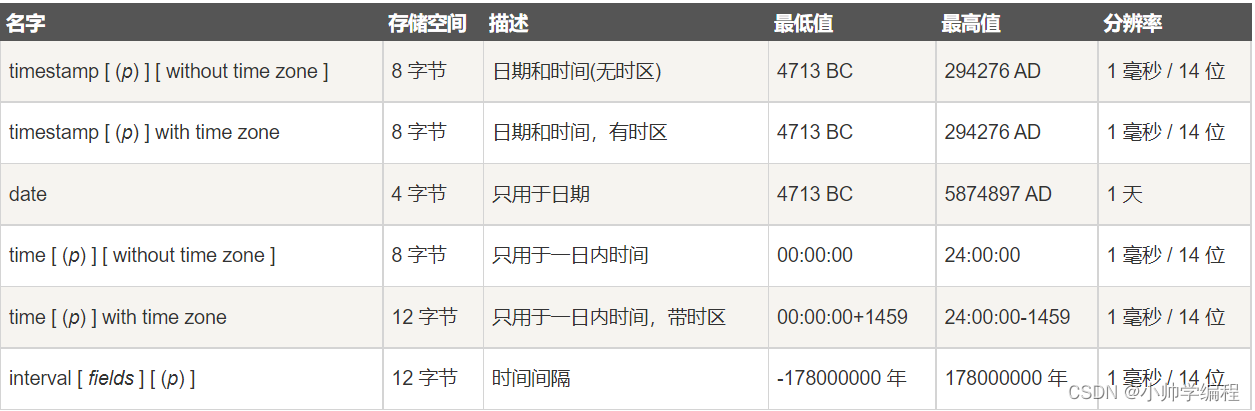
2.4日期或者时间类
2.5布尔类型
PostgreSQL支持标准的boolean类型数据。boolean由‘true’或‘false’两个状态,第三种‘unknow’状态,用null表示

2.6枚举类型
枚举类型是一个包含静态和值的有序集合的数据类型,PostgreSQL中的枚举类型类似于C语言中的enum类型,与其他类型不同的是枚举类型需要使用
CREATE TYPE命令创建。
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');
SELECT * FROM person WHERE current_mood = 'happy';
name | current_mood
------+--------------
Moe | happy
(1 row)
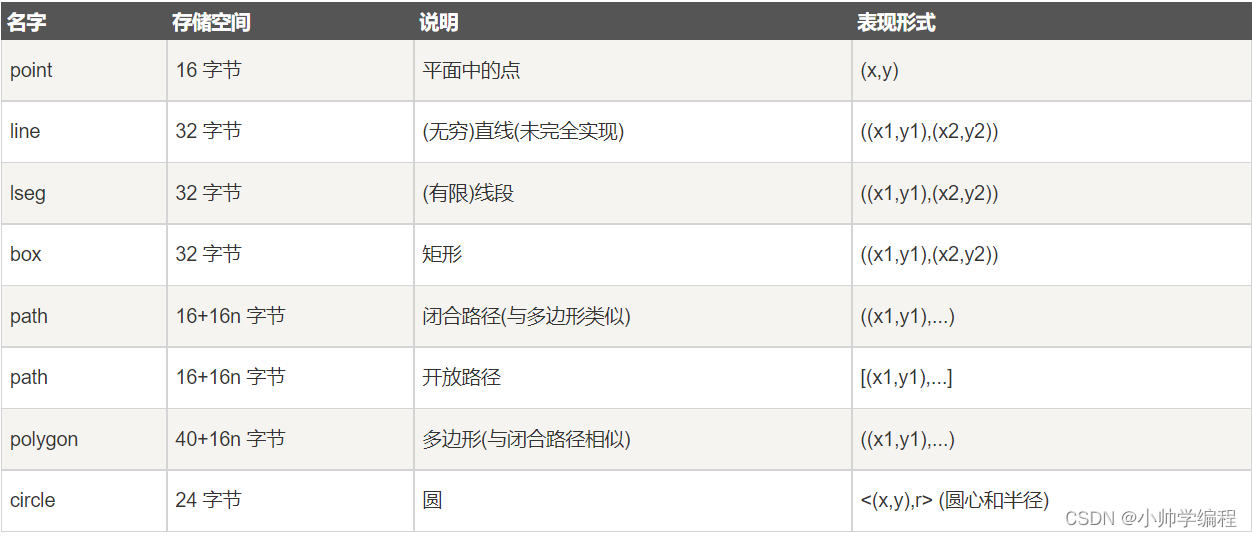
2.7几何类型
几何数据类型表示几维的平面物体。
2.8网络地址类型
使用这些数据类型储存网络地址比用纯文本类型好,因为这些类型提供输入错误检查和特殊的操作和功能。
在对inet或cidr数据类型进行排序的时候,IPV4地址总是排在IPv6地址前面,包括那些封装或者是映射在IPv6地址里的IPv4地址,比如 ::10.2.3.4 或 ::ffff:10.4.3.2。
2.9位串类型
位串就是一串1和0的字符串,它们可以用于存储和直观化位掩码,我们有两种SQL位类型:bit(n)和bit varying(n),这里的n是一个正整数,bit类型的数据必须准确匹配长度n,试图存储短些或者长一些的数据都是错误的,bit varying类型数据是最长n的变长类型,更长的串会被拒写,写一个没有长度的bit等于bit(1),没有长度的bit varying相当于没有长度限制。
2.10文本搜索类型
全文检索即通过自然语言文档的集合来找到那些匹配一个查询的检索。

2.11UUID类型
uuid 数据类型用来存储 RFC 4122,ISO/IEF 9834-8:2005 以及相关标准定义的通用唯一标识符(UUID)。 (一些系统认为这个数据类型为全球唯一标识符,或GUID。) 这个标识符是一个由算法产生的 128 位标识符,使它不可能在已知使用相同算法的模块中和其他方式产生的标识符相同。 因此,对分布式系统而言,这种标识符比序列能更好的提供唯一性保证,因为序列只能在单一数据库中保证唯一。
UUID 被写成一个小写十六进制数字的序列,由分字符分成几组, 特别是一组8位数字+3组4位数字+一组12位数字,总共 32 个数字代表 128 位, 一个这种标准的 UUID 例子如下:
a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
2.12XML类型
xml 数据类型可以用于存储XML数据。 将 XML 数据存到 text 类型中的优势在于它能够为结构良好性来检查输入值, 并且还支持函数对其进行类型安全性检查。 要使用这个数据类型,编译时必须使用 configure --with-libxml。
xml 可以存储由XML标准定义的格式良好的"文档", 以及由 XML 标准中的 XMLDecl? content 定义的"内容"片段, 大致上,这意味着内容片段可以有多个顶级元素或字符节点。 xmlvalue IS DOCUMENT 表达式可以用来判断一个特定的 xml 值是一个完整的文件还是内容片段。
2.12.1创建XML值
使用函数 xmlparse: 来从字符数据产生 xml 类型的值:
XMLPARSE (DOCUMENT '<?xml version="1.0"?><book><title>Manual</title><chapter>...</chapter></book>')
