分布式数据库——TiDB的介绍和基本原理
1、TiDB 介绍1.1 TiDB 介绍1.1.1 TiDB 是什么?TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景(on-line transaction processing,联机事务处理)还适合 OLAP 场景(On-Line Analytical
1、TiDB 介绍
1.1 TiDB 介绍
1.1.1 TiDB 是什么?
TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景(on-line transaction processing,联机事务处理)还适合 OLAP 场景(On-Line Analytical Processing,联机分析处理)的混合数据库。
1.1.2 TiDB 是基于 MySQL 开发的吗?
不是,虽然 TiDB 支持 MySQL 语法和协议,但是 TiDB 是由 PingCAP 团队完全自主开发的产品。
1.1.3 TiDB、TiKV、Placement Driver (PD) 主要作用?
- TiDB 是 Server 计算层,主要负责 SQL 的解析、制定查询计划、生成执行器。
- TiKV 是分布式 Key-Value 存储引擎,用来存储真正的数据,简而言之,TiKV 是 TiDB 的存储引擎。
- PD 是 TiDB 集群的管理组件,负责存储 TiKV 的元数据,同时也负责分配时间戳以及对 TiKV 做负载均衡调度。
1.1.4 TiDB 易用性如何?
TiDB 使用起来很简单,可以将 TiDB 集群当成 MySQL 来用,你可以将 TiDB 用在任何以 MySQL 作为后台存储服务的应用中,并且基本上不需要修改应用代码,同时你可以用大部分流行的 MySQL 管理工具来管理 TiDB。
1.1.5 TiDB 和 MySQL 兼容性如何?
TiDB 目前还不支持触发器、存储过程、自定义函数、外键,除此之外,TiDB 支持绝大部分 MySQL 5.7 的语法。
1.1.6 TiDB 支持分布式事务吗?
支持。无论是一个地方的几个节点,还是跨多个数据中心的多个节点,TiDB 均支持 ACID 分布式事务。
TiDB 事务模型灵感源自 Google Percolator 模型,主体是一个两阶段提交协议,并进行了一些实用的优化。该模型依赖于一个时间戳分配器,为每个事务分配单调递增的时间戳,这样就检测到事务冲突。在 TiDB 集群中,PD 承担时间戳分配器的角色。
1.1.7 TiDB 支持哪些编程语言?
只要支持 MySQL Client/Driver 的编程语言,都可以直接使用 TiDB。
1.1.8 TiDB 是否支持其他存储引擎?
是的,除了 TiKV 之外,TiDB 还支持一些流行的单机存储引擎,比如 GolevelDB、RocksDB、BoltDB 等。如果一个存储引擎是支持事务的 KV 引擎,并且能提供一个满足 TiDB 接口要求的 Client,即可接入 TiDB。
1.1.9 TiDB 用户名长度限制?
在 TiDB 中用户名最长为 32 字符。
1.1.10 TiDB 是否支持 分布式事务XA?
虽然 TiDB 的 JDBC 驱动用的就是 MySQL JDBC(Connector / J),但是当使用 Atomikos 的时候,数据源要配置成类似这样的配置:type="com.mysql.jdbc.jdbc2.optional.MysqlXADataSource"。MySQL JDBC XADataSource 连接 TiDB 的模式目前是不支持的。MySQL JDBC 中配置好的 XADataSource 模式,只对 MySQL 数据库起作用(DML 去修改 redo 等)。
Atomikos 配好两个数据源后,JDBC 驱动都要设置成 XA 模式,然后 Atomikos 在操作 TM 和 RM(DB)的时候,会通过数据源的配置,发起带有 XA 指令到 JDBC 层,JDBC 层 XA 模式启用的情况下,会对 InnoDB(如果是 MySQL 的话)下发操作一连串 XA 逻辑的动作,包括 DML 去变更 redo log 等,就是两阶段递交的那些操作。TiDB 目前的引擎版本中,没有对上层应用层 JTA / XA 的支持,不解析这些 Atomikos 发过来的 XA 类型的操作。
MySQL 是单机数据库,只能通过 XA 来满足跨数据库事务,而 TiDB 本身就通过 Google 的 Percolator 事务模型支持分布式事务,性能稳定性比 XA 要高出很多,所以不会也不需要支持 XA。
2、TiDB安装部署
CLUSTER START SUCCESSFULLY, Enjoy it ^-^
To connect TiDB: mysql --host 127.0.0.1 --port 4000 -u root -p (no password)
To view the dashboard: http://127.0.0.1:2379/dashboard
To view the Prometheus: http://127.0.0.1:9090
To view the Grafana: http://127.0.0.1:3000
使用 TiUP cluster 在单机上模拟生产环境部署步骤
- 适用场景:希望用单台 Linux 服务器,体验 TiDB 最小的完整拓扑的集群,并模拟生产的部署步骤。
本节介绍如何参照 TiUP 最小拓扑的一个 YAML 文件部署 TiDB 集群。
准备环境
准备一台部署主机,确保其软件满足需求:
- 推荐安装 CentOS 7.3 及以上版本
- Linux 操作系统开放外网访问,用于下载 TiDB 及相关软件安装包
最小规模的 TiDB 集群拓扑:
| 实例 | 个数 | IP | 配置 |
| TiKV | 3 | 10.0.1.1 | 避免端口和目录冲突 |
| TiDB | 1 | 10.0.1.1 | 默认端口 |
| PD | 1 | 10.0.1.1 | 默认端口 |
| TiFlash | 1 | 10.0.1.1 | 默认端口 |
| Monitor | 1 | 10.0.1.1 | 默认端口 |
部署主机软件和环境要求:
- 部署需要使用部署主机的 root 用户及密码
- 部署主机关闭防火墙或者开放 TiDB 集群的节点间所需端口
- 目前 TiUP 仅支持在 x86_64 (AMD64) 架构上部署 TiDB 集群(TiUP 将在 4.0 GA 时支持在 ARM 架构上部署)
实施部署
注意:
你可以使用 Linux 系统的任一普通用户或 root 用户登录主机,以下步骤以 root 用户为例。
- 下载并安装 TiUP:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
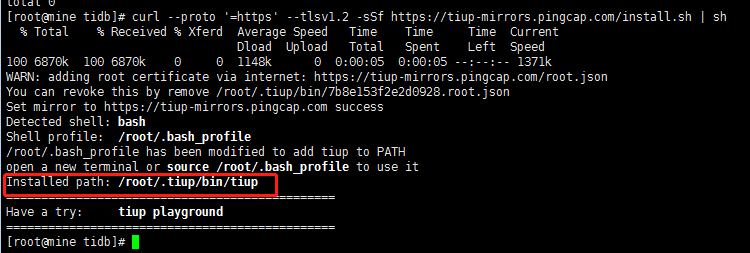
[root@mine tidb]# curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 6870k 100 6870k 0 0 1148k 0 0:00:05 0:00:05 --:--:-- 1371k
WARN: adding root certificate via internet: https://tiup-mirrors.pingcap.com/root.json
You can revoke this by remove /root/.tiup/bin/7b8e153f2e2d0928.root.json
Set mirror to https://tiup-mirrors.pingcap.com success
Detected shell: bash
Shell profile: /root/.bash_profile
/root/.bash_profile has been modified to add tiup to PATH
open a new terminal or source /root/.bash_profile to use it --- 需要执行source /root/.bash_profile启用配置
Installed path: /root/.tiup/bin/tiup
===============================================
Have a try: tiup playground
===============================================
2、安装 TiUP 的 cluster 组件:
tiup cluster
[root@mine bin]# tiup cluster
The component `cluster` version is not installed; downloading from repository.
