Hbase学习
Hbase
HBASE
简介
HBASE 是一个开源的、分布式的、非关系型的列式数据库,正如bigtable利用了谷歌文件系统提供的分布式数据存储一样,在HBASE在hadoop的hdfs之上提供了类似于Bigtable的功能
HBASE位于hadoop生态系统的结构化存储层,数据存储与分布式文件系统HDFS并且使用Zookeeper作为协调服务,HDFS为Hbase提供了高可靠性的底层存储服务,MapReduce为Hbase提供了高性能的计算能力,ZooKeeper则为Hbase提供了稳定的服务和失效恢复机制
Hbase 的设计目的是处理非常庞大的表,甚至是可以使用普通的计算机处理10亿行的、由数百万列组成的表的数据,由于Hbase依赖hadoop HDFS,因此它与Hadoop 一样,主要依靠横向扩展,并不断增加廉价的商用服务器来提高计算和存储能力
一、特点
表数据可以存储上亿行、百万列
采用面向列的存储和权限管控
为空(NULL)的列并不占用存储空间(节约资源和数据占用空间)
1、优点
容量巨大:单表支持千亿行、百万列的数据规模,数据容量达到TB甚至PB级别。传统关系型 Oracle或mysql超过亿行读写性能急剧下降。
扩展性:可对数据存储节点和读写服务节点进行扩展,数据存储节点可通过增加HDFS的 DataNode进行扩展;读写服务节点扩展可增加ReginServer实现扩展。
稀疏性:允许大量列值为空,并不占用任何存储空间。
高性能:擅长OLTP场景,数据写操作性能强劲;随机单点读以及小范围的扫描读,其性能能够 得到保证。对于大范围的扫描读可以使用MapReduce提供的API,以便实现更高效的并行扫描。
多版本:即一个KV可以同时保留多个版本,可选择最新版本或某个历史版本。
支持过期:用户只需要设置过期时间,超过TTL的数据会自动清理,无需写程序删除。
Hadoop原生支持:用户可以直接绕过HBase操作HDFS文件,高效的完成数据扫码和数据导入; 也可进行分级存储,重要的业务放到SSD、不重要的放到HDD。用户可以设置归档时间,将最 近数据放在SSD,归档数据放在HDD。
2、缺点
不支持很复杂的聚合逻辑(join、groupby),如果需要使用聚合运算,在HBase之上架设 Phoenix或Spark组件,前者主要用于小规模聚合OLTP场景,后者应用于大规模聚合的OLAP场 景。
HBase本身没有实现二级索引,不支持二级索引查找,普遍使用Phoenix提供的二级索引功能。
HBase原生不支持全局跨行失误,只支持单行事务模型。同样可通过Phoenix提供的全局事务模 型来弥补
3、OLAP VS OLAP
OLTP(On-Line Analytical Processing 联机事务处理):OLTP是传统的关系型数据库,主要应用,主要是基本的、日常的事务处理,记录即时的增、删、改、查
OLAP(On-Line Transaction Processing 联机分析处理):支持复杂的分析操作,侧重决策支 持,并且提供直观易懂的查询结果

二、基本结构
组成结构如下
1.表 ( table)
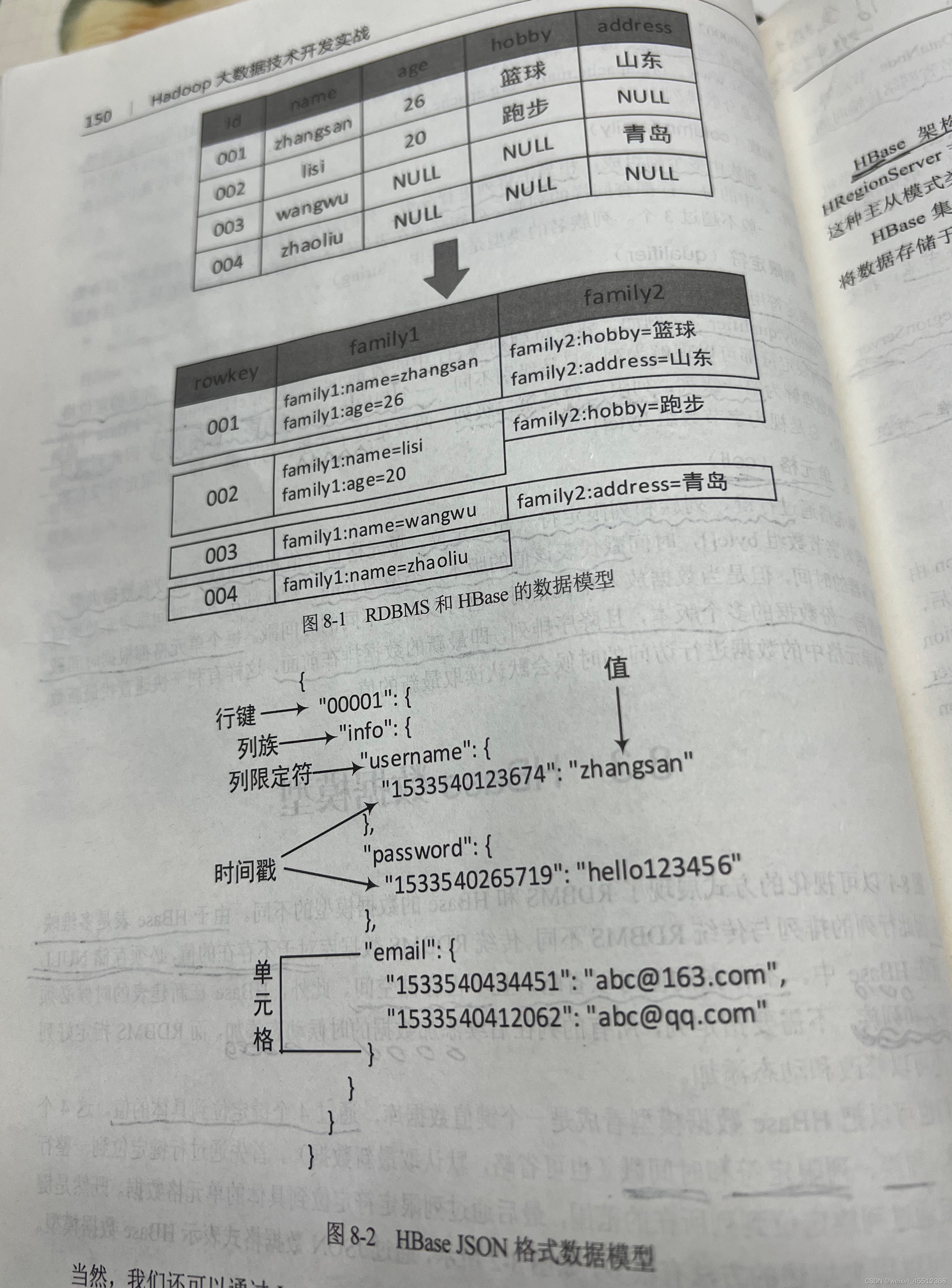
在Hbase中,数据存储在表中,表名是一个字符串,表由行和列组成,与关系型的数据库(RDBMS)不同,Hbase表是多位映射的
2.行(row)
Hbase中的行由行键rowkey和一个或者多个column组成,行键没有数据类型,总是为视为字节数组byte[]。行键类似于关系型数据库(RDBMS)中的主键索引,在整个Hbase表中是唯一的,但是与RDBMS不同的是,行家按照字母顺序排序。例如,表中已有三条行键为1000001、100002、和1000004的数据,当插入一条行键为1000003的数据时,该条数据不会拍在最后,而是排在行键1000002和1000004的中间,因此行键的设计非常重要,我们可以利用行键的这个特性将相关的数据排列在一起,例如建网站的域名最为行键的前缀,则应该将域名进行反转存储(例如 org.apache.www、org.apache.mail、org.apache.jira),这样所有的Apache域名将在表中排列在一起,而不是分散列
3、列族(column family)
Hbase列族由多个列组成,相当于列进行分组,列的数量没有限制,一个列族里可以有数百万个列,表中的每一行都有想同样的列族,列族必须在表创建的时候指定,不能轻易修改,且数量不能太多,一般不超过3个,列族名的类型是字符串(String)
4、列限定符(qualifier)
列限定符用于代表HBASE表中列名称,列族里的数据通过列限定符来定位,常见的定位格式为“family:qualifier”,(例如,要定位到列族cfl中的列name,则使用cfl:name)。Hbase中的列族和列限定符都可以理解为列,只是列级别不同,一个列族下面可以有多个列限定符,因此列族可以简单理解为第一级列,列限定符是二级列,两者的关系时父子关系,与行键一样,列限定符没有数据类型,总是视为字节数组byte[]
