数据库面试题:Redis如何保证数据一致性
Redis缓存如何保证数据一致性一. Redis概述redis是一个内存数据库, 因此数据基本上都存在于内存当中但是Redis会定时以追加或者快照的方式刷新到硬盘中.由于redis是一个内存数据库, 所以读取写入的速度是非常快的, 所以经常被用来做数据, 页面等的缓存。二.为什么会出现数据不一致2.1 一般的读写模式当Redis作为缓存的时候,经典的读写模式如下:(1)读的时候,先读缓存,缓存没有
·
Redis缓存如何保证数据一致性
一. Redis概述
- redis是一个内存数据库, 因此数据基本上都存在于内存当中
- 但是Redis会定时以追加或者快照的方式刷新到硬盘中.
- 由于redis是一个内存数据库, 所以读取写入的速度是非常快的, 所以经常被用来做数据, 页面等的缓存。
二.为什么会出现数据不一致
2.1 一般的读写模式
当Redis作为缓存的时候,经典的读写模式如下:
(1)读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应
(2)更新的时候,先删除缓存,然后再更新数据库
问题:
- 上述的读写模式看似没有任何问题,但是在高并发及多线程的情况下会出现数据不一致的情况。
2.2 单库产生数据不一致
发生条件:
- 同一时间发生了并发读写请求,比如A(写) ,B (读),2个请求
发生过程:
- A发送更新请求,先删除缓存,删除缓存后由于某种原因被阻塞
- B发送读请求,此时缓存无效,直接读取数据库,再将数据库的数据更新到缓存中
- 之后A再写数据库
- 这时候缓存和数据库就产生了数据不一致的问题,缓存中的数据就是脏数据
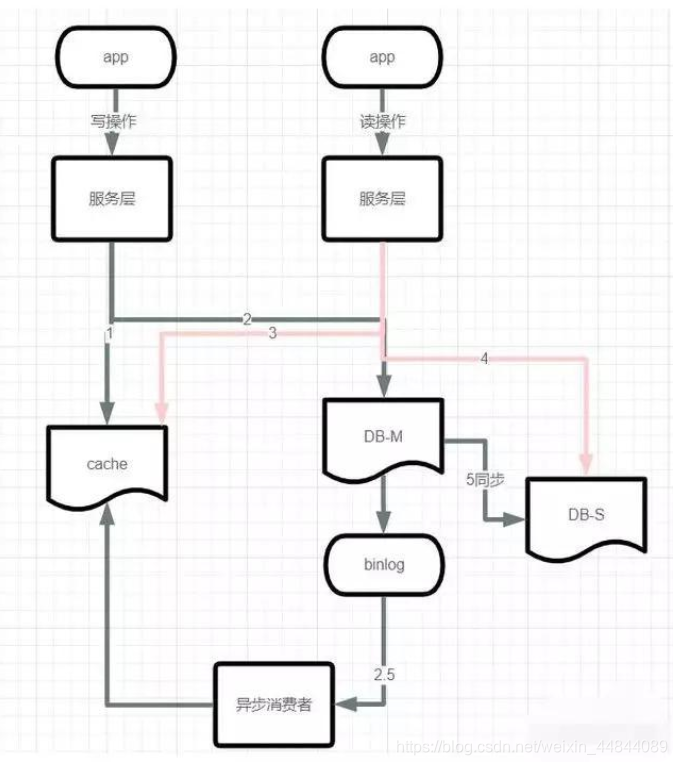
2.2 主从同步,读写分离产生数据不一致
主从同步,读写分离:实际上就是读数据库都是读从库,写数据库是写主库,然后进行主从同步。
过程:
- A请求发送一个写操作到服务端,第一步就会淘汰掉cache
- A请求写主数据库,往主数据库写了最新的数据。
- B请求发送一个读操作,读cache,因为cache淘汰,所以为空
- B请求继续读DB,这个时候读的是从库,此时主从同步还没同步成功。读出脏数据,然后脏数据写入cache
- 最后数据库主从同步完成。这时候还是会发生数据不一致的情况。
三. 数据不一致解决方案
3.1 缓存双淘汰法
- 在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。这样最差的情况是在超时时间内存在不一致,当然这种情况极其少见,可能的原因就是服务宕机。此种情况可以满足绝大多数需求。 当然这种策略要考虑redis和数据库主从同步的耗时,所以在第二次删除前最好休眠一定时间,比如500毫秒,这样毫无疑问又增加了写请求的耗时。
3.2 异步淘汰缓存
- 增加一个线下的读取binlog异步淘汰缓存模块,在读取binlog总的数据,然后进行异步淘汰。
过程:
MySQL binlog增量发布订阅消耗+消息队列+增量数据更新到redis
1)读取请求转到Redis:热数据基本上在Redis
2)写入请求转到MySQL:增加删除和 修改MySQL
3)更新Redis数据:MySQ数据操作binlog更新为Redis

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)