download https://tiup-mirrors.pingcap.com/cluster-v1.4.0-linux-amd64.tar.gz 8.05 MiB / 8.05 MiB 100.00% 1.97 MiB p/s
Starting component `cluster`: /root/.tiup/components/cluster/v1.4.0/tiup-cluster
Deploy a TiDB cluster for production
Usage: ---
tiup cluster [command]
Available Commands:
check Perform preflight checks for the cluster. --- 对集群预检
deploy Deploy a cluster for production 为生产环境部署集群
start Start a TiDB cluster --- 启动TiDB集群
stop Stop a TiDB cluster --- 停止TiDB集群
restart Restart a TiDB cluster --- 重新启动TiDB集群
scale-in Scale in a TiDB cluster --- 缩容TiDB集群
scale-out Scale out a TiDB cluster --- 扩容TiDB集群
destroy Destroy a specified cluster --- 销毁指定的集群
clean (EXPERIMENTAL) Cleanup a specified cluster --- (实验性)清除指定的集群
upgrade Upgrade a specified TiDB cluster --- 升级指定的TiDB集群
display Display information of a TiDB cluster --- 显示TiDB集群信息
prune Destroy and remove instances that is in tombstone state --- 删除并删除处于tombstone状态的实例
list List all clusters --- 列出所有集群
audit Show audit log of cluster operation --- Show集群操作审计日志
import Import an exist TiDB cluster from TiDB-Ansible --- 从TiDB- ansible中导入一个已经存在的TiDB集群
edit-config Edit TiDB cluster config. --- 编辑TiDB集群配置。
Will use editor from environment variable `EDITOR`, default use vi --- 将会使用环境变量' editor '中的编辑器,默认使用vi
reload Reload a TiDB cluster’s config and restart if needed --- 重新加载TiDB集群的配置,并在需要时重新启动
patch Replace the remote package with a specified package and restart the service --- 将远程包替换为指定的远程包,重新启动服务
rename Rename the cluster --- 重命名集群
enable Enable a TiDB cluster automatically at boot --- 允许在启动时自动启用TiDB集群
disable Disable automatic enabling of TiDB clusters at boot --- 不允许在启动时自动启用TiDB集群
replay Replay previous operation and skip successed steps --- 重放之前的操作并跳过成功的步骤
template Print topology template --- 打印拓扑图模板
help Help about any command --- 帮助
Flags:
-h, --help help for tiup
--ssh string (EXPERIMENTAL) The executor type: 'builtin', 'system', 'none'.
--ssh-timeout uint Timeout in seconds to connect host via SSH, ignored for operations that don't need an SSH connection. (default 5)
-v, --version version for tiup
--wait-timeout uint Timeout in seconds to wait for an operation to complete, ignored for operations that don't fit. (default 120)
-y, --yes Skip all confirmations and assumes 'yes'
Use "tiup cluster help [command]" for more information about a command.
[root@mine bin]#
- 如果机器已经安装 TiUP cluster,需要更新软件版本:
tiup update --self && tiup update cluster
- 由于模拟多机部署,需要通过
root用户调大 sshd 服务的连接数限制:
-
- 修改
/etc/ssh/sshd_config将MaxSessions调至 20。 - 重启 sshd 服务:
- 修改
service sshd restart
- 创建并启动集群按下面的配置模板,编辑配置文件,命名为
topo.yaml,其中:
-
user: "tidb":表示通过tidb系统用户(部署会自动创建)来做集群的内部管理,默认使用 22 端口通过 ssh 登录目标机器replication.enable-placement-rules:设置这个 PD 参数来确保 TiFlash 正常运行host:设置为本部署主机的 IP
- 配置模板如下:
# # Global variables are applied to all deployments and used as the default value of
# #全局变量应用于所有部署,并作为默认值
# # the deployments if a specific deployment value is missing.
# #如果缺少特定的部署值,则部署。
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
# # Monitored variables are applied to all the machines. --- 被监视的变量应用于所有机器。
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
server_configs:
tidb:
log.slow-threshold: 300
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
replication.enable-placement-rules: true
replication.location-labels: ["host"]
tiflash:
logger.level: "info"
pd_servers:
- host: 10.0.1.1
tidb_servers:
- host: 10.0.1.1
tikv_servers:
- host: 10.0.1.1
port: 20160
status_port: 20180
config:
server.labels: { host: "logic-host-1" }
- host: 10.0.1.1
port: 20161
status_port: 20181
config:
server.labels: { host: "logic-host-2" }
- host: 10.0.1.1
port: 20162
status_port: 20182
config:
server.labels: { host: "logic-host-3" }
tiflash_servers:
- host: 10.0.1.1
monitoring_servers:
- host: 10.0.1.1
grafana_servers:
- host: 10.0.1.1
- 执行集群部署命令:
可以使用在 deploy 语句最后添加 --ssh-time-out 参数将超时时间延长
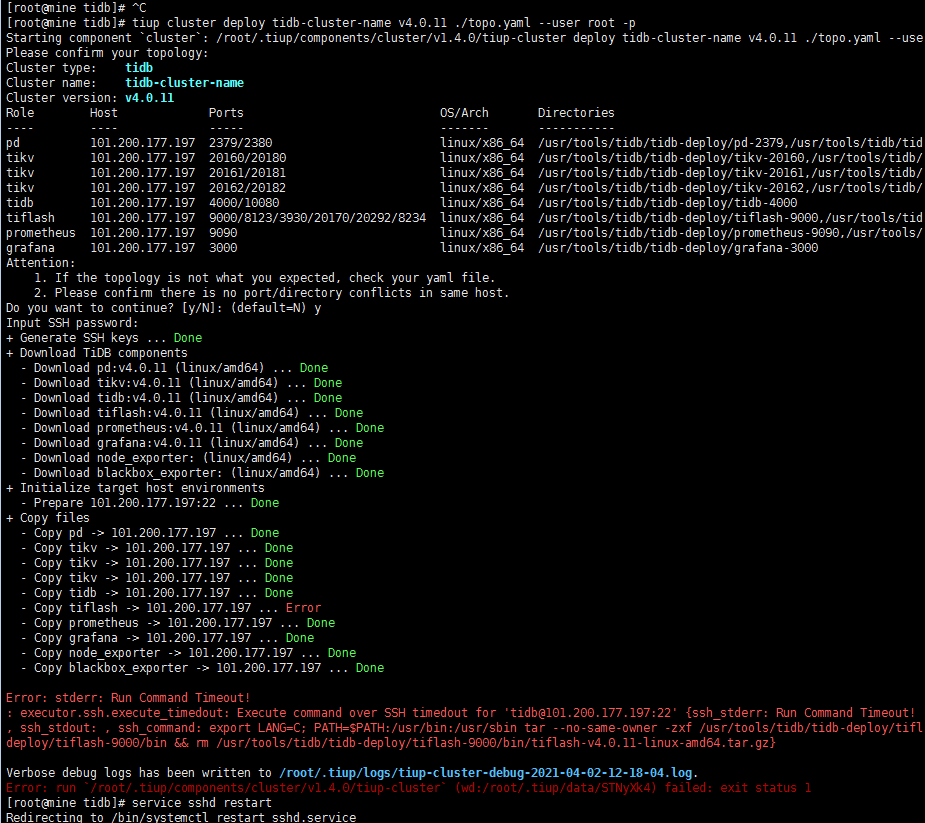
tiup cluster deploy <cluster-name> <tidb-version> ./topo.yaml --user root -p
-
- 参数
<cluster-name>表示设置集群名称 - 参数
<tidb-version>表示设置集群版本,可以通过tiup list tidb命令来查看当前支持部署的 TiDB 版本
- 参数
- 按照引导,输入”y”及 root 密码,来完成部署:
Do you want to continue? [y/N]: y Input SSH password:
- 启动集群:
本例设集群名称为tidb-cluster-name
tiup cluster start <cluster-name>
- 访问集群:
-
- 安装 MySQL 客户端。如果已安装 MySQL 客户端则可跳过这一步骤。
yum -y install mysql
-
- 访问 TiDB 数据库,密码为空:
mysql -h 10.0.1.1 -P 4000 -u root
-
- 访问 TiDB 的 Grafana 监控:
通过 http://{grafana-ip}:3000 访问集群 Grafana 监控页面,默认用户名和密码均为 admin。 - 访问 TiDB 的 Dashboard:
通过 http://{pd-ip}:2379/dashboard 访问集群 TiDB Dashboard 监控页面,默认用户名为 root,密码为空。 - 执行以下命令确认当前已经部署的集群列表:
- 访问 TiDB 的 Grafana 监控:
tiup cluster list
-
- 执行以下命令查看集群的拓扑结构和状态:
tiup cluster display <cluster-name>
3、TiDB实践案例
3.1、TiDB-SQL操作
3.1.1、创建、查看、删除数据库
TiDB 语境中的 Database 或者说数据库,可以认为是表和索引等对象的集合。
使用 SHOW DATABASES 语句查看系统中数据库列表:
SHOW DATABASES;
使用名为 mysql 的数据库:
USE mysql;
使用 SHOW TABLES 语句查看数据库中的所有表。例如:
SHOW TABLES FROM mysql;
使用 CREATE DATABASE 语句创建数据库。语法如下:
CREATE DATABASE study;
例如,要创建一个名为 samp_db 的数据库,可使用以下语句:
CREATE DATABASE IF NOT EXISTS study;
添加 IF NOT EXISTS 可防止发生错误。
使用 DROP DATABASE 语句删除数据库。例如:
DROP DATABASE study;
3.1.2、创建、查看、删除表
使用 CREATE TABLE 语句创建表。语法如下:
CREATE TABLE table_name column_name data_type constraint;
例如,要创建一个名为 person 的表,包括编号、名字、生日等字段,可使用以下语句:
CREATE TABLE `user` ( id INT, `name` VARCHAR(20), role VARCHAR(20), age INT, PRIMARY KEY (id), KEY idxAge(age) );
使用 SHOW CREATE 语句查看建表语句,即 DDL。例如:
SHOW CREATE TABLE user;
使用 DROP TABLE 语句删除表。例如:
DROP TABLE user;
3.1.3、增删改查数据
使用 INSERT 语句向表内插入表记录。例如:
1, TiDB, SQL Layer, 10
2, TiKV, KV Engine, 20
3, PD, Manager, 30
INSERT INTO user VALUES(1,'TiDB','SQL Layer', 10);
使用 INSERT 语句向表内插入包含部分字段数据的表记录。例如:
INSERT INTO user(id,name) VALUES('2','TiKV');
使用 UPDATE 语句向表内修改表记录的部分字段数据。例如:
UPDATE user SET role='KV Engine' WHERE id=2;
使用 DELETE 语句向表内删除部分表记录。例如:
DELETE FROM user WHERE id=2;
注意:UPDATE 和 DELETE 操作如果不带 WHERE 过滤条件是对全表进行操作。
DQL (Data Query Language)数据查询语言是从一个表或多个表中检索出想要的数据行,通常是业务开发的核心内容。
使用 SELECT 语句检索表内数据。例如:
SELECT * FROM user;
3.2、TiDB-读取历史数据
3.2.1、功能说明
TiDB 实现了通过标准 SQL 接口读取历史数据功能,无需特殊的 client 或者 driver。当数据被更新、删除后,依然可以通过 SQL 接口将更新/删除前的数据读取出来。
另外即使在更新数据之后,表结构发生了变化,TiDB 依旧能用旧的表结构将数据读取出来。
3.2.2、操作流程
为支持读取历史版本数据, TiDB 引入了一个新的系统变量 tidb_snapshot:
- 这个变量的作用域为
SESSION。 - 你可以通过标准的
SET语句修改这个变量的值。 - 这个变量的数据类型为文本类型,能够存储 TSO 和日期时间。TSO 是从 PD 端获取的全局授时的时间戳,日期时间的格式为:“2016-10-08 16:45:26.999”,一般来说可以只写到秒,比如”2016-10-08 16:45:26”。
- 当这个变量被设置时,TiDB 会按照设置的时间戳建立 Snapshot(没有开销,只是创建数据结构),随后所有的
SELECT操作都会从这个 Snapshot 上读取数据。
3.2.3、历史数据保留策略
TiDB 使用 MVCC 管理版本,当更新/删除数据时,不会做真正的数据删除,只会添加一个新版本数据,所以可以保留历史数据。历史数据不会全部保留,超过一定时间的历史数据会被彻底删除,以减小空间占用以及避免历史版本过多引入的性能开销。
TiDB 使用周期性运行的 GC(Garbage Collection,垃圾回收)来进行清理,关于 GC 的详细介绍参见 TiDB 垃圾回收 (GC)。
这里需要重点关注的是:
- 使用系统变量
tidb_gc_life_time可以配置历史版本的保留时间(默认值是10m0s)。 - 使用 SQL 语句
SELECT * FROM mysql.tidb WHERE variable_name = 'tikv_gc_safe_point'可以查询当前的 safePoint,即当前可以读的最旧的快照。在每次 GC 开始运行时,safePoint 将自动更新。
3.2.4、示例
- 初始化阶段,创建一个表,并插入几行数据:
- 查看表中的数据:
select * from user;
+----+------+-----------+------+ | id | name | role | age | +----+------+-----------+------+ | 1 | TiDB | SQL Layer | 10 | +----+------+-----------+------+
3.查看当前时间:
select now();
+---------------------+ | now() | +---------------------+ | 2016-10-08 16:45:26 | +---------------------+
4.更新某一行数据:
update user set age=20 where id=1;
5.确认数据已经被更新:
select * from user;
+----+------+-----------+------+ | id | name | role | age | +----+------+-----------+------+ | 1 | TiDB | SQL Layer | 20 | +----+------+-----------+------+
6.设置一个特殊的环境变量,这个是一个 session scope 的变量,其意义为读取这个时间之前的最新的一个版本。
set @@tidb_snapshot="2016-10-08 16:45:26";
注意:
- 这里的时间设置的是 update 语句之前的那个时间。
- 在
tidb_snapshot前须使用@@而非@,因为@@表示系统变量,@表示用户变量。
7.这里读取到的内容即为 update 之前的内容,也就是历史版本:
select * from user;
+----+------+-----------+------+ | id | name | role | age | +----+------+-----------+------+ | 1 | TiDB | SQL Layer | 10 | +----+------+-----------+------+