XMLPARSE (CONTENT 'abc<foo>bar</foo><bar>foo</bar>')
2.12JSON类型
json 数据类型可以用来存储 JSON(JavaScript Object Notation)数据, 这样的数据也可以存储为 text,但是 json 数据类型更有利于检查每个存储的数值是可用的 JSON 值。此外还有相关的函数来处理 json 数据:

2.12.1常用操作
2.12.1.1更新JSON属性中的字段
UPDATE 表名 set 列名 = (jsonb_set(列名::jsonb,'{key}','"value"'::jsonb)) where 条件
2.13数组类型
PostgreSQL允许将字段定义成变长的多维数组。数组类型可以是任何基本类型或用户定义类型,枚举类型或复合类型。
2.13.1声明数组
创建表的时候,我们可以声明数组,方式如下:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
pay_by_quarter 为一维整型数组、schedule 为二维文本类型数组。我们也可以使用 “ARRAY” 关键字,如下所示:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer ARRAY[4],
schedule text[][]
);
2.13.2插入值
插入值使用花括号 {},元素在 {} 使用逗号隔开:
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
2.13.3访问数组
SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2];
2.13.4修改数组
我们可以对数组的值进行修改
UPDATE sal_emp SET pay_by_quarter = '{25000,25000,27000,27000}' WHERE name = 'Carol';
或者使用ARRAY构造器语法:
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000] WHERE name = 'Carol';
2.13.5数组中检索
-- 找出元素值等于1000的行 --
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
2.14复合类型
复合类型表示一行或者一条记录的结构,它实际上只是一个字段名和它的数据类型的列表,PostgreSQL允许想简单数据类型那样使用复合类型,比如,一个表的某个字段可以声明为一个复合类型
2.14.1声明复合类型
CREATE TYPE complex AS (
r double precision,
i double precision
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
语法类似于CREATE TABLE,只是这里只可以声明字段名字和类型。定义了类型,我们就可以用它创建表:
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
2.14.2复合类型值输入
要以文本常量书写复合类型值,在原括号里保卫字段值并且用逗号分隔他们,你可以在任何字段值周围放上双引号,如果值本身包含逗号或者圆括弧,你必须用双引号括住。
'( val1 , val2 , ... )'
'("fuzzy dice",42,1.99)'
2.14.3访问复合类型
要访问复合类型字段的一个域,我们写出一个点以及域的名字,非常类似于从一个表明资料选出一个字段,实际上,因为实在太像从表名字中选择字段,所以我们经常需要用换括号来避免分析器混淆,比如,你可能需要从on_hand例子中选取一些子域。
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