5、单元格(cell)
单元格通过行键、列族和列限定符一起来定位的,单元格包含值和时间戳,值没有数据类型,总是视为字节数组byte[],时间戳代表该值的版本,类型为long,默认情况下,时间戳表示数据写入服务器的时间,但是当数据放入单元格时,也可以制定不同的时间戳,每个人单元格都根据时间戳保存同一份数据的多个版本,且降序排列,即最新的数据排在最前面,这样有利于快速查找最新数据,对单元格中的数据进行访问的时候,会默认读取最新值
6、 简单概括就是
表(table):一个表包含多行数据
行(row):唯一标识rowkey,多个列以及对应的值
列(column):列簇(colummn family):列名(qualifier)组成(:号相连)。一个列簇下可有多个 列;列可动态增加(可扩展到上百万列)
单元格(cell):五元组(row,column,timestamp,type,value)组成,其中(row,column,timestamp,type)是K,value字段对应KV结构的V
时间戳(timestamp):每个cell写入自带时间戳,同一个rowkey、column下有多个value存 在,value用timestamp作为版本号,版本号越大,数据越新
三、 数据模型
1、模型简介
因为Hbase表是多位映射的,因此行列的排列与传统RDBMS不同,传统的RDBMS数据库对于不存在的值,必须存储NULL值,而在Hbase中,不存在的值可以省略,且不占用存储空间,此外,Hbase在新建表的时候必须指定表名和列族,不需要指定列,,所有的列在后续添加数据的时候动态添加,而传统的RDBMS指定好列以后,不可以修改和动态添加
当然也可以把Hbase看成键值对的数据库(比如redis,mongdb等),通过4个键定位到具体的值,这4个值是行键、列族、列限定符、时间戳,
也可以通过此图看出来,java中常用的存储键值集合为Map,而Map是允许多层嵌套的,使用Map嵌套来表示Hbase数据模型的效果如下
Map<rowkey,Map<column faimily,Map<qualifier,Map<timestamp,data>>>>
逻辑视图
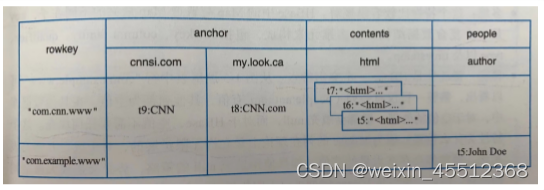
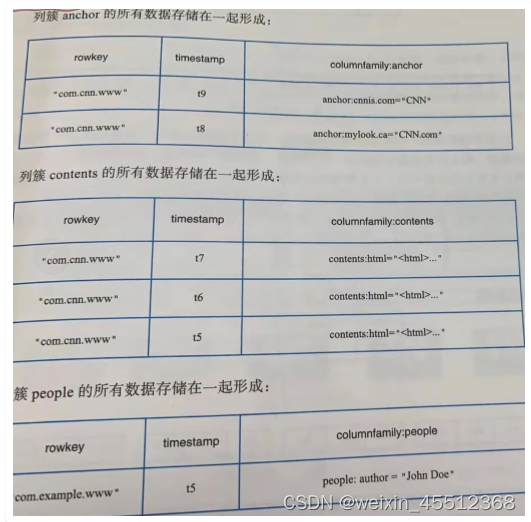
三个列簇,其中anchor下有2列,根据行com.cnn.www以及列anchor:cnnsi.com可以定位到数据 CNN,对应的时间戳是t9;同一行另一列contents:html下有3个版本数据,版本号是t5、t6、t7
物理视图
四、存储介绍
1、行式存储
按行写入:mysql典型 获取行高效 获取列低效:按行读取,按列过滤,无用列占用大量内存 适用于OLTP====
2、列式存储
将一列数据存储在一起:Kudu代表 获取列高效 获取行低效:按列读取,按行合并 具备高压缩特性:列数据类型相同
3、列簇式存储
介于行式存储和列式存储之间: 等同于行式:一张表只设置一个列簇 等同于列方式:一张表设置大量列簇,每个列簇下仅有一列(不建议设置太多列簇)
五、架构体系
1、架构方式
Hbase 架构采用主从(master/slave)方式,有三种类型的节点组成--------HMaster节点、HRegionServer节点和ZooKeeper集群,其中HMaster节点作为主节点,HRegionServer作为从节点,ZooKeeper来进行协调,这种节点方式类似于Hdfs中的NN和DN
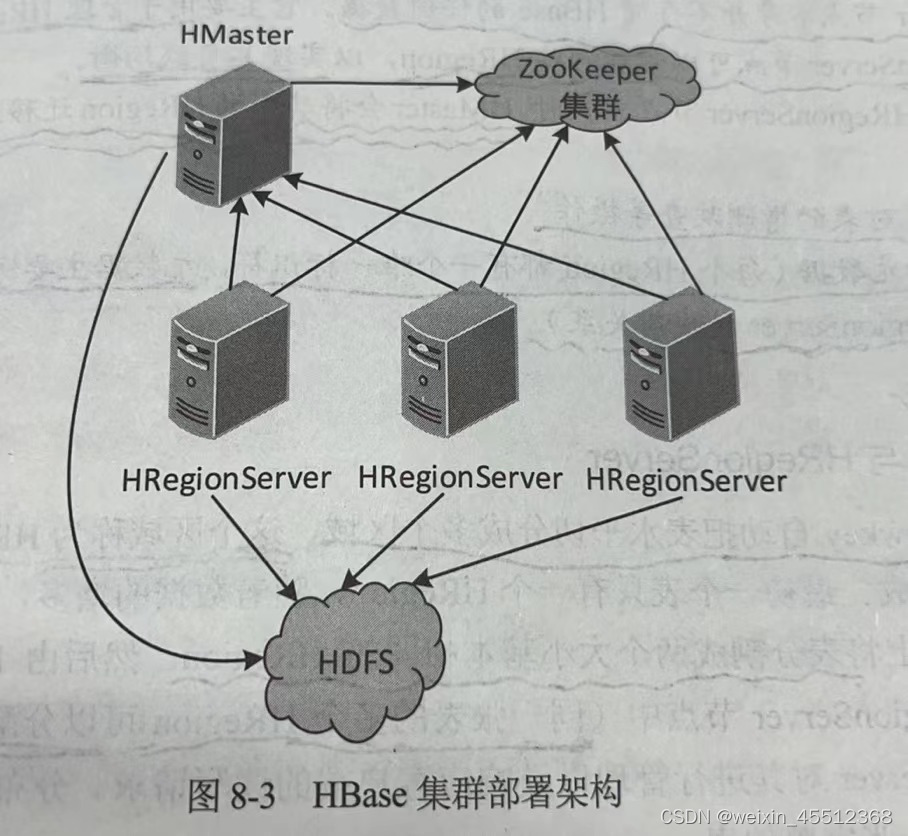
2、读写过程
2.1、Hbase 写流程
如图所示:
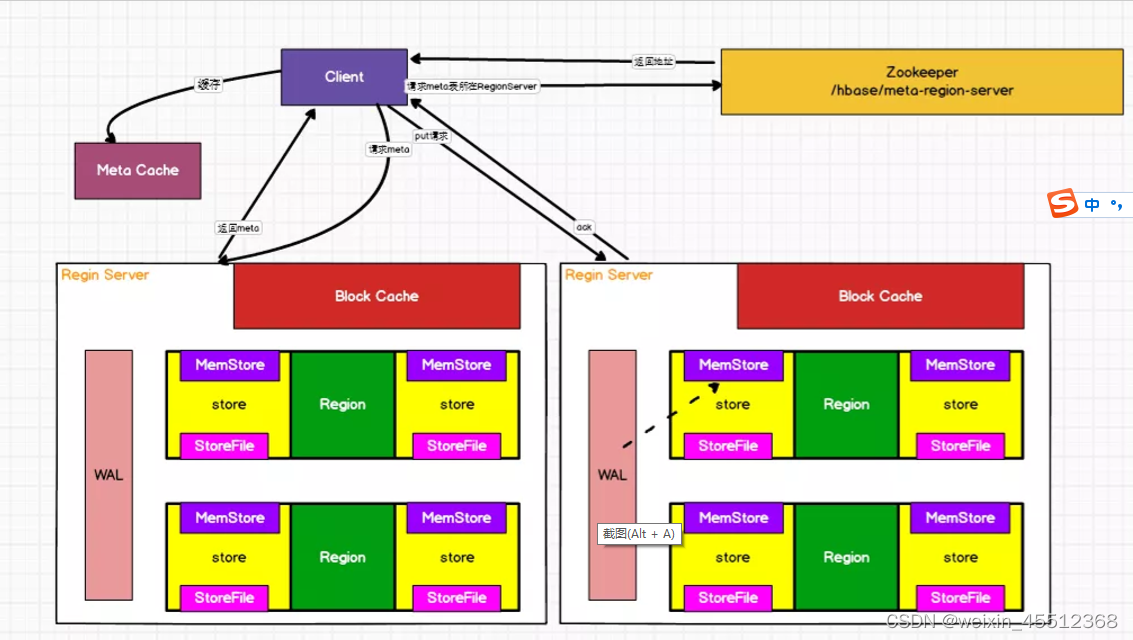
写流程的详细流程
(1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
(2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询 出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及metA表的位置信 息缓存在客户端的meta cache,方便下次访问。
(3)与目标Region Server进行通讯。
(4)将数据顺序写入(追加)到WAL。
(5)将数据写入对应的MemStore,数据会在MemStore进行排序。 (6)向客户端发送ack。 (7)等达到MemStore的刷写时机后,将数据刷写到HFile。
MemStore刷写时机
