
spark读取hive数据的两种方式
spark读取hive数据常用的有两种方式一是通过访问hive metastore的方式,这种方式通过访问hive的metastore元数据的方式获取表结构信息和该表数据所存放的HDFS路径,这种方式的特点是效率高、数据量大、使用spark操作起来更加友好。二是通过spark jdbc的方式访问,就是通过链接hiveserver2的方式获取数据,这种方式底层大题上跟spark链接其他rdbms上一
简述
spark读取hive数据的两种方式
一是通过访问hive metastore的方式,这种方式通过访问hive的metastore元数据的方式获取表结构信息和该表数据所存放的HDFS路径,这种方式的特点是效率高、数据吞吐量大、使用spark操作起来更加友好。
二是通过spark jdbc的方式访问,就是通过链接hiveserver2的方式获取数据,这种方式底层上跟spark链接其他rdbms上一样,可以采用sql的方式先在其数据库中查询出来结果再获取其结果数据,这样大部分数据计算的压力就放在了数据库上。
两种方式的实现
方式一:直接采用spark on hive的方式读取
这种方式只适用在服务器上提交spark-submit时读取本集群hive中的数据,后面会写一篇spark任务读取不同集群中的hive数据方法。
这种方式实现起来很简单,在构建SparkSession的时候设置
enableHiveSupport()样例:
val spark = SparkSession.builder()
.appName("test")
.enableHiveSupport()
.getOrCreate()这样你的SparkSession在使用sql的时候会去找集群hive中的库表,加载其hdfs数据与其元数据组成DataFrame
val df = spark.sql("select * from test.user_info")
方式二:采用spark jdbc的方式
这种方式并不是大数据的主流方法,并不是经常使用,能采用第一种方法最好,但是如果有特别的使用场景的话也可以通过这种方法来实现。
直接使用spark jdbc读取hive数据
val df = spark.read
.format("jdbc")
.option("driver","org.apache.hive.jdbc.HiveDriver")
.option("url","jdbc:hive2://xxx:10000/")
.option("user","hive")
.option("password","xxx")
.option("fetchsize", "2000")
.option("dbtable","test.user_info")
.load()
df.show(10)会有一个现象,DataFrame中只有该表的表结构,并没有该表的真实数据。
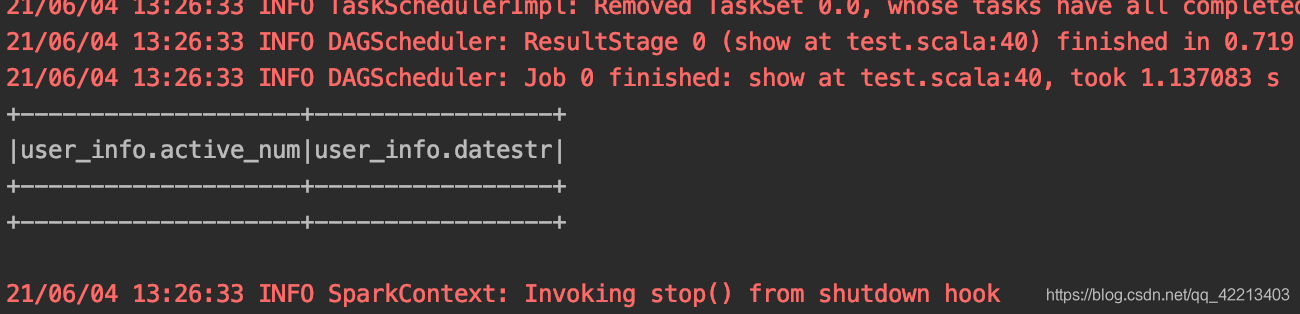
虽然原理一样,但是hive与spark通过jdbc连接其他的rdbms还有点不同,在spark源码中可以看出来,并没有hive相关的dialect用来注册。
