Hive常用命令
Hive常用命令
基础命令
show databases; # 查看某个数据库
use 数据库; # 进入某个数据库
show tables; # 展示所有表
desc 表名; # 显示表结构
show partitions 表名; # 显示表名的分区
show create table_name; # 显示创建表的结构
建表语句
内部表
use xxdb; create table xxx;
#创建一个表,结构与其他一样
create table xxx like xxx;
#外部表
use xxdb; create external table xxx;
#分区表
use xxdb; create external table xxx (l int) partitoned by (d string)
#内外部表转化
alter table table_name set TBLPROPROTIES (‘EXTERNAL’=‘TRUE’); # 内部表转外部表
alter table table_name set TBLPROPROTIES (‘EXTERNAL’=‘FALSE’);# 外部表转内部表
#表结构修改
#重命名表
use xxxdb; alter table table_name rename to new_table_name;
#增加字段
alter table table_name add columns (newcol1 int comment ‘新增’);
#修改字段
alter table table_name change col_name new_col_name new_type;
#删除字段(COLUMNS中只放保留的字段)
alter table table_name replace columns (col1 int,col2 string,col3 string);
#删除表
use xxxdb; drop table table_name;
#删除分区
#注意:若是外部表,则还需要删除文件(hadoop fs -rm -r -f hdfspath)
alter table table_name drop if exists partitions (d=‘2016-07-01’);
#字段类型
#tinyint, smallint, int, bigint, float, decimal, boolean, string
#复合数据类型
#struct, array, map
复合数据类型
#array
create table person(name string,work_locations array)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
COLLECTION ITEMS TERMINATED BY ‘,’;
#数据
biansutao beijing,shanghai,tianjin,hangzhou
linan changchu,chengdu,wuhan
#入库数据
LOAD DATA LOCAL INPATH ‘/home/hadoop/person.txt’ OVERWRITE INTO TABLE person;
select * from person;
#biansutao [“beijing”,“shanghai”,“tianjin”,“hangzhou”]
#linan [“changchu”,“chengdu”,“wuhan”]
#map
create table score(name string, score map<string,int>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
COLLECTION ITEMS TERMINATED BY ‘,’
MAP KEYS TERMINATED BY ‘:’;
#数据
biansutao ‘数学’:80,‘语文’:89,‘英语’:95
jobs ‘语文’:60,‘数学’:80,‘英语’:99
#入库数据
LOAD DATA LOCAL INPATH ‘/home/hadoop/score.txt’ OVERWRITE INTO TABLE score;
select * from score;
#biansutao {“数学”:80,“语文”:89,“英语”:95}
#jobs {“语文”:60,“数学”:80,“英语”:99}
#struct
CREATE TABLE test(id int,course structcourse:string,score:int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
COLLECTION ITEMS TERMINATED BY ‘,’;
#数据
1 english,80
2 math,89