(1)当某个memstroe的大小达到了默认值128M,其所在region的所有memstore都会刷写。
hbase.hregion.memstore.flush.size(默认值128M)
当memstore的大小达到了以下,会阻止继续往该memstore写数据。
hbase.hregion.memstore.flush.size(默认值128M)
hbase.hregion.memstore.block.multiplier(默认值4)
(2) 当region server中memstore的总大小达到java_heapsize百分比时候,region会按照其所有 memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小 到下述值以下。
hbase.regionserver.global.memstore.size(默认值0.4)
hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)
当region server中memstore的总大小达到,java_heapsize时,会阻止继续往所有的memstore写数 据。
hbase.regionserver.global.memstore.size(默认值0.4)
(3) 到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置。
hbase.regionserver.optionalcacheflushinterval(默认1小时)
(4) 当WAL文件的数量超过hbase.regionserver.max.logs(大值为32),region会按照时间顺序依 次进行刷写。**
2.2、Hbase 读流程
如图所示:
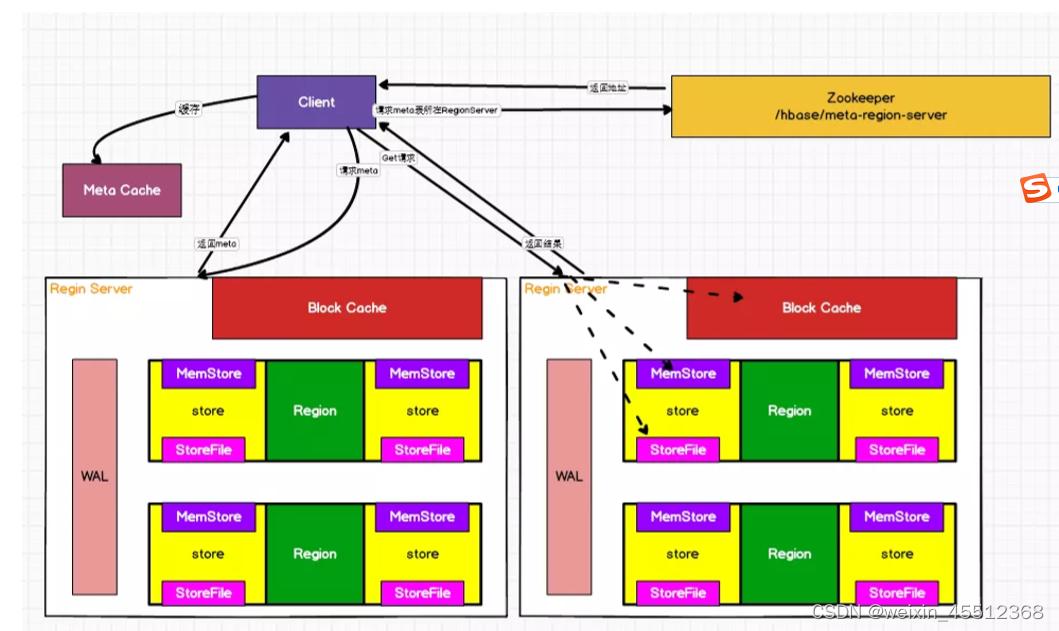
读流程的详细流程:
**
(1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
(2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询 出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信 息缓存在客户端的meta cache,方便下次访问。
(3)与目标Region Server进行通讯。
(4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所 有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
(5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
(6)将合并后的终结果返回给客户端。**
2.3、数据合并策略
StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型 (Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个 数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。 Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将邻近 的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会 将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。
Region Split
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分 时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个 Region转移给其他的Region Server。
Region Split时机 当1个region中的某个Store下所有StoreFile的总大小超过下面的值,该Region就会进行拆分。
Min(initialSize*R^3 ,hbase.hregion.max.filesize")
其中initialSize的默认值为2*hbase.hregion.memstore.flush.size
R为当前Region Server中属于该Table的Region个数)
具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了。
2.4、体系结构
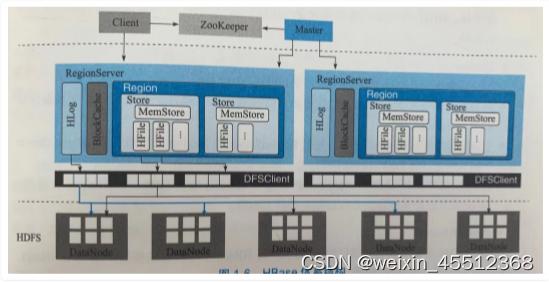
Client
shell
java-api