2.15范围类型
范围类型数据代表着某一些元素类型在一定范围内的值。PostgreSQL内置的范围类型有:
- int4range — integer的范围
- int8range —bigint的范围
- numrange —numeric的范围
- tsrange —timestamp without time zone的范围
- tstzrange —timestamp with time zone的范围
- daterange —date的范围
当然了,也可以定义自己的范围类型
2.16对象标识符类型
PostgreSQL在内部使用对象标识符(OID)作为各种系统表的主键。同时系统不会给用户创建的表增加一个OID系统字段(除非在建表时声明了WITH OIDS 或者配置参数default_with_oids设置为开启)。oid 类型代表一个对象标识符。除此以外 oid 还有几个别名:regproc, regprocedure, regoper, regoperator, regclass, regtype, regconfig, 和regdictionary。
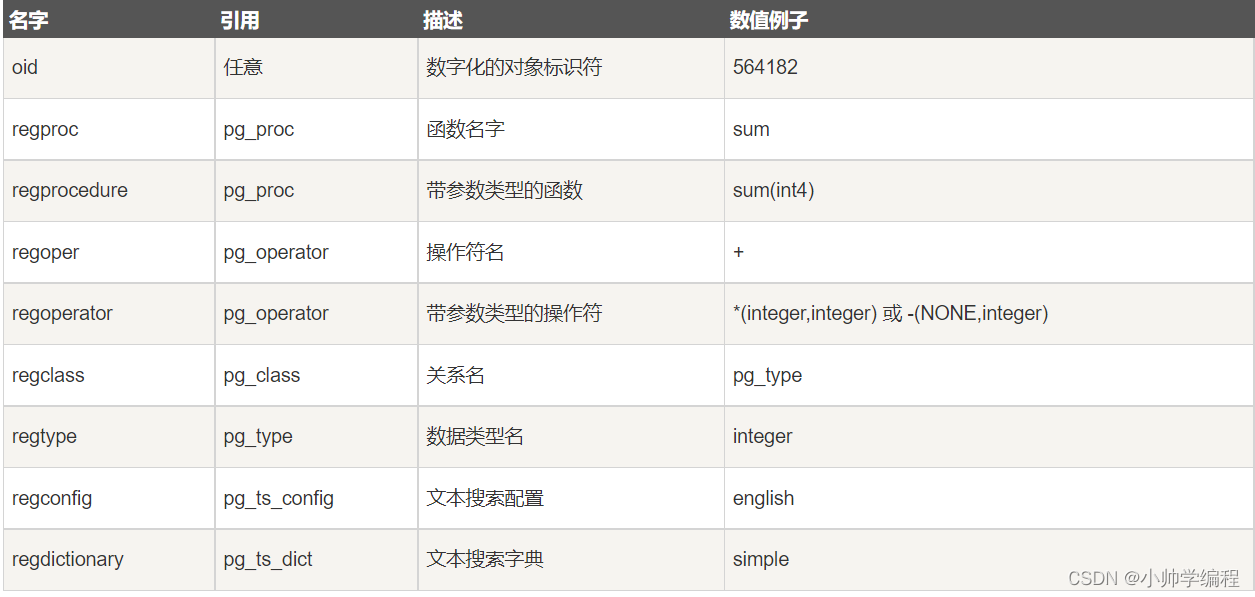
2.17伪类型
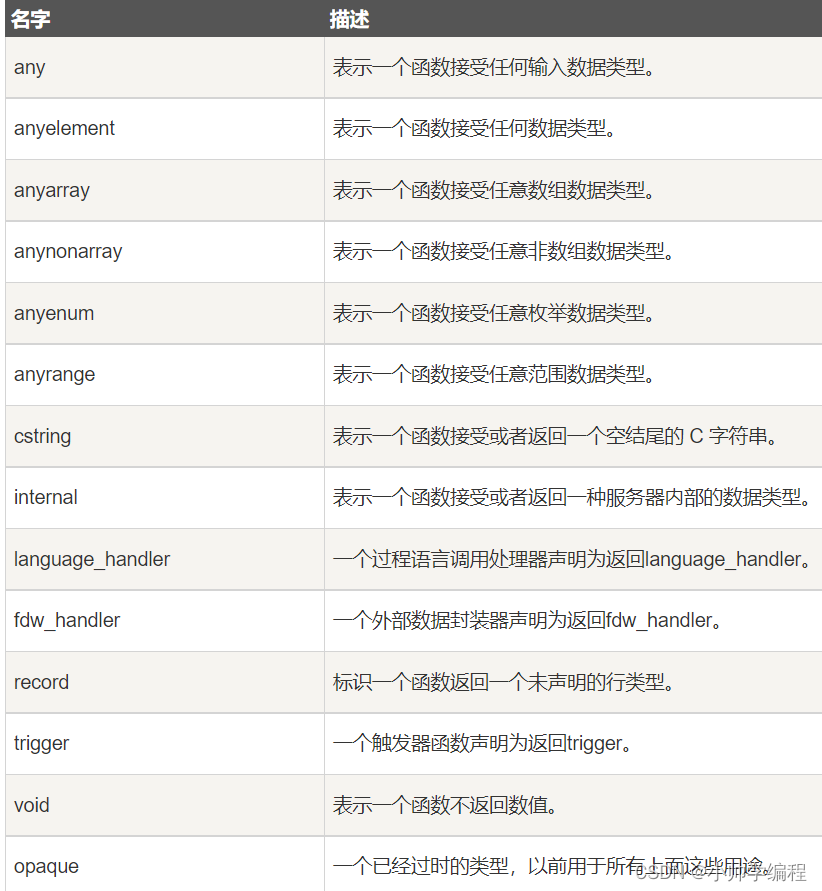
PostgreSQL类型系统包含一系列特殊用途的条目, 它们按照类别来说叫做伪类型。伪类型不能作为字段的数据类型, 但是它可以用于声明一个函数的参数或者结果类型。 伪类型在一个函数不只是简单地接受并返回某种SQL 数据类型的情况下很有用。
3.进入和退出数据库
#进入数据库
psql -U postgres
#查看所有数据库
\l
#进入某一数据库
\c 数据库名
#退出数据库
ctrl + z
4.创建数据库
CREATE DATABASE 数据库名;
5.删除数据库
DROP DATABASE 数据库名
6.创建表格
格式:
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY( 一个或多个列 )
);
例子:
CREATE TABLE department(
id INT PRIMARY KEY NOT NULL,
dept CHAR(50) NOT NULL,
emp_id INT NOT NULL
);
查看表格信息:
\d 表名
7.删除表格
DROP TABLE 表名
8.PostgreSQL模式(SCHEMA)
PostgreSQL模式可以看成一个表的集合,一个模式可以包含视图、索引、数据类型、函数和操作符等。相同的对象名称可以被用于不同的模式中而不会出现冲突,例如schema1和myschema都可以包含名为mytable的表,使用模式的优势是:
- 允许多个用户使用一个数据库且并不会互相干扰
- 将数据库对象组织成逻辑组即便更容易管理
- 第三方应用的独享可以独立放在独立的模式中,这样他们就不会与其他对象的名称发生冲突。
8.1创建模式
create schema myschema;
8.2在模式中创建表格
CREATE TABLE myschema.company (
id INT NOT NULL,
name VARCHAR(20) NOT NULL,
age INT NOT NULL,
address CHAR(25),
salary DECIMAL(18,2),
PRIMARY KEY (id)
);
8.3删除模式
DROP SCHEMA myschema;
--删除模式以及其中包含的所有数据
DROP SCHEMA myschema CASCADE;
9.INSERT INTO 语句
语法:
INSERT INTO 表名(字段名1,字段名2.....) VALUES (值1,值2.....);
-- 向表中所有字段插入值
INSERT INTO 表名 VALUES(值1,值2......)