3 chinese,95
#入库
LOAD DATA LOCAL INPATH ‘/home/hadoop/test.txt’ OVERWRITE INTO TABLE test;
#查询
select * from test;
#1 {“course”:“english”,“score”:80}
#2 {“course”:“math”,“score”:89}
#3 {“course”:“chinese”,“score”:95}
配置优化
#开启任务并行执行
set hive.exec.parallel=true
#设置运行内存
set mapreduce.map.memory.mb=1024;
set mapreduce.reduce.memory.mb=1024;
#指定队列
set mapreduce.job.queuename=jppkg_high;
#动态分区,为了防止一个reduce处理写入一个分区导致速度严重降低,下面需设置为false
#默认为true
set hive.optimize.sort.dynamic.partition=false;
#设置变量
set hivevar:factor_timedecay=-0.3;
set hivevar:pre_month=zdt.addDay(−30).format(“yyyy−MM−dd”);
set hivevar:predate=zdt.addDay(−30).format(“yyyy−MM−dd”);
set hivevar:cur_date={zdt.format(“yyyy-MM-dd”)};
#添加第三方jar包, 添加临时函数
add jar ***.jar;
#压缩输出,ORC默认自带压缩,不需要额外指定,如果使用非ORCFile,则设置如下
hive.exec.compress.output=true
#如果一个大文件可以拆分,为防止一个Map读取过大的数据,拖慢整体流程,需设置
hive.hadoop.suports.splittable.combineinputformat
#避免因数据倾斜造成的计算效率,默认false hive.groupby.skewindata
#避免因join引起的数据倾斜 hive.optimize.skewjoin
#map中会做部分聚集操作,效率高,但需要更多内存 hive.map.aggr
– 默认打开 hive.groupby.mapaggr.checkinterval
– 在Map端进行聚合操作的条目数目
#当多个group by语句有相同的分组列,则会优化为一个MR任务。默认关闭。 hive.multigroupby.singlemr
#自动使用索引,默认不开启,需配合row group index,可以提高计算速度 hive.optimize.index.filter
常用函数
#if 函数,如果满足条件,则返回A, 否则返回B if (boolean condition, T A, T B)
#case 条件判断函数, 当a为b时则返回c;当a为d时,返回e;否则返回f case a when b then c when d then e else f end
#将字符串类型的数据读取为json类型,并得到其中的元素key的值
#第一个参数填写json对象变量,第二个参数使用{zdt.format(“yyyy-MM-dd”)};
#添加第三方jar包, 添加临时函数 add jar ***.jar;
#压缩输出,ORC默认自带压缩,不需要额外指定,如果使用非ORCFile,则设置如下 hive.exec.compress.output=true
#如果一个大文件可以拆分,为防止一个Map读取过大的数据,拖慢整体流程,需设置 hive.hadoop.suports.splittable.combineinputformat
#避免因数据倾斜造成的计算效率,默认false hive.groupby.skewindata
避免因join引起的数据倾斜 hive.optimize.skewjoin
#map中会做部分聚集操作,效率高,但需要更多内存 hive.map.aggr – 默认打开 hive.groupby.mapaggr.checkinterval
– 在Map端进行聚合操作的条目数目
#当多个group by语句有相同的分组列,则会优化为一个MR任务。默认关闭。 hive.multigroupby.singlemr
#自动使用索引,默认不开启,需配合row group index,可以提高计算速度 hive.optimize.index.filter 常用函数
#if 函数,如果满足条件,则返回A, 否则返回B if (boolean condition, T A, T B)
#case 条件判断函数, 当a为b时则返回c;当a为d时,返回e;否则返回f case a when b then c when d then e else f end