thrift/rest-api:支持非java的上层业务需求
mapReduce:批量数据导入以及批量数据读取
Zookeeper
实现master高可用
管理系统核心元数据:管理工作的RegionServer集合,保存hbase:meta所在RegionServer地址 参与RegionServer宕机恢复
实现分布式表锁:对一张表进行管理操作,先加表锁,防止其他用户进行操作造成表状态不一 致
Master
处理用户各种管理请求
管理集群中所有RegionServer
清理过期日志及文件:间隔时间检查Hlog是否过期、HFile是否已删除,过期后进行删除
ReginServer
WAL(HLog):HBase数据写入时,先写入缓存再异步刷新落盘。为防止数据丢失,数据写入 缓存前首先顺序写入Hlog,即使缓存丢失也可通过Hlog进行恢复;通过HLog日志用于实现集群 中从复制。
BlockCache:HBase系统中的读缓存,客户端从磁盘读取数据之后通常会将数据缓存到内存 中,后续访问同一行数据直接从内存获取不需要访问磁盘。BlockCache缓存对象是一系列Block 块,一个Block块是64k,由物理上相邻的多个KV数据组成。BlockCache同时利用了空间局部性和 时间局部性原理,对应两种实现为LRUBlockCache和BucketCache
Region:数据表的一个分片,当数据表超过一定阀值就会水平切分成两个Region。一张表的 Region会分布在整个集群多台ReginServer上,一个ReginServer上会管理多个Region;一个 Region由一个或多个Store组成 Store: 每个列簇的数据都集中存放在一起形成一个存储单元Store,多少个列簇就有多少个
Store;每个Store由1个MemStore和一个或多个HFile组成。 MemStore:写缓存,写数据先写入MemStore,MemStore写满后(默认128M)异步将数据 flush成一个HFile文件。
HFile:随着数据不断写入,HFile文件会越来越多,当HFile文件超过一定阀值之后会执行 Compact操作,将这些小文件通过一定策略合并成一个或多个大文件
空间局限性:将读取KV数据很可能与当前读取到的KV数据在地址上是相邻的,缓存单位是Block(块)
时间局限性:KV数据正在被访问,那么近期它可能再次被访问。
HDFS
用户数据文件、HLog日志文件最终都会写入HDFS落盘,默认三副本存储,HBase封装了DFSClient 的HDFS客户端组件负责对HDFSDE实际数据进行读写访问。
六、Hbase参数设计
1、核心参数的优化—读写参数
Region
Region是HBase中的表是根据row key的值水平分割而成的。一个region包含表中所有row key位于region的起始键值和结束键值之间的行,所以Region是HBase中数据存储的载体,该载体包含内存存储以及文件存储。
hbase.hregion.max.filesize
默认为 10G,简单理解为 Region 中所有文件大小的总和大于该值就会进行 split 。
实际生产环境中该值不建议太大,也不能太小。
太大会导致系统后台执行 compaction 消耗大量系统资源,一定程度上影响业务响应;
太小会导致 Region 分裂比较频繁(分裂本身其实对业务读写会有一定影响),这样的话单个 RegionServer 中必然存在大量 Region,太多 Region 会消耗大量维护资源。
而且每台RegionServer的write cache是有上限的,如果触发上限,会导致HBase “stop the world and flush memstore”,这样对整个业务来说是不可接受的,所以Region个数在满足业务的前提下,也要考虑到RegionServer的负载以及该节点上write cache的总大小,以避免触发业务不可用的场景。
此外Region数量过大会在 RegionSever 下线迁移时比较耗时耗资源。
而且在HBase中也有逻辑控制如果单个RegionServer上的Region数量超过1000,则RegionServer会停止Region的split操作。
综合考虑,建议线上设置为 50G 左右。
但是从本人现场工作中 Region设置为200为最佳,RegionSize的大小为20G
2、写参数优化 ----Memstore
上面说的Region中包含内存存储以及文件存储,而Memstore即是内存存储,也是HBase的writecache。一个Region有一个Memstore,数据写入时首先写入Memstore,Memstore达到一定的阈值后会触发flush操作,生成文件从而做到持久化。
