redis使用布隆过滤器
介绍布隆过滤器以及用法,项目中如何使用,如何解决redis穿透
介绍
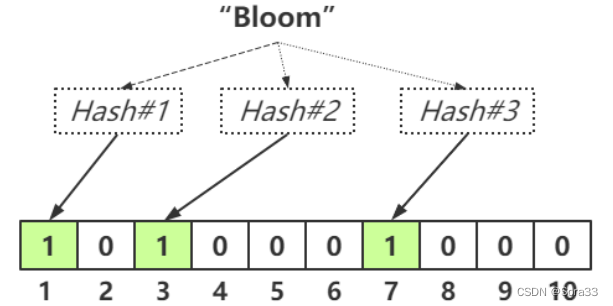
布隆过滤器采用一个很长的二进制数组,通过一系列的Hash函数来确定该数据是否存在
使用场景
- redis防止缓存击穿的解决方案
- 数据去重
- 过滤垃圾信息
简单原理
布隆过滤器本质上是一个二进制数组,元素的值不是1就是0. 当我们存一个商品id为10的商品,假设我们经过三次哈希,存的数组下标为1,3,7,就将这三个下标的元素改为1.这样每次访问redis之前,先访问布隆过滤器。查询id为10的商品的时候,经过布隆过滤器的哈希算法,获取到该商品对应的下标是1,3,7。那么,如果这三个数组的下标对应的元素都为1 则表示存在该商品,放行这次请求。如果有一个为0,则不存在该商品。
布隆过滤器判断存在不一定真的存在,但是,判断不存在则一定不存在。
针对布隆过滤器的一些误判,我们可以增加二进制数组位数或者增加Hash次数来解决。
使用布隆过滤器并测试
引入谷歌guava依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
创建一个测试类,存入100w个数据到布隆过滤器,同时用10w个不存在的数据测试误判率。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.math.BigDecimal;
@SpringBootTest
class RetailUserApplicationTests {
@Test
void contextLoads() {
this.BloomTest();
}
public void BloomTest() {
// 开始时间
long startTime = System.currentTimeMillis();
// 初始化误判个数
BigDecimal count = new BigDecimal("0");
// 相当于一个常量
BigDecimal one = new BigDecimal("1");
// 测试的10W个数据 也是常量 用于计算误判率
BigDecimal testCount = new BigDecimal("100000");
// 百分比换算,还是常量
BigDecimal mult = new BigDecimal("100");
// 第一个参数为数据类型,第二个数组长度,第三个误判率
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 1000000L, 0.01);
// 插入100w个数据
for (int i = 1; i <= 1000000; i++) {
bloomFilter.put(i);
}
// 测试10W个不存在的数据
for (int i = 2000000; i <= 2100000; i++) {
boolean mightContain = bloomFilter.mightContain(i);
if (mightContain) {
count = count.add(one);
}
}
System.out.println("总耗时" + (System.currentTimeMillis() - startTime) + "MS");