- 清空这个变量后,即可读取最新版本数据:
set @@tidb_snapshot=""; select * from user;
+----+------+-----------+------+ | id | name | role | age | +----+------+-----------+------+ | 1 | TiDB | SQL Layer | 20 | +----+------+-----------+------+
注意:
在
tidb_snapshot前须使用@@而非@,因为@@表示系统变量,@表示用户变量。
4、TiDB 整体架构
MySQL架构:
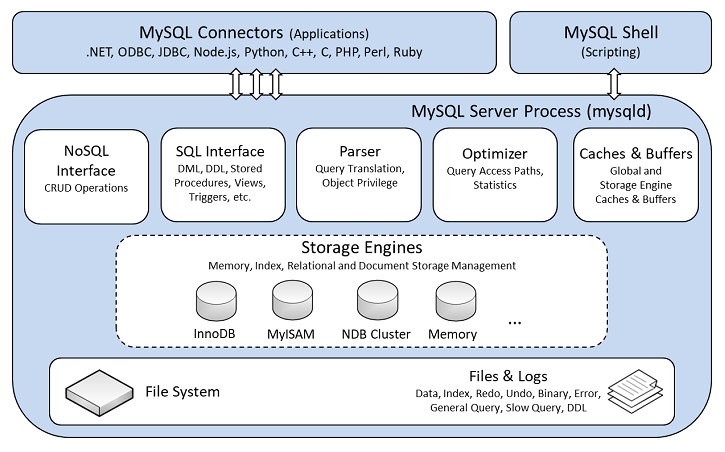
与传统的单机数据库相比,TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
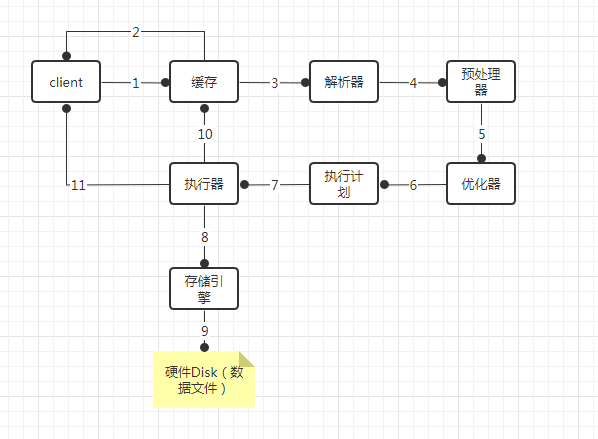
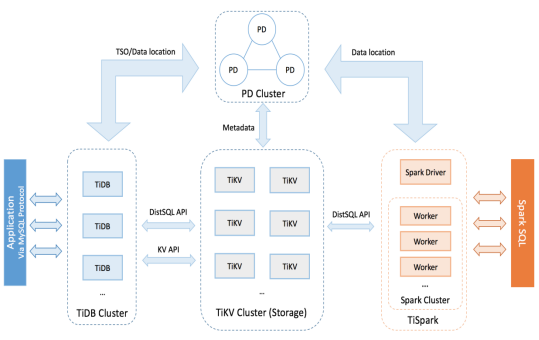
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
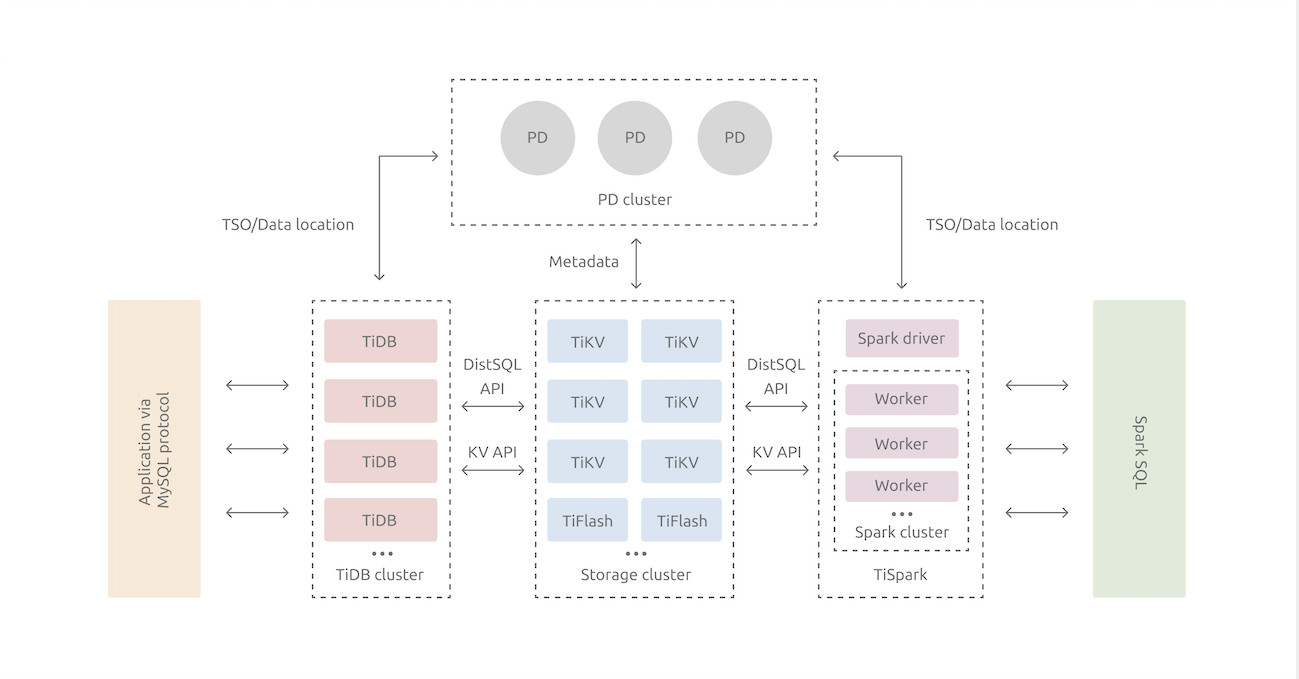
- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点
-
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
5、TiDB技术原理
5.1、TiDB 技术内幕-存储
5.1.1、Key-Value(数据结构)
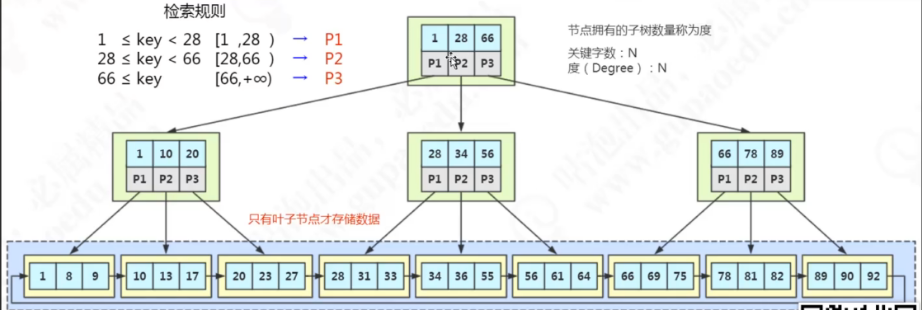
MySQL InnoDB使用文件的数据结构是B+Tree。TiKV使用的数据结构是Key-Value键值对模型,k、v均是原始Byte数组,其中k按照Byte数组的二进制顺序排序。好处是时间复杂度O(1)。
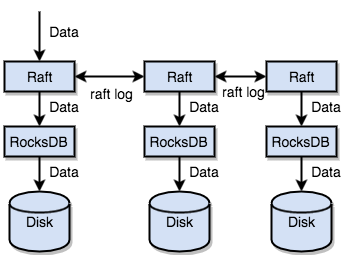
5.1.2、RocksDB(刷脏)
InnoDB的保存单位是page(16kb),如果直接对磁盘进行操作需要大量的IO,影响效率,所以在InnoDB要修改或新增一条数据是,从磁盘加载数据到内存中时,会将数据记录在buffer pool中,先修改内存中的数据page,如果内存中的page与磁盘的page不一样,则内存中的page叫dirty page(脏页,产生本质是刷脏时间差和事务没有提交)。一旦后台线程开始空闲,就将脏页数据刷到磁盘文件中,又叫刷脏。
TiKV也没直接向磁盘写数据,而是将数据保存在中间件RocksDB中,RocksDB将数据的修改增量的保存在内存中,当达到指定大小时批量把数据flush到磁盘,类似InnoDB的刷脏。
5.1.3、Raft(副本)
1、MySQL的主从同步原理:
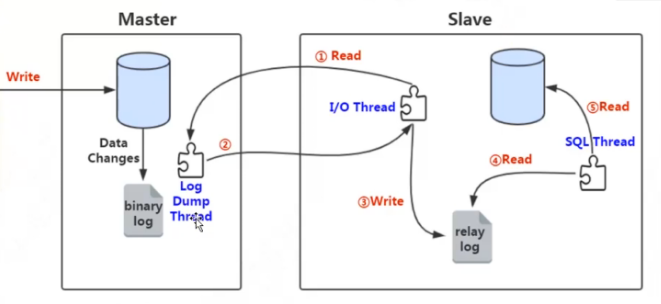
1、从节点的I/O Thread请求读取主节点的binlog
2、主节点的Log Dump Thread把数据发给从节点
3、从节点解析后写入中继日志
4、SQL Thread读取中继日志的数据
5、将解析后的SQL在从节点的DB中重放(重新执行)一遍
2、Raft在TiKV的使用
一致性算法:
- Leader选举
- 成员变更
- 日志复制
如何使用:
Leader中每个数据变更都会保存到Raft日志中,然后将日志在Follower重放,即实现副本的同步。
5.1.4、Region(存储单位)
目的是将数据分散在多个TiKV节点,实现水平扩展。有两种方式,Hash和范围。Hash:数据进来经过Hash得到节点编号。
范围:将一连串的Key做为一个Region(类比InnoDB的page,page:16KB,Region:96MB),Region的范围是[StartKey, EndKey)
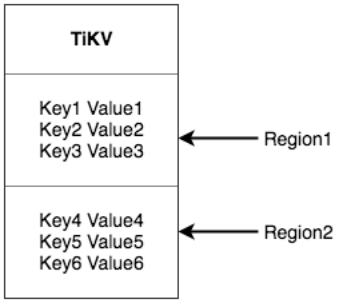
在TiKV中
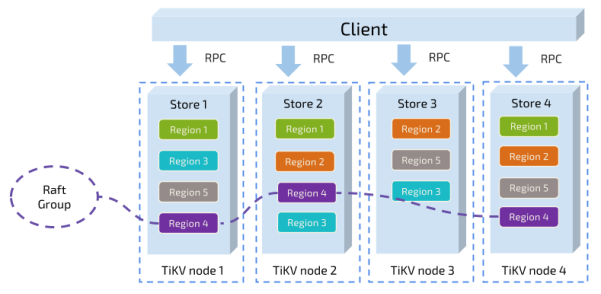
以Region为单位,将数据分散在集群的所有节点上,并保证每个节点上的Region数量差不多。数据按照Key切分很多Region,并且每个Region只会保存在一个节点。这样可以实现水平扩容(增加节点后,经过运算将其他节点的Region调度到新节点上)和负载均衡(Region均匀分布,不会集中在某一个节点)。
以Region为单位做Raft的复制和成员管理。TiKV以Region为单位做数据备份,副本叫Replica,副本之间通过Raft保持一致。Region和它的Replica也会分布在不同的节点,构成Raft Group。选举一个作为Leader,其它的是Follower。所有的读写都在Leader进行,再由Raft复制给Follower。
5.1.5、MVCC
Multi-Version Concurrency Control,即多版本并发控制
两个 Client 同时去修改一个 Key 的 Value,如果没有 MVCC,就需要对数据上锁,在分布式场景下,可能会带来性能以及死锁问题。 TiKV 的 MVCC 实现是通过在 Key 后面添加 Version 来实现。
举例:
没有 MVCC 之前,可以把 TiKV 看做这样的:
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
……
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