默认 128M(134217728),memstore 大于该阈值就会触发 flush。如果当前系统 flush 比较频繁,并且内存资源比较充足,可以适当将该值调整为 256M。调大的副作用可能是造成宕机时需要分裂的 hlog 数量变多,从而延长故障恢复时间。
hbase.hregion.memstore.block.multiplier
另外调整该值时需要考虑到该Region所在RegionServer的数量,因为每个memstore的flush size * region的个数的总量比write cache大太多,而每个region写入比较均衡的话,可能会出现每个memstore都还没达到flush的阈值,就已经触发了全局的stop the world and flush memstore,这种情况在生产环境下一定要尽量避免。
默认值为 4,表示一旦某 region 中所有写入 memstore 的数据大小总和达到或超过阈值 hbase.hregion.memstore.block.multiplier*hbase.hregion.memstore.flush.size,就会执行 flush 操作,并抛出 RegionTooBusyException 异常。
该值在笔者使用的 HBase1.2中的默认值为 4,由于不同版本该值的默认值不同,大家可以检查一下 HBase 版本的配置值,旧的版本默认值为 2。如果日志中出现如下内容:
RegionTooBusyException: Above memstore limit, regionName=xxxxx ...
这个是 Region 的 memstore 占用内存大小超过正常的 4 倍,这时候会抛异常,写入请求会被拒绝,然后开始flush Memstore。
该情况的产生大概率是因为突然插入一个特别大的值,超过了memstore 占用内存大小的 4 倍,或者一批次的写入总量超过了memstore 占用内存大小的 4 倍,此时Memstore进入保护机制,flush掉之后再恢复写入,防止内存被撑爆。
如果上面的情况,优先考虑避免超大值的插入或者控制一批写入的数据量,如果此方案无法实现,就需要考虑修改该参数值了。
hbase.regionserver.global.memstore.size
默认值为 0.4,表示占用总 JVM 内存大小的 40%,该参数非常重要,就是上面频繁提到的“stop the world and flush memstore”的阈值。整个 RegionServer 上所有写入 memstore 的数据大小总和不能超过该阈值,否则会阻塞所有写入请求并强制执行 flush 操作,直至总 memstore 数据大小降到hbase.regionserver.global.memstore.lowerLimit 以下。
在onheap模式下,如果业务特点是写多读少,可以适当增大,如写内存:0.65,读内存:0.15;反之则可以反向调整,但是不管哪种模式,读写内存之和不要超过0.8,否则会有OOME的风险
另外在 offheap 模式下,read cache绝大部分放在堆外(CBC模式下有一小部分在堆内),所以该值可以配置为 0.6~0.65,如果写多读少还可以分配的再多一点。一旦写入出现阻塞,立马查看日志定位,错误信息类似如下:
regionserver.MemStoreFlusher: Blocking updates on hostname,16020,1522286703886: the global memstore size 1.3 G is >= than blocking 1.3 G size
regionserver.MemStoreFlusher: Memstore is above high water mark and block 528ms
一般情况下不会出现这类异常,但如果出现就需要明确以下情况:
该RegionServer上region 数目是不是太多
单表列族设置的太多
该参数设置是否太小
hbase.regionserver.global.memstore.lowerLimit
默认值 0.95,表示 RegionServer 级别总 MemStore 大小的低水位是 hbase.regionserver.global.memstore.size 的 95%。这个参数表示 RegionServer 上所有写入 MemStore 的数据大小总和一旦超过这个阈值,就会挑选最大的 MemStore 执行强制flush操作;而如果flush的速度赶不上写入的速度,很快达到了hbase.regionserver.global.memstore.size的阈值,就会触发“stop the world and flush memorystore”来保护内存不被撑爆
hbase.regionserver.optionalcacheflushinterval