System.out.println("误判个数:" + count);
System.out.println("误判率:" + (count.divide(testCount)).multiply(mult) + "%");
}
}
误判了1004个,符合我们设置的0.01误判率。
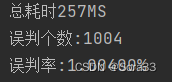
但是,误判率并不是设置的越小越好。设置的越小,进行的哈希次数就越多。接下来,我们来看下例子。比如我这里设置的0.01,就经过了7次哈希
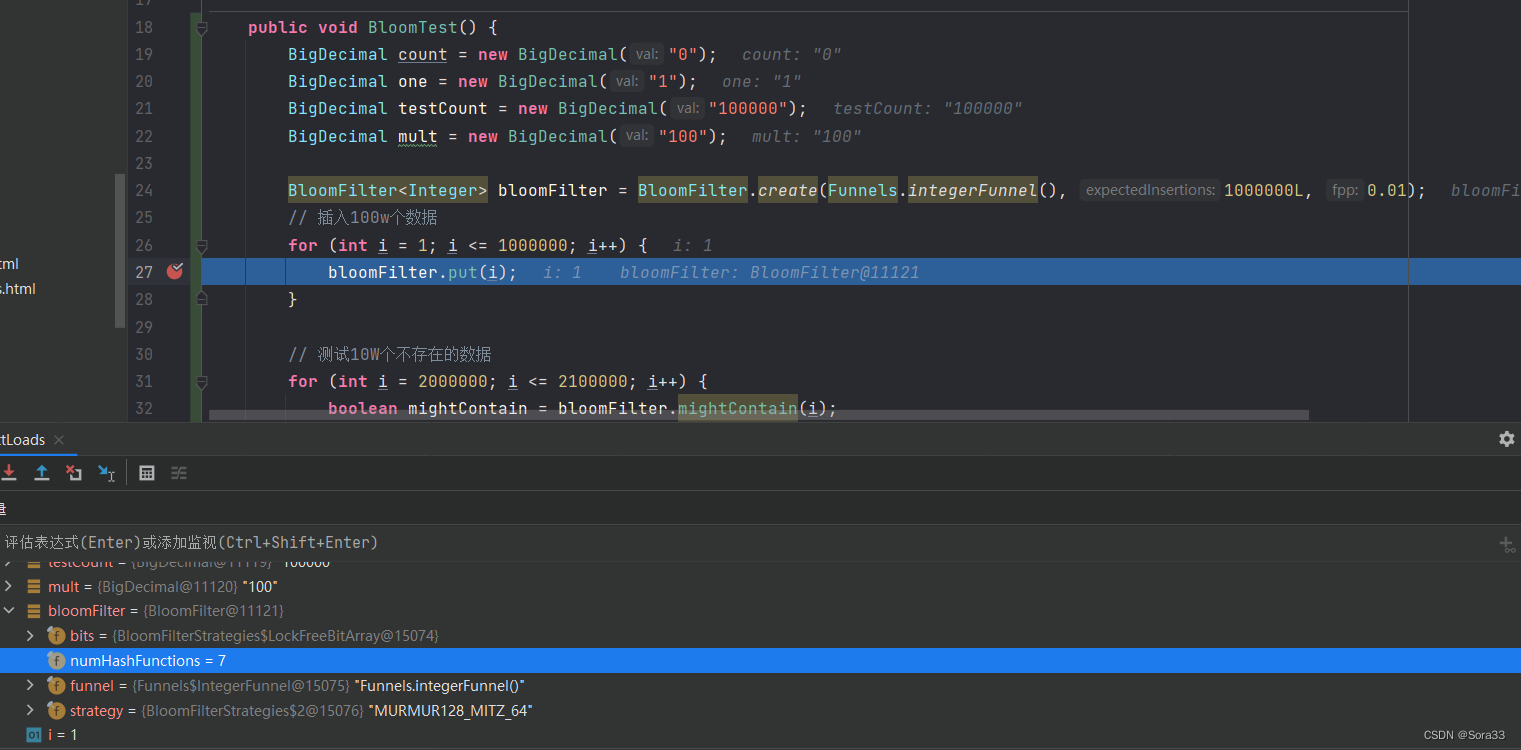
接下来我们测试将误差值改为0.000001,从原来的7次哈希变为了20次哈希
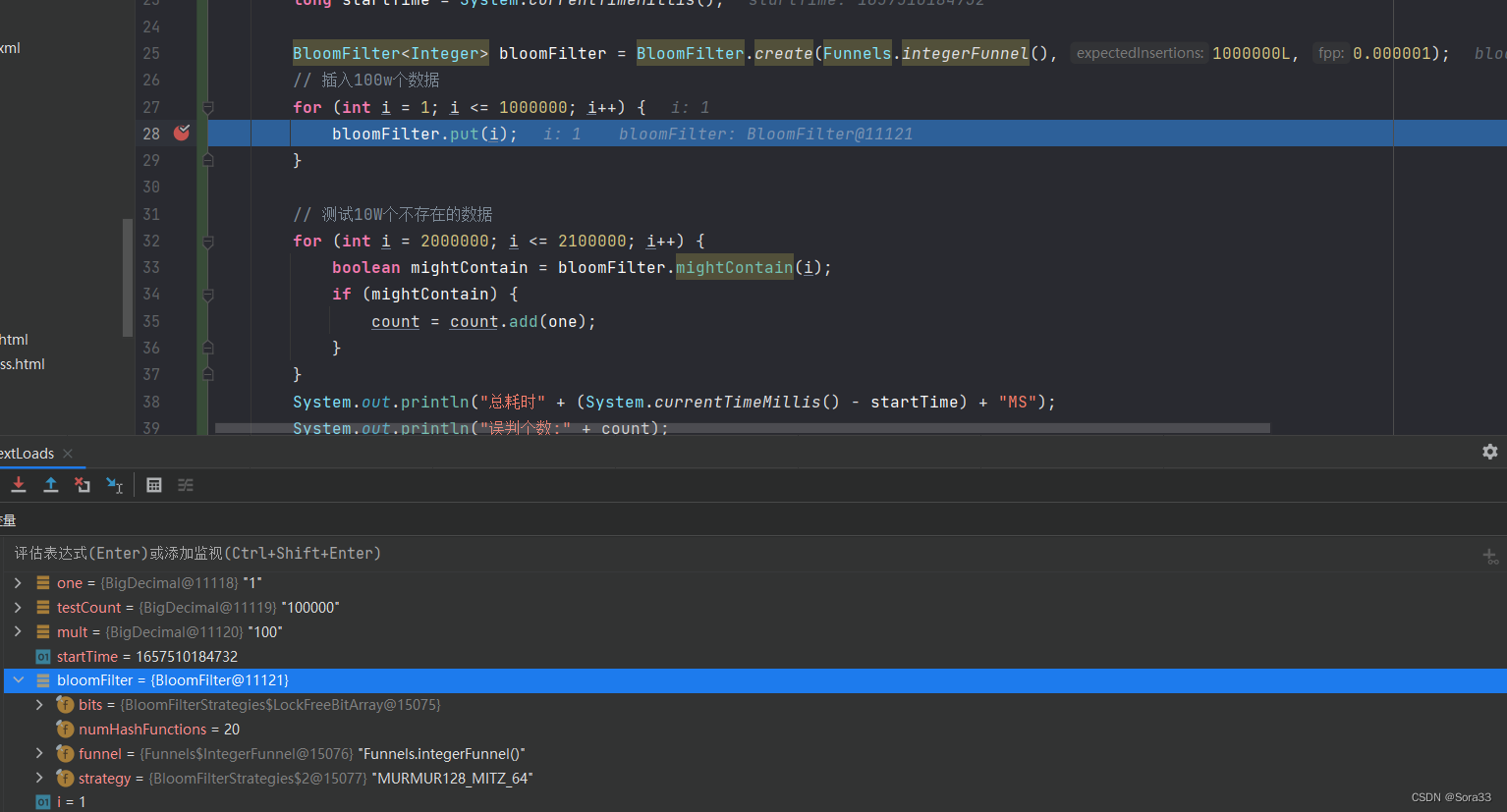
时间效率也从200增到了700+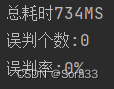
所以我们得出结论。要取一个适当的值来确定误差值。就和hashmap的负载因子是0.75一样 为1哈希冲突太大,为0.5冲突是少了,但是空间利用率下降了。
项目中使用布隆过滤器防止缓存穿透
创建一个初始化布隆过滤器类。并实现CommandLineRunner接口,启动项目后执行。
初始化一个布隆过滤器,设置好我们对应的参数。之后将数据库中的数据使用put方法加入到布隆过滤器中。这里我放入的是商品的详情
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import com.retail.constant.SkillConstants;
import com.retail.mapper.GoodsMapper;
import com.retail.pojo.resp.SkillActivityResp;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* @className: BloomInit
* @description: 初始化布隆过滤器
* @date: 2022/07/11
* @author: Sora33
*/
@Configuration
@Log4j2
public class BloomInit implements CommandLineRunner {
@Autowired
private GoodsMapper goodsMapper;
@Override
public void run(String... args) throws Exception {
this.bloomInit();
}
/**
* 初始化布隆过滤器
*/
@Bean
public BloomFilter bloomInit() {
// 初始化布隆过滤器,设置数据类型,数组长度和误差值
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), 1000000L, 0.01);
// 获取要装入过滤器的数据
List<SkillActivityResp> skillActivityGoods = goodsMapper.getSkillActivityGoods();