10.SELECT语句
语法:
--查询表中所有字段
SELECT * FROM 表名
--查询表中指定字段
SELECT 字段名.... FROM 表名
11.运算符
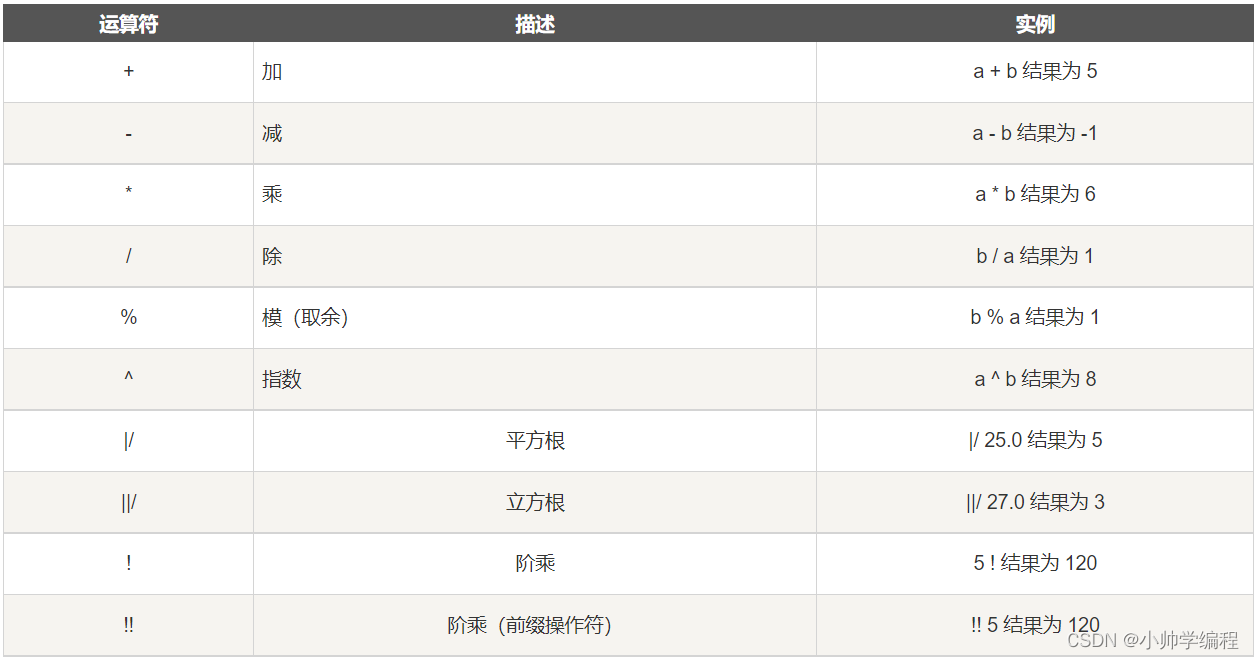
11.1算数运算符
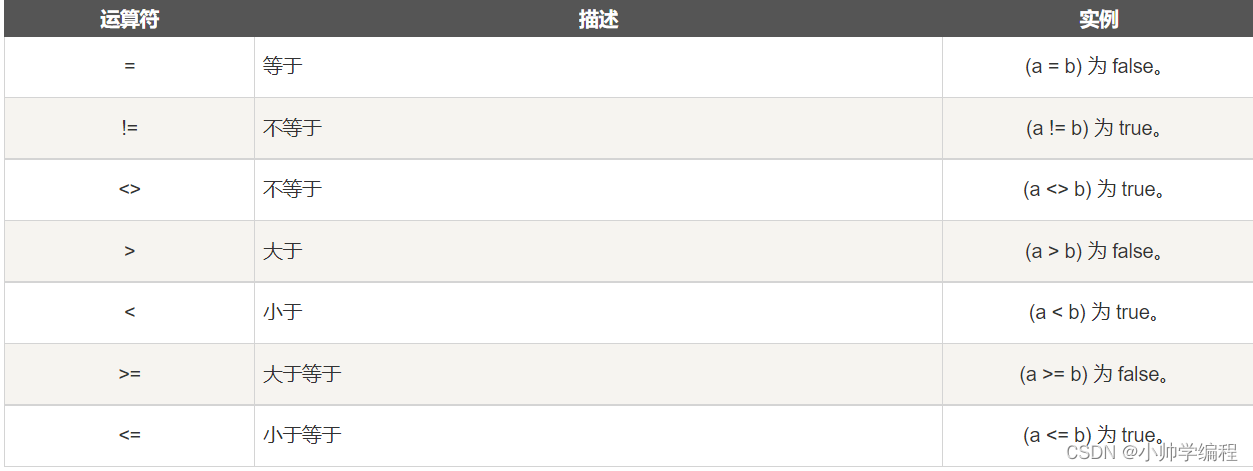
11.2比较运算符
11.3逻辑运算符

11.4位运算符

12.表达式
- 布尔表达式
- 数字表达式
avg():返回一个表达式的平均值
sum():返回指定字段的总和
count():返回查询的记录总和
- 日期表达式
SELECT CURRENT_TIMESTAMP;
13.WHERE 子句(模糊查询,子查询)
在 PostgreSQL 中,当我们需要根据指定条件从单张表或者多张表中查询数据时,就可以在 SELECT 语句中添加 WHERE 子句,从而过滤掉我们不需要数据。WHERE 子句不仅可以用于 SELECT 语句中,同时也可以用于 UPDATE,DELETE 等等语句中。
13.1语法
- AND
- OR
- NOT NULL
SELECT *
FROM object_intance AS oi
WHERE oi.name IS NOT NULL
- LIKE
-- %代表任意字符,-代表一个字符
SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
- IN
runoobdb=# SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
- NOT IN
SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
- BETWEEN
SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
- 子查询
SELECT *
FROM COMPANY
WHERE AGE > (
SELECT AGE
FROM COMPANY
WHERE SALARY > 65000
);
14.UPDATE语句(更新语句)
语法
UPDATE 表名
SET 字段名=值名,字段名=值名....