……
KeyN-Version2 -> Value
KeyN-Version1 -> Value
……
注意,对于同一个 Key 的多个版本,我们把版本号较大的放在前面,版本号小的放在后面(回忆一下 Key-Value 一节我们介绍过的 Key 是有序的排列),这样当用户通过一个 Key + Version 来获取 Value 的时候,可以将 Key 和 Version 构造出 MVCC 的 Key,也就是 Key-Version。然后可以直接 Seek(Key-Version),定位到第一个大于等于这个 Key-Version 的位置。
5.1.6、事务
TiKV 的事务采用的是 Percolator 模型,并且做了大量的优化。TiKV 的事务采用乐观锁,事务的执行过程中,不会检测写写冲突,只有在提交过程中,才会做冲突检测,冲突的双方中比较早完成提交的会写入成功,另一方会尝试重新执行整个事务。
5.2、TiDB 技术内幕-计算
5.2.1、关系模型到Key-Value
如何在KV结构上保存Table;如何在KV结构上运行SQL语句。
定义表:
CREATE TABLE `user` ( id INT, `name` VARCHAR(20), role VARCHAR(20), age INT, PRIMARY KEY (id), KEY idxAge(age) );
MySQL存储引擎的存储结构和KV的存储结构本质上是不同的。因此要达到KV结构能用sql映射的目的。
Table需要存储的数据包括:
- 表的元数据
- Row-行数据
- 索引数据
Row有行存和列存两种方式。TiDB的首要目标是OLTP(on-line transaction processing——联机事务处理)。这类业务需要支持快速的读取、保存、修改、删除一行数据,所以选择行存。
Index,TiDB需要支持Primary Index和Secondary Index。
查询。1、直接命中,通过Primary Key或者Unique Key的等值条件查询(select ... where id = 1),需要通过索引快速定位到某一行数据。
2、范围查询(select ... where age > 30 and age < 35),需要通过idxAge索引查询age在(30,35)的数据。此时索引可为Unique Key或非Unique Key。
TiDB数据库无损支持sql需要满足操作的场景:
Insert语句:要将Row写入KV,并保存索引数据。
Update语句:要将Row更新到KV,并更新索引数据。
Delete语句:要删除Row,并删除索引。
Select语句:快速读取一行数据(每个Row需要一个隐式或显示的ID)
读取多行数据(select from user)
索引读取数据,包括直接命中和范围查询
TiDB数据库的基本条件:全局有序的分布式Key-Value引擎。全局有序很重要,key和value都是bit数组,且按照bit顺序排列。快速获取一行数据时,通过构造出一个或多个key,定位到一行数据。扫描全表时,通过映射一个Key的范围,从Region的StartKey扫描到EndKey获取全表数据。操作Index数据是类似的思路。
TiDB数据库为每一个表、索引、行分配一个int64类型的TableID、IndexID、RowID(如果表有整数型的Primary Key,那么会用Primary Key作为RowID,类似MySQL的聚簇索引)。TableID在整个集群唯一,IndexID、RowID在表内唯一。
Row数据按如下规则编码成键值对(tablePrefix、recordPrefix是特定的字符串常量,用于在KV空间内区分其他数据):
Key:tablePrefix{TableID}_recordPrefix{RowID}
Value:[col1, col2, col3, col4]
Index数据按如下规则编码成键值对:
Key:tablePrefix{TableID}_indexPrefix{IndexID}_indexColumnsValue
Value:RowID
注意:对于Unique Index可完全按照上述编码生成Key。而非Unique Index的TableID、IndexID、indexColumnsValue都一样,所以有如下编码:
Key:tablePrefix{TableID}_indexPrefix{IndexID}_indexColumnsValue_RowID
Value:null
假设:tablePrefix = t;recordPrefix = r;IndexID = i
补充:上述编码方案中Table内的所有Row、同一种Index的数据都有自己相同的前缀,前文说过“Key全局有序很重要,因为key按照bit排列”。因此在TiKV中同一类的Key在Region内是顺序排列在一起的。
Key编码举例:
有如下三行数据,且TableID=10,age的IndexID=1:
1, TiDB, SQL Layer, 10
2, TiKV, KV Engine, 20
3, PD, Manager, 30
1、Row的键值对(有整数型的Primary Key,那么会用Primary Key作为RowID):
t_10_r_1 : [TiDB, SQL Layer, 10]
t_10_r_2 : [TiKV, KV Engine, 20]
t_10_r_3 : [PD, Manager, 30]
2、Index的键值对:
唯一索引:
t_10_i_4_10 : 1
t_10_i_4_10 : 2
t_10_i_4_10 : 3
非唯一索引:
t_10_i_4_10_1 : null
t_10_i_4_20_2 : null
t_10_i_4_30_3 : null
5.2.2、元数据管理