// 循环装填
for (SkillActivityResp skillActivityGood : skillActivityGoods) {
bloomFilter.put(SkillConstants.SKILL_GOODS + skillActivityGood.getShopId() + "_" + skillActivityGood.getActivityId());
log.info("已加入数据[{}]到布隆过滤器...", SkillConstants.SKILL_GOODS + skillActivityGood.getShopId() + "_" + skillActivityGood.getActivityId());
}
log.info("布隆过滤器装载完成");
return bloomFilter;
}然后在获取商品详情的地方外面加一层布隆过滤器。先从布隆过滤器中获取值,如果有则放行,没有直接返回。有效解决了请求直接穿过redis,访问数据库所造成的不必要的压力。
/**
* 根据商品id和活动id获取商品
* @param shopId
* @param activityId
* @param activityId
* @return
*/
@Override
public SkillActivityResp getGoodsByshopIdAndActivityId(Integer shopId, Integer activityId) {
boolean contains = bloomFilter.mightContain(SkillConstants.SKILL_GOODS + shopId + "_" + activityId);
if (!contains) {
return null;
}
// 尝试从redis中获取
String skillActivityResp = stringRedisTemplate.opsForValue().get(SkillConstants.SKILL_GOODS + shopId + "_" + activityId);
if (skillActivityResp == null) {
SkillActivityResp goods = goodsMapper.getGoodsByshopIdAndActivityId(shopId,activityId);
// 存入redis
stringRedisTemplate.opsForValue().set(SkillConstants.SKILL_GOODS + shopId + "_" + activityId, JSONObject.toJSONString(goods),24, TimeUnit.HOURS);
return goods;
}
return JSONObject.parseObject(skillActivityResp, SkillActivityResp.class);
}结尾
布隆过滤器也是有缺点的,比如存在误判,删除数据困难...可以选择使用布谷鸟过滤器,各方面相对于布隆过滤器都有一些优化
更多知识请移步个人博客:33sora.com

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)