默认值为 3600000(即 1 小时),hbase 会起一个线程定期 flush 所有 memstore,时间间隔就是该值配置。
生产线上如果有实时数据流入HBase,则该值建议设大,比如 12h。因为很多场景下1小时 flush 一次会导致产生很多小文件,一方面导致 flush 比较频繁,一方面导致小文件很多,影响随机读性能。
3、读参数优化-----BlockCache
上面的Memstore是HBase的write cache,BlockCache就是HBase的read cache,所有的HBase read都从BlockCache开始。不同 BlockCache 策略对应不同的参数,而且这里参数配置会影响到 Memstore 相关参数的配置。笔者对 BlockCache 策略一直持有这样的观点:RegionServer 内存在20G以内的就选择 LRUBlockCache,大于20G的就选择BucketCache 中的 Offheap 模式。接下来所有的相关配置都基于 BucketCache 的 offheap 模型进行说明。
hfile.block.cache.size
默认0.4,该值用来设置LRUBlockCache的内存大小,0.4表示JVM内存的40%。
当前 HBase 系统默认采用 LRUBlockCache 策略,BlockCache 大小和 Memstore 大小均为 JVM 的40%。但对于 BucketCache 策略来讲,Cache 分为了两层(Combine BlockCache,简称CBC),L1 采用LRUBlockCache,主要存储 HFile 中的元数据 Block,L2 采用 BucketCache,主要存储业务数据 Block。因为只用来存储元数据 Block,所以只需要设置很小的 Cache 即可。建议线上设置为 0.05~0.1 左右。
hbase.bucketcache.ioengine
BucketCache 策略的模式选择,可选择 heap、offheap 以及 file 三种,分别表示使用堆内内存、堆外内存以及 SSD 硬盘作为缓存存储介质。
hbase.bucketcache.size
堆外存大小,设置的大小主要依赖物理内存大小。
配置file模式的参数(线上环境针对内存资源不足,某段时间使用 SSD 存储 cache):
# SSD
hbase.bucketcache.ioengine=file:/disk/disk11/hbase_ssd/cache.data
hbase.bucketcache.size=20GB
4、文件的合并-----Compaction
上文已经介绍,Memstore在达到了flush的阈值后就会flush数据到硬盘。由于一个region属于一个table,一个table有多个列族,则一个region同样有多个列族,而一个列族有一个memestore,所以一次flush生成列族数个文件。由于数据不断的flush,生成的文件数会越来越多,如果不进行处理,那么磁盘上的小文件会越来越多,影响磁盘的效率同时也影响数据读取效率,在这种背景下就有了compaction 模块。
这个模块的主要用来合并小文件,分为minor compact和major compact。minor compact按照配置进行文件合并,将符合条件的文件合并成一个文件(可能是所有文件,也可能是部分文件),这个过程是条件触发的,下面的参数绝大部分都关于minor compact的;major compact则会将该region中所有文件合并成一个文件,并且在这个过程中删除过期数据、delete 数据等,这个是定时执行的,也可以禁止定时执行,根据情况手动执行。compact涉及参数较多,对于系统读写性能影响也很重要,下面主要介绍部分比较核心的参数。
hbase.hstore.compactionThreshold
默认值为 3,compaction 的触发条件之一,当 store 中文件数超过该阈值就会触发compaction。通常建议生产线上写入较高的系统调高该值,比如 5~10 之间。
如在任意一个 hstore 中有超过此数量的 HStoreFiles,则将运行minor compact以将所有 HStoreFiles 文件作为一个 HStoreFile 重新写入。(每次 memstore 刷新写入一个 HStoreFile)您可通过指定更大数量延长压缩,但minor compact将运行更长时间。在compact期间,更新无法刷新到磁盘。长时间compact需要足够的内存,以在compact的持续时间内记录所有更新。如太大,compact期间客户端会超时。
hbase.hstore.compaction.max
默认值为 10,最多可以参与 minor compaction 的文件数。该值通常设置为 hbase.hstore.compactionThreshold 的 2~3 倍。
