多系统对接的实现方案
随着信息化的发展,以及互联网、万物互联的逐渐普及和大数据时代的来临,数据资产已经成为企业的战略武器,越来越多的企事业单位不断上线了各种软件系统,另外随着移动互联网的发展,又出现了移动端多端应用,既出现了手机、PDA、Pad、移动智慧大屏等多类硬件设备,也出现了向钉钉、企业微信、飞书等分发的微应用,多个系统的同时出现发挥了不同的优势,可是系统平台越多也意味着"信息孤岛"越严重,数据中台和异构系统集成
随着信息化的发展,以及互联网、万物互联的逐渐普及和大数据时代的来临,数据资产已经成为企业的战略武器,越来越多的企事业单位不断上线了各种软件系统,另外随着移动互联网的发展,又出现了移动端多端应用,既出现了手机、PDA、Pad、移动智慧大屏等多类硬件设备,也出现了向钉钉、企业微信、飞书等分发的微应用,多个系统的同时出现发挥了不同的优势,可是系统平台越多也意味着"信息孤岛"越严重,数据中台和异构系统集成的出现就是为了解决信息孤岛,把多样化的系统整合到一起,让数据一体化、标准化,让所有系统能够贯通,这样既减少了重复的工作量,又大大提高了数据的共享能力,实现了数据资产的高度治理。
未来企业会不断走向多元化的发展,从生产经营提升到生产服务一体化运营,从单一产品供应提升为总体方案的建设,从局部服务提升为全方位整合。企业应用的信息化系统也越来越多,截至目前没有任何一套软件能够解决企业的所有的问题,每款系统平台都有他的特性,在管理的某些方面,发挥着比其他产品更加优秀的作用。
未来是一个大融合的时代,大数据时代的信息化建设将单一的系统建设向多系统应用发展,产业互联网的时代将从企业内控管理的内循环会提升为产业协同的外循环。异构系统的数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中采集进来,进行规则的映射,再分发到不同的系统,从而为企业提供全面的数据共享。
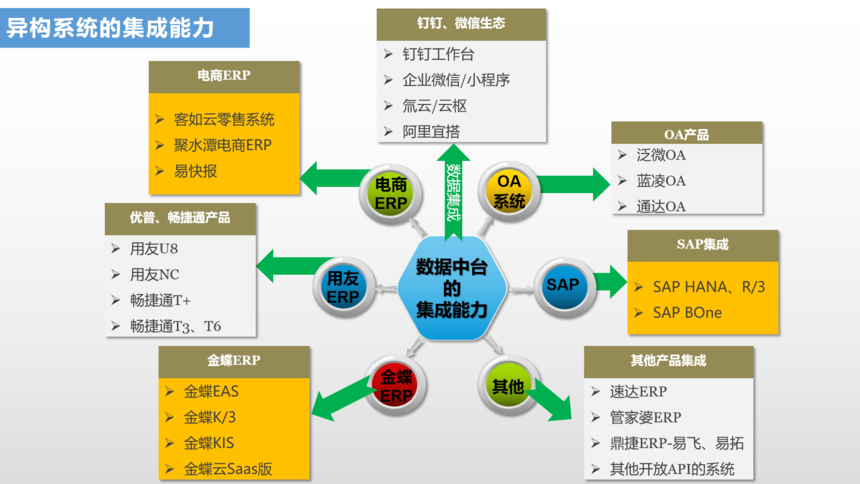
比如下图的场景中可以将SAP强大的企业资源管理和OA强大的审批流程结合起来,实现ERP业务数据流程的严谨管控的同时可以实现合同、付款等重要节点的评审会签和流程审批,同时也可以将采购端、销售端供销商的自主下单和订单跟踪,物流跟进、款项发票对账分发到钉钉、企业微信、公众号、小程序等多端应用中去。甚至针对一些电商的用户,可以将电商系统和企业内部ERP集成起来形成业务闭环,把企业生产出来的商品即时发布到电商平台,把电商平台的订单、发货、收款数据再取回来,在ERP形成了线上业务数据和线下B端批发业务数据的整合,打通了企业的外循环。
要实现企事业单位异构系统的集成也不是一件简简单单的小事,企业普遍的做法是找自己的软件服务商去二次开发,最终会发现A软件厂商说我的接口没问题对方系统有问题,或者是双方的系统都会出现二次开发的可能,每个软件供应商尽可能要保障自己系统的稳定、流程顺畅,把一些疑难问题跑给对方软件公司,有很多客户方也不具备全面的整合能力,其实是甲乙双方打比赛缺少了裁判和评委。数据中台的出现就是要把各方系统中不一致、不标准的数据规范统一标准化,不能标准化的通过抽取双方系统的主数据及相关枚举列表数据做映射关系实现标准化,同时分发给各个系统的数据结构经加工后保证符合对方系统接收的要求。