WHERE 条件语句
例子
UPDATE company
SET "name" = '库里'
WHERE "id" = 1
15.DELETE语句
语法:
DELETE FROM 表名
WHERE 条件语句
例子:
DELETE FROM company
WHERE "id" = 1
16.LIMIT 语句
语法:
-- 截取n位数据
LIMIT n;
--偏移m位截取n位数据(从第m位数据开始截取,截取n位数据)
LIMIT n OFFSET m;
例子:
SELECT *
FROM company AS c
LIMIT 5 OFFSET 3
SELECT *
FROM company AS c
LIMIT 5 OFFSET 3
17.ORDER BY语句
语法:
ORDER BY 字段名 asc/desc;--asc升序,desc降序
18.GROUP BY语句
GROUP BY语句和SELECT语句一起使用,用来对相同的数据进行分组,GROUP BY在一个SELECT 语句中,放在WHERE子句的后面,ORDER BY子句的前面。
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
19.WITH子句
在PostgreSQL中,WITH自居提供了一种编写辅助语句的方法,以便在更大的查询中使用。WITH字句有助于将复杂的大型查询分解为跟简单的表单,便于阅读,这些语句通常称为通式表达式(CTE),也可以当作一个为查询而存在的临时表。WITH语句在使用前必须先定义。基本语法如下:
With CTE AS
(Select
ID
, NAME
, AGE
, ADDRESS
, SALARY
FROM COMPANY )
Select * From CTE;
20.HAVING子句
HAVING子句可以让我们筛选分组后的各组数据,WHERE子句在所选列上设置条件,而HAVING子句则在有GROUP BY创建的分组上设置条件。
语法:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
示例:
SELECT *
FROM object_instance AS oi
WHERE oi.id > 5
GROUP GY oi.name
HAVING count(*) > 5
21去重关键字(DISTINCT)
DISTINCE关键字与SELECT语句一块使用,用于去除重复记录,只获取唯一记录,我们平时在操作数据时,有可能出现一种情况,在一个表中有多个重复的记录,当提取这样的记录时,DISTINCT关键字就显得特别有意义,特只能获取唯一一次记录,而不是获取重复数据。
22.约束
PostgreSQL约束用于规定表中的数据规则,如果存在违反约束的数据行为,行为会被约束终止。约束可以是列级或表级,列级约束仅适用于列,表级约束应用到整张表。
22.1 约束分类
- 非空约束(NOT NULL)
所在字段不能为空
- 唯一约束(UNIQUE)
所在字段不能出现重复值
- 主键约束(PRIMARY KEY)
所在字段唯一且不能为空,一张表中只能有一个字段存在主键约束
- 外键约束(FOREIGN KEY)
指定列(或者一组列)中的值必须匹配另一个表的某一行中出现的值
- 检查约束(CHECK KEY)
保证列中的所有值满足某一条件,及对输入一条记录,如果条件值为false,则记录违反了约束,且不能输入到表。
CREATE TABLE COMPANY5(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL CHECK(SALARY > 0)
);
- 排他约束(EXCLUSION KEY)
只能满足两个要求中的一个l。
CREATE TABLE COMPANY7(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT,
AGE INT ,
ADDRESS CHAR(50),
SALARY REAL,
EXCLUDE USING gist
(NAME WITH =, – 如果满足 NAME 相同,AGE 不相同则不允许插入,否则允许插入
AGE WITH <>) – 其比较的结果是如果整个表边式返回 true,则不允许插入,否则允许
);
22.1 删除约束(DELETE KEY)
ALTER TABLE table_name DROP CONSTRAINT some_name;
23.连接(JOIN)
- 内连接(INNER JOIN)
找到满足连接条件的匹配对
- 左外连接(LEFT JOIN)
对于左外连接,首先执行一个内连接。然后,如果右边表没有满足条件的数据,会给左边表的数据匹配一个空值。
- 右外连接(RIGHT JOIN)
首先执行一个内连接。然后,如果左边表没有满足条件的数据,会给右边表的数据匹配一个空值。
- 全外连接(FULL JOIN)
首先,执行内部连接。然后,对于表 T1 中不满足表 T2 中任何行连接条件的每一行,如果 T2 的列中有 null 值也会添加一个到结果中。此外,对于 T2 中不满足与 T1 中的任何行连接条件的每一行,将会添加 T1 列中包含 null 值的到结果中。
- 交叉连接(CROSS JOIN)
交叉连接(CROSS JOIN)把第一个表的每一行与第二个表的每一行进行匹配。如果两个输入表分别有 x 和 y 行,则结果表有 x*y 行。类似于笛卡尔积现象。由于交叉连接(CROSS JOIN)有可能产生非常大的表,使用时必须谨慎,只在适当的时候使用它们
语法:SELECT … FROM table1 CROSS JOIN table2 …
24.UNION 操作符
PostgreSQL UNION 操作符合并两个或多个 SELECT 语句的结果。UNION 操作符用于合并两个或多个 SELECT 语句的结果集。请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
语法:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
24.1UNION ALL子句
UNION ALL 操作符可以连接两个有重复行的 SELECT 语句,默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
语法:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION ALL
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
25.IS NULL和IN NOT NULL操作符
-- IS NULL表示为空,IS NOT NULL表示非空
SELECT ID, NAME, AGE, ADDRESS, SALARY FROM COMPANY WHERE SALARY IS NOT NULL;
SELECT ID, NAME, AGE, ADDRESS, SALARY FROM COMPANY WHERE SALARY IS NULL;
26.别名
我们可以用 SQL 重命名一张表或者一个字段的名称,这个名称就叫着该表或该字段的别名。创建别名是为了让表名或列名的可读性更强。SQL 中 使用 AS 来创建别名。
SELECT column1, column2....
FROM table_name AS alias_name
WHERE [condition];
SELECT column_name AS alias_name
FROM table_name
WHERE [condition];
27.触发器
PostgreSQL触发器是数据库的回调函数,他会在指定数据库事件发生时自动执行/调用。
- PostgreSql触发器可以在下面几种情况下触发:
- 在执行操作之前(再检查约束并尝试插入、更新或删除完成之后)。
- 在执行操作之后(再检查约束并插入、更新或删除之后)。
- 更新操作(对一个视图进行插入、更新、删除时)
- 触发器的FOR EACH ROW属性是可选的,如果选中,当操作修改时每行调用一次,相反,选中FOR EACH STATEMENT,不管修改了多少行,每个语句标记的触发器执行一次。
- WHEN子句和触发器操作在作用NEW.column-name和OLD.column-name表中插入、删除或更新时可以访问每一行元素,其中column-name是与触发器关联的表中的列的名称。
- 如果存在WHEN子句,PostgreSQL语句只会执行WHEN字句成立的那一行,如果没有WHEN子句,PostgreSQL语句会在每一行执行。
- BEFORE或者AFTER关键字决定何时触发器执行,决定是在关联行的插入/修改或删除之前或者之后执行触发器动作。
- 要修改的表必须存在于同一数据库中,作为触发器被附加的表或者视图,其必须只使用tablename,而不是database.tablename。
- 当创建约束触发器时会指定约束选项。这与常规触发器相同,只是可以使用这种约束来调整触发器触发的时间。当约束触发器实现的约束被违反时,它将抛出异常。
27.1语法
CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name
ON table_name
[
-- 触发器逻辑....
