Elasticsearch中字段类型(Field Type)详解
ElasticSearch 7.7 字段类型(Field datatype)详解字符串, object, 数值, 日期, 数组,0x00 字符串: text,...
ElasticSearch 7.7 字段类型(Field datatype)详解
字符串, object, 数值, 日期, 数组,
0x00 字符串: text, keyword
5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
ElasticSearch字符串将默认被同时映射成text和keyword类型,将会自动创建类似下面的动态映射(dynamic mappings):
{
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
这就是造成部分字段还会自动生成一个与之对应的“keyword”字段的原因。
text
会被分词器解析, 生成倒排索引, 支持模糊、精确查询, 不用于排序, 很少用于聚合(significant text aggregation除外)
常用于全文检索.
如果需要为结构化内容, 比如 id、email、hostnames、状态码、标签等进行索引,则推荐使用 keyword 类型以进行完全匹配. 比如我们需要查询"已发货"的订单, 标记为"已发布"的文章等.
更多信息参考官方文档
PUT my_index
{
"mappings": {
"properties": {
"full_name": {
"type": "text"
}
}
}
}
keyword
不进行分词,直接索引, 支持模糊、精确查询, 支持聚合
PUT my_index
{
"mappings": {
"properties": {
"tags": {
"type": "keyword"
}
}
}
}
ES会对"数值(numeric)"类型的字段(比如, integer, long)进行优化以支持范围(range)查询. 但是, 不是所有的数值类型的数据都需要使用"数值"类型, 比如产品id, 会员id, ISDN(出版社编号), 这些很少会被进行范围查询, 通常都是精确匹配(term query).
keyword类型的查询通常比numeric的要快, 如果不需要范围查询, 则建议使用keyword类型.
如果不确定使用哪一种, 可以通过multi-field同时设置keyword和numeric类型.
更多信息参考官方文档
0x01 数值类型(numeric)
- 整型: byte, short, integer, long 这些与java中的类型一致
- 浮点型: float, half_float, scaled_float, double
| 类型 | 说明 | 取值范围 |
|---|---|---|
| byte | 8位有符号整数 | -128 ~ 127 |
| short | 16位有符号整数 | -32768 ~ 32767 |
| integer | 32位有符号整数 | -2,147,483,648 ~ 2,147,483,647 即:-2^31 ~ 2^32 - 1 |
| long | 64位有符号整数 | -2^63 ~ 2^63 - 1 |
| float | 32位单精度IEEE 754浮点类型, 有限值, 24bits | 2^-149 ~ (2 - 2^-23) · 2^127 |
| double | 64位双精度IEEE 754浮点类型, 有限值, 53bits | 2^-1074 ~ (2 - 2^-52) · 2^1023 |
| half_float | 16位半精度IEEE 754浮点类型, 有限值, 11bits | 2^-24 ~ 65504 |
| scaled_float | 带有缩放因子scaling_factor的浮点数, 可以当整型看待 |
比如:
PUT my_index
{
"mappings": {
"properties": {
"number_of_bytes": {
"type": "integer"
},
"time_in_seconds": {
"type": "float"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
上面我们定义了3个字段:
- number_of_bytes: 整型, integer
- time_in_seconds: 浮点型, float
- price: 带有缩放因子
scaling_factor的浮点数. 比如价格是99.99, 缩放因子为100, 那么存储的值就是long类型的9999.
这种方式我们在数据库中也经常使用, 比如我们在mysql中存储价格, 只需要精确到分的话, 我们可以使用
decimal(12,2)或者int类型, 使用int类型可以节省空间而且不存在精度转换问题, 但是我们必须在业务逻辑中使用缩放因子进行转换, 而ES的scaled_float直接帮我们处理了.
对于上面展示的3种浮点类型(float, half_float, scaled_float)来说, -0.00和+0.00是不同的值,使用term查询-0.00时不会匹配+0.00, 反之亦然。对于范围查询(range query)来说也是如此:如果上边界是-0.00则无法匹配+0.00,如果下边界是+0.00则不会匹配-0.00
数值类型使用的注意事项:
- 在满足业务需求的情况下, 尽量选择范围小的类型, 这与mysql等关系型数据库的设计要求是一致的. 字段占用的空间越小, 搜索和索引的效率越高(这个有点废话, 数据量越小肯定越快了).