那么如何实现数据中台多系统的集成呢?我们长期的研发和客户案例中总结出来有以下几种思路可供参考:
1. 通过BusData企业数据总线实现数据集成
BusData数据总线集成是通过在数据中台中间件上统一进行规则制定、采集抽取、映射转换、管道调度和定向分发,它是一个中心辐射型的星型结构或总线结构,因此把它成为BusData数据总线。采用总线架构可以明显减少编写的专用集成代码量,提升了集成接口的可维护性和可管理性。不同连接对象如果连接方式有差异,可以通过总线完全屏蔽掉,做到对连接对象透明,无需各个连接对象关心。通过总线结构,把原来复杂的网状结构变成简单的星形结构,极大提高了硬件的可靠性和可用性。
BusData数据总线集成可分为:EDI-电子数据交换和ESB-企业服务总线
EDI是按照国际标准消息格式发送信息,接收方也需要按国际统一规范的语法规则,对消息进行处理,并引起其他相关系统的EDI综合治理。标准化的EDI数据交换保证了不同国家、地区、企业的各种商业文件(如单证、回执、载货清单、验收通知、出口许可证、原产地证等)的无障碍电子化交换,促进了国际贸易和交互的发展。
ESB企业服务总线的使用标志着数据治理的应用集成进入了SOA面向服务集成的时代。其主要特征是基于一系列Web标准或规范来开发接口程序,包括UDDI、SOAP、WSDL、XML、Json,并采用支持这些规范的中间件产品作为集成平台,从而实现了一种开放而富有弹性的应用集成方式。ESB是对web服务(WebService和Web )的注册、调度和管理,WebService/WebAPI是一种跨编程语言、跨操作系统平台的远程调用技术,是web的一种标准。它向外界暴露了一个能通过Web调用的API接口。各个软件的接口说明文件规定本系统有什么服务可以对外调用和回调,提供了什么服务,本服务中有哪些方法,方法入参是什么,返回值是什么,服务的相关参数及调用方式等等。
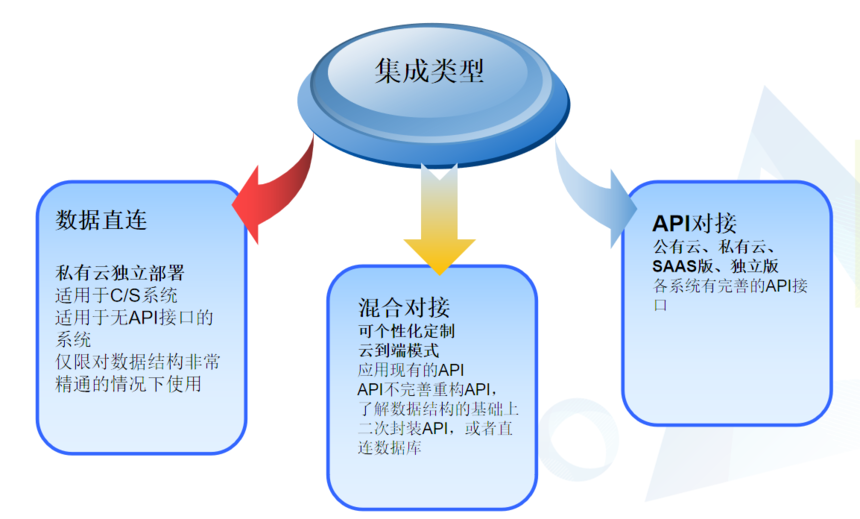
2. 通过点对点现实现数据集成
点对点数据集成的情况常见于2个系统之间的集成,主要场景有端到端(内网部署的两套系统,C/S系统之间的通信等)、端到云(一端部署在企业内部、另一套软件在云端)、云到云(两套系统均在云端)。有些客户会找2套软件中的一家软件供应商去做二次开发,这种方式软件开发方一般采用在原有系统中做接口获取对方数据或者发送给对方系统数据,这种方式应对2个系统对接也许可以,但是难以应对多个系统复杂的数据流向,同时如果任意乙方系统升级、更换其他系列产品等情况发生后,可能导致对接工作需要重新开展。
因此我们看出点对点的集成架构不能集中管理和监控接口服务,仅支持一对一的数据交换,如果交换协议不一致,开发则变得困难,另外这种集成是紧耦合的,当一个对双方系统紧密关联的接口变化时,所有与其相关的接口程序都需要重新调试或开发,从企业长期信息化规划发展来看,这种方式反而成本会比较高,可用性和可维护性差。
3. 批量数据集成