];
在这里,event_name 可以是在所提到的表 table_name 上的 INSERT、DELETE 和 UPDATE 数据库操作。您可以在表名后选择指定 FOR EACH ROW。
28.索引
索引是加速搜索引擎检索数据的一种特殊表查询,简单来说,索引是一个执行表中数据的指针,一个数据库的索引与一本书的索引条目是非常相似的。使用CREATE INDEX语句创建索引,它允许命名索引,指定表及要索引的一列或多列,并指定索引时升序排列还是降序排列。索引也可以是唯一的,与UNIQUE约束类型,在列上或列组合上防止重复条目。
28.1创建索引
CREATE INDEX index_name ON table_name;
28.2索引类型
28.2.1单列索引
单列索引是一个只基于表的一个列上创建的索引,基本语法如下:
CREATE INDEX index_name
ON table_name(column_name)
28.2.2组合索引
组合索引是基于表的多列上创建的索引,基本语法如下:
CREATE INDEX index_name
ON table_name(column1_name, column2_name)
不管是单列索引还是组合索引,该索引必须是在WHERE子句的过滤条件中使用非常频繁的列,如果只有一列被使用到,就选择单列索引,如果有多列就是用组合索引。
28.2.3唯一索引
使用唯一索引不仅是为了性能,同时也为了数据的完整性,唯一索引不允许任何重复的值插入到表中,基本语法如下:
CREATE UNIQUE INDEX index_name
ON table_name(column_name)
28.2.4局部索引
局部索引是在表的子集上构建的索引;子集有一个条件表达式上定义,索引值包含满足条件的行,基础语法如下:
CREATE INDEX index_name
ON table_name(conditional
28.2.5隐式索引
隐式索引是在创建对象时候时,有数据库服务器自动创建的索引,索引自动创建为主键约束和唯一约束。
28.3显示所有的索引
\d company
\di
28.4删除索引
DROP INDEX salary_index
28.5注意事项
- 索引不应该是用在较小的表上
- 索引不应该该使用在频繁的大批量对的更新或插入操作的表上。
- 索引不应该是用在含有大量的NULL值的列上
- 索引不应该是用在频繁操作的列上。
29.表结构修改命令(ALTER TABLE命令)
29.1添加列
ALTER TABLE table_name
ADD column_name datatype;
29.2删除列
ALTER TABLE table_name DROP COLUMN column_name;
29.3修改表中某列的数据类型
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype;
29.4添加约束
ALTER TABLE table_name ALTER column_name datatype NOT NULL;
29.5删除约束
ALTER TABLE table_name
DROP CONSTRAINT 约束类型
29.6添加注释
COMMENT ON COLUMN 表名.字段名 IS 注释;
30.删除表中的数据(TRUNCATE TABLE)
PostgreSQL 中 TRUNCATE TABLE 用于删除表的数据,但不删除表结构。
也可以用 DROP TABLE 删除表,但是这个命令会连表的结构一起删除,如果想插入数据,需要重新建立这张表。TRUNCATE TABLE 与 DELETE 具有相同的效果,但是由于它实际上并不扫描表,所以速度更快。 此外,TRUNCATE TABLE 可以立即释放表空间,而不需要后续 VACUUM 操作,这在大型表上非常有用。PostgreSQL VACUUM 操作用于释放、再利用更新/删除行所占据的磁盘空间。
TRUNCATE TABLE table_name
31.视图(View)
是一张假表,只不过是通过相关的名称存储在数据库中的一个 PostgreSQL 语句。PostgreSQL视图是只读的,因此可能无法在视图上执行DELETE、INSERT或者UPDATE语句,但是可以在视图上创建一个触发器,当尝试DELETE、INSERT或UPDATE视图时触发,需要做的动作在触发器内容中定义。
语法:
--创建视图语法
CREATE [TEMP | TEMPORARY] VIEW view_name AS
SELECT column1, column2.....
FROM table_name
WHERE [condition];
--创建视图例子:
CREATE VIEW COMPANY_VIEW AS
SELECT ID, NAME, AGE
FROM COMPANY;
--删除视图
DROP VIEW view_name;
32.事务
TRANSACTION(事务)是数据库管理系统执行过程中的一个逻辑单位,有一个有限的数据库操作序列构成。如果事务中有的操作没有成功完成,则事务中所有操作都需要回滚,回到事务执行前的状态,同时,该事务对数据库或者其他事务的执行无影响,所有的事物都好像在独立的运行。
32.1事务的特性:
- 原子性:事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性:事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
- 隔离性:多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
- 持久性:已被提交的事务对数据库的修改应该永久保存在数据库中。
32.2事务控制命令
- 开始事务:BEGIN;或者BEGIN TRANSACTION
- 确认事务:COMMIT;或者END TRANSACTION
- 回滚事务:ROLLBACK;
33.锁
所主要是为了保持数据库数据的一致性,可以阻止用户修改一行或者整个表,一边用在并发较高的数据库中,在多个用户访问数据库的时候若对并发操作不加控制就可能读取和存储不正确的数据,徘徊数据库的一致性。
数据库中有两种基本的锁:排它锁(Exclusive Locks)和共享锁(Share Locks)。如果数据对象加上排它锁,则其他的事务不能对它读取和修改。
如果加上共享锁,则该数据库对象可以被其他事务读取,但不能修改。
33.1基本语法:
LOCK [ TABLE ]
name
IN
lock_mode
- name:要锁定的现有表的名称(可选模式限定)。如果只在表名之前指定,则只锁定该表。如果未指定,则锁定该表及其所有子表(如果有)。
- lock_mode:锁定模式指定该锁与哪个锁冲突。如果没有指定锁定模式,则使用限制最大的访问独占模式。可能的值是:ACCESS SHARE,ROW SHARE, ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE,SHARE ROW EXCLUSIVE,EXCLUSIVE,ACCESS EXCLUSIVE。
33.2死锁
当两个事务彼此等待对方完成其操作时,可能会发生死锁。尽管 PostgreSQL 可以检测它们并以回滚结束它们,但死锁仍然很不方便。为了防止应用程序遇到这个问题,请确保将应用程序设计为以相同的顺序锁定对象。
33.3咨询锁
PostgreSQL 提供了创建具有应用程序定义含义的锁的方法。这些被称为咨询锁。由于系统不强制使用它们,所以正确使用它们取决于应用程序。咨询锁对于不适合 MVCC 模型的锁定策略非常有用。
34.自动增长(AUTO_INCREMENT)
AUTO INCREMENT(自动增长) 会在新记录插入表中时生成一个唯一的数字。
34.1例子
CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
35.常用函数
-- 转换为日期格式
todate();
-- 聚合函数(将查询后的接口合并到一行中)
string_agg(要合并的元素, 间隔符);
-- 返回括号中的第一个非空参数
coalesce(参数1,参数2,参数3,参数4.....)