官方文档说"storage is optimized based on the actual values that are stored", 难道一个integer类型的字段在存储很小的值, 比如100, 的时候会只占用1个字节而不是4个字节吗? 这个与mysql倒是不同的. 在mysql的存储中int就是4个字节, 而varchar才会根据实际的内容占用空间并记录长度.
- 如果是浮点数, 则也要优先考虑使用scaled_float类型.
对于scaled_float类型, 在索引时会乘以scaling_factor并四舍五入到最接近的一个long类型的值.
如果我们存储商品价格只需要精确到分, 两位小数点, 把缩放因子设置为100, 那么浮点价格99.99存储的是9999.
如果我们要存储的值是2.34, 而因子是10, 那么会存储为23, 在查询/聚合/排序时会表现为这个值是2.3. 如果设置更大的因子(比如100), 可以提高精度, 但是会增加空间需求.
scaled_float在查询时的的数据处理应该与mysql类似, 比如: SELECT * FROM products WHERE price > 99.99 * 100, 而不是 SELECT * FROM products WHERE price / 100 > 99.99, 后面一个写法不符合mysql优化原则: 不要对栏位进行函数运算以及类型转换.
0x02 Object类型
JSON文档天生具有层级关系: 文档可能包含内部对象, 而这个对象可能本身又包含对象, 就是可以包含嵌套的对象.
PUT my_index2/_doc/1
{
"region":"US",
"manager":{
"age":30,
"name":{
"first":"John",
"last":"Smith"
}
}
}
上面的文档中,整体是一个JSON,JSON中包含一个manager,manager又包含一个name。最终,文档会被索引成一平的key-value对:
整个文档是一个JSON对象, 它包含一个叫"manager"的内部对象, 而"manager"又包含一个叫"name"的内部对象.
在ES内部, 这个文档会被索引成一个扁平的key-value对:
{
"region": "US",
"manager.age": 30,
"manager.name.first": "John",
"manager.name.last": "Smith"
}
上面那个文档的mapping可以显式声明如下:
PUT my_index2
{
"mappings": {
"properties":{
"region":{
"type": "keyword"
},
"manager":{
"properties": {
"age":{"type":"integer"},
"name":{
"properties":{
"first":{"type":"text"},
"last":{"type":"text"}
}
}
}
}
}
}
}
这个索引有2个一级字段: region, manager. 而manager是一个对象类型, 又包含字段age和name, 可以写为 manager.age, manager.name. 而字段 manager.name 又是一个包含first和last的对象.
内部对象的type就是object, 这个不需要我们显式的去声明, 虽然我们写上去也没错.

如果需要对数组形式的对象(objects), 而不是单个对象, 进行索引, 请参考 Nested
0x03 date 类型
JSON没有日期(date)类型, 在ES中date类型可以表现为:
- 字符串格式的日期, 比如: "2015-01-01", "2015/01/01 12:10:30"
- long类型的自 epoch (1970-1-1) 以来的毫秒数
- integer类型的自 epoch (1970-1-1) 以来的秒数(时间戳, timestamp)
在ES内部, 日期被转换为UTC格式(如果指定了时区), 并存储为long类型的自 epoch (1970-1-1) 以来的毫秒数.
查询时 , date类型会在内部转换为long类型的范围查询,聚合和存储字段的结果根据与字段关联的日期格式转换回字符串。
date总是被显示为字符串格式, 即使他们在JSON文档中是long类型.
可以自定义date的格式, 如果没有指定format则默认格式为: strict_date_optional_time || epoch_millis, 其中的"||"是 "multiple formats"的分隔符.
