Mybatis之分组查询
在应用开发中,分组统计是非常经典的需求,在springboot+mybatis+mysql中实现分组统计。学生信息统计场景,学生包含姓名、性别、年龄、地址等属性。按性别分组统计数量按地址分组统计数量按地址、性别分组统计数量1、mysql中sql语句DROP TABLE IF EXISTS `student`;CREATE TABLE `student`(`id` int(11) NOT NULL
·
在应用开发中,分组统计是非常经典的需求,在springboot+mybatis+mysql中实现分组统计。
学生信息统计场景,学生包含姓名、性别、年龄、地址等属性。
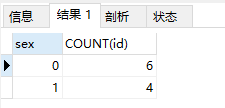
- 按性别分组统计数量
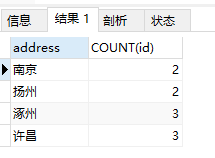
- 按地址分组统计数量
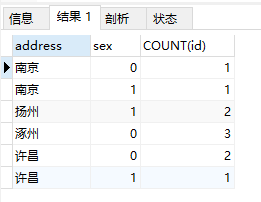
- 按地址、性别分组统计数量
1、mysql中sql语句
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`sex` tinyint(2) NULL DEFAULT NULL,
`age` tinyint(2) NULL DEFAULT NULL,
`address` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `nameKey`(`name`) USING BTREE COMMENT '唯一索引'
) ENGINE = InnoDB AUTO_INCREMENT = 22 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '曹操', 0, 20, '许昌');
INSERT INTO `student` VALUES (2, '刘备', 0, 20, '涿州');
INSERT INTO `student` VALUES (3, '孙权', 0, 20, '南京');
INSERT INTO `student` VALUES (4, '貂蝉', 1, 10, '许昌');
INSERT INTO `student` VALUES (5, '大乔', 1, 20, '扬州');
INSERT INTO `student` VALUES (6, '小乔', 1, 10, '扬州');
INSERT INTO `student` VALUES (7, '孙尚香', 1, 20, '南京');
INSERT INTO `student` VALUES (8, '关羽', 0, 10, '涿州');
INSERT INTO `student` VALUES (9, '张飞', 0, 10, '涿州');
INSERT INTO `student` VALUES (10, '曹仁', 0, 10, '许昌');
MySQL中,使用GROUP BY按某个字段,或者多个字段中的值,进行分组,字段中值相同的为一组。
SELECT 字段名1,字段名2,……
FROM 表名
WHERE BY 字段名1,字段名2,……[HAVING 条件表达式];
其中指定的字段名1、字段名2,是对查询结果分组的依据,HAVING关键字,指定条件表达式,对分组后的内容进行过滤,GROUP BY,一般和聚合函数一起使用。
SELECT sex,COUNT(id) FROM student GROUP BY sex
SELECT address,COUNT(id) FROM student GROUP BY address
SELECT address,sex,COUNT(id) FROM student GROUP BY address,sex
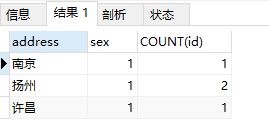
SELECT address,sex,COUNT(id) FROM student GROUP BY address,sex HAVING sex=1
2、mybatis
单个分组
<select id="addressStudent" resultType="java.util.HashMap">
SELECT address,COUNT(DISTINCT id) as 'count' FROM student GROUP BY address
</select>
List<HashMap<String,Long>> addressStudent();
两个分组
<resultMap id="addressSex" type="java.util.HashMap">
<result column="address" property="address" jdbcType="VARCHAR" />
<result column="sex" property="sex" jdbcType="VARCHAR" />
<result column="count" property="count" jdbcType="VARCHAR"/>
</resultMap>
<select id="addressSexStudent" resultMap="addressSex">
SELECT address,sex,COUNT(DISTINCT id) as 'count' FROM student2 GROUP BY address,sex
</select>
List<HashMap<String,Long>> addressSexStudent();
结果
[
{"address":"南京","sex":0,"count":1},
{"address":"南京","sex":1,"count":1},
{"address":"扬州","sex":1,"count":2},
{"address":"涿州","sex":0,"count":3},
{"address":"许昌","sex":0,"count":2},
{"address":"许昌","sex":1,"count":1}
]
<resultMap id="addressSex2" type="java.util.HashMap">
<result column="address" property="address" jdbcType="VARCHAR" />
<collection property="sexStudent" ofType="java.util.HashMap" javaType="java.util.ArrayList">
<result column="sex" property="sex" jdbcType="VARCHAR" />
<result column="count" property="count" jdbcType="VARCHAR"/>
</collection>
</resultMap>
<select id="addressSexStudent2" resultMap="addressSex2">
SELECT address,sex,COUNT(DISTINCT id) as 'count' FROM student2 GROUP BY address,sex
</select>
List<HashMap<Object,Object>> addressSexStudent2();
结果
[
{
"address":"南京",
"sexStudent":[
{"sex":0,"count":1},
{"sex":1,"count":1}
]
},
{
"address":"扬州",
"sexStudent":[
{"sex":1,"count":2}
]
},
{
"address":"涿州",
"sexStudent":[
{"sex":0,"count":3}
]
},
{
"address":"许昌",
"sexStudent":[
{"sex":0,"count":2},
{"sex":1,"count":1}
]
}
]
其中type是用java.util.Map类,这样才不会返回多余的字段null值,不要写表的实体类。collection集合里的ofType也是同理,要用java.util.Map类,javaType要用java.util.ArrayList类,这样才能返回一个List列表。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)