-- if-else
CASE
WHEN 布尔表达式
THEN 值1 --布尔表达式为true时返回此结果
CASE 值2 --布尔表达式为false时返回此结果
END
--递归操作(需要注意下:select中不能用通配符*,要遵循UNINT ALL的语法,即初始语句和递归执行语句字段的属性必须相同)
WITH RECURSIVE 名字 AS (
初始语句
UNION ALL --或者UNION也可,UNION去重或者UNION ALL 不去重
递归执行语句
)
SELECT 查询结果 FROM 名字;
36.序列: 参考网站
36.1什么是序列
PostgreSQL中的序列是一个数据库对象,本质上是一个自增器。所以,Sequence也可以通过在每个属性后加上autoincrment的值的形式存在。
sequence的作用有两个方面:
- 1.作为表的唯一标识符字段的默认值使用
- 2.主要用于jilushujukuzhongdeid,只要语句有动作(I|U|D),sequence的号就会随着更新。
Sequence对象中包含当前值,和一些独特属性,例如如果递增(或者递减),实际上Sequence是不能被直接访问到的;他们需要通过PostgreSQL中的相关函数来操作。
36.2创建序列
CREATE SEQUENCE sequencename
[ INCREMENT increment ] -- 自增数,默认是 1
[ MINVALUE minvalue ] -- 最小值
[ MAXVALUE maxvalue ] -- 最大值
[ START start ] -- 设置起始值
[ CACHE cache ] -- 是否预先缓存
[ CYCLE ] -- 是否到达最大值的时候,重新返回到最小值
36.3查看序列
PSQL的\d命令输出一个数据库对象,包括Sequence,表,视图和索引,还可以用\ds命令之查看当前数据库的所有序列。Sequence就像表和视图一样,拥有自己的结构,只不过他的结构是固定的。
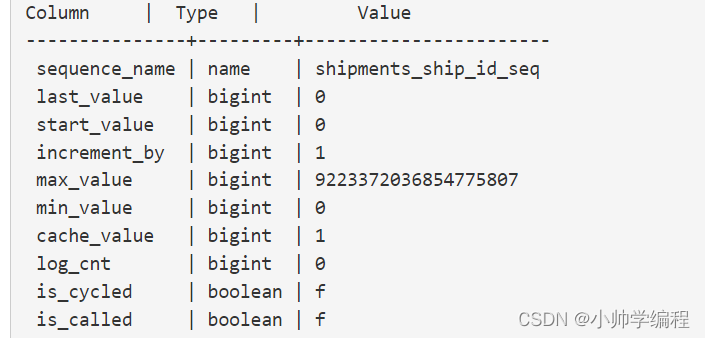
可以使用select语句查询当前序列的信息。
SELECT last_value, increment_by FROM shipments_ship_id_seq;
last_value | increment_by
------------+--------------
0 | 1
36.4使用序列
序列是通过函数来操作的。
- nextval(‘sequence_name’):将当前值设置为递增后的值,并返回
nextval()函数要求一个序列名(必须有单引号包围)为第一个参数,需要注意的是,当你第一次调用nextval()将会返回序列的初始值,即START;因为他没有调用递增的方法。
- currval(‘sequence_name’):返回当前值
- setval('sequence_name’,n,b=true):设置当前值;b默认为true,下一次调用nextval()是,直接返回n,如果设置false,则返回n+increment;
36.5删除序列
语法:
DROP SEQUENCE [seq1,seq2....]
来删除一个或者多个序列,命令中的seq_name是序列名,不需要被引号包围,如果是多个序列,可以使用逗号隔开。
37.常用符号
-- 强制转换符号
::
38.postgresql中的类if-else语句
38.1语法
CASE WHEN 条件
THEN
符合条件的值
ELSE
不符合条件的值
END CASE
38.2如果想要设置别名,需要将语句改成子查询
SELECT (
CASE WHEN 条件
THEN
符合条件的值
ELSE
不符合条件的值
END CASE
) AS 别名
39常用操作
39.1docker进入postgresql
docker exec -it 容器名 /bin/bash; #进入docker
su postgres; #切换为postgres用户
psql -U 数据库名称; #进入数据库
39.2修改已挂载视图表字段的属性
- 创建函数
create table if not exists deps_saved_ddl
(
deps_id serial primary key,
deps_view_schema name,
deps_view_name name,
deps_ddl_to_run text
);
create or replace function deps_save_and_drop_dependencies(p_view_schema name, p_view_name name) returns void as
$$
declare
v_curr record;
begin
for v_curr in
(
select obj_schema, obj_name, obj_type from
(
with recursive recursive_deps(obj_schema, obj_name, obj_type, depth) as
(
select p_view_schema, p_view_name, null::char, 0
union
select dep_schema::name, dep_name::name, dep_type::char, recursive_deps.depth + 1 from
(
select ref_nsp.nspname ref_schema, ref_cl.relname ref_name,
rwr_cl.relkind dep_type,
rwr_nsp.nspname dep_schema,
rwr_cl.relname dep_name
from pg_depend dep
join pg_class ref_cl on dep.refobjid = ref_cl.oid
join pg_namespace ref_nsp on ref_cl.relnamespace = ref_nsp.oid
join pg_rewrite rwr on dep.objid = rwr.oid
join pg_class rwr_cl on rwr.ev_class = rwr_cl.oid
join pg_namespace rwr_nsp on rwr_cl.relnamespace = rwr_nsp.oid
where dep.deptype = 'n'
and dep.classid = 'pg_rewrite'::regclass
) deps
join recursive_deps on deps.ref_schema = recursive_deps.obj_schema and deps.ref_name = recursive_deps.obj_name
where (deps.ref_schema != deps.dep_schema or deps.ref_name != deps.dep_name)
)
select obj_schema, obj_name, obj_type, depth
from recursive_deps
where depth > 0
) t
group by obj_schema, obj_name, obj_type
order by max(depth) desc
) loop
insert into deps_saved_ddl(deps_view_schema, deps_view_name, deps_ddl_to_run)
select distinct p_view_schema, p_view_name, indexdef
from pg_indexes
where schemaname = v_curr.obj_schema
and tablename = v_curr.obj_name;
insert into deps_saved_ddl(deps_view_schema, deps_view_name, deps_ddl_to_run)
select distinct tablename, rulename, definition
from pg_rules
where schemaname = v_curr.obj_schema
and tablename = v_curr.obj_name;
insert into deps_saved_ddl(deps_view_schema, deps_view_name, deps_ddl_to_run)
select p_view_schema, p_view_name, 'COMMENT ON ' ||
case
when c.relkind = 'v' then 'VIEW'
when c.relkind = 'm' then 'MATERIALIZED VIEW'
else ''
end
|| ' ' || n.nspname || '.' || c.relname || ' IS ''' || replace(d.description, '''', '''''') || ''';'