strict_date_optional_time 格式是指ISO标准格式, 例如: yyyy-MM-dd'T'HH:mm:ss.SSSZ 或者 yyyy-MM-dd
比如, 可以使用 "2015-01-01T12:10:30Z" 或者 "1420070400001"
DELETE my_index
# 使用默认格式
PUT my_index
{
"mappings": {
"properties": {
"date":{
"type": "date"
}
}
}
}
# 纯日期
PUT my_index/_doc/1
{ "date": "2015-01-01" }
# 包含时间
PUT my_index/_doc/2
{ "date": "2015-01-01T12:10:30Z" }
# 使用long格式的毫秒值
PUT my_index/_doc/3
{ "date": 1420070400001 }
查看:
GET my_index/_search?filter_path=hits.hits
查看结果:
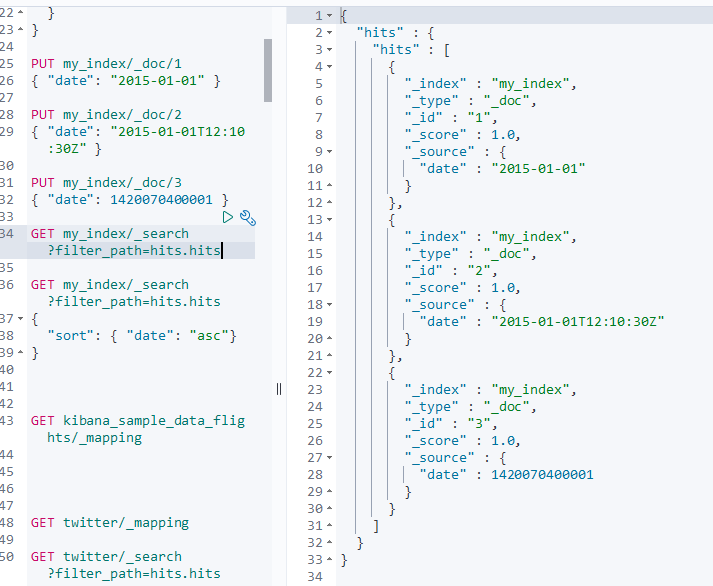
排序:
GET my_index/_search?filter_path=hits.hits
{
"sort": { "date": "asc"}
}
排序结果: sort栏位是一个long类型的毫秒值

Multiple date formats
使用||作为分隔符来让日期支持多种格式. 会轮流尝试每一种格式, 直到与之相匹配. 第一种格式会被用来把毫秒值转换回字符串.
PUT my_index
{
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
0x04 Array类型
ELasticsearch没有独立的数组类型,默认情况下任何字段都可以包含一个或者多个值,但是数组中的值必须是同一种类型。例如:
- 字符串数组: [ “one”, “two” ]
- 整型数组:[ 1, 2 ]
- 嵌套数组:[ 1, [ 2, 3 ]], 它等价于 [ 1, 2, 3 ]
- 对象数组:[ { “name”: “Mary”, “age”: 12 }, { “name”: “John”, “age”: 10 }]
note: 对象数组不能像你预期的那样工作:不能单独查询数组中的某一个对象(you cannot query each object independently of the other objects in the array)。如果你需要这样做,应该是用Nested类型而不是 object.
动态添加数组类型的字段时,数组中的第一个值决定了它的字段类型。后面的值必须具有相同的数据类型,或者至少可以将后续值强制转换为相同的数据类型。
混合类型的值是不被数组支持的, 比如 [ 10, "some string" ] 是不被支持的.
数组可以包含null值,它会被配置的 null_value 替代 或者 直接被忽略。
空数组 [] 会被当做missing field对待。
要在文档中使用数组,无需预先配置,它们受到开箱即用的支持:
PUT my_index4/_doc/1
{
"message": "has arrays",
"tags":["es", "mysql"],
"lists":[
{
"name":"java",
"description":"java book"
}
,{
"name":"python",
"description":"python book"
}
]
}
PUT my_index4/_doc/2
{
"message":"no arrays",
"tags":"es",
"lists":{
"name":"java",
"description":"use java"
}
}
GET my_index4/_search
{
"query":{
"match": {
"tags": "es"
}
}
}
id=1的文档, 动态的添加了一个字符串类型数组的字段"tags"和一个对象类型的字段"lists".
id=2的文档没有数组类型的字段, 但是可以像id=1的文档一样的索引到对应的字段里面去.
当我们搜索"tags"等于"es"的时候, 两个文档都是匹配的.
如果要搜索lists的name是java的呢?
GET my_index4/_search
{
"query":{
"match": {
"lists.name": "java"
}
}
}
两个文档也都可以匹配到! 想知道为什么? 用GET my_index4/_mapping看一下:
{
"my_index4" : {
"mappings" : {
"properties" : {
"lists" : {
"properties" : {
"description" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"message" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
我们可以看到, lists是object类型, message和tags都是text类型!
