指定offset/指定时间消费Kafka消息
kafka消费过程难免会遇到需要重新消费的场景,例如我们消费到kafka数据之后需要进行存库操作,若某一时刻数据库down了,导致kafka消费的数据无法入库,为了弥补数据库down期间的数据损失,有一种做法我们可以指定kafka消费者的offset到之前某一时间的数值,然后重新进行消费。首先创建kafka消费服务@Service@Slf4j//实现CommandLineRunner接口,在spr
·
一、 指定offset重新消费Kafka消息
首先创建kafka消费服务
@Service
@Slf4j
//实现CommandLineRunner接口,在springboot启动时自动运行其run方法。
public class TspLogbookAnalysisService implements CommandLineRunner {
@Override
public void run(String... args) {
//do something
}
}
kafka消费模型建立
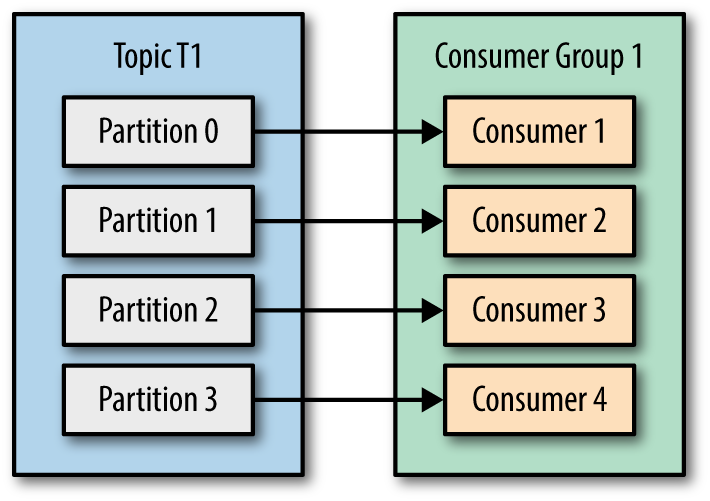
kafka server中每个主题存在多个分区(partition),每个分区自己维护一个偏移量(offset),我们的目标是实现kafka consumer指定offset消费。
在这里使用consumer-->partition一对一的消费模型,每个consumer各自管理自己的partition。
@Service
@Slf4j
public class TspLogbookAnalysisService implements CommandLineRunner {
//声明kafka分区数相等的消费线程数,一个分区对应一个消费线程
private static final int consumeThreadNum = 9;
//特殊指定每个分区开始消费的offset
private List<Long> partitionOffsets = Lists.newArrayList(1111,1112,1113,1114,1115,1116,1117,1118,1119);
private ExecutorService executorService = Executors.newFixedThreadPool(consumeThreadNum);
@Override
public void run(String... args) {
//循环遍历创建消费线程
IntStream.range(0, consumeThreadNum)
.forEach(partitionIndex -> executorService.submit(() -> startConsume(partitionIndex)));
}
}
kafka consumer对offset的处理
声明kafka consumer的配置类:
private Properties buildKafkaConfig() {
Properties kafkaConfiguration = new Properties();
kafkaConfiguration.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.GROUP_ID_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"");
kafkaConfiguration.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "");
...更多配置项
return kafkaConfiguration;
}
创建kafka consumer,处理offset,开始消费数据任务:
private void startConsume(int partitionIndex) {
//创建kafka consumer
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(buildKafkaConfig());
try {
//指定该consumer对应的消费分区
TopicPartition partition = new TopicPartition(kafkaProperties.getKafkaTopic(), partitionIndex);
consumer.assign(Lists.newArrayList(partition));
//consumer的offset处理
if (collectionUtils.isNotEmpty(partitionOffsets) && partitionOffsets.size() == consumeThreadNum) {
Long seekOffset = partitionOffsets.get(partitionIndex);
log.info("partition:{} , offset seek from {}", partition, seekOffset);
consumer.seek(partition, seekOffset);
}
//开始消费数据任务
kafkaRecordConsume(consumer, partition);
} catch (Exception e) {
log.error("kafka consume error:{}", ExceptionUtils.getFullStackTrace(e));
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}
消费数据逻辑,offset操作
private void kafkaRecordConsume(KafkaConsumer<String, byte[]> consumer, TopicPartition partition) {
while (true) {
try {
ConsumerRecords<String, byte[]> records = consumer.poll(TspLogbookConstants.POLL_TIMEOUT);
//具体的处理流程
records.forEach((k) -> handleKafkaInput(k.key(), k.value()));
//🌿很重要:日志记录当前consumer的offset,partition相关信息(之后如需重新指定offset消费就从这里的日志中获取offset,partition信息)
if (records.count() > 0) {
String currentOffset = String.valueOf(consumer.position(partition));
log.info("current records size is:{}, partition is: {}, offset is:{}", records.count(), consumer.assignment(), currentOffset);
}
//offset提交
consumer.commitAsync();
} catch (Exception e) {
log.error("handlerKafkaInput error{}", ExceptionUtils.getFullStackTrace(e));
}
}
}
二、指定时间消费历史Kafka消息并统计数量
package com.lxk.weber.utils;
/**