离线批量数据集成,一般是基于ETL工具的离线数据集成,ETL即数据的提取(Extract)、转换(Transform)和加载(Load),。
ETL常用的实现有有三种:ETL工具抽取、数据库同步(数据实时单向同步或双向同步)、ETL和SQL混合同步。
ETL工具抽取,常用到的工具有Talend、DataX、Kettle、Informatic等,借助ETL工具快速建立数据抽取规则定制、调度任务机制,省去了复杂的编程工作,提高了数据治理的效率。
数据库同步是借用数据库自带的同步、订阅、分发的功能进行,但前提是源数据库表和目标系统数据库表结构和字段属性需要保持基本一致,它一般应用与分布式数据库系统,有中央数据库和各终端对称数据库的场景下,对不同的两个系统来说,要保证数据结构的一致性,这种可能性很小,还得搭建中间库,两个系统还得做一些开发才能实现异构系统的集成,另外有很多云端Saas版的系统以及对安全性要求很高的系统不可能开放数据库供对方系统调用。
ETL和SQL混合同步综合了前面二种的优点,会极大地提高ETL的部署速度和效率。
4.流数据集成
流数据集成也叫流式数据实时数据采集,通常是采用Kafka、Kinesis、Flume等流式数据处理工具对NoSQL非关系型数据库进行实时监控和复制,根据应用场景做相应的处理(去重、去噪、预处理运算),之后再写入到对应的数据存储中。
以Kafka为例,它能够通过KafkaConnectAPI实现流数据管道的构建。ConnectAPI利用了Kafka的可扩展性,kafkaconnect是围绕kafka构建的一个可伸缩,可靠的数据流通道,通过kafkaconnect可以快速实现大量数据进出kafka从而和其他源数据源或者目标数据源进行交互构造一个低延时的数据通道。它可通过KafkaStreamsAPI实现数据转换,它用于在Kafka上构建高可分布式、拓展性,容错的应用程序。它建立在流处理的一系列重要功能基础之上,比如正确区分事件事件和处理时间,处理迟到数据以及高效的应用程序状态管理。KafkaStreams包含了ConsumerAPI和ProducerAPI的功能,增强了对数据流的处理能力。使用Kafka作为流处理平台能够消除为每个目标sink、数据存储或系统创建定制化(很可能是重复的)抽取、转换和加载组件的需求。来自数据源的数据经过抽取后可以作为结构化的事件放到平台中,然后可以通过流处理进行数据的转换。
5.爬虫数据采集
爬虫数据采集是通过网络爬虫或网站公开API等方式从网站上获取数据信息的过程,它一种按照一定的规则,自动地抓取互联网信息的程序或者脚本,一般分为通用网络爬虫和聚焦网络爬虫两种。网页爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。常见的网络网页爬虫有Octoparse、WebCopy、HTTrack、Getleft、Scraper等,支持文本文件、图片、音频、视频等非结构化数据、半结构化数据从网页中提取出来,存储在本地的存储系统中。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)