0x05 Binary类型
二进制类型, 值以Base64字符串的形式存贮,_source默认不会存贮该类型的值, 也不可搜索. 如果需要实际的存贮,请设置 store属性为true. 默认是false
DELETE /my_index
# 新增一个索引
PUT /my_index
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"name_blob": {
"type": "binary",
"doc_values": false,
"store": false
}
}
}
}
# 添加一个文档
PUT /my_index/_doc/1
{
"name": "aben",
"name_blob": "YWJlbg=="
}
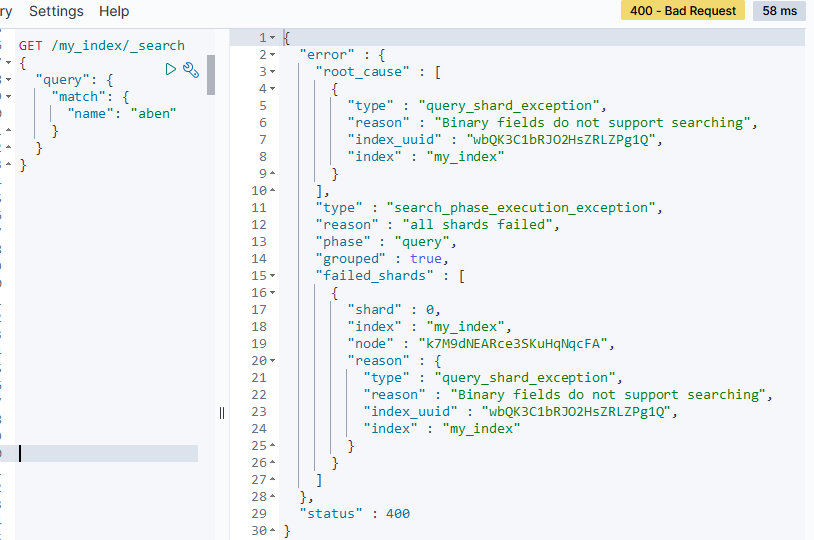
如果我们直接搜索name_blob列, 会报错:
GET /my_index/_search
{
"query": {
"match": {
"name": "aben"
}
}
}
0x06 ip类型
ip类型的字段只能存储ipv4或ipv6地址.
DELETE /my_index
# 新增一个索引
PUT my_index
{
"mappings": {
"properties": {
"ip_addr": {
"type": "ip"
}
}
}
}
POST _bulk
{"index":{"_index":"my_index", "_id":1}}
{"ip_addr":"192.168.1.1"}
{"index":{"_index":"my_index", "_id":2}}
{"ip_addr":"192.168.2.1"}
{"index":{"_index":"my_index", "_id":3}}
{"ip_addr":"192.168.0.1"}
{"index":{"_index":"my_index", "_id":4}}
{"ip_addr":"192.168.1.10"}
{"index":{"_index":"my_index", "_id":5}}
{"ip_addr":"192.168.3.1"}
{"index":{"_index":"my_index", "_id":6}}
{"ip_addr":"192.169.1.169"}
# 查询ip是192.168段的文档
GET my_index/_search
{
"query": {
"term": {
"ip_addr": "192.168.0.0/16"
}
}
}
# 查询ip是192.168.0段的文档
GET my_index/_search
{
"query": {
"term": {
"ip_addr": "192.168.0.0/24"
}
}
}
ipv6的查询也是类似的:
GET my_index/_search
{
"query": {
"term": {
"ip_addr": "2001:db8::/48"
}
}
}
当然ip地址也是支持范围查询的: ip_range, 下面的range会讲到.
