Hadoop三大核心组件概述
HDFS(Hadoop Distribute File System):hadoop的数据存储工具NameNode:1)负责客户端请求的响应2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理DataNode:1)存储用户的文件对应的数据块(Block)2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况YARN(Yet Another Resource Nego
·
HDFS(Hadoop Distribute File System):hadoop的数据存储工具
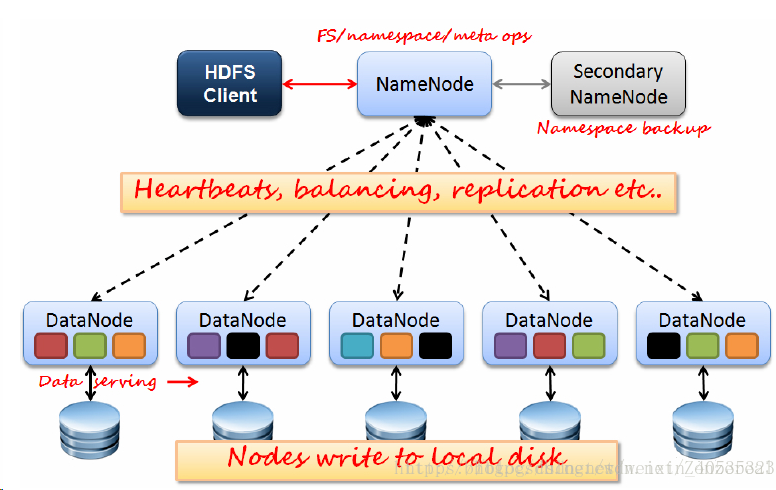
- NameNode:
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理 - DataNode:
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器
- 什么是YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。通过YARN,不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度。
YARN可以说是为了弥补MRv1的缺陷而诞生的 - YARN的基本架构
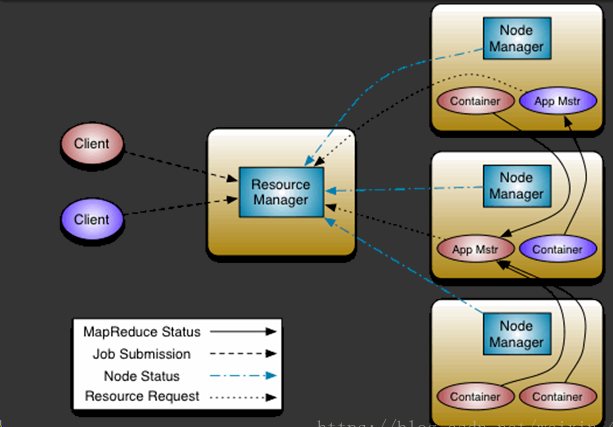
- ResourceManager: RM
整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
处理客户端的请求: 提交一个作业、杀死一个作业
监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何进行处理 - NodeManager: NM
整个集群中有多个,负责自己本身节点资源管理和使用
定时向RM汇报本节点的资源使用情况
接收并处理来自RM的各种命令:启动Container
处理来自AM的命令
单个节点的资源管理 - ApplicationMaster: AM
每个应用程序对应一个:MR、Spark,负责应用程序的管理
为应用程序向RM申请资源(core、memory),分配给内部task
需要与NM通信:启动/停止task,task是运行在container里面,AM也是运行在container里面 - Container
封装了CPU、Memory等资源的一个容器
是一个任务运行环境的抽象 - Client
提交作业
查询作业的运行进度
杀死作业
- YARN的工作流程
Hadoop MapReduce:分布式计算框架
- 什么是MapReduce
Hadoop的MapReduce是对google三大论文的MapReduce的开源实现,实际上是一种编程模型,是一个分布式的计算框架,用于处理海量数据的运算 - MapReduce的流程
MapReduce主要由下面几个过程组成

- 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster命令、用户程序等
- resourceManager为该应用程序分配第一个container,并与对应的nodeManager通信,要求它在这个container中启动应用程序的ApplicationMaster
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复4~7
- ApplicationMaster采用轮询的方式通过RPC协议向resourceManager申请和领取资源
- 一旦ApplicationMaster申请到资源后,便与对应的Nodemanager通信,要求它启动任务。
- NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
- 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态
- 应用程序运行完成后,ApplicationMaster向resourceManager注销并关闭自己
参考链接:Hadoop三大核心组件

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)