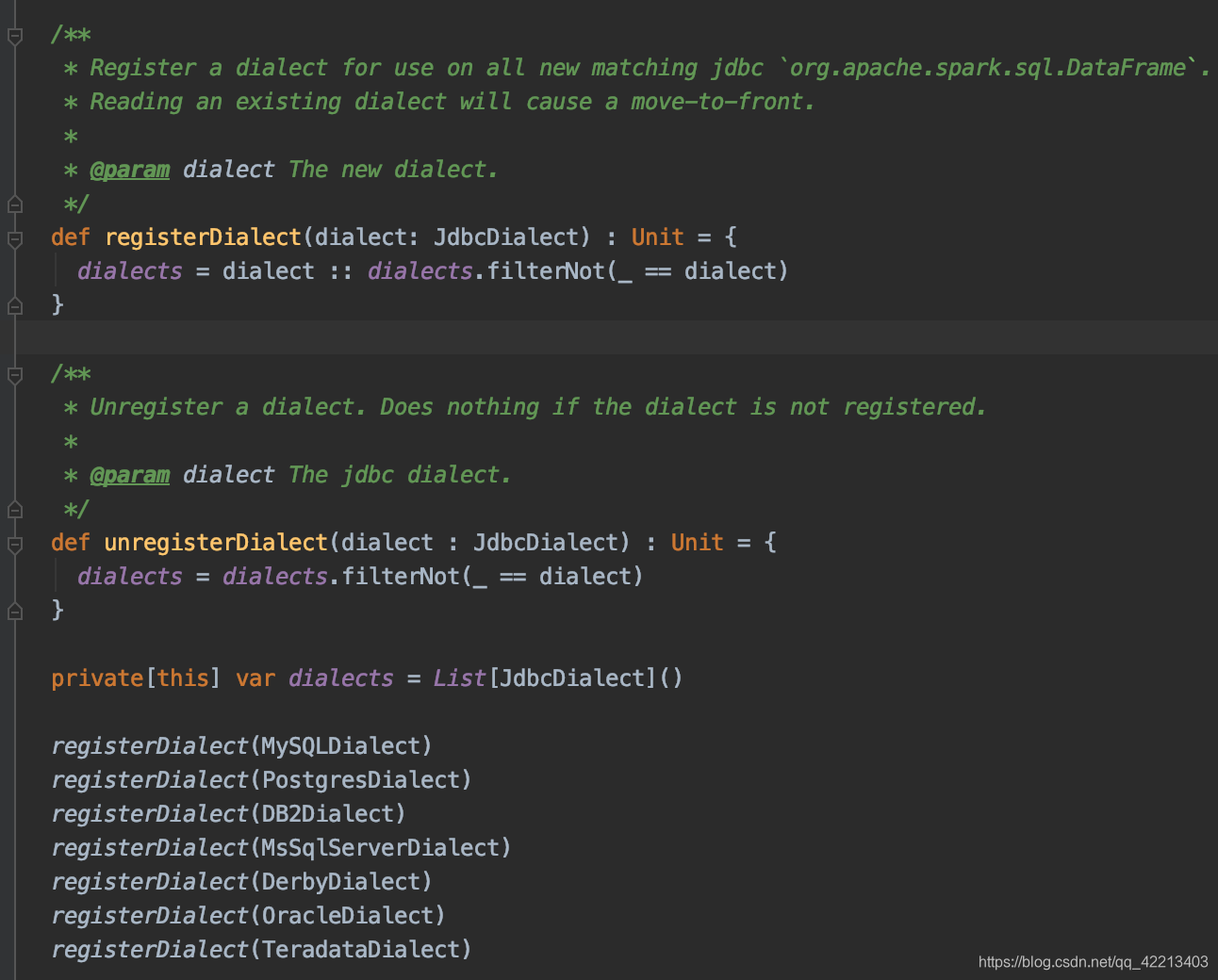
需要手动的加一点料
def register(): Unit = {
JdbcDialects.registerDialect(HiveSqlDialect)
}
case object HiveSqlDialect extends JdbcDialect {
override def canHandle(url: String): Boolean = url.startsWith("jdbc:hive2")
override def quoteIdentifier(colName: String): String = {
colName.split('.').map(part => s"`$part`").mkString(".")
}
}在使用spark jdbc之前调用register()方法手动注册即可

(注意:jdbc读取hive时需要加上.option("fetchsize", 每处理批次的条数),不然同样可能会出现不显示数据的问题)
完整代码
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.jdbc.{JdbcDialect, JdbcDialects}
object test{
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("test")
.getOrCreate()
register()
val df = spark.read
.format("jdbc")
.option("driver","org.apache.hive.jdbc.HiveDriver")
.option("url","jdbc:hive2://xxx:10000/")
.option("user","hive")
.option("password",xxx)
.option("fetchsize", "2000")
.option("dbtable","test.user_info")
.load()
df.show(10)
}
def register(): Unit = {
JdbcDialects.registerDialect(HiveSqlDialect)
}
case object HiveSqlDialect extends JdbcDialect {
override def canHandle(url: String): Boolean = url.startsWith("jdbc:hive2")
override def quoteIdentifier(colName: String): String = {
colName.split('.').map(part => s"`$part`").mkString(".")
}
}
}
欢迎留言讨论和指正

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)