0x07 range类型
range类型支持的有:
| 类型 | 说明 |
|---|---|
| integer_range | 32位有符号整数, 取值范围 -2^31 ~ 2^32 - 1 |
| float_range | 32位的单精度IEEE754浮点数范围 |
| long_range | 64位有符号整数, 取值范围 -2^63 ~ 2^63 - 1 |
| double_range | 64位双精度IEEE754浮点数范围 |
| date_range | 无符号的64位整数, 自系统纪元(1970-1-1)以来经过的毫秒数的日期值范围 |
| ip_range | 支持IPv4或IPv6(或混合的)地址的ip值范围 |
来个栗子:
DELETE /range_index
# 定义一个索引, 有2个字段: expected_attendees是整数范围, time_frame是日期范围
PUT /range_index
{
"mappings": {
"properties": {
"expected_attendees": {
"type": "integer_range"
},
"time_frame": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
# 插入数据: expected_attendees取值范围为10~20, 日期time_frame的范围是2015-10-31 12:00:00 ~ 2015-11-01
PUT /range_index/_doc/1?refresh
{
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2015-10-31 12:00:00",
"lte" : "2015-11-01"
}
}
term类型的查询比较好理解, 就是判断某一个值是否有对应的范围的记录存在
# 整数范围查询
GET range_index/_search
{
"query" : {
"term" : {
"expected_attendees" : {
"value": 12
}
}
}
}
# 日期范围查询
## 查询某一个日期是否有对应的范围值
GET range_index/_search
{
"query" : {
"term" : {
"time_frame" : {
"value" : "2015-10-31 13:00:00"
}
}
}
}
## 范围查询支持within, contains, intersects(默认)
GET range_index/_search
{
"query" : {
"range" : {
"time_frame" : {
"gte" : "2015-10-30 11:00:00",
"lte" : "2015-11-01 08:00:00",
"relation" : "within"
}
}
}
}
再看一个ip范围的栗子:
# IP范围类型
PUT /range_index2
{
"mappings": {
"properties": {
"ip_whitelist": {
"type": "ip_range"
}
}
}
}
# 插入一个192.168.*.*都支持的白名单文档
PUT /range_index2/_doc/1
{
"ip_whitelist" : "192.168.0.0/16"
}
# 查询 192.168.1.2是否有匹配的文档: 有
GET /range_index2/_search
{
"query":{
"term":{
"ip_whitelist":"192.168.1.2"
}
}
}
# 查询 10.0.1.2是否有匹配的文档: 无
GET /range_index2/_search
{
"query":{
"term":{
"ip_whitelist":"10.0.1.2"
}
}
}
官方文档: 链接
0x08 nested类型
nested嵌套类型是object中的一个特例,可以让array类型的Objects独立索引和查询。
array类型的object是怎么扁平化的呢?
ES没有内部对象(inner objects)的概念, 它将对象层次结构平铺为键和值的简单列表, 比如下面的文档:
DELETE /my_index
# 不定义索引的mapping, 直接插入array类型的数据, ES会自动生成mapping,但是字段类型是object
PUT /my_index/_doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
上面的文档会被平铺成这样:
{
"group" : "fans",
"user.first" : [ "alice", "john" ],
"user.last" : [ "smith", "white" ]
}
user.first和user.last会被平铺为多值字段,Alice和White之间的关联关系会消失。上面的文档会被错误的匹配到以下查询(虽然能搜索到, 实际上不存在Alice Smith):
# 查询结果是错误的, 实际上目前这个索引不存在Alice Smith
GET my_index/_search
{
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}
使用 nested 字段类型来处理数组类型的object带来的问题
DELETE /my_index
# 定义索引, 使用nested字段类型处理object array
PUT my_index
{
"mappings": {
"properties": {
"user": {
"type": "nested"
}
}
}
}
# 插入数据
PUT my_index/_doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
# 搜索 Alice Smith
GET my_index/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}
}
}
# 搜索 Alice Smith, 并用inner_hits高亮指定的字段
GET my_index/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "White" }}
]
}
},
"inner_hits": {
"highlight": {
"fields": {
"user.first": {}
}
}
}
}
}
}
nested字段类型的使用限制
ES把每一个nested对象都索引成一个单独的Lucene文档. 如果我们要索引一个包含100个user对象的文档, ES会建立101个Lucene文档: 一个父级文档, 以及100个user对象的文档. 因为这个高昂的代价, ES设置了几个参数以防止性能问题:
- index.mapping.nested_fields.limit: 一个索引中独立的nested mappings的最大数量, 默认50. 只有当需要关联查询array类型的object的时候才使用它, 其他情况不要滥用.
- index.mapping.nested_objects.limit: 一个单独的文档中所有nested类型字段所包含的nested JSON对象的最大个数, 默认10000. 这有助于阻止OOM(out of memory)问题.
0x09 token_count类型
一个token_count类型的字段其实就是一个 integer字段, 可以存储字符串值, 分析并统计词的个数.