#将字符串类型的数据读取为json类型,并得到其中的元素key的值
#第一个参数填写json对象变量,第二个参数使用表示json变量标识,然后用.读取对象或数组;
get_json_object(string s, ‘.key’)
#url解析 # parse_url(‘http://facebook.com/path/p1.php?query=1’,‘HOST’)返回’facebook.com’ # parse_url(‘http://facebook.com/path/p1.php?query=1’,‘PATH’)返回’/path/p1.php’
parse_url(‘http://facebook.com/path/p1.php?query=1’,‘QUERY’)返回’query=1’, parse_url() # explode就是将hive一行中复杂的array或者map结构拆分成多行 explode(colname)
#lateral view 将一行数据adid_list拆分为多行adid后,使用lateral view使之成为一个虚表adTable,使得每行的数据adid与之前的pageid一一对应, 因此最后pageAds表结构已发生改变,增加了一列adid select pageid, adid from pageAds lateral view explode(adid_list) adTable as adid
#去除两边空格 trim()
#大小写转换 lower(), upper()
#返回列表中第一个非空元素,如果所有值都为空,则返回null coalesce(v1, v2, v3, …)
#返回当前时间 from_unixtime(unix_timestamp(), ‘yyyy-MM-dd HH:mm:ss’)
#返回第二个参数在待查找字符串中的位置(找不到返回0) instr(string str, string search_str)
#字符串连接 concat(string A, string B, string C, …)
#自定义分隔符sep的字符串连接 concat_ws(string sep, string A, string B, string C, …)
#返回字符串长度 length() # 反转字符串 reverse()
#字符串截取 substring(string A, int start, int len)
#将字符串A中的符合java正则表达式pat的部分替换为C; regexp_replace(string A, string pat, string C)
#将字符串subject按照pattern正则表达式的规则进行拆分,返回index制定的字符
0:显示与之匹配的整个字符串, 1:显示第一个括号里的, 2:显示第二个括号里的 regexp_extract(string subject, string pattern, int index)
#按照pat字符串分割str,返回分割后的字符串数组 split(string str, string pat)
类型转换 cast(expr as type)
#将字符串转为map, item_pat指定item之间的间隔符号,dict_pat指定键与值之间的间隔 str_to_map(string A, string item_pat, string dict_pat)
#提取出map的key, 返回key的array map_keys(map m)
日期函数 # 日期比较函数,返回相差天数,datediff(‘.key’)
#url解析 # parse_url(‘http://facebook.com/path/p1.php?query=1’,‘HOST’)返回’facebook.com’
#parse_url(‘http://facebook.com/path/p1.php?query=1’,‘PATH’)返回’/path/p1.php’
parse_url(‘http://facebook.com/path/p1.php?query=1’,‘QUERY’)返回’query=1’, parse_url()
#explode就是将hive一行中复杂的array或者map结构拆分成多行 explode(colname)
lateral view 将一行数据adid_list拆分为多行adid后,使用lateral view使之成为一个虚表adTable,使得每行的数据adid与之前的pageid一一对应, 因此最后pageAds表结构已发生改变,增加了一列adid select pageid, adid from pageAds lateral view explode(adid_list) adTable as adid
#去除两边空格 trim() # 大小写转换 lower(), upper()