Database、Table的元数据(其各项属性),表名和TableID、列名和RowID、索引名和IndexID等。
SELECT VERSION( ); -- 服务器版本信息 SELECT DATABASE( ); -- 当前数据库名 (或者返回空) SELECT USER( ); -- 当前用户名 SHOW STATUS; -- 服务器状态 SHOW VARIABLES; -- 服务器配置变量
TiKV中,每个Database、Table都被分配了一个ID,在使用时加上m_前缀
5.2.3、SQL on KV 架构
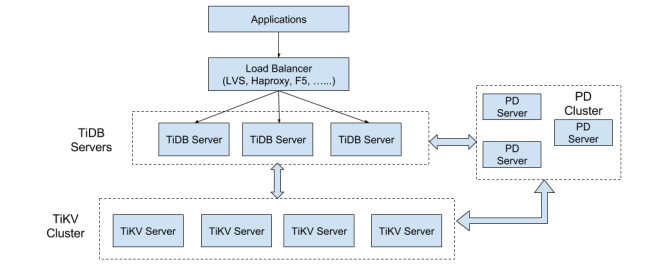
TiKV Cluster是KV引擎存储数据。TiDB Servers都是不保存数据的、节点完全对等的、无状态的节点,用作处理用户的请求,执行sql的运算逻辑(功能可类比MySQL的server层)。
5.2.4、SQL 运算
例如,
SELECT COUNT(*) FROM `user` WHERE `name` = 'TiDB'
首先需要读取表中的所有数据,过滤出name是TiDB的行,然后返回。使用KV操作的流程是:
- 构造出Key范围:已知表的RowID在[0, MaxInt64)的范围,根据编码规则构造Key的[StartKey, EndKey)
- 扫描Key范围,读取TiKV的数据
- 过滤数据,遍历每一行,计算表达式 `name` = 'TiDB',如果为真则向上返回此行,反之丢弃
- 计算Count
此方案虽然是可行的,但是由于每一行都要读取(意味着RPC调用),如果扫描的范围很大,则开销很大;并不是所有的行都有用,如果不满足条件,可以不读取;符合要求的整行的值没有必要全部取出,实际上只需要几个信息。
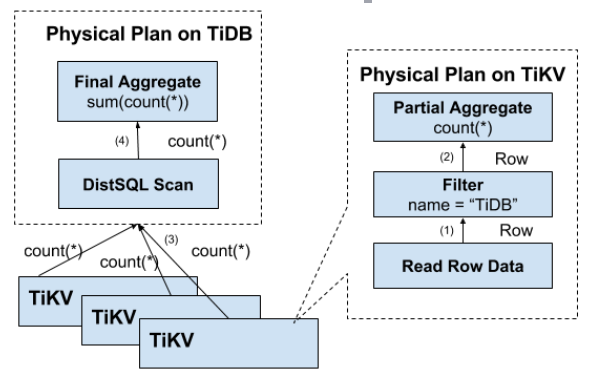
5.2.5、分布式 SQL 运算
如上节所述,上面的方案会导致大量的RPC调用,所以需要让计算尽量靠近存储节点。将过滤条件下推到存储节点计算,返回有效的行,避免无用的网络传输。同样适用于聚合函数、GroupBy。
5.2.6、SQL 层架构
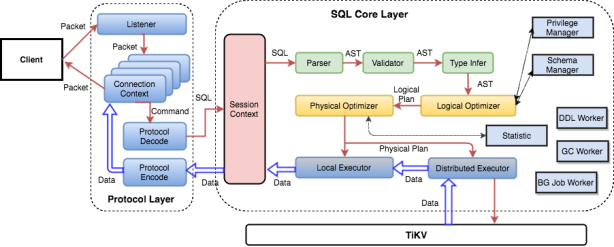
客户端的SQL请求通过Load Balance发送到TiDB-server。
TiDB-server进过解析、校验、结果类型推导、优化、制定查询计划、向TiKV执行查询计划、结果处理,并返回客户端。
5.3、TiDB 技术内幕-调度
5.3.1、为什么要进行调度
TiKV集群是TiDB数据库的分布式kv存储引擎,数据以Region为单位进行复制和管理的。每个Region会有多个Replica(副本)。这些Replica会分布在不同的TiKV节点上。其中Leader负责读/写,Follower负责同步Leader发来的raft log。
问题:
- 如何保证同一个Region的Replica分布在不同的节点上?换言之,如果一台机器上启动多个TiKV实例,会有什么问题?
- TiKV集群为了容灾而跨机房部署的时候,如何保证一个机房掉线,不会丢失Raft Group的多个Replica?
- 添加一个节点进入TiKV集群之后,如何将集群中其他节点的数据搬过来?
- 当一个节点掉线时,会出现什么问题?整个集群需要做什么事情?如果节点只是短暂掉线(服务重启),那么如何处理?如果节点是长时间掉线(磁盘故障,数据全部丢失),需要如何处理?
- 假设集群需要每个Raft Group有N个副本,那么对于单个Raft Group来说,Replica数量可能会<N(假如节点掉线,失去副本),也可能会>N(例如掉线的节点又恢复正常)。那么如何调节Replica的个数?
- 读/写都是通过TiKV的Leader进行,如果Leader只集中在少量节点上,会对集群有什么影响?
- 并不是所有的Region都被频繁访问,可能访问的热点只集中在少数几个Region,这个时候需要我们做什么?
- 集群在做负载均衡时,往往需要搬迁数据,这种数据的迁移会不会占用大量的网络带宽、磁盘IO以及CPU?进而影响在线服务?
上述问题中,有的只需要考虑单个Raft Group内部的情况,比如根据副本数据是否足够来决定是否需要添加副本。但是这个副本添加在哪里,是需要考虑全局的信息。整个系统也是在动态变化,Region的分裂、节点的加入、节点失效、访问热点变化等情况会不断发生。整个调度系统也需要在动态中不断向最优状态前进。如果没有一个掌握全局信息、可以对全局进行调度、并且支持配置的组件,就很难满足这些需求。因此需要一个中心节点,来对系统的整体状况进行把控和调整,所以有了PD这个模块。
5.3.2、调度的需求
5.3.2.1、作为一个分布式高可用存储系统,必须满足的需求。包括四种:
- 副本的数量不能多也不能少
- 副本需要分布在不同的机器上
- 新加节点后,可以将其他节点上的副本迁移过来
- 节点下线后,需要将该节点的数据迁移走
5.3.2.2、作为一个良好的分布式系统,需要优化的地方,包括:
- 维持整个集群的Leader分布均匀
- 维持每个节点的储存容量均匀
- 维持访问热点分布均匀
- 控制Balance的速度,避免影响在线服务
- 管理节点状态,包括手动上线/下线节点,以及自动下线失效节点
第一类的目的是,整个系统将具备多副本容错、动态扩容/缩容、容忍节点掉线以及自动错误恢复的功能。
第二类的目的是,实现负载的尽量均衡。
为了满足这些需求,需要收集足够的信息,比如每个节点的状态、每个Raft Group的信息、业务访问操作的统计等;
其次需要设置一些策略,PD根据这些信息以及调度的策略,制定出尽量满足上述需求的调度计划;最后需要一些基本操作,完成调度计划。
5.3.3、调度的基本操作
- 增加一个Replica
- 删除一个Replica