DELETE /my_index
# name 字段是text类型
# name.length 是一个 multi filed 的 token_count 类型, 参数 analyzer 必填
PUT /my_index
{
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"length": {
"type": "token_count",
"analyzer": "standard"
}
}
}
}
}
}
# 插入2个文档
PUT my_index/_doc/1
{ "name": "John Smith" }
PUT my_index/_doc/2
{ "name": "Rachel Alice Williams" }
# 查询name字段中词的个数为3的文档
GET my_index/_search
{
"query": {
"term": {
"name.length": 3
}
}
}
参数请参考官方文档 token_count
0x0A. Geo point / Geo shape 类型
geo point
geo_point接受 纬度-精度 数值对, 可以用于:
- 在指定的矩形框(geo_bounding_box), 或 与某一个坐标一定距离内, 或一个多边形, 或 地理位置形状查询(geo_shape query), 去寻找坐标点
- 按地理位置或与某一个位置的距离去聚合文档
- 把距离整合到文档的相关性得分中
- 把文档按距离排序
可以使用5种方式设置geo_point的字段的值:
DELETE /my_index
# 定义索引
PUT my_index
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
# 插入geo_point字段的5种方式
PUT my_index/_doc/1
{
"text": "Geo-point as an object",
"location": { "lat": 41.12, "lon": -71.34 }
}
# string方式: lat, lon
PUT my_index/_doc/2
{
"text": "Geo-point as a string",
"location": "41.12,-71.34"
}
PUT my_index/_doc/3
{
"text": "Geo-point as a geohash",
"location": "drm3btev3e86"
}
# 数组方式: lon, lat
PUT my_index/_doc/4
{
"text": "Geo-point as an array",
"location": [ -71.34, 41.12 ]
}
PUT my_index/_doc/5
{
"text": "Geo-point as a WKT POINT primitive",
"location" : "POINT (-71.34 41.12)"
}
# 查询: 按矩形范围
GET my_index/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 42, "lon": -72
},
"bottom_right": {
"lat": 40, "lon": -74
}
}
}
}
}
需要注意: string方式的顺序是 "lat, lon", 而数组方式的顺序是 [lon, lat]
参数:
- ignore_malformed: 是否忽略不符合要求的值. 默认false, 会抛出异常并拒绝接受该文档. 为true, 在忽略该位置.
- null_value: 是否接受一个null值. 默认是null, 表示这个字段没有设置
- ignore_z_value: 是否接受一个三维坐标值(但是仅纬度和经度会被索引). 默认是true. 如果设置为false, 则数据不符合要求时直接抛出异常, 并拒绝接受该文档.
geo shape
geo_shape数据类型有助于对任意地理形状(如矩形和多边形)进行索引和搜索。 当被索引的数据或正在执行的查询包含形状而不仅仅是点时,应该使用它,以得到比geo_point更高的查询效率。
geo_shape类型字段的查询参考 geo_shape query
mapping选项
- tree ES 6.6 已废弃.
- precision ES 6.6 已废弃.
- tree_levels ES 6.6 已废弃.
- strategy ES 6.6 已废弃.
- distance_error_pct ES 6.6 已废弃.
- orientation 可选, 定义如何解释多边形/多多边形的顶点顺序。
- points_only ES 6.6 已废弃.
- ignore_malformed 是否忽略不符合 GeoJSON或WKT形状的数据。默认
false。如果数据不符合会抛出异常并拒绝该文档. - ignore_z_value 是否接受三维坐标但是值去经纬度的数据而忽略第三维度的值。默认
true。如果设置false, 则抛出异常并拒绝该文档. - coerce 是否自动闭合多边形中未闭合的线性环。默认
false。
索引方法 (Indexing approach)
GeoShape类型的索引是通过将形状分解成一个三角形网格并将每个三角形索引为BKD树中的7维的点来实现的。 这提供了近乎完美的空间分辨率(小到1e^-7的十进制精度),因为所有空间关系都是使用原始形状的编码向量表示来计算的,而不是使用前缀树索引方法所使用的栅格-网格表示。 镶嵌器的性能主要取决于定义多边形/多多边形的顶点数。 虽然这是默认的索引技术,但仍然可以通过根据适当的Mapping Options设置树或策略参数来使用前缀树。
注意,这些参数现在已弃用,并将在未来的版本中删除。
前缀树 (Prefix trees)
ES 6.6已废弃
空间策略 (Spatial strategies)
ES 6.6已废弃. 提供了 recursive和term两种策略. recursive支持所有形状使用INTERSECTS /DISJOINT/WITHIN/CONTAINS查询, 而term只支持points使用INTERSECTS查询.
精度(accuracy)
Recursive和Term策略不能提供100%的准确性,根据它们的配置,可能会对 INTERSECTS、WITHIN 和 CONTAINS 查询返回一些假阳性,对DISJOINT查询返回一些假阴性。 为了减轻这种情况,为tree_levels参数选择一个合适的值并相应地调整预期值是很重要的。 例如,一个点可能靠近特定网格单元格的边界,因此可能不匹配只匹配它旁边的单元格的查询——即使形状非常接近这个点。
更多内容请参考官方文档 Geo-shape datatype
最后更新 10/21

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)