#返回列表中第一个非空元素,如果所有值都为空,则返回null coalesce(v1, v2, v3, …) # 返回当前时间 from_unixtime(unix_timestamp(), ‘yyyy-MM-dd HH:mm:ss’)
#返回第二个参数在待查找字符串中的位置(找不到返回0) instr(string str, string search_str)
#字符串连接 concat(string A, string B, string C, …)
#自定义分隔符sep的字符串连接 concat_ws(string sep, string A, string B, string C, …)
#返回字符串长度 length()
反转字符串 reverse()
#字符串截取 substring(string A, int start, int len)
将字符串A中的符合java正则表达式pat的部分替换为C; regexp_replace(string A, string pat, string C)
将字符串subject按照pattern正则表达式的规则进行拆分,返回index制定的字符
0:显示与之匹配的整个字符串, 1:显示第一个括号里的, 2:显示第二个括号里的 regexp_extract(string subject, string pattern, int index)
#按照pat字符串分割str,返回分割后的字符串数组 split(string str, string pat)
#类型转换 cast(expr as type)
将字符串转为map, item_pat指定item之间的间隔符号,dict_pat指定键与值之间的间隔 str_to_map(string A, string item_pat, string dict_pat)
提取出map的key, 返回key的array map_keys(map m)
#日期函数
日期比较函数,返回相差天数,datediff('{cur_date},d)
datediff(date1, date2)
hive统计重复数据:
select 字段名, count(字段名) from 表名 group by 字段名 having count(字段名) > 1;
模糊查询hive中的表名(先选择库):show tables ‘kc02’;
hive查看执行计划,输出到文件:hive2 -e " select * from table " >> ‘/opt/datas/detail2222.txt’
/usr/local/hadoop-current/bin/hadoop fs -cat hdfs://wecloud-cluster/data/hive/warehouse/wedw/dw/sdyb_medical_medicine_info_ty_jc_df_tmp/* >> /tmp/medical_medicine_info_ty_jc.txt;
hive2 -e " select * from wedw_dw.sdyb_medical_medicine_info_ty_jc_df " >> ‘/opt/datas/medical_medicine_info_ty_jc.txt’ (这种数据量太大会内存溢出)
insert overwrite local directory ‘/home/pms/workspace/ouyangyewei/data/bi_lost’ row format delimited fields terminated by ‘,’ select xxxx from xxxx;
hive2 -e " select * from table " >> ‘/opt/datas/detail2222.txt’
测试环境:hdfs://wedp-cluster
使用 overwrite 时,注意hive和spark的区别
hive中,如果两个表的存储格式不一样,有的关联条件一致,但是还是查不出数据,说明有的时候不同存储格式,不能进行关联查询,建表的时间建为同一存储格式,或者转化为同一存储格式的表再进行关联查询,或者转化为能进行关联查询的格式

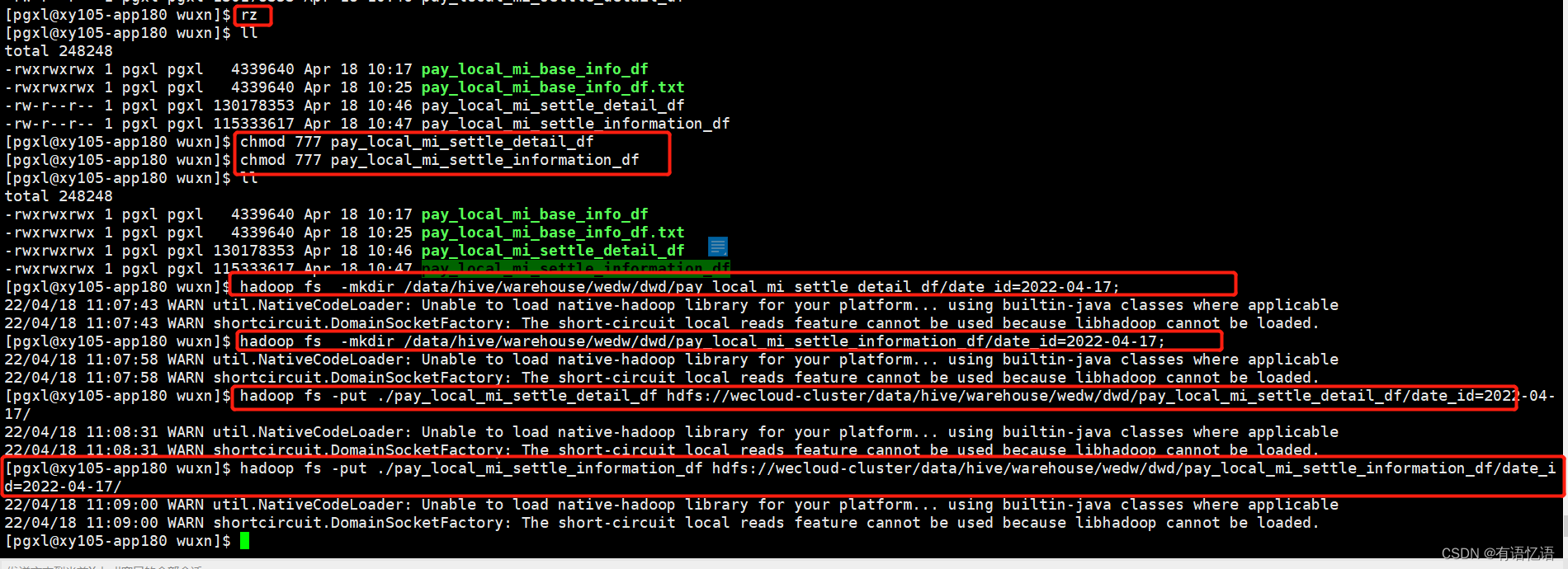
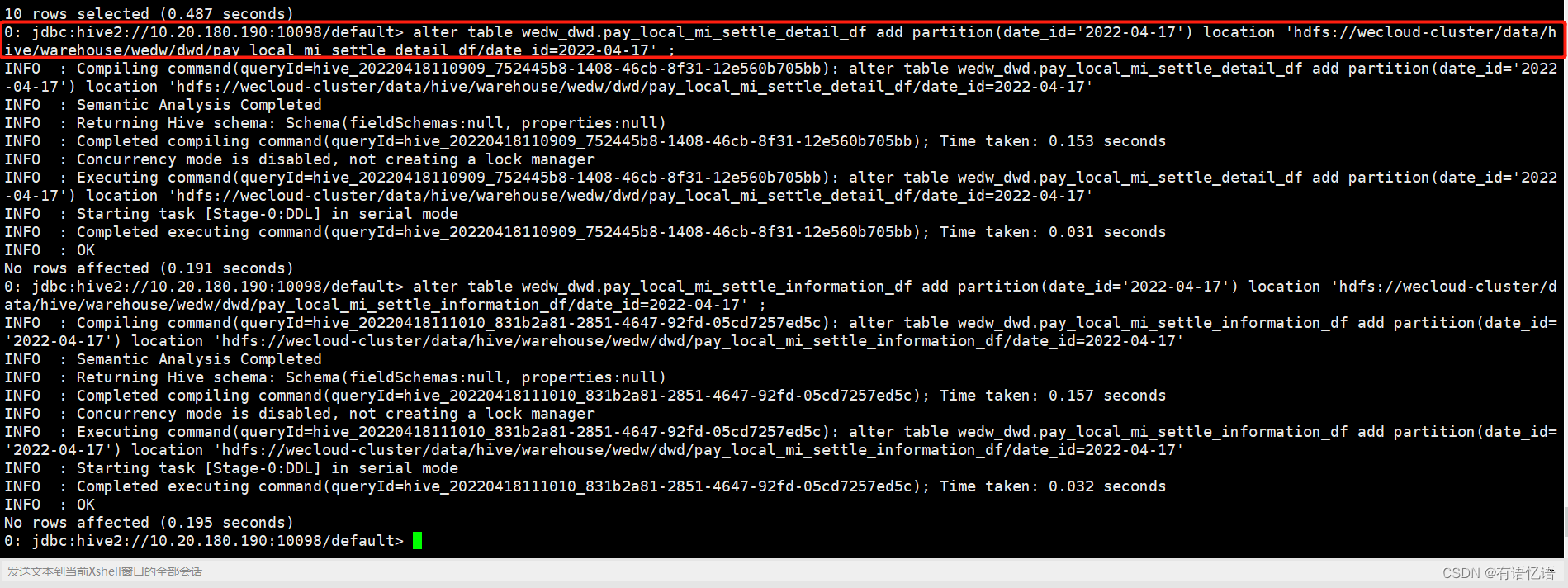
复制表:
create table if not exists wedw_aidm.tianjin_risk_all_group_last like wedw_aidm.tianjin_risk_all_group;
insert into wedw_aidm.tianjin_risk_all_group_last select * from wedw_aidm.tianjin_risk_all_group;

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)