- 将Leader角色在一个Raft Group的不同Replica之间切换。Raft协议的AddReplica、RemoveReplica、TransferLeader命令。
5.3.4、信息搜集
调度依赖于整个集群信息的搜集,即需要知道每个TiKV节点的状态,以及每个Region的状态。TiKV集群会向PD汇报两类信息:
每个TiKV节点会定期向PD汇报节点的整体信息
TiKV节点(Store)向PD发送心跳。PD通过心跳检查每个Store是否存活,以及是否有新增的Store;心跳包中也会携带这个Store的状态信息,主要包括:
- 总磁盘容量
- 可用的磁盘容量
- 承载的Region数量
- 数据写入速度
- 发送、接收的Snapshot数量(Replica之间可能会通过Snapshot同步数据)
- 是否过载
- 标签信息(标签是具备层级关系的一系列Tag)
每个Raft Group的Leader会定期向PD汇报信息
Leader向PD发送心跳。汇报这个Region的状态,主要包括:
- Leader的位置
- Followers的位置
- 掉线的Replica的个数
- 数据写、读取的速度
PD不断的通过这两类心跳消息收集整个集群的信息,再以这些信息作为决策的依据。除此之外,PD还可以通过管理模块的接口接收额外额外的信息,用来做更准群的决策。比如当某个Store的心跳包中断的时候,PD并不能判断这个节点是临时失效还是永久失效。默认是等待30分钟,如果还没有心跳,则认为Store已下线,在决定要将这个Store上面的Region调度走。如果是运维人员主动将某台机器下线,可以通过PD的管理接口通知PD该Store不可用。PD就可以马上判断要将这个Store上面的Region都调度走。
5.3.5、调度的策略
PD收集了这些信息后,还需要一些策略来制定具体的调度计划。
1、一个Region的Replica数量正确
当PD通过某个Region Leader的心跳包发现这个Region的Replica数量不满住要求时,需要通过Add/Remove Replica操作调整Replica数量。出现这种情况的原因可能是:
- 某个节点掉线,上面的数据全部丢失,导致一些Region的Replica数量不足
- 某个掉线的节点又恢复服务,自动接入集群,这样之前已经补过Replica的Region的当前Replica的数量过多,因此需要删除某个Replica
- 管理员调整了副本策略,修改了max-replicas的数量
2、一个Raft Group中的多个Replica不在同一位置
此处是同一位置,而不是同一节点。一般情况下,PD只会保证多个Replica不落在同一TiKV节点上,以避免单个节点失效导致多个Replica丢失。在实际部署中,还可能出现下面这些需求:
- 多个节点部署在同一物理机上
- TiKV节点分布在多个机架上,希望单个机架掉电时,也能保证系统的可用性
- TiKV节点分布在多个IDC(互联网数据中心——Internet Data Center)中,希望单个机房掉电时,也能保证系统的可用性
这些需求本质上都是某一个节点具备共同的位置属性,构成一个最小的容错单元。我们希望这个单元内部不会存在一个Region的多个Replica。这个时候,可以给节点配置labels,并且通过在PD上配置location-labels来指明哪些label是位置标识,需要在Replica分配的时候尽量保证不会有一个Region的多个Replica所在的节点不会有相同的位置标识。
3、副本在Store之间的分布均匀
每个副本中存储的数据容量上限是固定的(96MB),所以需要维持每个节点上面的副本数量均衡,使得总体的负载更均衡。
4、Leader数量在Store之间均匀分配
Raft协议是通过Leader进行读写,所以计算的负载主要在Leader上面,PD会尽量将Leader在节点间分散开。
5、访问热点数量在Store之间均匀分配
每个TiKV节点以及Region Leader在上报信息时携带了当前访问负载的信息,比如Key的读取、写入速度。PD会检测出访问热点,且将其在节点之间分散开。
6、各个Store的存储空间占用大致相等
每个Store启动时都会指定一个Capacity(容量)参数,表明这个Store的存储空间上限。PD调度时,会考虑节点的存储空间剩余量。
7、控制调度速度,避免影响在线服务
调度操作需要耗费CPU、内存、磁盘IO以及网络带宽,因此要避免对线上服务造成太大影响。PD会对当前正在进行的操作数量进行控制。默认的速度控制比较保守,如需加快调度,可通过pd-ctl手动加快调度速度。
8、支持手动下线节点
当通过pd-ctl手动下线节点后,PD会在一定的速率控制下,将节点上的数据调度走,当调度完成后,就会将这个节点置为下线状态。
5.3.6、调度的实现
PD通过Store和Leader的心跳包不断收集信息,获得整个集群的详细数据,并且根据这些信息和调度策略生成调度操作序列。每次收到Region Leader的心跳包时,PD都会检查是否有对这个Region待进行的操作,通过回复心跳包消息,将需要进行的操作返回给Region Leader。并且再后面的心跳包中监测执行结果。(此处的操作只是给Region Leader的建议,并不保证一定会执行,由Region Leader根据当前自身状态决定是否执行、什么时候执行)
补充:
HTAP(Hybrid Transaction and Analytical Process,混合事务和分析处理)
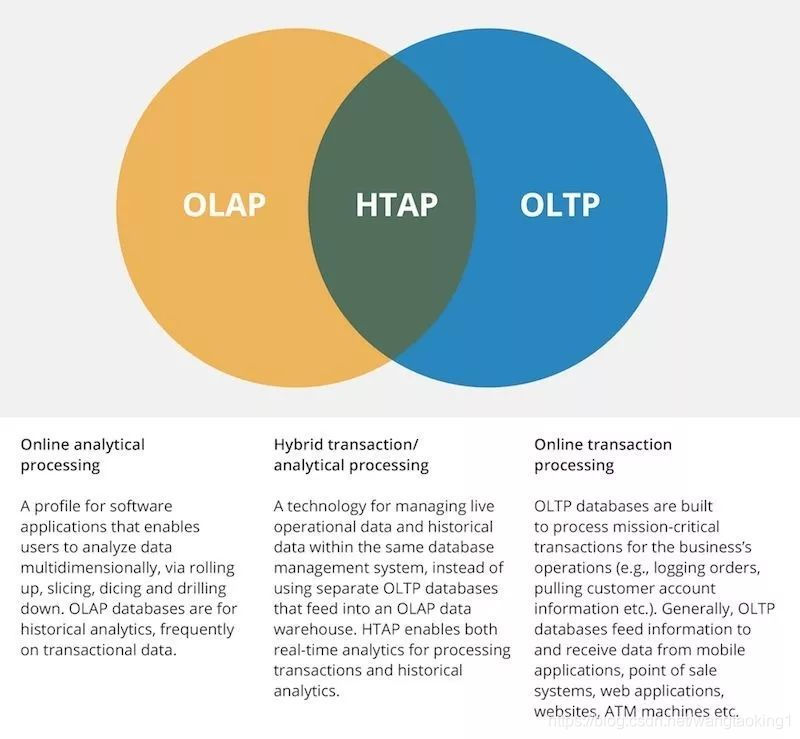
来源:https://www.yuque.com/docs/share/57a34c81-4192-4bce-b790-13b6499f470f?#

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)