from pg_class c
join pg_namespace n on n.oid = c.relnamespace
join pg_description d on d.objoid = c.oid and d.objsubid = 0
where n.nspname = v_curr.obj_schema and c.relname = v_curr.obj_name and d.description is not null;
insert into deps_saved_ddl(deps_view_schema, deps_view_name, deps_ddl_to_run)
select p_view_schema, p_view_name, 'COMMENT ON COLUMN ' || n.nspname || '.' || c.relname || '.' || a.attname || ' IS ''' || replace(d.description, '''', '''''') || ''';'
from pg_class c
join pg_attribute a on c.oid = a.attrelid
join pg_namespace n on n.oid = c.relnamespace
join pg_description d on d.objoid = c.oid and d.objsubid = a.attnum
where n.nspname = v_curr.obj_schema and c.relname = v_curr.obj_name and d.description is not null;
insert into deps_saved_ddl(deps_view_schema, deps_view_name, deps_ddl_to_run)
select p_view_schema, p_view_name, 'GRANT ' || privilege_type || ' ON ' || table_schema || '.' || quote_ident(table_name) || ' TO ' || grantee
from information_schema.role_table_grants
where table_schema = v_curr.obj_schema and table_name = v_curr.obj_name;
if v_curr.obj_type = 'v' then
insert into deps_saved_ddl(deps_view_schema, deps_view_name, deps_ddl_to_run)
select p_view_schema, p_view_name, 'CREATE VIEW ' || v_curr.obj_schema || '.' || quote_ident(v_curr.obj_name) || ' AS ' || view_definition
from information_schema.views
where table_schema = v_curr.obj_schema and table_name = v_curr.obj_name;
elsif v_curr.obj_type = 'm' then
insert into deps_saved_ddl(deps_view_schema, deps_view_name, deps_ddl_to_run)
select p_view_schema, p_view_name, 'CREATE MATERIALIZED VIEW ' || v_curr.obj_schema || '.' || quote_ident(v_curr.obj_name) || ' AS ' || definition
from pg_matviews
where schemaname = v_curr.obj_schema and matviewname = v_curr.obj_name;
end if;
execute 'DROP ' ||
case
when v_curr.obj_type = 'v' then 'VIEW'
when v_curr.obj_type = 'm' then 'MATERIALIZED VIEW'
end
|| ' ' || v_curr.obj_schema || '.' || quote_ident(v_curr.obj_name);
end loop;
end;
$$
LANGUAGE plpgsql;
create or replace function deps_restore_dependencies(p_view_schema name, p_view_name name) returns void as
$$
declare
v_curr record;
begin
for v_curr in
(
select deps_ddl_to_run
from deps_saved_ddl
where deps_view_schema = p_view_schema and deps_view_name = p_view_name
order by deps_id desc
) loop
execute v_curr.deps_ddl_to_run;
end loop;
delete from deps_saved_ddl
where deps_view_schema = p_view_schema and deps_view_name = p_view_name;
end;
$$
LANGUAGE plpgsql;
- 执行修改sql
select deps_save_and_drop_dependencies('模式名', '表名');
alter table 表名 alter 字段名 type 字段大小;
select deps_restore_dependencies('模式名', '表名');
- 例子
SELECT deps_save_and_drop_dependencies ( 'public', 'object_instance' );
ALTER TABLE object_instance ALTER instance_number TYPE VARCHAR ( 255 );
SELECT deps_restore_dependencies ( 'public', 'object_instance' );
39.3.docker中的postgresql,超级管理员密码忘记了
- 更改连接方式:在pg_hba.conf中修改如下设置,由md5改为trust
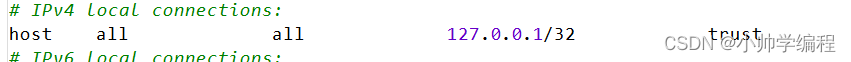
- 查看超级管理员账户名称相同的数据库是否存在,如果不存在,创建一个与超级管理员名称相同的数据库
- 执行shell
docker exec -it plm-postgresql /bin/bash #进入docker
su postgres #使用postgres用户
psql -U 超级管理员用户名 #进入超级管理员对应的数据
alter user 超级管理员用户名 with password 'XXXXXXX' #修改密码
39.4.docker中的postgresql短期回滚数据(恢复误删除命令,需要保证wal文件完整)
docker exec -it plm-postgresql /bin/bash #进入docker
su postgres #使用postgres用户
select pg_current_wal_lsn(),pg_walfile_name(pg_current_wal_lsn()),pg_walfile_name_offset(pg_current_wal_lsn()); # 查看当前事务号
pg_waldump 000000010000001600000049 00000001000000160000004D -r transaction | grep 2023-07-28 | head -n 100 #查询你需要的事务号
pg_ctl stop -D /var/lib/postgresql/data #关闭postgres,Docker不行,需要删除data下的postmaster.pid文件
pg_resetwal -x 41574998 -f -D /var/lib/postgresql/data #回滚事务
39.5清空数据库
//删除public模式以及模式里面所有的对象
DROP SCHEMA public CASCADE;
//创建public模式
CREATE SCHEMA public;

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)