* @author lixk
* @create 2021/10/12
*/
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.UUID;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndTimestamp;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
public class ConsumeOffsetByTime {
public static void main(String[] args) {
/**
* ************使用说明*******************
* 需要5个参数:
* 1.Server
* 2.Topic
* 3.开始时间,格式yyyyMMddHHmmss
* 4.结束时间,格式yyyyMMddHHmmss
* 5.输出文件
* 例:java -jar ConsumeOffsetByTime .jar [Server] [Topic] 20201128090600 20201128090659 output.txt
*/
if (args.length < 5) {
System.out.println("***********使用说明*****************");
System.out.println("1.Server");
System.out.println("2.Topic");
System.out.println("3.开始时间,格式yyyyMMddHHmmss");
System.out.println("4.结束时间,格式yyyyMMddHHmmss");
System.out.println("5.输出文件");
System.out.println("java -jar ConsumeOffsetByTime .jar [Server] [Topic] 20201128090600 20201128090659 output.txt");
} else {
try {
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
long begintime = sdf.parse(args[2]).getTime();
long endtime = sdf.parse(args[3]).getTime();
consumerByTime(args[0], UUID.randomUUID().toString(), args[1],
begintime, endtime, args[4]);
} catch (Exception e) {
e.printStackTrace();
}
}
}
static void consumerByTime(String server, String groupid, String topic, long begintime, long endtime, String outfile) {
Properties props = new Properties();
props.put("bootstrap.servers", server);
props.put("group.id", groupid);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer(props);
BufferedWriter bw = null;
try {
boolean isBreak;
List<PartitionInfo> partitionInfos = consumer.partitionsFor(topic);
List<TopicPartition> topicPartitions = new ArrayList<>();
Map<TopicPartition, Long> timestampsToSearch = new HashMap<>();
long fetchDataTime = begintime;
for (PartitionInfo partitionInfo : partitionInfos) {
topicPartitions.add(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()));
timestampsToSearch.put(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()), Long.valueOf(fetchDataTime));
}
// 分配一个指定topic的分区
consumer.assign(topicPartitions);
// 设置时间戳
Map<TopicPartition, OffsetAndTimestamp> map = consumer.offsetsForTimes(timestampsToSearch);
DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
OffsetAndTimestamp offsetTimestamp = null;
// 设置各分区的起始偏移量
Iterator<Map.Entry<TopicPartition, OffsetAndTimestamp>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<TopicPartition, OffsetAndTimestamp> entry = iterator.next();
offsetTimestamp = entry.getValue();
if (offsetTimestamp != null) {
int partition = entry.getKey().partition();
long timestamp = offsetTimestamp.timestamp();
long offset = offsetTimestamp.offset();
System.out.println("partition = " + partition + ", time = " + df.format(new Date(timestamp)) + ", offset = " + offset);
consumer.seek(entry.getKey(), offset);
}
}
// 拉取数据
do {
isBreak = false;
ConsumerRecords<String, String> records = consumer.poll(1000L);
bw = new BufferedWriter(new FileWriter(outfile, true));
System.out.println("拉取中: "+ records.count());
for (ConsumerRecord<String, String> record : records) {
bw.write(String.valueOf(record.value()) + "\r\n");
// 设置截止时间
if (record.timestamp() > endtime) {
isBreak = true;
}
}
bw.flush();
bw.close();
} while (!isBreak);
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)