hbase.regionserver.thread.compaction.throttle
默认值为 2G,评估单个 compaction 为 small 或者 large 的判断依据。为了防止 large compaction 长时间执行阻塞其他 small compaction,HBase 将这两种 compaction 进行了分离处理,每种 compaction 会分配独立的线程池。
hbase.regionserver.thread.compaction.large/small
默认值为 1,large 和 small compaction 的处理线程数。生产线上建议设置为 5,强烈不建议再调太大(比如10),否则会出现性能下降问题。
在写入负载比较高的集群,可以适当增加这两个参数的值,提高系统 Compaction 的效率。但是这两个参数不能太大,否则有可能出现 Compaction 效率不增反降到现象,要结合生产环境测试。
hbase.hstore.blockingStoreFiles
默认值为10,表示一旦某个 store 中文件数大于该阈值,就会导致所有更新阻塞。生产线上建议设置该值为 100,避免出现阻塞更新,一旦发现日志中出现如下日志信息:
too many store files; delaying flush up to 90000ms
这时就要查看该值是否设置正确了。
hbase.hregion.majorcompaction
默认值为 604800000(即 一周),表示 major compaction 的触发周期。
由于major compaction消耗资源较大,执行时间较长,对HBase性能产生很大的影响,所以生产线上建议大表手动执行 major compaction,需要将此参数设置为0,即关闭自动触发机制,然后通过脚本或者人工来执行此动作。
5、请求的参数-----Request队列相关参数
hbase.regionserver.handler.count
默认值为 30,服务器端用来处理用户请求的线程数。生产线上通常需要将该值调到 100~200。
用户关心的请求响应时间由两部分构成:排队时间和服务时间,即 response time = queue time + service time。优化系统需要经常关注排队时间,如果用户请求排队时间很长,首要关注的问题就是 hbase.regionserver.handler.count 是否没有调整。
hbase.ipc.server.callqueue.handler.factor
默认值为 0,服务器端设置队列个数,默认只有1个队列。假如该值为 0.1,那么服务器就会设置 handler.count0.1=300.1=3 个队列。
hbase.ipc.server.callqueue.read.ratio
默认值为 0,服务器端设置读写业务分别占用的队列百分比以及 handler 百分比。默认所有请求使用所有的队列,先到先得。但是某些场景下需要控制读写分离,就需要设置该值了。假如该值为0.5,表示读写各占一半队列,同时各占一半 handler。
hbase.ipc.server.call.queue.scan.ratio
默认值为 0,即读数据时候所有请求使用所有队列,但某些场景下服务器端为了将 get 和 scan 隔离,需要设置该参数。假如该值为0.5,表示scan和get各占一半读队列,同时各占一半读handler,结合上面的hbase.ipc.server.callqueue.read.ratio的0.5,则各占所有资源的25%。
6、其他参数
hbase.online.schema.update.enable
默认值为 true,表示更新表 schema 的时候不再需要先 disable 再 enable,直接在线更新即可。该参数在HBase 2.0之后默认为true。
生产线上建议设置为true。
hbase.quota.enabled
默认值为 false,表示是否开启 quota 功能,quota 的功能主要是限制用户/表的 QPS,起到限流作用。
hbase.snapshot.enabled
默认值为 true,表示是否开启 snapshot 功能,snapshot 功能主要用来备份 HBase 数据。
生产线上建议设置为true。
zookeeper.session.timeout
默认值为 180s,表示 Zookeeper 客户端与服务器端 session 超时时间,超时之后 RegionServer 将会被踢出集群。
有两点需要重点关注:其一是该值需要与 Zookeeper 服务器端 session 相关参数一同设置才会生效。但是如果一味的将该值增大而不修改 Zookeeper 服务端参数,可能并不会实际生效。其二是通常情况下离线集群可以将该值设置较大,在线业务需要根据业务对延迟的容忍度考虑设置。
详细介绍可见zookeeper.session.timeout相关参数与配置
详解:
https://blog.csdn.net/microGP/article/details/107481150
https://blog.csdn.net/microGP/article/details/116752249
七、数据结构和算法
HBase2.0 代码行数突破150w行 HBase
1、核心数据结构:
主要包括跳跃表、LSM树和布隆过滤器
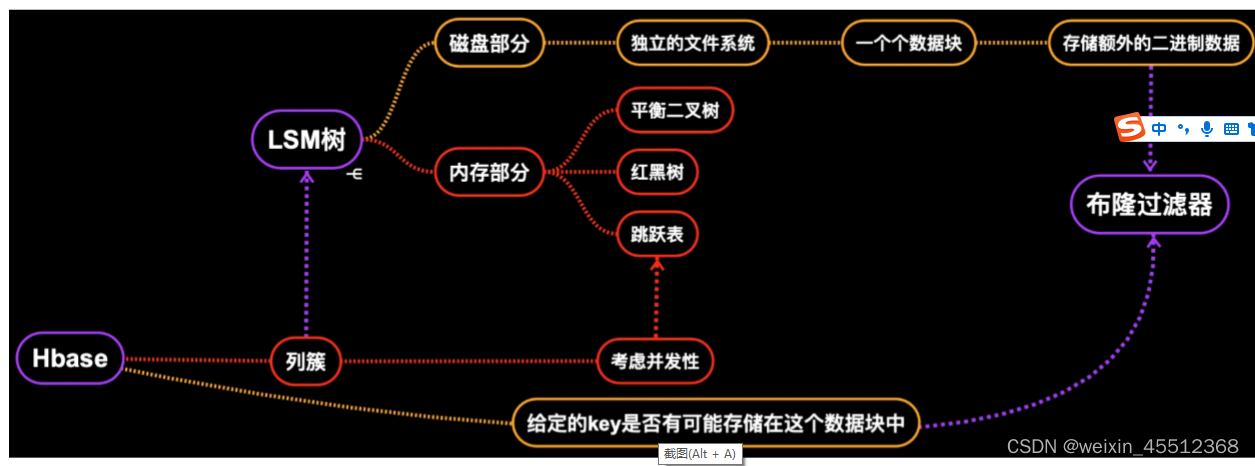
跳跃表(SkipList)
高效实现插入、删除、查找的内存数据结构,期望复杂度是O(logN) 优点:与红黑树以及其他二分查找相比,实现简单、高并发场景下加锁粒度更小,从而实现更 高并发。
例如Redis、LevelDB、HBase都把跳跃表作为维护有序数据集合的基础数据结构
如图所示:
1.定义:

2.查找
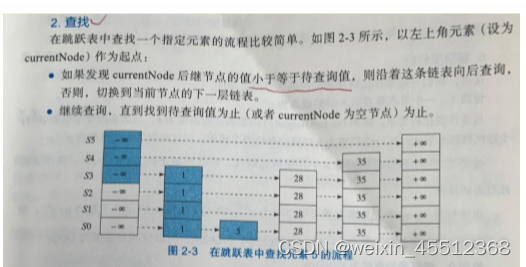
3.插入
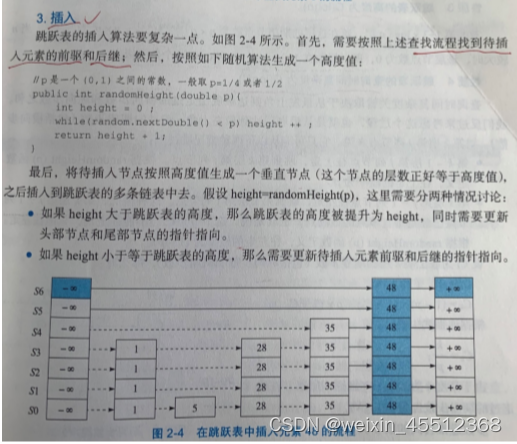
LSM树
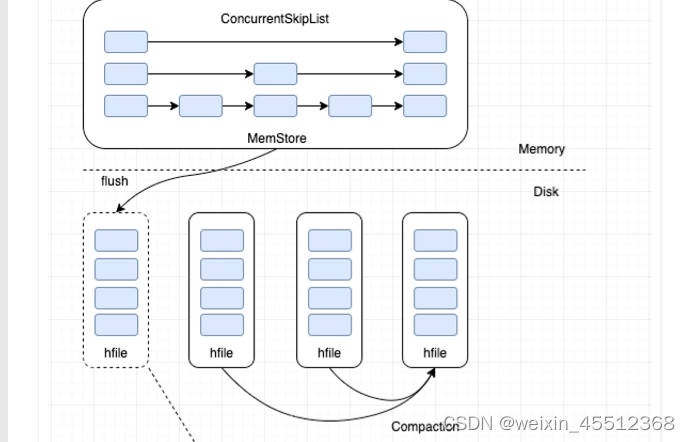
本质和B+树一样,是一种磁盘数据的索引结构,和B+树不同的是,LSM树的索引对写入请求更 友好。因为无论何种写入请求,LSM树都会将写入操作处理为一次顺序写,而HDFS擅长的正是 顺序写(HDFS不支持随机写)。 LSM树内存部分采用跳跃表来维护KeyValue集合,磁盘部分一般由多个内部KeyValue有序的文 件组成
KeyValue存储格式

索引结构
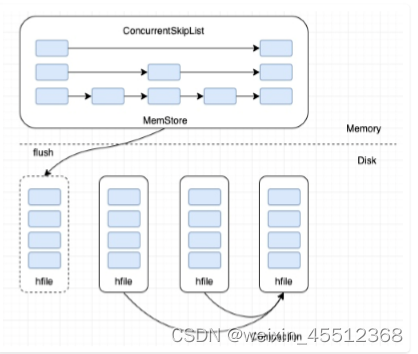
内存部分:ConcurrentSkipListMap,key就是前面key部分,value是字节数组 flush:内存部分形成有序文件,
flush写入性能:当前写入Memstore设为Snapshot(不能再写 入),另开一个内存空间作为MemStore写入
磁盘写性能:LSM树使用append操作来实现磁盘顺序写,LSM是一种写入极其友好的索引结 构,可将磁盘写入带宽用到极致
优化读性能:因读取时需要将大量文件进行多路归并,可设置策略将多个hfile文件进行合并成 一个文件(文件个数越少,读取时seek操作次数越少)
文件合并策略:major/minor compact

本质
将写入操作转化成磁盘顺序写入,但对读取不利,
需要读取过程通过归并文件读取对应的KV,这样非常消耗IO,HBase通过异步compaction来降低文件个数,达到提供读取性能目的。
布隆过滤器

例如:判断元素w是否存在在集合A之中
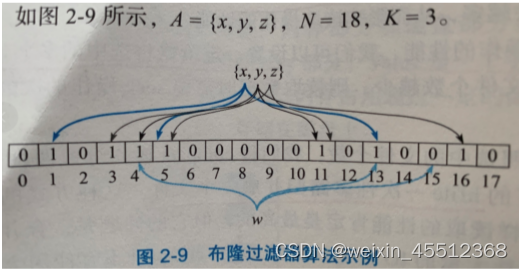
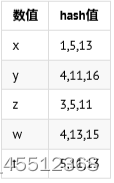
w肯定不在集合A中(3次hash值存在15没全碰成功) t可能存在于集合A中(3次hash值全碰成功)
本质
肯定不存在 可能存在
HBase与布隆过滤器
过滤掉数据块 节省大量io
HBase 1.x
| 布隆过滤器 | 规则 |
|---|---|
| NONE | 关闭 |
| ROW | rowkey |
| ROWCOL | rowkey+family+quailfier |
scan操作无法使用布隆过滤器,除非key固定
scan同一行切换列 rowkey=#<other-field>
核心设计
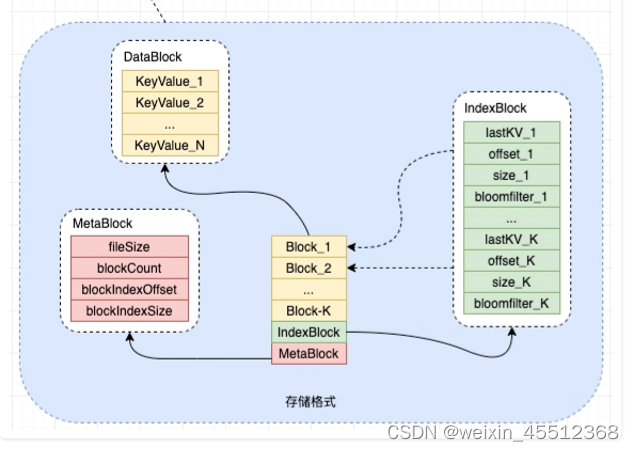
DataBlock
存储有序的KeyValue集合(大小顺序与其存储顺序严格一致),可设置Block大小
IndexBlock
存储多个DataBlock的索引数据
lastKV:该Block下最后一个KV offset:该Block在hfile下的偏移位置,查找时通过offset去seek读取block数据 size: 该Block的字节长度 bloomfilter:该Block内所有keyvalue计算出的布隆过滤器字节数组
MetaBlock
MetaBlock为定长(hfile.filesize-len(MetaBlock))来读取MetaBlock,主要用于保存hfile的元数据信 息
fileSize: hfile的文件总长度(可根据该值和当前文件真实长度判断文件损坏) blockCount: hfile拥有的Block数量 blockIndexOffset: hfile内IndexBlock的偏移量(方便定位IndexBlock) bloclIndexSize: IndexBlock的字节长度

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)